También podría gustarte
- Resumen SparkDocumento2 páginasResumen SparkJair Francesco HcAún no hay calificaciones
- Spark 1Documento44 páginasSpark 1mauricio995Aún no hay calificaciones
- Completar en Los Campos Diseñados El Tema PropuestoDocumento9 páginasCompletar en Los Campos Diseñados El Tema PropuestoSolo NesTor QuispeAún no hay calificaciones
- 1.1 Introducción A SparkDocumento23 páginas1.1 Introducción A Sparkabel0% (1)
- Apache SparkDocumento11 páginasApache SparklquichimAún no hay calificaciones
- SSD SparkDocumento8 páginasSSD SparkJuan Manuel AlvaradoAún no hay calificaciones
- Spark Cluster Computing With Working SetsDocumento6 páginasSpark Cluster Computing With Working SetsAnibal Ignacio VenturaAún no hay calificaciones
- Ensayo Hadoop y SparkDocumento4 páginasEnsayo Hadoop y SparkKaren Jazmín Jiménez RodríguezAún no hay calificaciones
- Entregable 2 Arquitectura de LnformacionDocumento3 páginasEntregable 2 Arquitectura de LnformacionMIGUEL GARCIAAún no hay calificaciones
- Procesamiento de Datos Con Apache SparkDocumento7 páginasProcesamiento de Datos Con Apache SparksidenandoAún no hay calificaciones
- Presentacion Metodologias Graphos - WorkDocumento25 páginasPresentacion Metodologias Graphos - Workpato sbAún no hay calificaciones
- S02 ApacheSparkDocumento25 páginasS02 ApacheSparkSandra InfanteAún no hay calificaciones
- 1 - Introducción Spark Curso BIT (Medio)Documento25 páginas1 - Introducción Spark Curso BIT (Medio)Deogracias PlaudAún no hay calificaciones
- Nsdi12-Final138 en EsDocumento14 páginasNsdi12-Final138 en EsAlex gugolAún no hay calificaciones
- Hadoop Vs SparkDocumento21 páginasHadoop Vs SparkJamil CerezoAún no hay calificaciones
- Taller Big DataDocumento6 páginasTaller Big Datarocky albertoAún no hay calificaciones
- Actividad 6. Investigación SparkDocumento9 páginasActividad 6. Investigación SparkBeatriz C.FloresAún no hay calificaciones
- Herramientas Inteligencia ArtificialDocumento3 páginasHerramientas Inteligencia Artificialnancy cameloAún no hay calificaciones
- Caso de Estudio Framework SparkDocumento9 páginasCaso de Estudio Framework SparkSolo NesTor QuispeAún no hay calificaciones
- Presentacion Curso DatabricksDocumento27 páginasPresentacion Curso DatabricksLeonardo ChavezAún no hay calificaciones
- Clase 4 - Herramientas Big Data Nov 15Documento31 páginasClase 4 - Herramientas Big Data Nov 15anamar.prilopAún no hay calificaciones
- Spark HadoopDocumento7 páginasSpark HadoopJorge VásquezAún no hay calificaciones
- Ventajas de SparkDocumento2 páginasVentajas de SparkJoseRamirezAún no hay calificaciones
- Actividad 6. Investigación SparkDocumento9 páginasActividad 6. Investigación SparkBeatriz C.FloresAún no hay calificaciones
- Laboratorio 3Documento2 páginasLaboratorio 3Reynaldo RamírezAún no hay calificaciones
- Base de Datos Transaccional Usando Hive Sobre HadoopDocumento8 páginasBase de Datos Transaccional Usando Hive Sobre Hadoopfjmerchan21Aún no hay calificaciones
- Pregunta 2Documento3 páginasPregunta 2Keren Mejia HerreraAún no hay calificaciones
- Spark para DummiesDocumento6 páginasSpark para Dummiesjesusdaa1Aún no hay calificaciones
- Taller1 MiddlewaresDocumento4 páginasTaller1 Middlewaressamira ocampoAún no hay calificaciones
- Computación ParalelaDocumento9 páginasComputación Paralelajimer sayagoAún no hay calificaciones
- PDF DefinidoDocumento25 páginasPDF DefinidoAlejandro CorrealAún no hay calificaciones
