También podría gustarte
- Estadística para veterinarios y zootecnistasDe EverandEstadística para veterinarios y zootecnistasCalificación: 5 de 5 estrellas5/5 (1)
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Razonamiento cuantitativo, 2ª edición: Notas de claseDe EverandRazonamiento cuantitativo, 2ª edición: Notas de claseCalificación: 5 de 5 estrellas5/5 (1)
- Distribucion de FrecuenciasDocumento10 páginasDistribucion de FrecuenciasMichel Alondra Millán100% (1)
- Unidad 3 Estadistica DescriptivaDocumento9 páginasUnidad 3 Estadistica DescriptivaCarloss Ruiz R100% (1)
- Cimentaciones de Concreto ArmadoDocumento17 páginasCimentaciones de Concreto Armadopauljjjjj50% (6)
- Cocina Vegetariana IndiaDocumento4 páginasCocina Vegetariana IndiaLucero BaezAún no hay calificaciones
- Estadistica Act 2 Corte I Trimestre IVDocumento8 páginasEstadistica Act 2 Corte I Trimestre IVMaria LopezAún no hay calificaciones
- Intervalos de Clase: Guía 3 Ciclo 5Documento10 páginasIntervalos de Clase: Guía 3 Ciclo 5Kevin MontenegroAún no hay calificaciones
- Clase Estadistica DescriptivaDocumento33 páginasClase Estadistica DescriptivaRomi Von EckartsbergAún no hay calificaciones
- Distribución de FrecuenciasDocumento33 páginasDistribución de FrecuenciasRoberto SochAún no hay calificaciones
- Est Ad Is Tic ADocumento44 páginasEst Ad Is Tic AAngel RobledoAún no hay calificaciones
- SOLUCIONDocumento9 páginasSOLUCIONVeizaga ArlinAún no hay calificaciones
- Distribución de FrecuenciaDocumento7 páginasDistribución de FrecuenciaCristalHernandezAún no hay calificaciones
- EXPERIMENTODocumento12 páginasEXPERIMENTORoberto TorrucoAún no hay calificaciones
- 4 - Distribución de Frecuencias.Documento17 páginas4 - Distribución de Frecuencias.ANTHONY WILLY VARGAS CONTRERASAún no hay calificaciones
- Resumen Probabilidad y EstadísticaDocumento73 páginasResumen Probabilidad y EstadísticaMaria Jose ManeroAún no hay calificaciones
- Distribucion de Frecuencias PDFDocumento6 páginasDistribucion de Frecuencias PDF17191016Aún no hay calificaciones
- II Unidad Ordenamiento y Presentacion de DatosDocumento9 páginasII Unidad Ordenamiento y Presentacion de Datosjose ruizAún no hay calificaciones
- Distribucion de FrecuenciasDocumento11 páginasDistribucion de FrecuenciasSelvin Danilo QuiñonezAún no hay calificaciones
- Organización de Los DatosDocumento3 páginasOrganización de Los DatosOrtiz MirianniAún no hay calificaciones
- Tema 2Documento7 páginasTema 2rosannypAún no hay calificaciones
- 4.distribuciones de FrecuenciasDocumento13 páginas4.distribuciones de Frecuenciaszusseth LopezAún no hay calificaciones
- Medidas de Dispersión 1Documento15 páginasMedidas de Dispersión 1JoseRubioAún no hay calificaciones
- 484324análisis Descriptivo de Los DatosDocumento14 páginas484324análisis Descriptivo de Los DatosEdixon TavarezAún no hay calificaciones
- Estadisticas Unidad 2Documento8 páginasEstadisticas Unidad 2Valdo CruzAún no hay calificaciones
- Clase v. Datos Agrupados - Distribución de FrecuenciasDocumento5 páginasClase v. Datos Agrupados - Distribución de FrecuenciasAlexandra CarvajalAún no hay calificaciones
- Desarrollo - Distribuccion de FrecuenciaDocumento4 páginasDesarrollo - Distribuccion de FrecuenciaJean Carlos PeñaAún no hay calificaciones
- Promedi 1Documento23 páginasPromedi 1Robert GolindanoAún no hay calificaciones
- Estadística PDFDocumento74 páginasEstadística PDFJoaquin LilloAún no hay calificaciones
- MAILINDocumento8 páginasMAILINAlicia ContrerasAún no hay calificaciones
- Distribución de FrecuenciaDocumento13 páginasDistribución de FrecuenciaIsmaelAún no hay calificaciones
- Distribución de FrecuenciasDocumento36 páginasDistribución de FrecuenciasAlexander FuentesAún no hay calificaciones
- Cap 5Documento106 páginasCap 5Liliana VillamilAún no hay calificaciones
- Cap 6Documento141 páginasCap 6Liliana VillamilAún no hay calificaciones
- Distribucion de FrecuenciasDocumento52 páginasDistribucion de FrecuenciasKevinCortézAún no hay calificaciones
