Documentos de Académico
Documentos de Profesional
Documentos de Cultura
Informe - Interbloqueos (Grupo 02)
Cargado por
Luis villanuevaDerechos de autor
Formatos disponibles
Compartir este documento
Compartir o incrustar documentos
¿Le pareció útil este documento?
¿Este contenido es inapropiado?
Denunciar este documentoCopyright:
Formatos disponibles
Informe - Interbloqueos (Grupo 02)
Cargado por
Luis villanuevaCopyright:
Formatos disponibles
SISTEMAS OPERATIVOS
UNIVERSIDAD NACIONAL
DE TRUJILLO
FACULTAD DE INGENIERIA
ESCUELA DE INGENIERIA DE SISTEMAS
Tema:
“INTERBLOQUEOS”
Profesor:
César Arellano Salazar
Integrantes:
- Huertas Franco Alec
- Paulino Vigo Arturo
- Rojas Sánchez Orlando
- Roncal Sánchez Geraldine
- Salvador Llaro Ericka
- Zavaleta Taucett Jhanpoul
Ingeniería de Sistemas -2021- Página 1
SISTEMAS OPERATIVOS
INTERBLOQUEOS
Ingeniería de Sistemas Página 2
SISTEMAS OPERATIVOS
CONTENIDO
INTRODUCCIÓN .......................................................................................................... 6
DESARROLLO ............................................................................................................. 6
1. Recursos ............................................................................................................ 7
1.1.1. Recurso apropiativo: ................................................................................... 7
1.1.2. Recurso no apropiativo: .............................................................................. 7
1.2. Adquisición de recursos .................................................................................. 8
1.2.1. Recurso adquirido por solo 1 proceso ......................................................... 8
1.2.2. Recurso adquirido por 2 o más procesos .................................................... 8
2. Interbloqueo ....................................................................................................... 9
2.1. Condiciones para los interbloqueos de recursos ........................................... 10
2.2. Modelo de Interbloqueo ................................................................................ 10
3. El Algoritmo del Avestruz ................................................................................. 11
4. Detección y recuperación de un Interbloqueo................................................... 11
4.1. Conceptos: ................................................................................................... 11
4.2. Detección de interbloqueos con un recurso de cada tipo .............................. 11
4.3. Detección del interbloqueo con varios recursos de cada tipo ........................ 13
4.4. Recuperación de un interbloqueo: ................................................................ 15
4.4.1. Recuperación por medio de apropiación: .................................................. 15
4.4.2. Recuperación a través del retroceso: ........................................................ 15
4.4.3. Recuperación a través de la eliminación de procesos: .............................. 16
5. Cómo evitar un Interbloqueo ............................................................................ 16
5.1. Trayectoria de recursos............................................................................. 16
5.2. Estados seguros e inseguros .................................................................... 18
5.3. El algoritmo del banquero para un solo recurso ........................................ 19
5.4. El algoritmo del banquero para varios recursos......................................... 21
6. Como prevenir interbloqueos ........................................................................... 22
6.1. Cómo atacar la condición de exclusión mutua........................................... 22
6.2. Cómo atacar la condición de contención y espera .................................... 23
6.3. Cómo atacar la condición no apropiativa ................................................... 23
6.4. Cómo atacar la condición de espera circular ............................................. 24
7. Mecanismos de concurrencia de UNIX............................................................. 25
7.1. TUBERIAS ................................................................................................ 29
7.2. MENSAJES ............................................................................................... 30
7.3. MEMORIA COMPARTIDA ........................................................................ 30
7.4. SEMAFOROS ........................................................................................... 30
7.5. SEÑALES ................................................................................................. 31
8. Mecanismos de concurrencia del núcleo de Linux ........................................... 32
Ingeniería de Sistemas Página 3
SISTEMAS OPERATIVOS
8.1. Operaciones Atómicas .................................................................................. 33
8.2. Cerrojos Cíclicos .......................................................................................... 34
8.3. Semáforos .................................................................................................... 36
8.4. Barreras........................................................................................................ 38
9. Funciones de sincronización de Hilos de Solaris .............................................. 39
9.1. Cerrojo de Exclusión Mutua .......................................................................... 40
9.2. Semáforos .................................................................................................... 40
