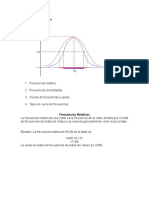
También podría gustarte
- Actividad 3 - Evaluativa. Estadistica DescriptivaDocumento6 páginasActividad 3 - Evaluativa. Estadistica DescriptivaAndrea CORREA REYESAún no hay calificaciones
- AlvarezSanchezDulceRosario InvestigacionDocumento15 páginasAlvarezSanchezDulceRosario InvestigacionRosalia TellezAún no hay calificaciones
- Gráficas y Curvas de Frecuencia (Estadística)Documento11 páginasGráficas y Curvas de Frecuencia (Estadística)Brayelis Rodriguez0% (1)
- FrecuenciaDocumento13 páginasFrecuenciaMaria ReyesAún no hay calificaciones
- ACTIVIDAD 3 Estadistica DescriptivaDocumento10 páginasACTIVIDAD 3 Estadistica DescriptivaPaola RodriguezAún no hay calificaciones
- Actividad Estadistica 3Documento9 páginasActividad Estadistica 3martaAún no hay calificaciones
- Distribucion de FrecuenciasDocumento11 páginasDistribucion de FrecuenciasSelvin Danilo QuiñonezAún no hay calificaciones
- A.2.1. Investigación Documental - LeonOlveraEmilioGeovanyDocumento13 páginasA.2.1. Investigación Documental - LeonOlveraEmilioGeovanyLeón Olvera Emilio GAún no hay calificaciones
- Preguntas Orientadoras Estadistica DescriptivaDocumento13 páginasPreguntas Orientadoras Estadistica Descriptivacarlos albertoAún no hay calificaciones
- Est Ad Is Tic ADocumento44 páginasEst Ad Is Tic AAngel RobledoAún no hay calificaciones
- Unidad1 - Fase 2Documento5 páginasUnidad1 - Fase 2sergio ovalleAún no hay calificaciones
- Actividad 3Documento8 páginasActividad 3Herminda Contreras VargasAún no hay calificaciones
- Histograma de FrecuenciasDocumento20 páginasHistograma de FrecuenciasJesus FernandezAún no hay calificaciones
- Tablas de Frecuencia - ArveloDocumento62 páginasTablas de Frecuencia - ArveloAngel Francisco Arvelo LujánAún no hay calificaciones
- ESTADISTICA Frecuencia, Media, Moda y MásDocumento9 páginasESTADISTICA Frecuencia, Media, Moda y MásRECKA67Aún no hay calificaciones
- Contenido Estadistica 3MDocumento15 páginasContenido Estadistica 3MSarita InfanteAún no hay calificaciones
- Resumen 1° Parcial de EstadisticaDocumento10 páginasResumen 1° Parcial de EstadisticaDy guarnieriAún no hay calificaciones
- Recolección y Organización de DatosDocumento15 páginasRecolección y Organización de Datoselmaster.emcy100% (2)
- Taller de EstadisticaDocumento11 páginasTaller de EstadisticaJh JjAún no hay calificaciones
- Cea D'Ancona - El Análisis de Los Datos ResumenDocumento6 páginasCea D'Ancona - El Análisis de Los Datos ResumenfrancotelescaAún no hay calificaciones
- Tabla de FrecuenciasDocumento13 páginasTabla de FrecuenciasNaileth Sinaiz CorderoAún no hay calificaciones
- Estadisticas Unidad 2Documento8 páginasEstadisticas Unidad 2Valdo CruzAún no hay calificaciones
- Unidad 2 de EstadísticaDocumento8 páginasUnidad 2 de EstadísticaAna Barbara RivasAún no hay calificaciones
- Fase-2-Identificación y Análisis de Variables EstadísticasDocumento7 páginasFase-2-Identificación y Análisis de Variables Estadísticasjohann roldanAún no hay calificaciones
- Qué Es Una Tabla PuntualDocumento3 páginasQué Es Una Tabla PuntualWilderBorges17Aún no hay calificaciones
- ATRIBUTOSDocumento4 páginasATRIBUTOSAngie BautistaAún no hay calificaciones
- Estadistica Tema 2Documento5 páginasEstadistica Tema 2Milauris LucianoAún no hay calificaciones
- HistogramaDocumento12 páginasHistogramaJaanett' GuzzmánnAún no hay calificaciones
- Graficos y Cuadros de Datos EstadisticosDocumento14 páginasGraficos y Cuadros de Datos EstadisticosA L E J A N D R AAún no hay calificaciones
- TAREA # 3 Distribución de Frecuencias y Su Representación GráficaDocumento15 páginasTAREA # 3 Distribución de Frecuencias y Su Representación GráficaCarlos HernandezAún no hay calificaciones
- Resumen Unidad 2 Primer ParcialDocumento5 páginasResumen Unidad 2 Primer ParcialMaria Cecilia RoblesAún no hay calificaciones