- Curso de Estadistica 2Documento55 páginasCurso de Estadistica 2RafaelDragoHerreraCapalleraAún no hay calificaciones
- Esta Di SticaDocumento36 páginasEsta Di SticaIsabel Di IorioAún no hay calificaciones
- Estadistica y Analisis de DatosDocumento15 páginasEstadistica y Analisis de DatosmariaAún no hay calificaciones
- Estadistica AcipolDocumento62 páginasEstadistica AcipolAnonymous K2AvuIAún no hay calificaciones
- Clase N°2 Distribución de FrecuenciaDocumento16 páginasClase N°2 Distribución de Frecuenciarafa_patonAún no hay calificaciones
- LABORATORIODocumento6 páginasLABORATORIOJenali PaimaAún no hay calificaciones
- Tabla de Frecuencia CentralDocumento10 páginasTabla de Frecuencia CentralDaniel AldanaAún no hay calificaciones
- Trabajo de EstadisticaDocumento9 páginasTrabajo de EstadisticaJuan Andres RivazAún no hay calificaciones
- 1.4 Organización de Los DatosDocumento12 páginas1.4 Organización de Los DatosSergio D'Chko MandgtzAún no hay calificaciones
- Organizacion de Datos Simples y AgrupadosDocumento30 páginasOrganizacion de Datos Simples y AgrupadosjggjAún no hay calificaciones
- S-5 Calidad TotalDocumento18 páginasS-5 Calidad TotalJhan Carlos Córdova SánchezAún no hay calificaciones
- Unidad Cero UnoDocumento15 páginasUnidad Cero UnoLu ihAún no hay calificaciones
- Conceptos EstadísticosDocumento49 páginasConceptos EstadísticosKristianskrillex1080 HDAún no hay calificaciones
- AlvarezSanchezDulceRosario InvestigacionDocumento15 páginasAlvarezSanchezDulceRosario InvestigacionRosalia TellezAún no hay calificaciones
- 4-Material de TrabajoDocumento53 páginas4-Material de TrabajoJohn Alexander Vasquez Saenz100% (1)
- Clase Nro. 01 Estadística 501 Medidas de Tendencia CentralDocumento15 páginasClase Nro. 01 Estadística 501 Medidas de Tendencia CentralAnghi WookAún no hay calificaciones
- Estadistica 3Documento20 páginasEstadistica 3karelislarosaAún no hay calificaciones
- Criterios para Agrupar DatosDocumento6 páginasCriterios para Agrupar DatosEduardo Melendez100% (1)
- Tabla de Distribución de FrecuenciaDocumento6 páginasTabla de Distribución de FrecuenciaVagoGui ViolinGuiAún no hay calificaciones
- Tarea123T EstadísticasDocumento3 páginasTarea123T EstadísticasRoberto Rafael Rodríguez PeláezAún no hay calificaciones
- Usamos Este Tipo de Tablas Cuando TenemosDocumento2 páginasUsamos Este Tipo de Tablas Cuando TenemosDaniela SolanoAún no hay calificaciones
- S05.s5-Tarea Herramientas de GestiónDocumento12 páginasS05.s5-Tarea Herramientas de GestiónJoseph PçAún no hay calificaciones
- Clase 4. Tablas de FrecuenciaDocumento8 páginasClase 4. Tablas de FrecuenciaLilian PreciadoAún no hay calificaciones
- Estadística SCHAUM BUENODocumento7 páginasEstadística SCHAUM BUENOArely R. VelázquezAún no hay calificaciones
- Histograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraDe EverandHistograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraAún no hay calificaciones
- Cruz Categorial SensacionDocumento1 páginaCruz Categorial SensacionYuliana Angela Garcia LizarbeAún no hay calificaciones
- Infografia Línea Del Tiempo Historia Psicologia AmbientalDocumento1 páginaInfografia Línea Del Tiempo Historia Psicologia AmbientalYuliana Angela Garcia LizarbeAún no hay calificaciones
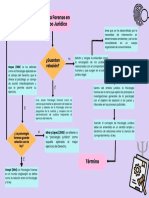
- Diagrama de Flujo Psicologia Forense y Relacion JuridicaDocumento1 páginaDiagrama de Flujo Psicologia Forense y Relacion JuridicaYuliana Angela Garcia LizarbeAún no hay calificaciones
- Importancia de La NeurocienciaDocumento15 páginasImportancia de La NeurocienciaYuliana Angela Garcia LizarbeAún no hay calificaciones
- Corregido Test de La FamiliaDocumento10 páginasCorregido Test de La FamiliaYuliana Angela Garcia LizarbeAún no hay calificaciones
- TEMA2Documento3 páginasTEMA2Yuliana Angela Garcia LizarbeAún no hay calificaciones
- Resuemn Pagina 43 y Conclusion de CasoDocumento2 páginasResuemn Pagina 43 y Conclusion de CasoYuliana Angela Garcia LizarbeAún no hay calificaciones
- Prueba de Berry P.cognitivosDocumento11 páginasPrueba de Berry P.cognitivosYuliana Angela Garcia LizarbeAún no hay calificaciones
