También podría gustarte
- Estadística inferencial aplicadaDe EverandEstadística inferencial aplicadaCalificación: 5 de 5 estrellas5/5 (1)
- Bioestadística: Medidas de PosiciónDocumento24 páginasBioestadística: Medidas de PosiciónAngela CumpaAún no hay calificaciones
- Medidas de PosiciónDocumento6 páginasMedidas de PosiciónLiamelAún no hay calificaciones
- Tipos de Medida en EstadisticaDocumento29 páginasTipos de Medida en EstadisticaAnthony Calderón AquiñoAún no hay calificaciones
- Medidas de Posición RelativaDocumento12 páginasMedidas de Posición RelativaAmerica EMAún no hay calificaciones
- Sauceda Heydi U2T1a6Documento9 páginasSauceda Heydi U2T1a6May Sauceda GonzalezAún no hay calificaciones
- Segunda Unidad Parte 3 Estadística I 2020Documento16 páginasSegunda Unidad Parte 3 Estadística I 2020Emmanuel AcebedoAún no hay calificaciones
- Medidas de PosiciónDocumento2 páginasMedidas de PosiciónDelia RivarolaAún no hay calificaciones
- Cuartiles Deciles PercentilesDocumento39 páginasCuartiles Deciles PercentilesAlejandrina De BoutaudAún no hay calificaciones
- 04 Los CuantilesDocumento25 páginas04 Los CuantilesJosé Justiniano Pérez CarbajalAún no hay calificaciones
- CUANTILOSDocumento7 páginasCUANTILOSKevGom MirAún no hay calificaciones
- Guia-4 Estadística Ejercicios Resueltos y PropuestosDocumento10 páginasGuia-4 Estadística Ejercicios Resueltos y Propuestosdragonrojo1964Aún no hay calificaciones
- CUARTILESDocumento9 páginasCUARTILESAndrea Rojas CamargoAún no hay calificaciones
- CuantilesDocumento10 páginasCuantilesChristian SupeAún no hay calificaciones
- Guia de Laboratorio 4 Medidas de PosicionDocumento19 páginasGuia de Laboratorio 4 Medidas de PosicionProfe JamesAún no hay calificaciones
- Medidas de Posicion UtsDocumento6 páginasMedidas de Posicion Utslucho20021Aún no hay calificaciones
- Percentiles Cuartiles DecilesDocumento5 páginasPercentiles Cuartiles DecilesDarwhyn SabinoAún no hay calificaciones
- Distribuciones de FrecuenciasDocumento6 páginasDistribuciones de FrecuenciasSANTIAGO ADALBERTO PEREZ RIVERAAún no hay calificaciones
- Semana 07 - AQPDocumento8 páginasSemana 07 - AQPalexander pumacharaAún no hay calificaciones
- Medidas de Tendencia Central y de PosicinDocumento11 páginasMedidas de Tendencia Central y de PosicinFlorencia De SanctisAún no hay calificaciones
- Estadísticos de PosiciónDocumento11 páginasEstadísticos de PosiciónWilson CuburAún no hay calificaciones
- Ficha Medidas de Localizacion para Datos Agrupados IiDocumento10 páginasFicha Medidas de Localizacion para Datos Agrupados IiBL EPAún no hay calificaciones
- Medidas de Centralidad y de Posicion (Portafolio)Documento29 páginasMedidas de Centralidad y de Posicion (Portafolio)estrellapathAún no hay calificaciones
- Estadística y Prob Semana 4Documento54 páginasEstadística y Prob Semana 4Jhenny Sebastian TacucheAún no hay calificaciones
- C04 Medidas Tendencia02Documento12 páginasC04 Medidas Tendencia02ASLY CAMILA SOLARTE DELGADOAún no hay calificaciones
- Separata #03 Estadisticos Tendencia CentralDocumento6 páginasSeparata #03 Estadisticos Tendencia CentralGuina HuancaAún no hay calificaciones
- Ejercicios Resueltos de CuartilesDocumento14 páginasEjercicios Resueltos de Cuartileslobitooooo86% (7)
- Travajo de EstadisticaDocumento19 páginasTravajo de EstadisticaByll Alonso BernardoAún no hay calificaciones
- MEDIDAS DE POSICIÓN EstadísticaDocumento5 páginasMEDIDAS DE POSICIÓN EstadísticaJavier Ruiz SuarezAún no hay calificaciones
- Quartiles, Percentiles, DecilesDocumento7 páginasQuartiles, Percentiles, DecilesCristian AristizabalAún no hay calificaciones
- Ejercicio Ok - 28Documento9 páginasEjercicio Ok - 28German PinchaoAún no hay calificaciones
- Qué Son Los PercentilesDocumento6 páginasQué Son Los PercentilesMaglia TorresAún no hay calificaciones
- Medidas de Tendencias No Centralesq, D y P.Documento4 páginasMedidas de Tendencias No Centralesq, D y P.Angel ParedesAún no hay calificaciones
- Clase de Medidas de Tendencia CentralDocumento28 páginasClase de Medidas de Tendencia CentralLuis SRAún no hay calificaciones
