También podría gustarte
- Factor de Empaquetamiento para Una Celda Hexagonal CompactaDocumento5 páginasFactor de Empaquetamiento para Una Celda Hexagonal CompactaJesus Julio50% (2)
- Curso básico de teoría de númerosDe EverandCurso básico de teoría de númerosCalificación: 5 de 5 estrellas5/5 (2)
- Consolid 11no TrigonometriaDocumento16 páginasConsolid 11no Trigonometriayoandris100% (4)
- Sistema de Control 2 - S6 - Victor GuzmanDocumento9 páginasSistema de Control 2 - S6 - Victor GuzmanVictor Hugo Guzmán Silva100% (2)
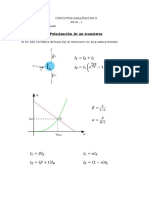
- Circuitos Analogicos Ii PardoDocumento91 páginasCircuitos Analogicos Ii PardojbfjegfgewfwefAún no hay calificaciones
- 05-05-2022 VARIABLES ALEATORIAS CONTINUAS Y ALGUNOS MODELOS DE PROBABILIDAD Funciones de Probabilidad Bivariantes Esperanza Bivariantes - CovarianzaDocumento6 páginas05-05-2022 VARIABLES ALEATORIAS CONTINUAS Y ALGUNOS MODELOS DE PROBABILIDAD Funciones de Probabilidad Bivariantes Esperanza Bivariantes - CovarianzaAlain RamosAún no hay calificaciones
- Formulario de DistribucionesDocumento3 páginasFormulario de DistribucionesALVARO TOCO TOACAAún no hay calificaciones
- Fórmulas de Estadística - S1Documento4 páginasFórmulas de Estadística - S1Junior Daygoro Navarro IpanaqueAún no hay calificaciones
- MAEDocumento7 páginasMAESomaly Ariana Pachacama GrandaAún no hay calificaciones
- Ejercicios Desarrollados de V.a.1Documento9 páginasEjercicios Desarrollados de V.a.1Yomer CernaAún no hay calificaciones
- EE610N PC3 Grupo5Documento33 páginasEE610N PC3 Grupo5Kiara RodriguezAún no hay calificaciones
- Tema 3 VAD 2020 1 PDFDocumento9 páginasTema 3 VAD 2020 1 PDFPriscila OñasAún no hay calificaciones
- UntitledDocumento12 páginasUntitledANGIE CELESTE MACIAS GONZALEZAún no hay calificaciones
- TENSORES ExpoDocumento33 páginasTENSORES ExpoelvisAún no hay calificaciones
- Bibliografia - METODO-DE-DYKSTRADocumento16 páginasBibliografia - METODO-DE-DYKSTRAJeffTorresAún no hay calificaciones
- República Bolivariana de Venezuela Instituto Universitario Politécnico "Santiago Mariño" Escuela de Ingeniería Eléctrica Extensión MaturínDocumento18 páginasRepública Bolivariana de Venezuela Instituto Universitario Politécnico "Santiago Mariño" Escuela de Ingeniería Eléctrica Extensión Maturínperro locoAún no hay calificaciones
- Primera Calificada de Inteligencia ArtificialDocumento3 páginasPrimera Calificada de Inteligencia ArtificialIsaac Alexis RiveraAún no hay calificaciones
- Intervalos de Confianza - Diferencia de MediasDocumento8 páginasIntervalos de Confianza - Diferencia de MediasAxcel Chilingano RojasAún no hay calificaciones
- Fundamentos de Circuitos Electricos - SadikuDocumento19 páginasFundamentos de Circuitos Electricos - SadikuJuan Pablo OcampoAún no hay calificaciones
- Coordendas Intrinsecas y Radio de Curvatura - Fis100 - 16032021Documento15 páginasCoordendas Intrinsecas y Radio de Curvatura - Fis100 - 16032021Nicolas Ramiro Lopez RafaelAún no hay calificaciones
- Sesión 1Documento8 páginasSesión 1Sara Daniela Garcia AparicioAún no hay calificaciones
- CLASE DE EJERCICIOS-No1Documento5 páginasCLASE DE EJERCICIOS-No1araña 17Aún no hay calificaciones
- FlujodePotenciaDocumento3 páginasFlujodePotenciaAntonio ChacónAún no hay calificaciones
- Formulario ProbabilidadDocumento8 páginasFormulario ProbabilidadVanesa LeónAún no hay calificaciones
- Flujos de Potencia (2) - EjerciciosDocumento10 páginasFlujos de Potencia (2) - EjerciciosKevin HuacchilloAún no hay calificaciones
- EXA-2017-2S-ESTADÍSTICA DESCRIPTIVA-3-1ParDocumento7 páginasEXA-2017-2S-ESTADÍSTICA DESCRIPTIVA-3-1Parthe flashAún no hay calificaciones
- Regresores Estocásticos y Variables Instrumentales PDFDocumento13 páginasRegresores Estocásticos y Variables Instrumentales PDFLilly Pop0% (1)
- (Tarea1) (Metodos Numericos)Documento18 páginas(Tarea1) (Metodos Numericos)Bryan SantiagoAún no hay calificaciones