- Plan de Intervencion ..Documento11 páginasPlan de Intervencion ..Yuliana Angela Garcia LizarbeAún no hay calificaciones
- Mystery CompressDocumento3 páginasMystery CompressbryanAún no hay calificaciones
- Textos DESCRIPTIVOS Y NARRATIVOS.Documento4 páginasTextos DESCRIPTIVOS Y NARRATIVOS.Maria PérezAún no hay calificaciones
- Introduccion A La Cromatografia Del Gas NaturalDocumento37 páginasIntroduccion A La Cromatografia Del Gas NaturalANIBALAún no hay calificaciones
- Caminemos A La Luz Del SeñorDocumento41 páginasCaminemos A La Luz Del SeñorJosé Juber BalanAún no hay calificaciones
- Dialnet LaMujerNuevoSujetoSocialDocumento12 páginasDialnet LaMujerNuevoSujetoSocialXIMENA NATALIA CASTRO TENAAún no hay calificaciones
- Cubero Perez y Santamaria Santigosa - Psicología Cultural, Una Aproximacion Conceptual e Historica Al Encuentro Entre Mente y CulturaDocumento15 páginasCubero Perez y Santamaria Santigosa - Psicología Cultural, Una Aproximacion Conceptual e Historica Al Encuentro Entre Mente y CulturaCinthya AriasAún no hay calificaciones
- Rubrica Geometría Analítica Ejemplo AiDocumento2 páginasRubrica Geometría Analítica Ejemplo Aipruebas17771Aún no hay calificaciones
- 2.1 Cohesión y CoherenciaDocumento5 páginas2.1 Cohesión y CoherenciaNazareth Amador HernándezAún no hay calificaciones
- NUALC - Normas Universales Sobre El Año Litúrgico y El CalendarioDocumento13 páginasNUALC - Normas Universales Sobre El Año Litúrgico y El CalendarioJOSE GALVISAún no hay calificaciones
- La Escuela Positiva y La Filosofia Del Derecho en El Siglo XXDocumento39 páginasLa Escuela Positiva y La Filosofia Del Derecho en El Siglo XXSamaíMirandaAún no hay calificaciones
- MELENA DE LEON - Docx 1Documento7 páginasMELENA DE LEON - Docx 1Esteban CallejaAún no hay calificaciones
- Informe DinamicaDocumento3 páginasInforme DinamicaCristian ChavezAún no hay calificaciones
- Evaluación Formativa Módulo 3Documento11 páginasEvaluación Formativa Módulo 3Cristóbal Cabrera MuñozAún no hay calificaciones
- Géneros NarrativosDocumento9 páginasGéneros NarrativosCarlos HCAún no hay calificaciones
- Recuerdos de La Atlántida 11Documento14 páginasRecuerdos de La Atlántida 11apachexAún no hay calificaciones
- Dengue, Zika, Chikungunya PDFDocumento13 páginasDengue, Zika, Chikungunya PDFJhasmyn Ivon Callejas BustosAún no hay calificaciones
- Resumen Ejecutivo 2019Documento3 páginasResumen Ejecutivo 2019Jose Hernandez GutierrezAún no hay calificaciones
- Colaborativo Unidad 1Documento2 páginasColaborativo Unidad 1Cristian jose Montes GonzalezAún no hay calificaciones
- Informe 2 Gestión de Datos de Información IIDocumento22 páginasInforme 2 Gestión de Datos de Información IIleider chacon gironAún no hay calificaciones
- Dolor de CabezaDocumento2 páginasDolor de CabezaLuisa HernandezAún no hay calificaciones
- Locuciones LatinasDocumento20 páginasLocuciones LatinasalbertochinoAún no hay calificaciones
- 4º Leng Lectura N°8Documento2 páginas4º Leng Lectura N°8Profesora Rominna Cabello RuzAún no hay calificaciones
- Majerhua Chacceri Rosa Estrella - Tema 1 Iv Unidad 5to Bendícenos Señor de Los Milagros en Nuestro 38 AniversarioDocumento4 páginasMajerhua Chacceri Rosa Estrella - Tema 1 Iv Unidad 5to Bendícenos Señor de Los Milagros en Nuestro 38 AniversarioRodrigo Apaza ValverdeAún no hay calificaciones
- UNIDAD 8 EmpowerDocumento5 páginasUNIDAD 8 EmpowerNashely ReaAún no hay calificaciones
- Aplicacion de La Derivada en La FisicaDocumento3 páginasAplicacion de La Derivada en La FisicaMaria De Los Angeles Rivera GarciaAún no hay calificaciones
- Tarea 2 Allport Kuder PV PPDocumento3 páginasTarea 2 Allport Kuder PV PPjennifer MoralesAún no hay calificaciones
- El Libro Del Jardín Mayo-Junio-Julio InicialDocumento9 páginasEl Libro Del Jardín Mayo-Junio-Julio InicialSoledad RamírezAún no hay calificaciones
- Milagroso Free Worship Cumplido Esta.EDocumento3 páginasMilagroso Free Worship Cumplido Esta.EEnrique ChapasAún no hay calificaciones