También podría gustarte
- Apunte Estadística EzeDocumento91 páginasApunte Estadística EzeEzequiel ZacañinoAún no hay calificaciones
- Tarea 2 Temas EstadísticosDocumento8 páginasTarea 2 Temas EstadísticosBryanMendzVnturaAún no hay calificaciones
- TEMA 4. Procedimiento AnaliticoDocumento16 páginasTEMA 4. Procedimiento Analiticoysabel carranzaAún no hay calificaciones
- Capitulo 8, CALIDADY PRODUCTIVIDADDocumento7 páginasCapitulo 8, CALIDADY PRODUCTIVIDADGiovanni ReynosoAún no hay calificaciones
- 4.6 y ConclusionesDocumento6 páginas4.6 y ConclusionesMa Guadalupe GAAún no hay calificaciones
- Estadística DescriptivaDocumento9 páginasEstadística Descriptivarosa caez velasquezAún no hay calificaciones
- Exploración y Análisis Del Concepto de Normalidad en EstadísticaDocumento16 páginasExploración y Análisis Del Concepto de Normalidad en Estadísticacuentacorriente2020Aún no hay calificaciones
- 04-10-2022 233125474 Sesion13Documento30 páginas04-10-2022 233125474 Sesion13ELIZABETH YULIANA MUÑOZ SOTELOAún no hay calificaciones
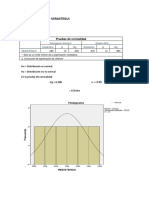
- Máxima Formación - Guía Definitiva para Encontrar La Prueba Estadística Que BuscasDocumento19 páginasMáxima Formación - Guía Definitiva para Encontrar La Prueba Estadística Que Buscaswhoyos21Aún no hay calificaciones
- Estadistica II EstudioDocumento212 páginasEstadistica II EstudioAmador Pensador0% (1)
- Recuperacion EstadisticaDocumento6 páginasRecuperacion EstadisticaAndres GamboaAún no hay calificaciones
- T de StudentDocumento10 páginasT de StudentAnderson MontalvoAún no hay calificaciones
- Guía Definitiva para Encontrar La Prueba Estadística Que BuscasDocumento8 páginasGuía Definitiva para Encontrar La Prueba Estadística Que BuscasJuan AlekAún no hay calificaciones
- Clase 4Documento31 páginasClase 4Mario RodriguezAún no hay calificaciones
- Estadistica MuestreoDocumento20 páginasEstadistica MuestreoEdith CruzAún no hay calificaciones
- Trabajo Final Estadistica IiDocumento15 páginasTrabajo Final Estadistica IianaAún no hay calificaciones
- Prueba Chi CuadradoDocumento24 páginasPrueba Chi CuadradoVelvet EscobarAún no hay calificaciones
- Lab 2Documento31 páginasLab 2Karen GallegosAún no hay calificaciones
- IutaDocumento7 páginasIutaYerwin YauriAún no hay calificaciones
- Trabajo MarioDocumento11 páginasTrabajo MariodulceAún no hay calificaciones
- Distribucion Muestral de La MediaDocumento20 páginasDistribucion Muestral de La MediaJoseph Michael 803Aún no hay calificaciones
- Analisi Exploratorio de DatosDocumento18 páginasAnalisi Exploratorio de DatosNicolCastilloAún no hay calificaciones
- Problemas Con Las Variables Explicativas, Problemas Con Los Parámetros, Variables Omitidas, Consecuencias Al Omitir Variables, Lemas Con Las VariabDocumento19 páginasProblemas Con Las Variables Explicativas, Problemas Con Los Parámetros, Variables Omitidas, Consecuencias Al Omitir Variables, Lemas Con Las VariabKelvin RamirezAún no hay calificaciones
- 2022-04-22 EstFnd Material Clase 11Documento7 páginas2022-04-22 EstFnd Material Clase 11xcuenta22Aún no hay calificaciones
- Tema 2......... IIDocumento11 páginasTema 2......... IIObed Joel Condori QuispeAún no hay calificaciones
- INFORME 09 MÉTODO-Análisis de La InformaciónDocumento8 páginasINFORME 09 MÉTODO-Análisis de La InformaciónRomina Verona AguilarAún no hay calificaciones
- Estadistica 2-1Documento8 páginasEstadistica 2-1Edgar FerrerAún no hay calificaciones
- Informe AnálisisDocumento6 páginasInforme AnálisisAnny OrtizAún no hay calificaciones