9.3. Cerrojo de Lectura/Escritura ......................................................................... 41
9.4. Variables de Condición ................................................................................. 41
10. Mecanismos de concurrencia Windows ........................................................ 42
10.1. Funciones de Espera ................................................................................ 42
10.2. Objetos de Sincronización ......................................................................... 42
10.3. Objetos de Sección Crítica ........................................................................ 44
CONCLUSIONES ....................................................................................................... 45
BIBLIOGRAFÍA ........................................................................................................... 47
Ingeniería de Sistemas Página 4
SISTEMAS OPERATIVOS
LISTA DE ILUSTRACIONES
Ilustración 1: Uso de un semáforo para proteger los recursos. (a) Un recurso. (b) Dos
recursos ........................................................................................................................ 8
Ilustración 2: (a) Código libre de interbloqueos. (b) Código con potencial de
interbloqueo. ................................................................................................................. 9
Ilustración 3- Gráficos de asignación de recursos. (a) Contención de un recurso. (b)
Petición de un recurso. (c) Interbloqueo ..................................................................... 10
Ilustración 4: (a) Proceso con interbloqueo (b) Sección con Interbloqueo ................ 12
Ilustración 5: Estructurad de datos para detección de interbloqueos con recursos
múltiples ..................................................................................................................... 14
Ilustración 6: Trayectorias de recursos de dos procesos ............................................. 17
Ilustración 7: Demostración de que el estado en (a) es seguro. .................................. 18
Ilustración 8: Demostración de que el estado en (b) no es seguro. ............................. 19
Ilustración 9: Tres estados de asignación de recursos: (a) Seguro. (b) Seguro. (c)
Inseguro...................................................................................................................... 20
Ilustración 10: El algoritmo del banquero con varios recursos..................................... 21
Ilustración 11: (a) Recursos ordenados en forma numérica. (b) Un gráfico de recursos
................................................................................................................................... 24
Ilustración 12: Resumen de los métodos para evitar interbloqueos............................. 25
Ilustración 13: Disposición para los filósofos comensales. .......................................... 26
Ilustración 14: Solución 1 (Problema de los filósofos comensales) ............................. 27
Ilustración 15: Solución 2 (Problema de los filósofos comensales) ............................. 27
Ilustración 16: Solución 3 (Problema de los filósofos comensales) ............................. 29
Ilustración 17: Operaciones disponibles con señales .................................................. 32
Ilustración 18: Operaciones atómicas en Linux ........................................................... 34
Ilustración 19: Cerrojos cíclicos en Linux .................................................................... 35
Ilustración 20: Semáforos en Linux ............................................................................. 38
Ilustración 21: Barreras en Linux ................................................................................ 39
Ilustración 22: Estructura de Datos de Sincronización de Solaris ................................ 39
Ilustración 23:Uso de la función cv_wait() ................................................................... 42
Ilustración 24: Objetos de sincronización en Windows ................................................ 42
Ingeniería de Sistemas Página 5
SISTEMAS OPERATIVOS
INTRODUCCIÓN
Los sistemas computacionales están llenos de recursos que pueden ser utilizados por
sólo un proceso a la vez sin embargo cuando dos procesos escriben de manera
simultánea en uno de estos recursos se producen incoherencias. En consecuencia,
todos los sistemas operativos tienen la habilidad de otorgar (en forma temporal) a un
proceso el acceso exclusivo a ciertos recursos.
Para muchas aplicaciones, un proceso necesita acceso exclusivo no sólo a un recurso,
sino a varios. Por ejemplo, suponga que cada uno de dos procesos quiere grabar un
documento digitalizado en un CD. El proceso A pide permiso para utilizar el escáner y
se le otorga. El proceso B se programa de manera distinta y solicita primero el grabador
de CDs, y también se le otorga. Ahora A pide el grabador de CDs, pero la petición se
rechaza hasta que B lo libere. Por desgracia, en vez de liberar el grabador de CD, B
pide el escáner. En este punto ambos procesos están bloqueados y permanecerán así
para siempre. A esta situación se le conoce como interbloqueo.
DESARROLLO
Ingeniería de Sistemas Página 6
SISTEMAS OPERATIVOS
1. Recursos
Los recursos vendrían a ser los objetos exclusivos otorgados a diferentes
procesos, estos pueden ser un dispositivo de hardware (por ejemplo, una unidad
de cinta) o una pieza de información (como un registro bloqueado en una base
de datos). Por lo general, una computadora tendrá muchos recursos que se
pueden adquirir.