- Unidad 2 Resumen Completo Probabilidad y EstadísticaDocumento5 páginasUnidad 2 Resumen Completo Probabilidad y EstadísticadientesfornerisAún no hay calificaciones
- Tablas de Frecuencia Graficos Estadisticos ArveloDocumento62 páginasTablas de Frecuencia Graficos Estadisticos ArveloAdalberto SantiagoAún no hay calificaciones
- HISTOGRAMADocumento6 páginasHISTOGRAMAFrank StopAún no hay calificaciones
- Curvas de FrecuenciasDocumento13 páginasCurvas de FrecuenciasRodrigo GonzalezAún no hay calificaciones
- EXPERIMENTODocumento12 páginasEXPERIMENTORoberto TorrucoAún no hay calificaciones
- Estadística DescriptivaDocumento14 páginasEstadística DescriptivaCyber WebAún no hay calificaciones
- Actividad 3Documento15 páginasActividad 3Yei GarciaAún no hay calificaciones
- Histograma PDFDocumento4 páginasHistograma PDFAlejo Ticona100% (1)
- Esta Di SticaDocumento10 páginasEsta Di SticaMarce MosxqueraAún no hay calificaciones
- Informe de Histogrmas y Curvas de OjivaDocumento10 páginasInforme de Histogrmas y Curvas de OjivaEver AlcidesAún no hay calificaciones
- Cuestionario Estadistica DescriptivaDocumento6 páginasCuestionario Estadistica DescriptivaJhon CruzAún no hay calificaciones
- ESTADISTICADocumento21 páginasESTADISTICAalexa salinasAún no hay calificaciones
- Distribución de FrecuenciaDocumento7 páginasDistribución de FrecuenciaCristalHernandezAún no hay calificaciones
- GRAFICASDocumento9 páginasGRAFICASFernando OvandoAún no hay calificaciones
- Histogram ADocumento13 páginasHistogram ANorelys MaitaAún no hay calificaciones
- Unidad 1Documento62 páginasUnidad 1Antonio Ibarra VegaAún no hay calificaciones
- Carátula 2 (Separador)Documento15 páginasCarátula 2 (Separador)miguel angelAún no hay calificaciones
- Estadìstica DescriptivaDocumento7 páginasEstadìstica DescriptivaStudentguyAún no hay calificaciones
- 4 Distribución de FrecuenciasDocumento4 páginas4 Distribución de FrecuenciasJesus BaldeonAún no hay calificaciones
- Estadistica Descitiva - Paola GarzonDocumento9 páginasEstadistica Descitiva - Paola GarzonGarzon Culma Paola AndreaAún no hay calificaciones
- HISTOGRAMASDocumento3 páginasHISTOGRAMASDaniel JustinianoAún no hay calificaciones
- Organizacion de DatosDocumento6 páginasOrganizacion de DatosSophie RodríguezAún no hay calificaciones
- Histogramas y Diagramas de ParetoDocumento5 páginasHistogramas y Diagramas de ParetoCristyan SabillonAún no hay calificaciones
- Introduccion A La Estadistica Glosario 2Documento4 páginasIntroduccion A La Estadistica Glosario 2Bella DonnaAún no hay calificaciones
- EstadisticaDocumento5 páginasEstadisticakim genesisAún no hay calificaciones
- Histograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraDe EverandHistograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraAún no hay calificaciones
- Razonamiento cuantitativo, 2ª edición: Notas de claseDe EverandRazonamiento cuantitativo, 2ª edición: Notas de claseCalificación: 5 de 5 estrellas5/5 (1)
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Matemática AplicadaDocumento6 páginasMatemática Aplicadamaria100% (1)
- Ejercicios de Operaciones Con Matrices Sistemas de Ecuaciones Lineale1Documento15 páginasEjercicios de Operaciones Con Matrices Sistemas de Ecuaciones Lineale1mariaAún no hay calificaciones
- Elementos Que Conforman Una Red Típica de ComunicacionesDocumento10 páginasElementos Que Conforman Una Red Típica de ComunicacionesmariaAún no hay calificaciones
- Sandoval DiseosUrbticaSostenibilidadDocumento14 páginasSandoval DiseosUrbticaSostenibilidadmariaAún no hay calificaciones
- 490-Texto Del Artículo-2724-1-10-20200615Documento8 páginas490-Texto Del Artículo-2724-1-10-20200615mariaAún no hay calificaciones
- Mem. Descrip. Carretera1Documento28 páginasMem. Descrip. Carretera1Nathaly Sandra ChoqueAún no hay calificaciones
- Levi-Strauss - Estructuralismo en Ling y en AntropDocumento11 páginasLevi-Strauss - Estructuralismo en Ling y en AntropOscar JaimesAún no hay calificaciones
