También podría gustarte
- 10 Patrones de Velas Japonesas Con Acción de Precios - FUTUROS TRADINGDocumento24 páginas10 Patrones de Velas Japonesas Con Acción de Precios - FUTUROS TRADINGDavid Ayala100% (1)
- Informe Económico y Social de Santa Cruz Sep 2023 SHDocumento70 páginasInforme Económico y Social de Santa Cruz Sep 2023 SHDavid AyalaAún no hay calificaciones
- p3 Analisis de Regesion Lineal Cipas 4Documento14 páginasp3 Analisis de Regesion Lineal Cipas 4Maria Fernanda Bermudez100% (2)
- Mat200 Guia Ejercicios N7 Función LogaritmicaDocumento14 páginasMat200 Guia Ejercicios N7 Función LogaritmicaBastian Fuentes PinoAún no hay calificaciones
- Lección 1. Velas Japonesas - Fundamentos BásicosDocumento12 páginasLección 1. Velas Japonesas - Fundamentos BásicosDavid AyalaAún no hay calificaciones
- Tema 6 Heterocedasticidad Multicolinealidad y AutocorrelaciónDocumento25 páginasTema 6 Heterocedasticidad Multicolinealidad y AutocorrelaciónYedhi FloresAún no hay calificaciones
- Ejercisios Capitulo 4 Produccion 1 II ParcialDocumento45 páginasEjercisios Capitulo 4 Produccion 1 II ParcialRocy Sánchez GarcíaAún no hay calificaciones
- TCC. ESTADISTICA INF. Prob y Est Intervalos, Pruebas, R L y Multiple 2021Documento16 páginasTCC. ESTADISTICA INF. Prob y Est Intervalos, Pruebas, R L y Multiple 2021DISTRIPAGOS MYMAún no hay calificaciones
- 1.1 Pruebas de Hipótesis en Regresión Lineal MúltipleDocumento16 páginas1.1 Pruebas de Hipótesis en Regresión Lineal MúltipleAntonio Palomares Diaz44% (9)
- Tema 8 - Correlación - Teoría y PrácticaDocumento26 páginasTema 8 - Correlación - Teoría y PrácticaDavid AyalaAún no hay calificaciones
- Grupo de LorentzDocumento6 páginasGrupo de LorentzMateo Andres Duran BarrazaAún no hay calificaciones
- Matrices de Transformación HomogéneaDocumento17 páginasMatrices de Transformación HomogéneaJhonatan Kevin OrozaAún no hay calificaciones
- Teoria LogaritmoDocumento2 páginasTeoria Logaritmocesar_al31_312184795Aún no hay calificaciones
- Ayudantia 10Documento4 páginasAyudantia 10pedroAún no hay calificaciones
- Ayudantia 08 MAT-022 2022-2Documento9 páginasAyudantia 08 MAT-022 2022-2Oscar ValverdeAún no hay calificaciones
- IV BIM - 5to. Año - ALG - Guía 1 - LogaritmosDocumento8 páginasIV BIM - 5to. Año - ALG - Guía 1 - LogaritmosAnnthonny Roman De La CruzAún no hay calificaciones
- Apunte Curvas y SuperficiesDocumento37 páginasApunte Curvas y SuperficiesRBAún no hay calificaciones
- Ejercicios de Logaritmos para Quinto de SecundariaDocumento5 páginasEjercicios de Logaritmos para Quinto de SecundariaAbigail CalderonAún no hay calificaciones
- Experimento AmortiguamientoDocumento2 páginasExperimento AmortiguamientoDunia CortezAún no hay calificaciones
- Operadores No Acotados en Espacios de HilbertDocumento34 páginasOperadores No Acotados en Espacios de HilbertLEVA CORDOVA DIEGOAún no hay calificaciones
- QUINTODocumento8 páginasQUINTOJhordick Paul Navarrete AtocheAún no hay calificaciones
- Pendulo Dinámica USMDocumento4 páginasPendulo Dinámica USMVictor Reyes VidalAún no hay calificaciones
- Laboratorio PenduloDocumento3 páginasLaboratorio PenduloAlejandro Medina JimenezAún no hay calificaciones
- Clase 2Documento28 páginasClase 2Guillermo Angulo NiquenAún no hay calificaciones
- DivisibilidadDocumento11 páginasDivisibilidadJCamposanoGC0% (1)
- Logaritmos - STAGE10Documento8 páginasLogaritmos - STAGE10Jarom Maldonado ChavezAún no hay calificaciones
- A8 PautaDocumento4 páginasA8 PautapedroAún no hay calificaciones
- Optimización RestrictivaDocumento8 páginasOptimización RestrictivaJHYMY EDU SANCHEZ GIRONAún no hay calificaciones