- Diseño de Experimentos de Chemitech-Edith-4DDocumento6 páginasDiseño de Experimentos de Chemitech-Edith-4DedithAún no hay calificaciones
- Existen Diferentes Medidas de LocalizaciónDocumento15 páginasExisten Diferentes Medidas de LocalizaciónolimpoAún no hay calificaciones
- MÉTODOS NO PARAMÉTRICOS FinalDocumento19 páginasMÉTODOS NO PARAMÉTRICOS Finalalvaro uribeAún no hay calificaciones
- Diseno de Experimentos Con SPSSDocumento19 páginasDiseno de Experimentos Con SPSSDario Santillan GarciaAún no hay calificaciones
- Practica III CalidadDocumento8 páginasPractica III CalidadmariaAún no hay calificaciones
- Cerps Unidad 2Documento9 páginasCerps Unidad 2Ma JoséAún no hay calificaciones
- 04 - Escobar, ChaidDocumento39 páginas04 - Escobar, ChaidFlo LópezAún no hay calificaciones
- Medidas de Sesgo y CurtosisDocumento7 páginasMedidas de Sesgo y CurtosisDany RubioAún no hay calificaciones
- Eleccion de La Prueba Estadistica AdecuadaDocumento21 páginasEleccion de La Prueba Estadistica Adecuadajuan pablo100% (2)
- Act. 1. Datos Agrupados y No AgrupadosDocumento7 páginasAct. 1. Datos Agrupados y No AgrupadosGeo CerezoAún no hay calificaciones
- Informe de Laboratorio N1antoDocumento18 páginasInforme de Laboratorio N1antoJOHN ALEX YUCRA LLACCTAAún no hay calificaciones
- Tabajo #5 - Probabilidad y EstadísticaDocumento13 páginasTabajo #5 - Probabilidad y EstadísticaSTEPHANI VERGARAAún no hay calificaciones
- Nociones Basicas y Analisis Descriptivo de Una Variable ESTADISTICADocumento12 páginasNociones Basicas y Analisis Descriptivo de Una Variable ESTADISTICANoheli CáceresAún no hay calificaciones
- Medidas de Tendencia Central.Documento18 páginasMedidas de Tendencia Central.Katalyna Morato CruzAún no hay calificaciones
- Estadistica 1Documento9 páginasEstadistica 1Maria Guadalupe Solorzano LunaAún no hay calificaciones
- Resumen Probabilidad y Estadística I 2°Documento12 páginasResumen Probabilidad y Estadística I 2°Miguel Angel López NavarreteAún no hay calificaciones
- Estadística Descriptiva e Inferencial: January 2013Documento13 páginasEstadística Descriptiva e Inferencial: January 2013Marie LinaAún no hay calificaciones
- Capitulo 0001 Introduccion Al Ade PDFDocumento17 páginasCapitulo 0001 Introduccion Al Ade PDFjeanAún no hay calificaciones
- Ensayo de Estadistica InferencialDocumento5 páginasEnsayo de Estadistica InferencialLiliana Arcia PortilloAún no hay calificaciones
- EstadescripDocumento17 páginasEstadescripeyravaughanAún no hay calificaciones
- Estadística Descriptiva e Inferencial: January 2013Documento13 páginasEstadística Descriptiva e Inferencial: January 2013Henry CrisostomoAún no hay calificaciones
- Tai EstadisticaDocumento21 páginasTai EstadisticaLuis Picón ArtigasAún no hay calificaciones
- Estadistica 2Documento18 páginasEstadistica 2BrendelbashnJoseDanielCarrasquelAún no hay calificaciones
- Sesion 1Documento17 páginasSesion 1Arturo Tipacti QuijanoAún no hay calificaciones
- Estadística InferencialDocumento4 páginasEstadística InferencialAlejandro ConstantinoAún no hay calificaciones
- Rigoberto - Ef1 - Probabilidad y EstadisticaDocumento10 páginasRigoberto - Ef1 - Probabilidad y EstadisticaRIGOBERTO MARIN OVIEDOAún no hay calificaciones
- Trabajo de Investigación Chi-CuadradaDocumento20 páginasTrabajo de Investigación Chi-CuadradaEsvin ZelayaAún no hay calificaciones
