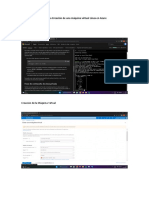
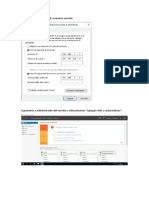
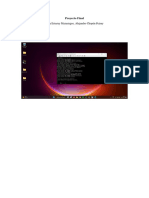
También podría gustarte
- Clase Semana 7Documento31 páginasClase Semana 7JULIO ARMANDO LANDAZURI CASTROAún no hay calificaciones
- Crisp IDocumento23 páginasCrisp Icatarosed100% (1)
- Metodología CRISP-DMDocumento22 páginasMetodología CRISP-DMEmperatriz Diaz MuñozAún no hay calificaciones
- Metodologia para El Desarrollo de Proyectos en Mineria de Datos CRISP-DMDocumento21 páginasMetodologia para El Desarrollo de Proyectos en Mineria de Datos CRISP-DMDenisse Bonilla ReynosoAún no hay calificaciones
- Crisp DMDocumento12 páginasCrisp DMFernando Casasbuenas BarriosAún no hay calificaciones
- Solucion Caso PracticoDocumento5 páginasSolucion Caso PracticoOmar OrralaAún no hay calificaciones
- Etapas de La Metodología CRISPDocumento3 páginasEtapas de La Metodología CRISPJosue Andres Aizprua MeraAún no hay calificaciones
- CRISP-DM - (Cross Industry Standard Process For Data Mining)Documento2 páginasCRISP-DM - (Cross Industry Standard Process For Data Mining)Josue Andres Aizprua MeraAún no hay calificaciones
- Crips DMDocumento13 páginasCrips DMElvin Somón SánchezAún no hay calificaciones
- Practica PDFDocumento7 páginasPractica PDFJavier SánchezAún no hay calificaciones
- Crisp DMDocumento26 páginasCrisp DMA DAún no hay calificaciones
- Metodología CRISP DMDocumento74 páginasMetodología CRISP DMInversiones Solis100% (1)
- Trabajo Final Diplomado Carlos PadillaDocumento36 páginasTrabajo Final Diplomado Carlos Padillacarlos padillaAún no hay calificaciones
- Asum DMDocumento4 páginasAsum DMAnto MorenoAún no hay calificaciones
- Tema 4Documento52 páginasTema 4Patricia CamposAún no hay calificaciones
- MODELODIMENSIONALKIMBALLDocumento41 páginasMODELODIMENSIONALKIMBALLsteven perezAún no hay calificaciones
- Metodología CRISPDocumento10 páginasMetodología CRISPJair RodriguezAún no hay calificaciones
- P3 - MetodologiasDocumento31 páginasP3 - MetodologiasBrandon DuarteAún no hay calificaciones
- Documento CRISP DM.2385037Documento12 páginasDocumento CRISP DM.2385037Harold Jair Gaytan SaavedraAún no hay calificaciones
- ASO Ráctico Nálisis: "Without Data, You Are Just Another Person With An Opinion" - W. Edwards DemingDocumento34 páginasASO Ráctico Nálisis: "Without Data, You Are Just Another Person With An Opinion" - W. Edwards DemingHeimyAún no hay calificaciones
- Metodología KimballDocumento12 páginasMetodología KimballRicardo RamirezAún no hay calificaciones
- Metodologia CRISP-DMDocumento9 páginasMetodologia CRISP-DMMiguel pilamungaAún no hay calificaciones
- Metodologia ModelosDocumento12 páginasMetodologia ModelosLiliana ChavezAún no hay calificaciones
- Proceso KDD: E.F.P. Ciencia de Datos Aplicada A La IndustriaDocumento23 páginasProceso KDD: E.F.P. Ciencia de Datos Aplicada A La IndustriaShaky GamesAún no hay calificaciones
- 008 Dmaic PDFDocumento23 páginas008 Dmaic PDFOdalis Pierina Chelin MartinezAún no hay calificaciones
- Metodología para El Desarrollo de Proyectos en Minería de Datos PDFDocumento13 páginasMetodología para El Desarrollo de Proyectos en Minería de Datos PDFCarlos Urrea100% (1)
- UntitledDocumento9 páginasUntitledSergioAAún no hay calificaciones
- Metodo Kimball PDFDocumento16 páginasMetodo Kimball PDFMiguel Angel Toro CaresAún no hay calificaciones
- Actividad 4Documento5 páginasActividad 4Lisa AguirreAún no hay calificaciones
- Tercera Entrega Minería de DatosDocumento6 páginasTercera Entrega Minería de Datossanyira castroAún no hay calificaciones
