También podría gustarte
- Red Neuronal EjemploDocumento7 páginasRed Neuronal EjemploSergio sersh CruzAún no hay calificaciones
- Ejemplo de Red Neural Con MatlabDocumento12 páginasEjemplo de Red Neural Con Matlabjavier_valdivia_42Aún no hay calificaciones
- Cómo Programar Una Red Neuronal Desde 0 en R Otra VersionDocumento12 páginasCómo Programar Una Red Neuronal Desde 0 en R Otra VersionJesus ArcilaAún no hay calificaciones
- Cómo Programar Una Red Neuronal Desde 0 en PythonDocumento4 páginasCómo Programar Una Red Neuronal Desde 0 en Pythontoro vacaAún no hay calificaciones
- Análisis Discriminante No-Lineal y Perceptrón MulticapaDocumento41 páginasAnálisis Discriminante No-Lineal y Perceptrón MulticapaAlex GomezAún no hay calificaciones
- Práctica 7Documento28 páginasPráctica 7MILENKA ALISON SICCHA JARAAún no hay calificaciones
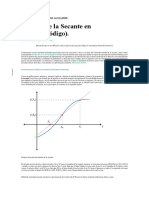
- Método de La Secante en MatlabDocumento13 páginasMétodo de La Secante en MatlabBrygida SophiaAún no hay calificaciones
- Regresion LinealDocumento21 páginasRegresion Linealdanie1234100% (1)
- AdalineDocumento13 páginasAdalineAsdtnGhymnbFghjytAún no hay calificaciones
- REDES NEURONALES Y LÓGICA DIFUSADocumento23 páginasREDES NEURONALES Y LÓGICA DIFUSAJonathan Gabriel Catari AlanocaAún no hay calificaciones
- S03.s2 - Redes Neuronales y Lógica DifusaDocumento24 páginasS03.s2 - Redes Neuronales y Lógica DifusaJonathan Gabriel Catari AlanocaAún no hay calificaciones
- 6 FuncionesDocumento17 páginas6 FuncionesVicente AlarconAún no hay calificaciones
- La Regla de La CadenaDocumento7 páginasLa Regla de La CadenaalexjanaAún no hay calificaciones
- Guía 2, Energía Potencial EléctricaDocumento22 páginasGuía 2, Energía Potencial Eléctricaluz gilAún no hay calificaciones
- Suma recursiva de vectores en CDocumento16 páginasSuma recursiva de vectores en CAlex CcallaAún no hay calificaciones
- Funciones MATLABDocumento9 páginasFunciones MATLABjeferson andyAún no hay calificaciones
- Operaciones escalares en MATLABDocumento47 páginasOperaciones escalares en MATLABLINA HERNANDEZ RAMIREZAún no hay calificaciones
- IA-Regresión LinealDocumento15 páginasIA-Regresión LinealJavierGamarraYumbatoAún no hay calificaciones
- Capítulo 4-MatlabDocumento44 páginasCapítulo 4-MatlabERIKA LEYVA GOMEZAún no hay calificaciones
- Perceptronparte2 120718194301 Phpapp02 PDFDocumento25 páginasPerceptronparte2 120718194301 Phpapp02 PDFJesus Romero MirandaAún no hay calificaciones
- Taller Autovalores MN Intensivo2019Documento6 páginasTaller Autovalores MN Intensivo2019ernestoAún no hay calificaciones
- Implementación de Una Red Neuronal Desde Cero en PythonDocumento5 páginasImplementación de Una Red Neuronal Desde Cero en PythonLinker LAún no hay calificaciones
- CTM Ejemplo - Diseño en Espacio de Estado para El Péndulo Invertido PDFDocumento9 páginasCTM Ejemplo - Diseño en Espacio de Estado para El Péndulo Invertido PDFWilson Barco MAún no hay calificaciones
- Plantilla InformeDocumento6 páginasPlantilla InformeOHANA GAMERAún no hay calificaciones
- Entrada de usuario y conversión de tiposDocumento20 páginasEntrada de usuario y conversión de tiposEduardo e isabellaAún no hay calificaciones
- RetropropagacionDocumento7 páginasRetropropagacionRocioAún no hay calificaciones
- Trabajo F1 - ICA - v2018 - Impar PDFDocumento2 páginasTrabajo F1 - ICA - v2018 - Impar PDFFabricio Benavente100% (1)