Cuando hay disponibles varias copias de un recurso, se puede utilizar sólo una
de ellas para satisfacer cualquier petición de ese recurso. En resumen, un
recurso es cualquier cosa que se debe adquirir, utilizar y liberar con el transcurso
del tiempo.
1.1. Recursos apropiativos y no apropiativos
Los recursos son de dos tipos: apropiativos y no apropiativos.
1.1.1. Recurso apropiativo:
Es aquel recurso que se puede quitar al proceso que lo posee
sin efectos dañinos. Ejemplo
La memoria, si un proceso A tiene la impresora y un proceso B
tiene la memoria, y ninguno puede proceder sin el recurso que el otro
posee, esto originaria un indicio de interbloqueo, sin embargo, es
posible apropiarse (quitar) de la memoria de B al intercambiarlo y
colocar el proceso A de vuelta. Ahora A se puede ejecutar, realizar su
impresión y después liberar la impresora. Así no ocurre ningún
interbloqueo.
1.1.2. Recurso no apropiativo:
Es aquel recurso que no se puede quitar a su propietario actual
sin hacer que el cómputo falle. Ejemplo
Si un proceso ha empezado a quemar un CD-ROM y tratamos
de quitarle de manera repentina el grabador de CD y otorgarlo a otro
proceso, se obtendrá un CD con basura. Los grabadores de CD no
son apropiativos en un momento arbitrario.
En general, los interbloqueos involucran a los recursos no
apropiativos. Los interbloqueos potenciales que pueden involucrar a
los recursos apropiativos por lo general se pueden resolver mediante
la reasignación de los recursos de un proceso a otro.
Ingeniería de Sistemas Página 7
SISTEMAS OPERATIVOS
1.2. Adquisición de recursos
La secuencia de eventos requerida para utilizar un recurso se
proporciona a continuación, en un formato abstracto.
1. Solicitar el recurso.
2. Utilizar el recurso.
3. Liberar el recurso.
Los tres pasos antes listados se implementan como una operación
down para adquirir el recurso, usarlo y finalmente realizar una operación
up en el recurso para liberarlo.
1.2.1. Recurso adquirido por solo 1 proceso
Algunas veces los procesos necesitan dos o más recursos. Si
solo es uno que solicite estos recursos, se pueden adquirir de manera
secuencial, como se muestra en la figura (b). Si se necesitan más de
dos recursos, sólo se adquieren uno después del otro.
Ilustración 1: Uso de un semáforo para proteger los recursos. (a) Un recurso. (b) Dos recursos
1.2.2. Recurso adquirido por 2 o más procesos
Ahora consideremos una situación con dos procesos, A y B, y
dos recursos. En la figura 6-2 se ilustran dos escenarios. En la figura
6-2(a), ambos procesos piden los recursos en el mismo orden. En la
figura 6-2(b), los piden en un orden distinto.
− En la figura (a), uno de los procesos adquirirá el primer recurso
antes del otro. Después ese proceso adquirirá con éxito el
segundo recurso y realizará su trabajo. Si el otro proceso
intenta adquirir el recurso 1 antes de que sea liberado, el otro
proceso simplemente se bloqueará hasta que esté disponible.
Ingeniería de Sistemas Página 8
SISTEMAS OPERATIVOS
En la figura (b), la situación es distinta. Podría ocurrir
que uno de los procesos adquiera ambos recursos y en efecto
bloquee al otro proceso hasta que termine. Sin embargo,
también podría ocurrir que el proceso A adquiera el recurso 1
y el proceso B adquiera el recurso 2. Ahora cada uno se
bloqueará al tratar de adquirir el otro. Ninguno de los procesos
se volverá a ejecutar. Esa situación es un interbloqueo.
Ilustración 2: (a) Código libre de interbloqueos. (b) Código con potencial de interbloqueo.
2. Interbloqueo
“Un conjunto de procesos se encuentra en un interbloqueo si cada
proceso en el conjunto está esperando un evento que sólo puede ser ocasionado
por otro proceso en el conjunto”.
Debido a que todos los procesos están en espera, ninguno de ellos producirá
alguno de los eventos que podrían despertar a cualquiera de los otros miembros
del conjunto, y todos los procesos seguirán esperando para siempre. En otras
palabras, ninguno de los procesos se puede ejecutar, ninguno de ellos puede
liberar recursos y ninguno puede ser despertado.