- Aplicación de La Metodología Crisp-Dm ADocumento52 páginasAplicación de La Metodología Crisp-Dm AKelvin BarahonaAún no hay calificaciones
- Foro de Debate y ArgumentaciónDocumento5 páginasForo de Debate y ArgumentaciónAlex LopezAún no hay calificaciones
- 6S Metodología y Proyectos de Diseño para Seis SigDocumento26 páginas6S Metodología y Proyectos de Diseño para Seis SigEduardo RodriguezAún no hay calificaciones
- Actividad 2 Proyectos en Ciencia de DatosDocumento26 páginasActividad 2 Proyectos en Ciencia de DatosDavid Alejandro Garcia AtoyAún no hay calificaciones
- Metodología de KimballDocumento6 páginasMetodología de KimballJosé Ricardo Melendez QuinterosAún no hay calificaciones
- Estudio de Factibilidad TécnicaDocumento17 páginasEstudio de Factibilidad TécnicakndydoAún no hay calificaciones
- Tarea 3 Generacion de EmpresasDocumento5 páginasTarea 3 Generacion de EmpresasGeneil Nicole Neil Agurcia100% (1)
- Im 2Documento30 páginasIm 2Josue Juarez MelendezAún no hay calificaciones
- DataMining IDocumento52 páginasDataMining IDIEGO ALONSO GALEANO HERRERAAún no hay calificaciones
- Semana 9 inDocumento28 páginasSemana 9 inNorma ValenciaAún no hay calificaciones
- Metodologia de KIMBALLDocumento18 páginasMetodologia de KIMBALLJose CheroAún no hay calificaciones
- ESCENARIOs 2Documento14 páginasESCENARIOs 2juanaAún no hay calificaciones
- Presentacion Universidad Internacional de San Luís PotosíDocumento14 páginasPresentacion Universidad Internacional de San Luís PotosíJorge Andres MendezAún no hay calificaciones
- #7 Plan de NegociosDocumento45 páginas#7 Plan de NegociosMarcely BolañosAún no hay calificaciones
- LAB IN Tarea 02 PDFDocumento15 páginasLAB IN Tarea 02 PDFRenzo E RojasAún no hay calificaciones
- Metodologia KimballDocumento15 páginasMetodologia KimballDaphne Paucar Moreyra100% (1)
- Business M7T3Documento9 páginasBusiness M7T3Ay GaAún no hay calificaciones
- Tarea 3 Generacion de EmpresasDocumento6 páginasTarea 3 Generacion de EmpresasIsabella CarrascoAún no hay calificaciones
- Business Problems and Data Science SolutionsDocumento2 páginasBusiness Problems and Data Science SolutionsBarbara PintoAún no hay calificaciones
- Sesion 2 Plan de Investigacion de MercadosDocumento28 páginasSesion 2 Plan de Investigacion de MercadosALEX ULISES MORALES ALVARADOAún no hay calificaciones
- Sesion 12 Metodologia HefestoDocumento61 páginasSesion 12 Metodologia HefestoLuis Martin Guevara CondoriAún no hay calificaciones
- Tema 2Documento14 páginasTema 2Edgar Guerrero0% (2)
- Plantilla Paso 4 - Modelar Las Capacidades de Negocio Ricardo Alfonso Forero BahamónDocumento6 páginasPlantilla Paso 4 - Modelar Las Capacidades de Negocio Ricardo Alfonso Forero Bahamónricardo alfonso forero bahamonAún no hay calificaciones
- Resumen de Technology Scorecards de Sam BansalDe EverandResumen de Technology Scorecards de Sam BansalAún no hay calificaciones
- Resumen de Delivering On The Promise de David M. Walker, James Hatch y Brian FriedmanDe EverandResumen de Delivering On The Promise de David M. Walker, James Hatch y Brian FriedmanAún no hay calificaciones
- UF1781 - Tratamiento y análisis de la información de mercadosDe EverandUF1781 - Tratamiento y análisis de la información de mercadosAún no hay calificaciones
- El método Seis Sigma: Mejore los resultados de su negocioDe EverandEl método Seis Sigma: Mejore los resultados de su negocioCalificación: 4 de 5 estrellas4/5 (24)
- Planificación de proyectos de implantación de infraestructuras de redes telemáticas. IFCT0410De EverandPlanificación de proyectos de implantación de infraestructuras de redes telemáticas. IFCT0410Aún no hay calificaciones