- Práctica 2.1 Investigación Sobre HadoopDocumento6 páginasPráctica 2.1 Investigación Sobre Hadoopfredosanzz1999Aún no hay calificaciones
- Bbva Open4u Ebook Herramientas Visualizacion Datos PDFDocumento26 páginasBbva Open4u Ebook Herramientas Visualizacion Datos PDFMiguel MoyaAún no hay calificaciones
- Ecosistema Spark IntroDocumento87 páginasEcosistema Spark IntrosilAún no hay calificaciones
- CD - M8 AE1 Contenidos - 2023Documento12 páginasCD - M8 AE1 Contenidos - 2023li_sisayAún no hay calificaciones
- 03 Lectura ADocumento5 páginas03 Lectura Akathy MonteroAún no hay calificaciones
- Análisis de Hadoop y Map/ReduceDocumento12 páginasAnálisis de Hadoop y Map/ReducejessicapaumierAún no hay calificaciones
- Bases de Datos NoSQL Caso de Estudio Apa PDFDocumento12 páginasBases de Datos NoSQL Caso de Estudio Apa PDFsape2001Aún no hay calificaciones
- 00 Que Es Cassandra, Arquitectura Con DiagramasDocumento9 páginas00 Que Es Cassandra, Arquitectura Con DiagramasMariano TaboadaAún no hay calificaciones
- Exposicion CassandraDocumento14 páginasExposicion CassandraSergio Andres Muñoz0% (1)
- Foro 2 Moises JimenezDocumento2 páginasForo 2 Moises JimenezAdrián HerreraAún no hay calificaciones
- 1.2.1 Ecosistema HadoopDocumento33 páginas1.2.1 Ecosistema HadoopItalo Garrido AAún no hay calificaciones
- Ponentes CoreDocumento21 páginasPonentes CoreGuillermo RamblaAún no hay calificaciones
- Spark y DAG - 075005Documento6 páginasSpark y DAG - 075005toloka5654Aún no hay calificaciones
- Actividad 4Documento5 páginasActividad 4saturvinngAún no hay calificaciones
- Procesamiento Paralelo Con JPPFDocumento19 páginasProcesamiento Paralelo Con JPPFAndrés Felipe GalindoAún no hay calificaciones
- Teoria M4Documento41 páginasTeoria M4Luis Molina ReinosoAún no hay calificaciones
- Spark 2Documento46 páginasSpark 2mauricio995Aún no hay calificaciones
- CassandraDocumento12 páginasCassandraRosemary MontillaAún no hay calificaciones
- Separata 04Documento23 páginasSeparata 04Joaquín AlvaradoAún no hay calificaciones
- Ebook: Herramientas de Visualización de DatosDocumento26 páginasEbook: Herramientas de Visualización de DatosBBVA Innovation Center100% (1)
- Arquitectura Big DataDocumento11 páginasArquitectura Big DataTitoAún no hay calificaciones
- Programación Paralela Con Cuba, C++ y Unidades de GPUDocumento31 páginasProgramación Paralela Con Cuba, C++ y Unidades de GPUJoel Antonio Rosa MorilloAún no hay calificaciones
- Dask Distributed Project 1Documento26 páginasDask Distributed Project 1mauricio sarangoAún no hay calificaciones
- Curso Big Data (Tema 1)Documento32 páginasCurso Big Data (Tema 1)CORAL ALONSO JIMÉNEZAún no hay calificaciones
- Investigación de Bases de Datos de GrafosDocumento3 páginasInvestigación de Bases de Datos de GrafosJaime De la VegaAún no hay calificaciones
- Cierre PDFDocumento35 páginasCierre PDFJuan Antonio ZambranoAún no hay calificaciones
- 04 Arquitecturas Big DataDocumento23 páginas04 Arquitecturas Big DataEsteban100% (1)
- Apache HadoopDocumento14 páginasApache HadoopMauricio Alberto Arce Bolados0% (1)
- Programación en Pascal: Desde simples programas Pascal hasta aplicaciones de escritorio actuales con Base de Datos DEV-PASCAL, LAZARUS Y PASCAL N-IDEDe EverandProgramación en Pascal: Desde simples programas Pascal hasta aplicaciones de escritorio actuales con Base de Datos DEV-PASCAL, LAZARUS Y PASCAL N-IDEAún no hay calificaciones
- Ataque de CumpleañosDocumento20 páginasAtaque de CumpleañosAlex gugolAún no hay calificaciones