- Plantas Utiles de BailadoresDocumento27 páginasPlantas Utiles de Bailadoresveliger2009Aún no hay calificaciones
- DI2 Examenes TODO Años AnterioresDocumento755 páginasDI2 Examenes TODO Años AnterioresToni DiesAún no hay calificaciones
- MY SYMPTOMS Sesion 7 1 y 2 InglesDocumento4 páginasMY SYMPTOMS Sesion 7 1 y 2 InglesCarina Huillca Huamani100% (1)
- Extracto de BancosDocumento9 páginasExtracto de BancosjohannaAún no hay calificaciones
- Unan Managua Guia Autoestudio Matematica 2019Documento3 páginasUnan Managua Guia Autoestudio Matematica 2019boscoasAún no hay calificaciones
- Tarea en ClaseDocumento17 páginasTarea en ClaseBrian Ricardo Flores Orellana100% (1)
- Rotafolio TantalioDocumento18 páginasRotafolio TantalioleitoAún no hay calificaciones
- Productividad Fabrica Nacional Calzado Curtiduria Zamora S.ADocumento5 páginasProductividad Fabrica Nacional Calzado Curtiduria Zamora S.ADiana Marcela Sanchez PerezAún no hay calificaciones
- Academia Mexicana de Derechos HumanosDocumento2 páginasAcademia Mexicana de Derechos HumanosAndrés ArellanoAún no hay calificaciones
- EJERCICIO PRACTICO No 3 PLANEACION DE LA PRODUCCIONDocumento2 páginasEJERCICIO PRACTICO No 3 PLANEACION DE LA PRODUCCIONKarol Jimena PeñaAún no hay calificaciones
- La Cultura Chalchihuites de HersDocumento4 páginasLa Cultura Chalchihuites de HersJosé Luis Cervantes CortésAún no hay calificaciones
- Solucion de Caso de Estudio #2Documento4 páginasSolucion de Caso de Estudio #2Alejandra MVAún no hay calificaciones
- Caso Práctico ProbabilidadDocumento2 páginasCaso Práctico Probabilidadlineylosadag75% (4)
- Modelos en Los Diseños Experimentales Básicos Analizados Como Tratamientos Y El Cálculo de Los ResidualesDocumento4 páginasModelos en Los Diseños Experimentales Básicos Analizados Como Tratamientos Y El Cálculo de Los ResidualesSARAHI FLores GuzmanAún no hay calificaciones
- Proyecto de Turismo Eco-Cultural para La Provincia de CatamarcaDocumento18 páginasProyecto de Turismo Eco-Cultural para La Provincia de CatamarcaGODISNOWHERE0% (1)
- Procedimiento CampamentoDocumento5 páginasProcedimiento CampamentoMario TapiaAún no hay calificaciones
- ACTIVIDAD 1 DEL MODULO CONTROVERSIA, SE VAN LOS CARNIVOROS (Primera Parte) Luis Rangel 1104Documento3 páginasACTIVIDAD 1 DEL MODULO CONTROVERSIA, SE VAN LOS CARNIVOROS (Primera Parte) Luis Rangel 1104luis eduardo rangel sotoAún no hay calificaciones
- 4.216 VII La Vida Intelectual en Los Años de PrimariaDocumento6 páginas4.216 VII La Vida Intelectual en Los Años de PrimariaMartín OchoOcho Cuatrodos DiezseisAún no hay calificaciones
- QR P9 CerebroDocumento15 páginasQR P9 CerebroMaryAún no hay calificaciones
- Diagnóstico Por Los 8 Principios. MTCHDocumento2 páginasDiagnóstico Por Los 8 Principios. MTCHJelitza NaranjoAún no hay calificaciones
- Componentes Del CementoDocumento6 páginasComponentes Del CementoPaola LliguicotaAún no hay calificaciones
- SilabaDocumento14 páginasSilabaLorena SalazarAún no hay calificaciones
- Guía ESC 2022 Sobre Evaluación y Manejo Cardiovascular de Pacientes Sometidos A Cirugía No Cardíaca Parte 1Documento49 páginasGuía ESC 2022 Sobre Evaluación y Manejo Cardiovascular de Pacientes Sometidos A Cirugía No Cardíaca Parte 1ricardo villaAún no hay calificaciones
- Organigrama Ministerio Del Interior 1 - ARGENTINADocumento1 páginaOrganigrama Ministerio Del Interior 1 - ARGENTINAdaniel muñozAún no hay calificaciones
- Seguridad Electrica 2024Documento21 páginasSeguridad Electrica 2024Alex MuñozAún no hay calificaciones
- Busso, PaulaDocumento18 páginasBusso, PaulaBIBHUMAAún no hay calificaciones
- Función Afín y LinealDocumento2 páginasFunción Afín y LinealLEIDY KATERINE MARIN ARGUELLOAún no hay calificaciones
- Micro Currículo Legislación SSTDocumento3 páginasMicro Currículo Legislación SSTPaola RamosAún no hay calificaciones