- Los criterios SMART: El método para fijar objetivos con éxitoDe EverandLos criterios SMART: El método para fijar objetivos con éxitoCalificación: 4 de 5 estrellas4/5 (15)
- Angular, React, VueDocumento2 páginasAngular, React, VueCamila Est MazariegosAún no hay calificaciones
- Sociedad Pañuelos FinosDocumento4 páginasSociedad Pañuelos FinosCamila Est MazariegosAún no hay calificaciones
- Creación de Una Máquina Virtual Linux en AzureDocumento5 páginasCreación de Una Máquina Virtual Linux en AzureCamila Est MazariegosAún no hay calificaciones
- Introducción A Los Aspectos Básicos de AzureDocumento1 páginaIntroducción A Los Aspectos Básicos de AzureCamila Est MazariegosAún no hay calificaciones
- Formato de Realimentación de EvaluacionesDocumento5 páginasFormato de Realimentación de EvaluacionesCamila Est MazariegosAún no hay calificaciones
- Libro Diario, Mayor y Balance de SaldosDocumento14 páginasLibro Diario, Mayor y Balance de SaldosCamila Est MazariegosAún no hay calificaciones
- DHCPDocumento6 páginasDHCPCamila Est MazariegosAún no hay calificaciones
- Proyecto FinalDocumento1 páginaProyecto FinalCamila Est MazariegosAún no hay calificaciones
- Características Del Aprendizaje OrganizacionalDocumento1 páginaCaracterísticas Del Aprendizaje OrganizacionalCamila Est MazariegosAún no hay calificaciones
- Modelo OSIDocumento4 páginasModelo OSICamila Est MazariegosAún no hay calificaciones
- Tarea ISODocumento12 páginasTarea ISOCamila Est Mazariegos100% (1)
- Formas de Fomentar El Aprendizaje OrganizacionalDocumento1 páginaFormas de Fomentar El Aprendizaje OrganizacionalCamila Est MazariegosAún no hay calificaciones
- TestDocumento3 páginasTestCamila Est MazariegosAún no hay calificaciones
- Cableado EstructuradoDocumento7 páginasCableado EstructuradoCamila Est MazariegosAún no hay calificaciones
- Conectores LógicosDocumento13 páginasConectores LógicosCamila Est MazariegosAún no hay calificaciones
- Herramientas para Gestión de RedDocumento7 páginasHerramientas para Gestión de RedCamila Est MazariegosAún no hay calificaciones
- Herramientas de Minería de DatosDocumento13 páginasHerramientas de Minería de DatosCamila Est MazariegosAún no hay calificaciones
- Árboles de DecisiónDocumento13 páginasÁrboles de DecisiónCamila Est MazariegosAún no hay calificaciones
- Tipo de MemoriasDocumento6 páginasTipo de MemoriasCamila Est MazariegosAún no hay calificaciones
- Algoritmos de AgrupamientoDocumento14 páginasAlgoritmos de AgrupamientoCamila Est MazariegosAún no hay calificaciones
- Modelo Lotka VolterraDocumento9 páginasModelo Lotka VolterraCamila Est MazariegosAún no hay calificaciones
- Planteamiento Problemas de TransporteDocumento2 páginasPlanteamiento Problemas de TransporteCamila Est MazariegosAún no hay calificaciones
- Conectores LógicosDocumento13 páginasConectores LógicosCamila Est MazariegosAún no hay calificaciones
- Método de MullerDocumento11 páginasMétodo de MullerCamila Est MazariegosAún no hay calificaciones
- Distribución HipergeométricaDocumento8 páginasDistribución HipergeométricaCamila Est MazariegosAún no hay calificaciones
- Matriz de CrecimientoDocumento2 páginasMatriz de CrecimientoCamila Est MazariegosAún no hay calificaciones
- PADRERICOPADREPOBREDocumento10 páginasPADRERICOPADREPOBRECamila Est MazariegosAún no hay calificaciones
- Modelo de MultiplicadoresDocumento4 páginasModelo de MultiplicadoresCamila Est MazariegosAún no hay calificaciones
- Lectura 2Documento3 páginasLectura 2Camila Est MazariegosAún no hay calificaciones
- Data MiningDocumento5 páginasData MiningAlfredoAún no hay calificaciones