- Unidad III Inferencia Acerca de Una y Dos PoblacionesDocumento25 páginasUnidad III Inferencia Acerca de Una y Dos Poblaciones??????Aún no hay calificaciones
- Te IIPt 3 Jgranes 10022021Documento6 páginasTe IIPt 3 Jgranes 10022021John Paulo GranesAún no hay calificaciones
- 2da Clase - Modelo Clásico de Regresión Lineal - INTRO MCODocumento22 páginas2da Clase - Modelo Clásico de Regresión Lineal - INTRO MCOJosé Daniel Colque HuereAún no hay calificaciones
- Un Formulario para EstadisticaDocumento5 páginasUn Formulario para EstadisticaDaniel Robinson GutierrezAún no hay calificaciones
- Practica Dirigida 02 (1) .BDocumento11 páginasPractica Dirigida 02 (1) .BAnsel Villanueva HerreraAún no hay calificaciones
- Solucionario Taller 7 EconometríaDocumento14 páginasSolucionario Taller 7 EconometríaKarla Milena Pedroza OspinaAún no hay calificaciones
- Taller 2 Procesamiento ImagenesDocumento19 páginasTaller 2 Procesamiento ImagenesSantiago LealAún no hay calificaciones
- Taller de Preconceptos N°1Documento2 páginasTaller de Preconceptos N°1julian carantonAún no hay calificaciones
- Ejercicios Resueltos Sobre Desviación Estándar Poblacional, Función de Densidad de Probabilidad, Estimación Por Momentos y Variable AleatoriaDocumento10 páginasEjercicios Resueltos Sobre Desviación Estándar Poblacional, Función de Densidad de Probabilidad, Estimación Por Momentos y Variable AleatoriaMario Orlando Suárez IbujésAún no hay calificaciones
- Ayudantia Sabado 14 de MayoDocumento3 páginasAyudantia Sabado 14 de MayoAlejandraAún no hay calificaciones
- Problemario Canales de InformacionDocumento5 páginasProblemario Canales de InformacionPancho VázquezAún no hay calificaciones
- Clase Funcion DistribucionDocumento10 páginasClase Funcion DistribucionJeanPierreVargasBastiasAún no hay calificaciones
- TRABAJO V - Desarrollo Del Pensamiento Lógico MatemáticoDocumento18 páginasTRABAJO V - Desarrollo Del Pensamiento Lógico MatemáticoEmerson Junior Ramos CotrinaAún no hay calificaciones
- AULA 3 - 9 de Agosto de 2022Documento19 páginasAULA 3 - 9 de Agosto de 2022Carolina Choque MamaniAún no hay calificaciones
- Modelos DiscretosDocumento54 páginasModelos DiscretosLeidy Florez02Aún no hay calificaciones
- Primer CertamenDocumento8 páginasPrimer CertamenDanilo MuñozAún no hay calificaciones
- Variable Aleatoria DiscretaDocumento45 páginasVariable Aleatoria DiscretaGaAún no hay calificaciones
- Examen de Probabilidades 1Documento1 páginaExamen de Probabilidades 1César CAAún no hay calificaciones
- Bfi06 Clase Semana12Documento13 páginasBfi06 Clase Semana12Cmasmas 97Aún no hay calificaciones
- Ada Inferencia Unidad 2Documento13 páginasAda Inferencia Unidad 2José Eduardo HerreraAún no hay calificaciones
- Taller FiltrosDocumento3 páginasTaller FiltrosJuan Martin Calderon RestrepoAún no hay calificaciones
- Diseño y Simulación de AntenasDocumento43 páginasDiseño y Simulación de AntenasDanny SPAún no hay calificaciones
- 5 - Producto Vectorial, Ecuacion de La Recta y Del PlanoDocumento10 páginas5 - Producto Vectorial, Ecuacion de La Recta y Del PlanoSimone bbbbeAún no hay calificaciones
- Identidades Trigonometricas FundamentalesDocumento2 páginasIdentidades Trigonometricas FundamentalesJesus Nuñez CuevaAún no hay calificaciones
- Laboratorio de Estadística Aplicada-SemiresueltoDocumento5 páginasLaboratorio de Estadística Aplicada-SemiresueltoMiluska Rubio PortalesAún no hay calificaciones
- Algebra LinealDocumento5 páginasAlgebra LinealAdriel ManzanoAún no hay calificaciones
- Ejercicios MecánicaDocumento4 páginasEjercicios Mecánicamario1404Aún no hay calificaciones
- Extrapolación de Richardson PDFDocumento5 páginasExtrapolación de Richardson PDFANDRES FELIPE CARDOZO CASTILLOAún no hay calificaciones
- Parcial de Econometria IDocumento11 páginasParcial de Econometria IJesús DavidAún no hay calificaciones