- Como Seleccionar Test EstadisticosDocumento4 páginasComo Seleccionar Test EstadisticosmonicaAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- El Metodo EstadísticoDocumento5 páginasEl Metodo Estadísticodiargoza2014Aún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Estadística para veterinarios y zootecnistasDe EverandEstadística para veterinarios y zootecnistasCalificación: 5 de 5 estrellas5/5 (1)
- Tipo de DatosDocumento4 páginasTipo de DatosMarco Romero XxM4rkoRxXAún no hay calificaciones
- Administraciòn Unidad1y2Documento36 páginasAdministraciòn Unidad1y2Marco Romero XxM4rkoRxXAún no hay calificaciones
- Tarea2 EnsayoDocumento14 páginasTarea2 EnsayoMarco Romero XxM4rkoRxXAún no hay calificaciones
- Actividad15 - Gestión de RiesgoDocumento16 páginasActividad15 - Gestión de RiesgoMarco Romero XxM4rkoRxXAún no hay calificaciones
- Administraciòn - Unidad 3 y 4Documento38 páginasAdministraciòn - Unidad 3 y 4Marco Romero XxM4rkoRxXAún no hay calificaciones
- Propuestas de ProyectosDocumento4 páginasPropuestas de ProyectosMarco Romero XxM4rkoRxXAún no hay calificaciones
- Actividad22 Equipo1Documento42 páginasActividad22 Equipo1Marco Romero XxM4rkoRxXAún no hay calificaciones
- Equipo 2Documento8 páginasEquipo 2Marco Romero XxM4rkoRxXAún no hay calificaciones
- Equipo2 TareaLargaDocumento23 páginasEquipo2 TareaLargaMarco Romero XxM4rkoRxXAún no hay calificaciones
- Actividad14 WireframeDocumento16 páginasActividad14 WireframeMarco Romero XxM4rkoRxXAún no hay calificaciones
- Front End (Back End EQUIPO1Documento17 páginasFront End (Back End EQUIPO1Marco Romero XxM4rkoRxXAún no hay calificaciones
- Equipo1 DrechosdeAutorDocumento22 páginasEquipo1 DrechosdeAutorMarco Romero XxM4rkoRxXAún no hay calificaciones
- Tutorial JadeDocumento43 páginasTutorial JadeMarco Romero XxM4rkoRxXAún no hay calificaciones
- Tarea Infecciones de Trasnmisión SexualDocumento22 páginasTarea Infecciones de Trasnmisión SexualMarco Romero XxM4rkoRxXAún no hay calificaciones
- Actividad 2 Derecho LaboralDocumento4 páginasActividad 2 Derecho LaboralMarco Romero XxM4rkoRxXAún no hay calificaciones
- Verbos CH, SH, X, O, SS MarcoRomeroMarquezDocumento2 páginasVerbos CH, SH, X, O, SS MarcoRomeroMarquezMarco Romero XxM4rkoRxX0% (1)
- Derecho Laboral Unidad 4Documento2 páginasDerecho Laboral Unidad 4Marco Romero XxM4rkoRxXAún no hay calificaciones
- Conceptos KattyDocumento6 páginasConceptos KattyMarco Romero XxM4rkoRxXAún no hay calificaciones
- Pruebas de La Bondad Del Ajuste y AnalisisDocumento4 páginasPruebas de La Bondad Del Ajuste y AnalisisMarco Romero XxM4rkoRxXAún no hay calificaciones
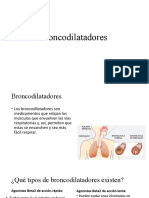
- Broncodilatadores KATYPRIEGODocumento8 páginasBroncodilatadores KATYPRIEGOMarco Romero XxM4rkoRxXAún no hay calificaciones
- Conceptos KatyDocumento6 páginasConceptos KatyMarco Romero XxM4rkoRxXAún no hay calificaciones
- Una Mirada Más Cercana Al Diseño Centrado en El Usuario - 1 ES - UnlockedDocumento11 páginasUna Mirada Más Cercana Al Diseño Centrado en El Usuario - 1 ES - UnlockedMarco Romero XxM4rkoRxXAún no hay calificaciones
- RomeroRodríguez AdaGuadalupe M22S2A3 Fase3Documento3 páginasRomeroRodríguez AdaGuadalupe M22S2A3 Fase3Marco Romero XxM4rkoRxXAún no hay calificaciones
- RomeroRodriguez AdaGuadalupe M22S3A6 Fase6Documento6 páginasRomeroRodriguez AdaGuadalupe M22S3A6 Fase6Marco Romero XxM4rkoRxXAún no hay calificaciones
- Matemáticas Aplicadas A La MercadotecniaDocumento11 páginasMatemáticas Aplicadas A La MercadotecniaMalu MoralesAún no hay calificaciones