Este resultado se aplica a cualquier tipo de recurso, tanto de hardware
como de software. A este tipo de interbloqueo se le conoce como interbloqueo
de recursos. Es probablemente el tipo más común, pero no el único. Para este
modelo suponemos que los procesos tienen sólo un hilo y que no hay
interrupciones posibles para despertar a un proceso bloqueado.
Ingeniería de Sistemas Página 9
SISTEMAS OPERATIVOS
2.1. Condiciones para los interbloqueos de recursos
Coffman y colaboradores (1971) mostraron que deben aplicarse
cuatro condiciones para un interbloqueo (de recursos):
1. Condición de exclusión mutua: Cada recurso se asigna en un
momento dado a sólo un proceso, o está disponible.
2. Condición de contención y espera: Los procesos que
actualmente contienen recursos que se les otorgaron antes
pueden solicitar nuevos recursos.
3. Condición no apropiativa: Los recursos otorgados previamente
no se pueden quitar a un proceso por la fuerza. Deben ser
liberados de manera explícita por el proceso que los contiene.
4. Condición de espera circular: Debe haber una cadena circular
de dos o más procesos, cada uno de los cuales espera un recurso
contenido por el siguiente miembro de la cadena.
2.2. Modelo de Interbloqueo
Holt (1972) mostró cómo se pueden modelar estas cuatro
condiciones mediante el uso de gráficos dirigidos. Los gráficos tienen dos
tipos de nodos: procesos, que se muestran como círculos, y recursos,
que se muestran como cuadros. Un arco dirigido de un nodo de recurso
(cuadro) a un nodo de proceso (círculo) significa que el recurso fue
solicitado previamente por, y asignado a, y actualmente es contenido por
ese proceso.
Ilustración 3- Gráficos de asignación de recursos. (a) Contención de un recurso. (b)
Petición de un recurso. (c) Interbloqueo
En la figura 6-3(c) podemos ver un interbloqueo: el proceso C está
esperando al recurso T, que actualmente es contenido por el proceso D. El
proceso D no va a liberar al recurso T debido a que está esperando el recurso
U, contenido por C. Ambos procesos esperarán para siempre.
Ingeniería de Sistemas Página 10
SISTEMAS OPERATIVOS
3. El Algoritmo del Avestruz
En general, se utilizan cuatro estrategias para lidiar con los interbloqueos.
• Sólo ignorar el problema. Tal vez si usted lo ignora, él lo ignorará a usted.
• Detección y recuperación. Dejar que ocurran los interbloqueos,
detectarlos y tomar acción.
• Evitarlos en forma dinámica mediante la asignación cuidadosa de los
recursos.
• Prevención, al evitar estructuralmente una de las cuatro condiciones
requeridas.
El método más simple es el algoritmo del avestruz: meta su cabeza en la
arena y pretenda que no hay ningún problema. Si ocurren interbloqueos en
promedio de una vez cada cinco años, pero los fallos del sistema debido al
hardware, errores del compilador y errores en el sistema operativo ocurren una
vez por semana, la mayoría de los ingenieros no estarán dispuestos a reducir
considerablemente el rendimiento por la conveniencia de eliminar los
interbloqueos.
4. Detección y recuperación de un Interbloqueo
4.1. Conceptos:
Detección: El concepto nos dice que es la localización de algo que es
difícil de observar a simple vista, para que en un sistema operativo
detecte un interbloqueo, se realiza un algoritmo que le permite detectar
la condición de espera circular que produce un interbloqueo.
Recuperación: El concepto nos dice que es volver a adquirir aquello que
se tuvo en algún momento previo, una vez que se ha detectado el
interbloqueo se necesita alguna estrategia para recuperarlo, para ello se
hace uso de estrategias que veremos a luego.
La técnica de detección y recuperación no trata de evitar los
interbloqueos, intenta detectarlos cuando ocurran y luego realiza cierta
acción para recuperarse después del hecho.
4.2. Detección de interbloqueos con un recurso de cada tipo
Vamos a empezar con el caso más simple, solo existe un recurso
de cada tipo. Dicho sistema podría tener un escáner, un grabador de CD,
un trazador (plotter) y una unidad de cinta, pero no más que un recurso
de cada clase. Para un sistema así, podemos construir un gráfico de
recursos. Si este gráfico contiene uno o más ciclos, existe un
Ingeniería de Sistemas Página 11
SISTEMAS OPERATIVOS
interbloqueo. Cualquier proceso que forme parte de un ciclo está en
interbloqueo. Si no existen ciclos, el sistema no está en interbloqueo.