- CC30A Algoritmos y Estructuras de DatosDocumento129 páginasCC30A Algoritmos y Estructuras de DatosDaniAún no hay calificaciones
- Ace p1 1Documento15 páginasAce p1 1claudioAún no hay calificaciones
- Cómo simular una partícula en caída libre en MatlabDocumento5 páginasCómo simular una partícula en caída libre en Matlab1518robinAún no hay calificaciones
- Méndez-Brella-Realizar MatrizDocumento6 páginasMéndez-Brella-Realizar MatrizBrella MéndezAún no hay calificaciones
- Trabajo F1 - ICA - V2019 - ImparDocumento2 páginasTrabajo F1 - ICA - V2019 - ImparJunior Tejada SanchezAún no hay calificaciones
- RecursividadDocumento17 páginasRecursividadAnonymous VkNMThxMyAún no hay calificaciones
- Capitulo BPDocumento8 páginasCapitulo BPJaviera MartínezAún no hay calificaciones
- Resumen MatlabDocumento8 páginasResumen Matlabknzo25Aún no hay calificaciones
- Practica1 ResueltaDocumento14 páginasPractica1 ResueltaBorys Maquera ChoqueAún no hay calificaciones
- Cap 19Documento14 páginasCap 19bebesonik0Aún no hay calificaciones
- Transcripción de Rotación MatlabDocumento19 páginasTranscripción de Rotación MatlabVerenisse Mishel CalleAún no hay calificaciones
- Programa de Cola en CDocumento53 páginasPrograma de Cola en Ckillroy7250% (2)
- Redes Neuronales pERCEPTRON-ADALINEDocumento44 páginasRedes Neuronales pERCEPTRON-ADALINEGERARDO CABRERAAún no hay calificaciones
- Clase 5-Optimizacion Polinomios y Numeros ComplejosDocumento44 páginasClase 5-Optimizacion Polinomios y Numeros Complejosacte90Aún no hay calificaciones
- Redes neuronales multicapa resuelven XORDocumento29 páginasRedes neuronales multicapa resuelven XORJonathan Gabriel Catari AlanocaAún no hay calificaciones
- 95.12 Algoritmos y Programación II 1. Arboles BinariosDocumento5 páginas95.12 Algoritmos y Programación II 1. Arboles BinariosPaloma Paloma GMAún no hay calificaciones
- Guia 1Documento22 páginasGuia 1Luis ArévaloAún no hay calificaciones
- Practica 2 MayaDocumento20 páginasPractica 2 MayanetbomAún no hay calificaciones
- Cálculo integral doble e-(x2+y2Documento19 páginasCálculo integral doble e-(x2+y2EannyAún no hay calificaciones
- Derivadas Por DefinicionDocumento31 páginasDerivadas Por DefinicionMilca Valdez100% (1)
- Equipo-13-Informe Red Neuronal GenéticoDocumento5 páginasEquipo-13-Informe Red Neuronal GenéticoJorge Andrés Leiva MorantesAún no hay calificaciones
- Metodo Del Elemento DiscretoDocumento11 páginasMetodo Del Elemento DiscretoDeisy M SAún no hay calificaciones
- Diseño de Controladores y ObservadoresDocumento11 páginasDiseño de Controladores y ObservadoresOmar Gibrahin Hernandez UribeAún no hay calificaciones
- Guía de Modelación para La Aplicación Del Método en EtabsDocumento25 páginasGuía de Modelación para La Aplicación Del Método en EtabsEdwin VenturaAún no hay calificaciones
- Apunte Normalizacion Intro Hasta BCNF 1ra ParteDocumento29 páginasApunte Normalizacion Intro Hasta BCNF 1ra ParteBlas ItoAún no hay calificaciones
- Entrenamiento de redes neuronales con MATLAB usando backpropagationDocumento32 páginasEntrenamiento de redes neuronales con MATLAB usando backpropagationejmc_sicAún no hay calificaciones
- Perceptron MulticapaDocumento29 páginasPerceptron MulticapaCarlos Solis VelascoAún no hay calificaciones
- Parcial 1 Equipo 13Documento5 páginasParcial 1 Equipo 13Jorge Andrés Leiva MorantesAún no hay calificaciones