- Probabilidades y EstadisticaDocumento4 páginasProbabilidades y EstadisticaGabriela MuñozAún no hay calificaciones
- Clase Repaso 1Documento6 páginasClase Repaso 1Anómimo desconocidoAún no hay calificaciones
- MODULO II Descripción de Datos - Medidas Numéricas-2Documento15 páginasMODULO II Descripción de Datos - Medidas Numéricas-2Orlando ChaconAún no hay calificaciones
- Tarea 5Documento7 páginasTarea 5Fisiko NuklearAún no hay calificaciones
- SEMANA 05 y 06 - PrácticaDocumento6 páginasSEMANA 05 y 06 - PrácticaKevin Calderon P.Aún no hay calificaciones
- T3 - Medidas de RiesgoDocumento25 páginasT3 - Medidas de RiesgorobertzeluAún no hay calificaciones
- Momentos, Sesgo y CurtosisDocumento15 páginasMomentos, Sesgo y CurtosisJoîz Vêrito100% (1)
- Ejercicios de AplicaciónDocumento5 páginasEjercicios de AplicaciónBryan Flores Mamani100% (3)
- 20 Regres..Documento41 páginas20 Regres..Dulce Rocío MotaAún no hay calificaciones
- Informe Final de Estadística Intervalos de ConfianzaDocumento48 páginasInforme Final de Estadística Intervalos de ConfianzaMagda Isabel Javier Villanueva100% (3)
- Regla EmpiricaDocumento3 páginasRegla Empiricaazucena obregonAún no hay calificaciones
- TEORIA DEL MUESTREO Muestras Aleatorias Errores enDocumento90 páginasTEORIA DEL MUESTREO Muestras Aleatorias Errores ennn357Aún no hay calificaciones
- Actividad de Puntos Evaluables - Escenario 2 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO B12)Documento3 páginasActividad de Puntos Evaluables - Escenario 2 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO B12)Duber Pineda67% (3)
- Taller Sobre Distribuciones de ProbabilidadDocumento8 páginasTaller Sobre Distribuciones de ProbabilidadAngie Peña perez0% (1)
- Test de Signo PDFDocumento9 páginasTest de Signo PDFjavier BandaAún no hay calificaciones
- Estadística Hipotesis Media N Grande y Valor PDocumento16 páginasEstadística Hipotesis Media N Grande y Valor PJESSICA TATIANA VARGAS CERONAún no hay calificaciones
- Propiedades EstadisticaDocumento2 páginasPropiedades EstadisticaJhonatan Henry Idrogo BustamanteAún no hay calificaciones
- Desviación FisherDocumento11 páginasDesviación FisherGastón Miranda García100% (2)
- Examen Estadistica - CotacheDocumento3 páginasExamen Estadistica - CotacheFiorelaAún no hay calificaciones
- Distribuciones de Probabilidad LPDocumento23 páginasDistribuciones de Probabilidad LPJuan Pablo RosalesAún no hay calificaciones
- Suavización Exponencial y Análisis de RegresiónDocumento23 páginasSuavización Exponencial y Análisis de RegresiónYenny Saltarin RamirezAún no hay calificaciones
- Problemas Unidad 5 BricioDocumento32 páginasProblemas Unidad 5 BriciocarlAún no hay calificaciones
- Taller N 3Documento5 páginasTaller N 3Pedro DavidAún no hay calificaciones
- Taller Segundo Corte - Estadística IiDocumento3 páginasTaller Segundo Corte - Estadística Iiyohadis esther santoya sarmientoAún no hay calificaciones
- Fase 4 Grupo 123Documento59 páginasFase 4 Grupo 123sebastianAún no hay calificaciones
- Distribuciones EspecialesDocumento54 páginasDistribuciones EspecialesNehilot Montañez CastroAún no hay calificaciones
- Abigail Callisaya Maita Bloque 2 2tDocumento2 páginasAbigail Callisaya Maita Bloque 2 2tAbigail CallisayaAún no hay calificaciones
- Unidad 4.1 - Probabilidad y Confiabilidad Básica 2020Documento37 páginasUnidad 4.1 - Probabilidad y Confiabilidad Básica 2020Isabel Cabrera SierraAún no hay calificaciones
- Trabajo Estadística NataDocumento4 páginasTrabajo Estadística NataNATMISAún no hay calificaciones