- 2.1 - Técnicas de Estática ComparativaDocumento65 páginas2.1 - Técnicas de Estática ComparativaLucas figueroaAún no hay calificaciones
- Lab Cali Inter 2022Documento8 páginasLab Cali Inter 2022Nikol CubidesAún no hay calificaciones
- 2013 Integracion Estocastica PDFDocumento84 páginas2013 Integracion Estocastica PDFvrubio66Aún no hay calificaciones
- ME Simulación 3Documento3 páginasME Simulación 3JP ZeladaAún no hay calificaciones
- LogaritmosDocumento8 páginasLogaritmosEsperanza ElizondoAún no hay calificaciones
- Examen Parcial 02 - Análisis SismorresistenteDocumento9 páginasExamen Parcial 02 - Análisis SismorresistenteJeancarlos Lopez BalladaresAún no hay calificaciones
- Movimiento - Armónico - Simple - y - Oscilador - AmortiguadoDocumento6 páginasMovimiento - Armónico - Simple - y - Oscilador - Amortiguadolaura mariñoAún no hay calificaciones
- FuncionesDocumento5 páginasFuncioneskimberlyAún no hay calificaciones
- DivisibilidadDocumento8 páginasDivisibilidadWalter Hancco100% (1)
- Derivadas AplicacionesDocumento31 páginasDerivadas AplicacionesRobertusGonsaresuAún no hay calificaciones
- Aplicaciones de Las Transformadas de LaplaceDocumento15 páginasAplicaciones de Las Transformadas de LaplaceCoutsilver HsAún no hay calificaciones
- 12 LimitesTrigonometricosDocumento3 páginas12 LimitesTrigonometricosMelissa ValenciaAún no hay calificaciones
- Informe Pendulo. Lab de FisicaDocumento4 páginasInforme Pendulo. Lab de Fisicapinto23.gabyAún no hay calificaciones
- Tiempo de ResidenciaDocumento4 páginasTiempo de ResidenciaShirley Andrea ChambiAún no hay calificaciones
- Modelo DinamicoDocumento18 páginasModelo DinamicoSTEFANO CALDERONAún no hay calificaciones
- Tema 22Documento23 páginasTema 22borjalopeznavaroAún no hay calificaciones
- Examen Parcial - Versión 2Documento1 páginaExamen Parcial - Versión 2Jonel Hector Cuchula TaypeAún no hay calificaciones
- Lecture 11 Cointegracion VECM PreliminarDocumento32 páginasLecture 11 Cointegracion VECM PreliminarAlissa MonteroAún no hay calificaciones
- Pauta PR1Documento2 páginasPauta PR1Tienda KendraAún no hay calificaciones
- Movimiento AmortiguadoDocumento3 páginasMovimiento Amortiguadojulian arangurenAún no hay calificaciones
- Lab Cali Inter 2022-IDocumento9 páginasLab Cali Inter 2022-INikol CubidesAún no hay calificaciones
- Clase 9Documento19 páginasClase 9Jose Carlos Torres LopezAún no hay calificaciones
- Variable Dependiente LimitadaDocumento23 páginasVariable Dependiente LimitadaDiego MedranoAún no hay calificaciones
- Tarea - Logaritmos 2Documento5 páginasTarea - Logaritmos 2Jose DanielAún no hay calificaciones
- Wuolah Free SOL4Documento7 páginasWuolah Free SOL4SilviaAún no hay calificaciones
- Ejercicios - Propiedades de La DTFDocumento8 páginasEjercicios - Propiedades de La DTFCarlos MarínAún no hay calificaciones
- Curvas, Superficies, IntegralesDocumento47 páginasCurvas, Superficies, IntegralesGreta Jazmín LigatoAún no hay calificaciones
- Integración Numérica 5.1 La Regla Del TrapecioDocumento13 páginasIntegración Numérica 5.1 La Regla Del TrapecioGarcía Díaz Abdiel EnriqueAún no hay calificaciones
- Ejercicios 17112022 SolDocumento6 páginasEjercicios 17112022 SolPablo JordáAún no hay calificaciones
- Taller Parcial Especiales c3Documento1 páginaTaller Parcial Especiales c3quetzaliochanAún no hay calificaciones
- Clase 17. Funciones Vectoriales y Curvas Paramétricas en El EspacioDocumento5 páginasClase 17. Funciones Vectoriales y Curvas Paramétricas en El EspacioJuanpablo bolañosAún no hay calificaciones