- Guia 05 - AQPDocumento7 páginasGuia 05 - AQPdiego GSAún no hay calificaciones
- Cuestionario. Unidad #4Documento13 páginasCuestionario. Unidad #4Althur MatosAún no hay calificaciones
- Cuartil, Decil y PercentilDocumento7 páginasCuartil, Decil y Percentilmaryoris muñozAún no hay calificaciones
- Medidas de PosiciónDocumento15 páginasMedidas de PosiciónMagdalena VilarAún no hay calificaciones
- Matemática 8°básico Unidad9 Guía17 EstadísticaDocumento11 páginasMatemática 8°básico Unidad9 Guía17 EstadísticaNicolas ContrerasAún no hay calificaciones
- Unidad 2 6sem (2019) MEDIDAS DE POSICIÓNokDocumento29 páginasUnidad 2 6sem (2019) MEDIDAS DE POSICIÓNokJoséAún no hay calificaciones
- Cartilla Tabulación y Ordenación de Datos PDFDocumento8 páginasCartilla Tabulación y Ordenación de Datos PDFLEYDI CAROLINA ORJUELA SALAZARAún no hay calificaciones
- Guia N°3 - EstadigrafosDocumento7 páginasGuia N°3 - EstadigrafosJuan Sebastian Martinez CasasAún no hay calificaciones
- Estadistica Obtencion de Medidas de Tendencia CentralDocumento13 páginasEstadistica Obtencion de Medidas de Tendencia Centralernie brownieAún no hay calificaciones
- Escala PercentilarDocumento10 páginasEscala PercentilarJuan Carlos ReyesAún no hay calificaciones
- 8-Medidas de Posicionamiento CDPDocumento29 páginas8-Medidas de Posicionamiento CDPJoel JcantoralAún no hay calificaciones
- Como Calcular Medidas Distribucion Fractiles 6449 CompletoDocumento12 páginasComo Calcular Medidas Distribucion Fractiles 6449 CompletoLuis Alberto IzarraAún no hay calificaciones
- Clase Del Martes 1 SepDocumento7 páginasClase Del Martes 1 SepLINA MARIU CABEZAAS CLAVIJOAún no hay calificaciones
- Medidas de Posición No CentralesDocumento12 páginasMedidas de Posición No CentralesClaudiaAún no hay calificaciones
- Medidas de PosicionDocumento44 páginasMedidas de PosicionShiomara PicoAún no hay calificaciones
- Cuartiles, Deciles y Porcentiles Trabajo GrupalDocumento8 páginasCuartiles, Deciles y Porcentiles Trabajo GrupalIvanova GonzálezAún no hay calificaciones
- S04.s1 - Mediadas de PosiciónDocumento21 páginasS04.s1 - Mediadas de PosiciónJuniorJ.PeveDiazAún no hay calificaciones
- Guía # 7 10 Virtual CEC.Documento13 páginasGuía # 7 10 Virtual CEC.Juan OlaAún no hay calificaciones
- Guia de Estudio U II Distribucion de FrecuenciasDocumento9 páginasGuia de Estudio U II Distribucion de FrecuenciasGREGORY PEINADOAún no hay calificaciones
- Semana 11-Medidas de Posición-2022-20Documento36 páginasSemana 11-Medidas de Posición-2022-20Rhau Ramiell Granados SaboyaAún no hay calificaciones
- Medidas de PosicionDocumento28 páginasMedidas de PosicionAdriana Abigail Gómez GaliciaAún no hay calificaciones
- Distribución de FrecuenciasDocumento4 páginasDistribución de FrecuenciasFranklin JiménezAún no hay calificaciones
- CuartilesDocumento20 páginasCuartilesJosceline Mieles ConstanteAún no hay calificaciones
- Replanteo y preparación de tuberías. IMAI0108De EverandReplanteo y preparación de tuberías. IMAI0108Aún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
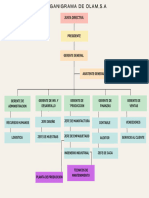
- Junta DirectivaDocumento1 páginaJunta DirectivaDOLORES PEREZAún no hay calificaciones
- Caso No 5 FerreteriaDocumento14 páginasCaso No 5 FerreteriaDOLORES PEREZAún no hay calificaciones
- 7ClaseAdmonIII04032023GtosHistóricos y ContinuoDocumento29 páginas7ClaseAdmonIII04032023GtosHistóricos y ContinuoDOLORES PEREZAún no hay calificaciones
- Análisis de La Evolución de La MercadotecniaDocumento1 páginaAnálisis de La Evolución de La MercadotecniaDOLORES PEREZAún no hay calificaciones
- Documento de Apoyo TEMA No 7 Introducción A La Teoría de La ProbabilidadDocumento9 páginasDocumento de Apoyo TEMA No 7 Introducción A La Teoría de La ProbabilidadDOLORES PEREZAún no hay calificaciones
- Documento de Apoyo TEMA No 8 Probabilidad EnfoquesDocumento7 páginasDocumento de Apoyo TEMA No 8 Probabilidad EnfoquesMildre PadillaAún no hay calificaciones
- Documento de Apoyo TEMA No 12 Teorema de Bayes, Arbol de ProbabilidadDocumento8 páginasDocumento de Apoyo TEMA No 12 Teorema de Bayes, Arbol de ProbabilidadDOLORES PEREZAún no hay calificaciones