- Redes Neuronales AprendizajeDocumento3 páginasRedes Neuronales AprendizajeJonathan Paul Aimacaña Molina100% (1)
- Ejercicios Del Metodo de La SecanteDocumento6 páginasEjercicios Del Metodo de La SecantecrissAún no hay calificaciones
- Trabajo F1 - ICA - V2-2020 - NivelaciónDocumento2 páginasTrabajo F1 - ICA - V2-2020 - NivelaciónJose Luis RiveraAún no hay calificaciones
- Milh - Elec-Magn - 5to Domingo IscDocumento5 páginasMilh - Elec-Magn - 5to Domingo Iscfabian jiro fuezAún no hay calificaciones
- Act 2 Lhmi Investigacion U1Documento4 páginasAct 2 Lhmi Investigacion U1fabian jiro fuezAún no hay calificaciones
- 15 Definiciones Del Concepto Sociologia Con Sus AutoresDocumento7 páginas15 Definiciones Del Concepto Sociologia Con Sus AutoresOtto Mar HernandezAún no hay calificaciones
- Act 2 - Lhmi-Unidad 1Documento3 páginasAct 2 - Lhmi-Unidad 1fabian jiro fuezAún no hay calificaciones
- Filosofia MedievalDocumento2 páginasFilosofia Medievalfabian jiro fuezAún no hay calificaciones
- Por Qué Es Importante Un Sistema de RRHH - Isc-Domingo-MarlonDocumento2 páginasPor Qué Es Importante Un Sistema de RRHH - Isc-Domingo-Marlonfabian jiro fuezAún no hay calificaciones
- Milh-S.o. Isc4to-2do ParcialDocumento5 páginasMilh-S.o. Isc4to-2do Parcialfabian jiro fuezAún no hay calificaciones
- Milh-Base de Datos-Isc-4to 2do Parcial.Documento5 páginasMilh-Base de Datos-Isc-4to 2do Parcial.fabian jiro fuezAún no hay calificaciones
- METODOLOGIADocumento6 páginasMETODOLOGIAfabian jiro fuezAún no hay calificaciones
- Cómo Establecer La Configuración Del Proxy de RedDocumento3 páginasCómo Establecer La Configuración Del Proxy de Redfabian jiro fuezAún no hay calificaciones
- Seguir Las Flechas Ahi en Te Punto Se Encuentra El Rancho Los MochisDocumento1 páginaSeguir Las Flechas Ahi en Te Punto Se Encuentra El Rancho Los Mochisfabian jiro fuezAún no hay calificaciones
- Componentes del Desarrollo Sostenible y Ciclo de VidaDocumento1 páginaComponentes del Desarrollo Sostenible y Ciclo de Vidafabian jiro fuezAún no hay calificaciones
- Desarrollo HumanoDocumento2 páginasDesarrollo Humanofabian jiro fuezAún no hay calificaciones
- Cómo Configurar Un Servidor Proxy en Su PCDocumento4 páginasCómo Configurar Un Servidor Proxy en Su PCfabian jiro fuezAún no hay calificaciones
- Tipos de Aportaciones MemofichasDocumento3 páginasTipos de Aportaciones Memofichasfabian jiro fuezAún no hay calificaciones
- Conceptos de Auditoria y Auditoria InformáticaDocumento4 páginasConceptos de Auditoria y Auditoria Informáticafabian jiro fuezAún no hay calificaciones
- AlabaréDocumento2 páginasAlabaréfabian jiro fuezAún no hay calificaciones
- Terapia ImplosivaDocumento3 páginasTerapia ImplosivaAylin BalderramaAún no hay calificaciones
- Tarea 2 Modulo 6Documento8 páginasTarea 2 Modulo 6gregorioAún no hay calificaciones
- Clima OrganizacionalDocumento9 páginasClima OrganizacionalRaúl VidalAún no hay calificaciones
- La Teoría Física y El ExperimentoDocumento2 páginasLa Teoría Física y El ExperimentoJonathan Armeaga DíazAún no hay calificaciones
- CursoLenguaMayaDocumento2 páginasCursoLenguaMayaSergio CastilloAún no hay calificaciones
- Desarrollo de Software EducativoDocumento18 páginasDesarrollo de Software EducativoD Liz VasAún no hay calificaciones