Como ejemplo, considere un sistema con siete procesos, A-G, y
seis recursos, R-W. Los estados de los recursos son:
1. El proceso A contiene a R y quiere a S.
2. El proceso B no contiene ningún recurso, pero quiere a T.
3. El proceso C no contiene ningún recurso, pero quiere a S.
4. El proceso D contiene a U y quiere a S y a T.
5. El proceso E contiene a T y quiere a V.
6. El proceso F contiene a W y quiere a S.
7. El proceso G contiene a V y quiere a U.
Ilustración 4: (a) Proceso con interbloqueo (b) Sección con Interbloqueo
Es relativamente fácil distinguir los procesos en interbloqueo a
simple vista a partir de un sencillo gráfico, para usar este método en
sistemas reales necesitamos un algoritmo formal para la detección de
interbloqueos.
Hay muchos algoritmos conocidos para detectar ciclos en gráficos
dirigidos. A continuación, veremos un algoritmo simple que inspecciona
un gráfico y termina al haber encontrado un ciclo, o cuando ha
demostrado que no existe ninguno.
Utiliza cierta estructura dinámica de datos: L, una lista de nodos,
así como la lista de arcos. Durante el algoritmo, los arcos se marcarán
para indicar que ya han sido inspeccionados, para evitar repetir
inspecciones.
El algoritmo opera al llevar a cabo los siguientes pasos, según lo
especificado:
1. Para cada nodo N en el gráfico, realizar los siguientes cinco pasos
Ingeniería de Sistemas Página 12
SISTEMAS OPERATIVOS
con N como el nodo inicial.
2. Inicializar L con la lista vacía y designar todos los arcos como
desmarcados.
3. Agregar el nodo actual al final de L y comprobar si el nodo ahora
aparece dos veces en L.
4. Si lo hace, el gráfico contiene un ciclo (listado en L) y el algoritmo
termina.
5. Del nodo dado, ver si hay arcos salientes desmarcados. De ser
así, ir al paso 5; en caso contrario, ir al paso
6. Elegir un arco saliente desmarcado al azar y marcarlo. Después
seguirlo hasta el nuevo nodo actual e ir al paso 3.
7. Si este nodo es el inicial, el gráfico no contiene ciclos y el algoritmo
termina. En caso contrario, ahora hemos llegado a un punto
muerto. Eliminarlo y regresar al nodo anterior.
Lo que hace este algoritmo es tomar cada nodo en turno, como la
raíz de lo que espera sea un árbol, y realiza una búsqueda de un nivel de
profundidad en él. Si alguna vez regresa a un nodo que ya se haya
encontrado, entonces ha encontrado un ciclo. Si agota todos los arcos
desde cualquier nodo dado, regresa al nodo anterior. Si regresa hasta la
raíz y no puede avanzar más, el subgráfico que se puede alcanzar desde
el nodo actual no contiene ciclos. Si esta propiedad se aplica para todos
los nodos, el gráfico completo está libre de ciclos, por lo que el sistema
no está en interbloqueo.
4.3. Detección del interbloqueo con varios recursos de cada tipo
Cuando existen varias copias de algunos de los recursos, se
necesita un método distinto para detectar interbloqueos. Ahora
presentaremos un algoritmo basado en matrices para detectar
interbloqueos entre n procesos, de P1 a Pn. Hagamos que el número de
clases de recursos sea m, con E1 recursos de la clase 1, E2 recursos de
la clase 2 y en general, Ei recursos de la clase i (1 <= i =< m). E es el
vector de recursos existentes. Este vector proporciona el número total de
instancias de cada recurso en existencia. Por ejemplo, si la clase 1 son
las unidades de cinta, entonces E1 = 2 significa que el sistema tiene dos
unidades de cinta.
En cualquier instante, algunos de los recursos están asignados y
no están disponibles. Hagamos que A sea el vector de recursos
disponibles, donde Ai proporciona el número de instancias del recurso i
Ingeniería de Sistemas Página 13
SISTEMAS OPERATIVOS
que están disponibles en un momento dado (es decir, sin asignar). Si
ambas de nuestras unidades de cinta están asignadas, A1 será 0.