- Berndtssoncap6,7 en EsDocumento17 páginasBerndtssoncap6,7 en EsAlex gugolAún no hay calificaciones
- Práctica #13Documento1 páginaPráctica #13Alex gugolAún no hay calificaciones
- Baum2017 en EsDocumento5 páginasBaum2017 en EsAlex gugolAún no hay calificaciones
- Repaso ÁlgebraDocumento3 páginasRepaso ÁlgebraAlex gugolAún no hay calificaciones
- SanidadddddddddddddddddddDocumento5 páginasSanidadddddddddddddddddddAlex gugolAún no hay calificaciones
- Fracciones 2Documento2 páginasFracciones 2Alex gugolAún no hay calificaciones
- Lenguaje Ii Guía 3 Verano 2022Documento12 páginasLenguaje Ii Guía 3 Verano 2022Alex gugolAún no hay calificaciones
- 08 Habilidad Operativa (Práctica)Documento2 páginas08 Habilidad Operativa (Práctica)Alex gugolAún no hay calificaciones
- Guia de Tercero - Mayo-19-32Documento14 páginasGuia de Tercero - Mayo-19-32Alex gugolAún no hay calificaciones
- Algebra 5to Año JunioDocumento10 páginasAlgebra 5to Año JunioAlex gugolAún no hay calificaciones
- Identidades Trigonometricas de Arco Compuesto para Tercero de SecundariaDocumento17 páginasIdentidades Trigonometricas de Arco Compuesto para Tercero de SecundariaAlex gugolAún no hay calificaciones
- Resolucion de Triangulos Rectangulos para Tercero de SecundariaDocumento6 páginasResolucion de Triangulos Rectangulos para Tercero de SecundariaAlex gugolAún no hay calificaciones
- Lenguaje Ii Guía 1 Verano 2022Documento12 páginasLenguaje Ii Guía 1 Verano 2022Alex gugolAún no hay calificaciones
- Practica de RM Iii Bryce MiscelaneDocumento1 páginaPractica de RM Iii Bryce MiscelaneAlex gugol0% (1)
- Álgebra Guía 4 Anual 2023 - 16Documento3 páginasÁlgebra Guía 4 Anual 2023 - 16Alex gugolAún no hay calificaciones
- Geo. Analitica - Guía Anual 4 2023 - 16Documento3 páginasGeo. Analitica - Guía Anual 4 2023 - 16Alex gugolAún no hay calificaciones
- Lenguaje Ii Guía 2 Verano 2022Documento12 páginasLenguaje Ii Guía 2 Verano 2022Alex gugolAún no hay calificaciones
- Lenguaje 1 Guía 3 Intensivo 2021Documento12 páginasLenguaje 1 Guía 3 Intensivo 2021Alex gugolAún no hay calificaciones
- Matemática 1 Guía Anual 4 2023 - 16Documento3 páginasMatemática 1 Guía Anual 4 2023 - 16Alex gugolAún no hay calificaciones
- Geometría Plana Guía Anual 4 2023 - 16Documento3 páginasGeometría Plana Guía Anual 4 2023 - 16Alex gugolAún no hay calificaciones
- Trigonometria Guía 4 Anual 2023 - 16Documento3 páginasTrigonometria Guía 4 Anual 2023 - 16Alex gugolAún no hay calificaciones
- Química III Guía 2 Verano 2022Documento12 páginasQuímica III Guía 2 Verano 2022Alex gugolAún no hay calificaciones
- Algebra 4to Año JunioDocumento10 páginasAlgebra 4to Año JunioAlex gugolAún no hay calificaciones
- Raz Matematico I Guia Intensivo 2 2023 - 5Documento3 páginasRaz Matematico I Guia Intensivo 2 2023 - 5Alex gugolAún no hay calificaciones
- Algebra 3er Año JunioDocumento10 páginasAlgebra 3er Año JunioAlex gugolAún no hay calificaciones
- Química II Guía 2 Verano 2022Documento12 páginasQuímica II Guía 2 Verano 2022Alex gugolAún no hay calificaciones
- 002.algebra 1er Año DiciembreDocumento6 páginas002.algebra 1er Año DiciembreAlex gugolAún no hay calificaciones
- 002.algebra 2do Año DiciembreDocumento8 páginas002.algebra 2do Año DiciembreAlex gugolAún no hay calificaciones
- Biologia Ii Guia Verano 2 2021Documento12 páginasBiologia Ii Guia Verano 2 2021Alex gugolAún no hay calificaciones
- Instalar Windows XP Desde La RedDocumento6 páginasInstalar Windows XP Desde La Redcolbaip100% (9)