- Dogliotti, Figuaras de Autoridad y EnseñanzaDocumento4 páginasDogliotti, Figuaras de Autoridad y EnseñanzaAnthony Perez BenitezAún no hay calificaciones
- Proyecto Áulico - Avance #3Documento22 páginasProyecto Áulico - Avance #3LUIS ALFONSO VELÁSQUEZ VERAAún no hay calificaciones
- Funciones CognitivasDocumento13 páginasFunciones CognitivasJuan FoAún no hay calificaciones
- Plan de Monitoreo Acompañamiento 2021-SecundariaDocumento8 páginasPlan de Monitoreo Acompañamiento 2021-SecundariaJOSÉ GARCIAAún no hay calificaciones
- La ComunicaciónDocumento29 páginasLa ComunicaciónYuri CruzAún no hay calificaciones
- Libro Supuestos Prácticos PDFDocumento257 páginasLibro Supuestos Prácticos PDFAlfonsoAún no hay calificaciones
- Paso 2 - Desarrollo de La contabilidad-Epistemologia-Jeizon FuentesDocumento8 páginasPaso 2 - Desarrollo de La contabilidad-Epistemologia-Jeizon FuentesCarmen GaravitoAún no hay calificaciones
- La percepción del cuidado humanizado en el Hospital EsSalud HuachoDocumento9 páginasLa percepción del cuidado humanizado en el Hospital EsSalud HuachoJEANNETH MUÑOZAún no hay calificaciones
- 1 PBDocumento20 páginas1 PBJ WhônleyAún no hay calificaciones
- Tarea 6Documento5 páginasTarea 6Martha Figuereo100% (1)
- Cuadro de Analisis de La Experiencia Exitosa de La GiaDocumento4 páginasCuadro de Analisis de La Experiencia Exitosa de La GiaTan Solo ImaginameAún no hay calificaciones
- Función FáticaDocumento5 páginasFunción FáticaOscar De LeonAún no hay calificaciones
- Trabajo Sobre La Preferencia de La Joven Universitaria Por El Hombre MaduroDocumento19 páginasTrabajo Sobre La Preferencia de La Joven Universitaria Por El Hombre MaduroAmbiox Perez100% (2)
- Guía de Actividades y Rúbrica de Evaluación - Paso 1 - Realizar Reconocimiento Del CursoDocumento12 páginasGuía de Actividades y Rúbrica de Evaluación - Paso 1 - Realizar Reconocimiento Del Cursozoraida acosta salazarAún no hay calificaciones
- PLANIFICACIÓN DEL 14 Al 18 de NoviembreDocumento5 páginasPLANIFICACIÓN DEL 14 Al 18 de Noviembrenatalie san martinAún no hay calificaciones
- Metodologia de Sistemas Blandos (MSB) : Daniel Baez Acevedo Mauricio Alejandro Romero JaimesDocumento31 páginasMetodologia de Sistemas Blandos (MSB) : Daniel Baez Acevedo Mauricio Alejandro Romero JaimesDaniel Baez Acevedo0% (1)
- TEORIA DE Lyman W Porter y Edward Lawler IIIDocumento2 páginasTEORIA DE Lyman W Porter y Edward Lawler IIIEsthefany Yessenia Cardoza ReyesAún no hay calificaciones
- Sustentación de Proyecto de GradoDocumento26 páginasSustentación de Proyecto de GradoCamila MorenoAún no hay calificaciones
- E-Alvarado Belkis ENSAYO. OJO.Documento10 páginasE-Alvarado Belkis ENSAYO. OJO.isaias lozadaAún no hay calificaciones
- Caracterización de los aportes de Julio Núñez Madachi a la filosofía y cultura del Caribe colombianoDocumento18 páginasCaracterización de los aportes de Julio Núñez Madachi a la filosofía y cultura del Caribe colombianoJosé GonzálezAún no hay calificaciones
- Evaluacion Final U1ADocumento4 páginasEvaluacion Final U1ADiego GomezAún no hay calificaciones
- Los 7 Factores de La IluminacionDocumento3 páginasLos 7 Factores de La IluminacionJavier RosasAún no hay calificaciones
- Desarrollo Personal y la Pirámide de MaslowDocumento2 páginasDesarrollo Personal y la Pirámide de MaslowMeli PasikAún no hay calificaciones
- Crianza PositivaDocumento15 páginasCrianza PositivaNAYELY ANTONIA PAVON MEJIA100% (1)