- Clase Integral PC1 MA265 - 2021-2 (Solucionario)Documento5 páginasClase Integral PC1 MA265 - 2021-2 (Solucionario)César MartinezAún no hay calificaciones
- Peceros Villcas, Franklin PativilcaDocumento4 páginasPeceros Villcas, Franklin Pativilcafrankdaniel peceros villcasAún no hay calificaciones
- PIA Contexto SocialDocumento19 páginasPIA Contexto Socialeduardo jacobo sillerAún no hay calificaciones
- Makro Avance Diario 14-10Documento2 páginasMakro Avance Diario 14-10Zamuel ChacónAún no hay calificaciones
- 00 Tecnologia2020condensado TallerDocumento13 páginas00 Tecnologia2020condensado TallerElizabeth Quiñones AedoAún no hay calificaciones
- Introduccion A La Gestion de ProyectosDocumento17 páginasIntroduccion A La Gestion de ProyectosBetzabé TolentinoAún no hay calificaciones
- Ficha Tecnica de Tuberia JupiterDocumento2 páginasFicha Tecnica de Tuberia Jupitersalvador GarciaAún no hay calificaciones
- Casita Antañona - GuionDocumento3 páginasCasita Antañona - GuionSamuel S.Aún no hay calificaciones
- Funcionamiento de Las Autoclaves en La Esterilización de EquipoDocumento5 páginasFuncionamiento de Las Autoclaves en La Esterilización de EquipoChristian Alexandro Avila SeguraAún no hay calificaciones
- Funciones Del DbaDocumento2 páginasFunciones Del DbaMariela Terán0% (1)
- Sle5000-4000 Manual de Uso P y RDocumento212 páginasSle5000-4000 Manual de Uso P y RDanielaRestrepoGalvánAún no hay calificaciones
- Manejo FSM Cap1 120ppiDocumento13 páginasManejo FSM Cap1 120ppiManuel AlejandroAún no hay calificaciones
- Folleto SMRDocumento2 páginasFolleto SMRBlanca Bautista PérezAún no hay calificaciones
- 1 Transformacion de Formatos y DatumsDocumento8 páginas1 Transformacion de Formatos y DatumsJoel IdmeAún no hay calificaciones
- Registro de Tecnologia EducativaDocumento8 páginasRegistro de Tecnologia EducativalucasrsAún no hay calificaciones
- Cajeros de Un BancoDocumento24 páginasCajeros de Un BancoJosé BatistaAún no hay calificaciones
- Solicitud de Acceso, Comprobante - Universitat Oberta de Catalunya (UOC)Documento2 páginasSolicitud de Acceso, Comprobante - Universitat Oberta de Catalunya (UOC)holaasAún no hay calificaciones
- M0 S2 Normas de Comunicación Virtual PDFDocumento2 páginasM0 S2 Normas de Comunicación Virtual PDFMiguel Angel Michel AnayaAún no hay calificaciones
- Guia 1 Conceptos Asociados A La ComunicaciónDocumento7 páginasGuia 1 Conceptos Asociados A La ComunicaciónKaren Rodriguez100% (1)
- Estudio de Hidrología Losa-Esperanza BajaDocumento18 páginasEstudio de Hidrología Losa-Esperanza BajaMari DayAún no hay calificaciones
- Manifiesto Ágil - Valores, Características de Un Proceso Ágil y Métodos de Desarrollo ÁgilDocumento30 páginasManifiesto Ágil - Valores, Características de Un Proceso Ágil y Métodos de Desarrollo ÁgilWilson SalinasAún no hay calificaciones
- DesfribiladorDocumento3 páginasDesfribiladorCarlos AndrésAún no hay calificaciones
- Proyecto IntegradorDocumento27 páginasProyecto IntegradorLobo Lorq “Lobo mix XD” para ustedesAún no hay calificaciones
- Act. 3.1 Perspectiva Clásica de La Administración (Taylor y Fayol) Administracion CientíficaDocumento4 páginasAct. 3.1 Perspectiva Clásica de La Administración (Taylor y Fayol) Administracion CientíficaYeanny FríaAún no hay calificaciones
- Borrador Estudio TecnicoDocumento4 páginasBorrador Estudio TecnicoOscar ChicojAún no hay calificaciones
- Adalsus M2 - Soyhenry Mis Apuntes React JSDocumento16 páginasAdalsus M2 - Soyhenry Mis Apuntes React JS_adal_Aún no hay calificaciones
- PRACTICA CALIFICADA UNID. 4 DE LENGUAJE (1) 17 JulioDocumento4 páginasPRACTICA CALIFICADA UNID. 4 DE LENGUAJE (1) 17 JulioErika Melissa García ArceAún no hay calificaciones
- Bench MarkingDocumento9 páginasBench MarkingElishem ZuñigaAún no hay calificaciones
- Trabajo IndividualDocumento9 páginasTrabajo IndividualAxelAún no hay calificaciones
- PDF Doc E001 52420610621571Documento1 páginaPDF Doc E001 52420610621571STEFANI BUENDIAAún no hay calificaciones