- PaperAprendizajeMaq v1Documento8 páginasPaperAprendizajeMaq v1MIGUEL ANGEL ESPINOZA CARRANZAAún no hay calificaciones
- Metodologias Del Data MiningDocumento19 páginasMetodologias Del Data MiningJaime GallegoAún no hay calificaciones
- Introducción A La Mineria de DatosDocumento56 páginasIntroducción A La Mineria de DatosHomero CardenasAún no hay calificaciones
- Tema 1Documento50 páginasTema 1Patricia CamposAún no hay calificaciones
- ForoDocumento26 páginasForoAlex LopezAún no hay calificaciones
- Revista IT Lops - 26-31-PBDocumento45 páginasRevista IT Lops - 26-31-PBNelson ArturoAún no hay calificaciones
- Mineria Con R-FinalDocumento407 páginasMineria Con R-FinalJOSE MIGUEL ZUNIGA NUNEZAún no hay calificaciones
- Segmentación de Base de Datos de Clientes para Personalizacion de Portafolio de Productos Entrega IiiDocumento31 páginasSegmentación de Base de Datos de Clientes para Personalizacion de Portafolio de Productos Entrega IiiIvan BejaranoAún no hay calificaciones
- Sesión 01Documento22 páginasSesión 01Randy Morales CarbajalAún no hay calificaciones
- Solucion Caso PracticoDocumento5 páginasSolucion Caso PracticoOmar OrralaAún no hay calificaciones
- Análisis Predictivo. Proceso, Métodos y Algoritmos de Minería de DatosDocumento98 páginasAnálisis Predictivo. Proceso, Métodos y Algoritmos de Minería de DatosCamilo Giraldo QuinteroAún no hay calificaciones
- Biblio y Recursos WebDocumento17 páginasBiblio y Recursos WebEmerson NorabuenaAún no hay calificaciones
- Fase Evaluacion Del Modelo CRISP-DMDocumento10 páginasFase Evaluacion Del Modelo CRISP-DMjose luisAún no hay calificaciones
- Trabajo de GradoDocumento51 páginasTrabajo de GradoGustavo Gualsema100% (1)
- Fundamentos de La Ciencia de Datos Tad403-996-223081-Tlp-metodologia Crisp DMDocumento9 páginasFundamentos de La Ciencia de Datos Tad403-996-223081-Tlp-metodologia Crisp DMMary'd oyukipaAún no hay calificaciones
- Unidad III Teoría - Semana - 7Documento43 páginasUnidad III Teoría - Semana - 7Carlos Román Ordoñez PinillosAún no hay calificaciones
- Aplicación de La Metodología CRISP DM en La Minería de Datos en La ClasificaciónDocumento6 páginasAplicación de La Metodología CRISP DM en La Minería de Datos en La ClasificaciónAxel Aviles P.Aún no hay calificaciones
- Proceso de DescubrimientoDocumento120 páginasProceso de DescubrimientoConchi MarcosAún no hay calificaciones
- La Minería de Datos en El Proceso de KDDDocumento5 páginasLa Minería de Datos en El Proceso de KDDDaniel BaqueAún no hay calificaciones
- Crisp-Dm y SemmaDocumento28 páginasCrisp-Dm y SemmaCamila Est MazariegosAún no hay calificaciones
- Informe de Investigación ANALITICA DE DATOSDocumento29 páginasInforme de Investigación ANALITICA DE DATOSSantiago DiazAún no hay calificaciones
- Fase - Comprension de Los DatosDocumento7 páginasFase - Comprension de Los DatosMirko Vela LopezAún no hay calificaciones
- Yamile Peña Lozano: Palabras ClaveDocumento17 páginasYamile Peña Lozano: Palabras Clavecristian velasquezAún no hay calificaciones
- Primera Entrega Mineria de DatosDocumento8 páginasPrimera Entrega Mineria de DatosHector MedinaAún no hay calificaciones
- Actividad 9Documento3 páginasActividad 9Emilio GrijalvaAún no hay calificaciones
- Desarrollo de Un Modelo Predictivo para Mejorar La Estimacion de Energia Por Leer en Los Medidores ELM Con El Uso de Datos Generados Por Medidores Del Segmento MasivoDocumento62 páginasDesarrollo de Un Modelo Predictivo para Mejorar La Estimacion de Energia Por Leer en Los Medidores ELM Con El Uso de Datos Generados Por Medidores Del Segmento MasivoRicardo SotoAún no hay calificaciones