Ahora necesitamos dos arreglos: C, la matriz de asignaciones
actuales y R, la matriz de peticiones. La i-ésima fila de C nos indica
cuántas instancias de cada clase de recurso contiene Bi en un momento
dado. Así Cij es el número de instancias del recurso j que están
contenidas por el proceso i. De manera similar, Rij es el número de
instancias del recurso j que desea Bi. Estas cuatro estructuras de datos
son:
Ilustración 5: Estructurad de datos para detección de interbloqueos con recursos múltiples
En otras palabras, si agregamos todas las instancias del recurso j
que se han asignado, y para ello agregamos todas las instancias
disponibles, el resultado es el número de instancias existentes de esa
clase de recursos.
El algoritmo de detección de interbloqueos se basa en la
comparación de vectores y muestra a continuación.
1. Buscar un proceso desmarcado, Pi, para el que la i-ésima fila de
R sea menor o igual que A.
2. Si se encuentra dicho proceso, agregar la i-ésima fila de C a A,
marcar el proceso y regresar al paso 1.
3. Si no existe dicho proceso, el algoritmo termina.
Cuando el algoritmo termina, todos los procesos desmarcados (si
los hay) están en interbloqueo.
Lo que hace el algoritmo en el paso 1 es buscar un proceso que
se pueda ejecutar hasta completarse. Dicho proceso se caracteriza por
tener demandas de recursos que se pueden satisfacer con base en los
recursos disponibles actuales. Entonces, el proceso seleccionado se
Ingeniería de Sistemas Página 14
SISTEMAS OPERATIVOS
ejecuta hasta que termina, momento en el que devuelve los recursos que
contiene a la reserva de recursos disponibles. Después se marca como
completado. Si todos los procesos pueden en última instancia ejecutarse
hasta completarse, ninguno de ellos está en interbloqueo. Si algunos de
ellos nunca pueden terminar, están en interbloqueo. Aunque el algoritmo
no es determinístico (debido a que puede ejecutar los procesos en
cualquier orden posible), el resultado siempre es el mismo.
Ahora que sabemos cómo detectar interbloqueos (por lo menos
cuando se conocen de antemano las peticiones de recursos estáticas),
surge la pregunta sobre cuándo buscarlos. Una posibilidad es comprobar
cada vez que se realiza una petición de un recurso. Esto sin duda los
detectará lo más pronto posible, pero es potencialmente costoso en
términos de tiempo de la CPU. Una estrategia alternativa es comprobar
cada k minutos, o tal vez sólo cuando haya disminuido el uso de la CPU
por debajo de algún valor de umbral. La razón de esta consideración es
que, si hay suficientes procesos en interbloqueo, habrá pocos procesos
ejecutables y la CPU estará inactiva con frecuencia.
4.4. Recuperación de un interbloqueo:
Algunas formas de recuperarse de un interbloqueo detectado son:
4.4.1. Recuperación por medio de apropiación:
En algunos casos puede ser posible quitar temporalmente un
recurso a su propietario actual y otorgarlo a otro proceso. En muchos
casos se puede requerir intervención manual, en especial en los
sistemas operativos de procesamiento por lotes que se ejecutan en
mainframes.
Por ejemplo, para quitar una impresora láser a su propietario, el
operador puede recolectar todas las hojas ya impresas y colocarlas
en una pila. Después se puede suspender el proceso (se marca como
no ejecutable). En este punto, la impresora se puede asignar a otro
proceso. Cuando ese proceso termina, la pila de hojas impresas se
puede colocar de vuelta en la bandeja de salida de la impresora y se
puede reiniciar el proceso original.
4.4.2. Recuperación a través del retroceso:
Los procesos realizan puntos de comprobación en forma
periódica, realizar puntos de comprobación en un proceso significa
que su estado se escribe en un archivo para poder reiniciarlo más
Ingeniería de Sistemas Página 15
SISTEMAS OPERATIVOS
tarde. El punto de comprobación no sólo contiene la imagen de la
memoria, sino también el estado del recurso; en otras palabras, qué
recursos están asignados al proceso en un momento dado. Para que
sean más efectivos, los nuevos puntos de comprobación no deben
sobrescribir a los anteriores, sino que deben escribirse en nuevos
archivos, para que se acumule una secuencia completa a medida que
el proceso se ejecute.
Cuando se detecta un interbloqueo, es fácil ver cuáles
recursos se necesitan. Para realizar la recuperación, un proceso que
posee un recurso necesario se revierte a un punto en el tiempo antes
de que haya adquirido ese recurso, para lo cual se inicia uno de sus
puntos de comprobación anteriores.