- 13 LogaritmosDocumento7 páginas13 LogaritmosBenjamín AlejandroAún no hay calificaciones
- Qui 5to SM Cap15Documento15 páginasQui 5to SM Cap15Nadia PajueloAún no hay calificaciones
- Clase 8 - Cinemática Directa, Inversa y OdometríaDocumento22 páginasClase 8 - Cinemática Directa, Inversa y OdometríaL.RobledoAún no hay calificaciones
- Ejemplo T2 en R4Documento4 páginasEjemplo T2 en R4Isaac Hasse ArmengolAún no hay calificaciones
- ppt7 Teorema de Rolle y Teorema Del Valor MedioDocumento11 páginasppt7 Teorema de Rolle y Teorema Del Valor MedioJuan Miguel Aquije IncaAún no hay calificaciones
- Convolución de Funciones y Evaluación Por Métodos Numéricos y La Transformada de LaplaceDocumento13 páginasConvolución de Funciones y Evaluación Por Métodos Numéricos y La Transformada de LaplaceEduardo PastorAún no hay calificaciones
- PASO 1 - Robotica AvanzadaDocumento15 páginasPASO 1 - Robotica Avanzadacristian camilo contreras diazAún no hay calificaciones
- EDO Exacta eDXDocumento52 páginasEDO Exacta eDXDavid AyalaAún no hay calificaciones
- Dynamic ModelsDocumento16 páginasDynamic ModelsDavid AyalaAún no hay calificaciones
- (P2-4) Modelos de ProbabilidadDocumento15 páginas(P2-4) Modelos de ProbabilidadDavid AyalaAún no hay calificaciones
- Procedimientos GraficosDocumento10 páginasProcedimientos GraficosDavid AyalaAún no hay calificaciones
- Otros Tipos EDOs eDXDocumento58 páginasOtros Tipos EDOs eDXDavid AyalaAún no hay calificaciones
- Protocolo fusionBDD EHv2Documento5 páginasProtocolo fusionBDD EHv2David AyalaAún no hay calificaciones
- ¿Permanecerá Alta La InflaciónDocumento12 páginas¿Permanecerá Alta La InflaciónDavid AyalaAún no hay calificaciones
- S23T43 Spanish HandoutDocumento22 páginasS23T43 Spanish HandoutDavid AyalaAún no hay calificaciones
- S26E4 Spanish 2016Documento2 páginasS26E4 Spanish 2016David AyalaAún no hay calificaciones
- INSTRUCTIVO EH2019 Uies2Documento6 páginasINSTRUCTIVO EH2019 Uies2David AyalaAún no hay calificaciones
- Relación de Largo Plazo Entre Los Cambios Del Salario Mínimo y LoDocumento43 páginasRelación de Largo Plazo Entre Los Cambios Del Salario Mínimo y LoDavid AyalaAún no hay calificaciones
- Para MardokwnDocumento38 páginasPara MardokwnDavid AyalaAún no hay calificaciones
- Salrio Real y Sistema FiancieroDocumento140 páginasSalrio Real y Sistema FiancieroDavid AyalaAún no hay calificaciones
- Los Festivales Bc3adblicos de OtoñoDocumento6 páginasLos Festivales Bc3adblicos de OtoñoDavid AyalaAún no hay calificaciones
- Calidad de Salud en BucaramgaDocumento12 páginasCalidad de Salud en BucaramgaDavid AyalaAún no hay calificaciones
- Las Claves Del Éxito de La Política Social en Bolivia - CELAGDocumento7 páginasLas Claves Del Éxito de La Política Social en Bolivia - CELAGDavid AyalaAún no hay calificaciones
- Reporte Económico de Bolivia. Evolución Salarial 2008-2017 - CELAGDocumento5 páginasReporte Económico de Bolivia. Evolución Salarial 2008-2017 - CELAGDavid AyalaAún no hay calificaciones
- SeñoreajeDocumento3 páginasSeñoreajeDavid AyalaAún no hay calificaciones
- Modelos ARMA y ARIMADocumento10 páginasModelos ARMA y ARIMADavid AyalaAún no hay calificaciones
- Glosario de Términos LaboralesDocumento16 páginasGlosario de Términos LaboralesDavid AyalaAún no hay calificaciones
- DT Junio Wanderley Avances y Desafios Sociales y Laborales 1Documento49 páginasDT Junio Wanderley Avances y Desafios Sociales y Laborales 1David AyalaAún no hay calificaciones
- Lección 4. Estrategias de Velas JaponesasDocumento8 páginasLección 4. Estrategias de Velas JaponesasDavid AyalaAún no hay calificaciones