- VLAN 10 (192.168.10.0/24) - Fastethernet 0/0.10 VLAN 20 (192.168.20.0/24) - Fastethernet 0/0.20Documento6 páginasVLAN 10 (192.168.10.0/24) - Fastethernet 0/0.10 VLAN 20 (192.168.20.0/24) - Fastethernet 0/0.20Ferraz goAún no hay calificaciones
- RS900 Datasheet - SpanishDocumento6 páginasRS900 Datasheet - SpanishVENCEDOR0603Aún no hay calificaciones
- Docker. Introducción y Almacenamiento. PDFDocumento3 páginasDocker. Introducción y Almacenamiento. PDFGermán BlascoAún no hay calificaciones
- Procesador CuadroDocumento2 páginasProcesador Cuadrovictorbustos77mcAún no hay calificaciones
- 10.2.3.5 Lab - Configuring Stateless and Stateful DHCPv6Documento28 páginas10.2.3.5 Lab - Configuring Stateless and Stateful DHCPv6Dairo ortegaAún no hay calificaciones
- Trabajos de RedesDocumento34 páginasTrabajos de RedeseliasAún no hay calificaciones
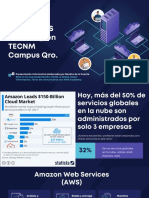
- Aws-Overview+1 en Es PDFDocumento95 páginasAws-Overview+1 en Es PDFJaime VasquezAún no hay calificaciones
- Es Ccna1 SLM v31Documento184 páginasEs Ccna1 SLM v31Patricio CordovaAún no hay calificaciones
- Antecedentes de La ComputadoraDocumento14 páginasAntecedentes de La ComputadoraCarolinaHdezSantarosaAún no hay calificaciones
- Server SoftguardDocumento6 páginasServer SoftguardOswaldo Merchan100% (1)
- Servidor DellDocumento2 páginasServidor DellAlondoFonnegraAún no hay calificaciones
- Linea Del Tiempo de WindowsDocumento17 páginasLinea Del Tiempo de WindowsFRANCKFOX0% (1)
- KV-NC32T DatasheetDocumento3 páginasKV-NC32T DatasheetWyatt MendezAún no hay calificaciones
- Hardware EstructuraDocumento19 páginasHardware Estructurayenyj100% (12)
- 02 Guía de LaboratorioDocumento2 páginas02 Guía de LaboratorioJHOSEP HINOSTROZA MANCCOAún no hay calificaciones
- Practica de Gestion de Redes Con WiresharkDocumento56 páginasPractica de Gestion de Redes Con WiresharkmiguedeozAún no hay calificaciones
- Presentación de La Vida de Bill GatesDocumento5 páginasPresentación de La Vida de Bill GatesJeremias Bustillo100% (1)
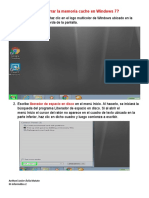
- Cómo Borrar La Memoria Cache en Windows 7Documento6 páginasCómo Borrar La Memoria Cache en Windows 7Javier MatuteAún no hay calificaciones
- Entregable 1 Redes PDFDocumento3 páginasEntregable 1 Redes PDFAlvaro Jesus Moreno IbarraAún no hay calificaciones
- AttachmentDocumento5 páginasAttachmentMaría Garulo ManzanoAún no hay calificaciones
- Informatica Requerimientos de SoDocumento6 páginasInformatica Requerimientos de SoLuis JavierAún no hay calificaciones
- Memoria No Volatil Lectura-EscrituraDocumento10 páginasMemoria No Volatil Lectura-EscrituraIan HerediaAún no hay calificaciones
- Sistema Operativo Micro Control Adores Pic RtosDocumento22 páginasSistema Operativo Micro Control Adores Pic RtosNereu OliveiraAún no hay calificaciones
- VMware y VMware VSphereDocumento20 páginasVMware y VMware VSphereVictor Sevillano100% (1)
- AWS Academy-IntroDocumento9 páginasAWS Academy-IntroSandra de la FuenteAún no hay calificaciones
- Actividad 1 Leccion 1Documento2 páginasActividad 1 Leccion 1Hernan Izurieta GreffAún no hay calificaciones
- Plan Computacion 2022Documento6 páginasPlan Computacion 2022Roxana Mamani TitoAún no hay calificaciones
- Registro Procesador 8086Documento1 páginaRegistro Procesador 8086Paola RiveraAún no hay calificaciones
- CLASE 2-La Placa MadreDocumento25 páginasCLASE 2-La Placa MadreMiguel EnigmahAún no hay calificaciones