- Los Indicadores EducativosDocumento13 páginasLos Indicadores EducativosDavid AyalaAún no hay calificaciones
- Notas de Clase Econometria IIDocumento119 páginasNotas de Clase Econometria IIDavid Ayala0% (1)
- Pruebas de Hipótesis MRLDocumento29 páginasPruebas de Hipótesis MRLDavid AyalaAún no hay calificaciones
- Estadistica Actividad 4Documento10 páginasEstadistica Actividad 4Mariano BarbosaAún no hay calificaciones
- La Ley de Los Pequeños NumerosDocumento12 páginasLa Ley de Los Pequeños NumerosFlorencia ChiaffitellaAún no hay calificaciones
- 16 Unad Examenes Estadistica DescriptivaDocumento11 páginas16 Unad Examenes Estadistica DescriptivaHéctor Armando Valderrama BaqueroAún no hay calificaciones
- Ex Mat2 Jun02 1S DepDocumento6 páginasEx Mat2 Jun02 1S DepJuan Francisco GarciaAún no hay calificaciones
- Estadística ParamétricaDocumento36 páginasEstadística ParamétricaAlan Fernando Arroyo JimenezAún no hay calificaciones
- Elasticidad EstimacionDocumento29 páginasElasticidad EstimacionAurora NarvaezAún no hay calificaciones
- TRATAMIENTO Informe #2 Fisica GeneralDocumento27 páginasTRATAMIENTO Informe #2 Fisica GeneralGianella Zoraya Torres AscurraAún no hay calificaciones
- Cómo Analizar La Regresión Lineal Múltiple en 4 PasosDocumento3 páginasCómo Analizar La Regresión Lineal Múltiple en 4 Pasospetha90Aún no hay calificaciones
- Analisis de Un ExperimentoDocumento10 páginasAnalisis de Un ExperimentoJuan Mauro ForeroAún no hay calificaciones
- CP 3.act 12Documento2 páginasCP 3.act 12Jorge GonzálezAún no hay calificaciones
- Pensum Estadìstica IIDocumento5 páginasPensum Estadìstica IIAle MejiaAún no hay calificaciones
- Tarea-9 NNDocumento26 páginasTarea-9 NNNicole NelsonAún no hay calificaciones
- Estimadores de Minimos Cuadrados OrdinariosDocumento7 páginasEstimadores de Minimos Cuadrados OrdinariosAlexandra TandazoAún no hay calificaciones
- Practica de Colorimetría Con Sulfato de CobreDocumento7 páginasPractica de Colorimetría Con Sulfato de CobreValentinaAún no hay calificaciones
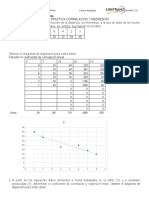
- Practica Correlación Y Regresión #De Clientes (X) 8 7 6 4 2 1 Distancia (Y) 15 19 25 23 34 40Documento6 páginasPractica Correlación Y Regresión #De Clientes (X) 8 7 6 4 2 1 Distancia (Y) 15 19 25 23 34 40marco pAún no hay calificaciones
- Modelos ARX, ARMAX, Output-Error y Box-JenkinsDocumento3 páginasModelos ARX, ARMAX, Output-Error y Box-Jenkinsjonatan patiñoAún no hay calificaciones
- Informe Fisica III - Movimiento AmortiguadoDocumento4 páginasInforme Fisica III - Movimiento Amortiguadoluis angel moreno peñaAún no hay calificaciones
- Valoración ForestalDocumento7 páginasValoración ForestalGianmarcoGoycocheaCasas100% (1)
- Investigación Tipos de Modelos MultivariadosDocumento1 páginaInvestigación Tipos de Modelos Multivariadosbojorquez.godfredoAún no hay calificaciones
- Calculo Aplicado Hughes Hallett and Glea-395-399Documento5 páginasCalculo Aplicado Hughes Hallett and Glea-395-399Julio Nicolas Polo MoralesAún no hay calificaciones
- Diagrama de CorrelacionDocumento50 páginasDiagrama de CorrelacionAndres Rodriguez67% (3)
- Regresion LinealDocumento15 páginasRegresion LinealFernando Marquez ZubietaAún no hay calificaciones
- Tarea 01 Estadistica Ing Sistemas UmgDocumento15 páginasTarea 01 Estadistica Ing Sistemas UmgWilmerAún no hay calificaciones
- Taller Minimo Cuadrados OrdinariosDocumento3 páginasTaller Minimo Cuadrados OrdinariosTatiana Erazo100% (1)
- Chapra 490 526Documento37 páginasChapra 490 526Anonymous JMUMC8a3Aún no hay calificaciones