4.4.3. Recuperación a través de la eliminación de procesos:
La forma más cruda y simple de romper un interbloqueo es
eliminar uno o más procesos. Una posibilidad es eliminar a uno de los
procesos en el ciclo. Con un poco de suerte, los demás procesos
podrán continuar. Si esto no ayuda, se puede repetir hasta que se
rompa el ciclo.
De manera alternativa, se puede elegir como víctima a un
proceso que no esté en el ciclo, para poder liberar sus recursos. En
este método, el proceso a eliminar se elige con cuidado, debido a que
está conteniendo recursos que necesita cierto proceso en el ciclo.
Por ejemplo, un proceso podría contener una impresora y
querer un trazador, en donde otro proceso podría contener un
trazador y querer una impresora. Estos dos procesos están en
interbloqueo. Un tercer proceso podría contener otra impresora
idéntica y otro trazador idéntico, y estar felizmente en ejecución. Al
eliminar el tercer proceso se liberarán estos recursos y se romperá el
interbloqueo que involucra a los primeros dos.
Donde sea posible, es mejor eliminar un proceso que se pueda
volver a ejecutar desde el principio sin efectos dañinos.
5. Cómo evitar un Interbloqueo
Existen 4 formas de evitar el interbloqueo mediante una asignación cuidadosa
de los recursos.
5.1. Trayectoria de recursos
Los principales algoritmos para evitar interbloqueos se basan en
Ingeniería de Sistemas Página 16
SISTEMAS OPERATIVOS
el concepto de los estados seguros.
En la siguiente imagen podemos ver un modelo para lidiar con dos
procesos y dos recursos, una impresora y un trazador. El eje horizontal
representa el número de instrucciones ejecutadas por el proceso A, y, por
otro lado, el eje vertical representa el número de instrucciones ejecutadas
por el proceso B.
Ilustración 6: Trayectorias de recursos de dos procesos
En I1, A solicita una impresora; en I2 necesita un trazador. La
impresora y el trazador se liberan en I3 y en I4, respectivamente. El
proceso B necesita el trazador de I5 a I7, y la impresora de I6 a I8.
Cada punto en el diagrama representa un estado conjunto de los
dos procesos. Al principio el estado está en p, en donde ninguno de los
procesos ha ejecutado instrucciones. Si el programador opta por ejecutar
primero que A, llegamos al punto 1, en el que A ha ejecutado cierto
número de instrucciones, pero B no ha ejecutado ninguna. En el punto q,
la trayectoria se vuelve vertical, indicando que el programador ha optado
por ejecutar a B. Cuando A cruza con la línea I1 en la ruta de r a s, solicita
la impresora y se le otorga. Cuando B llega al punto t, solicita el trazador.
Las regiones sombreadas son en especial interesantes. La región
con las líneas que se inclinan de suroeste a noreste representa cuando
ambos procesos tienen la impresora. La regla de exclusión mutua hace
imposible entrar a esta región. De manera similar, la región sombreada
de la otra forma representa cuando ambos procesos tienen el trazador, y
es igual de imposible.
Ingeniería de Sistemas Página 17
SISTEMAS OPERATIVOS
Si el sistema entra alguna vez al cuadro delimitado por I1 e I2 en
los lados, y por I5 e I6 en la parte superior e inferior, entrará en
interbloqueo en un momento dado, cuando llegue a la intersección de I2
e I6. En este punto, A está solicitando el trazador y B la impresora, y
ambos recursos ya están asignados. Todo el cuadro es inseguro y no se
debe entrar en él. En el punto t, lo único seguro por hacer es ejecutar el
proceso A hasta que llegue a I4. Más allá de eso, cualquier trayectoria
hasta u bastará.
Lo importante a considerar aquí es que en el punto t, B está
solicitando un recurso. El sistema debe decidir si lo otorga o no. Si se
otorga el recurso, el sistema entrará en una región insegura y en el
interbloqueo, en un momento dado. Para evitar el interbloqueo, B se debe
suspender hasta que A haya solicitado y liberado el trazador.
5.2. Estados seguros e inseguros
Se dice que un estado es seguro si hay cierto orden de
programación en el que se puede ejecutar cada proceso hasta
completarse, incluso aunque todos ellos solicitaran de manera repentina
su número máximo de recursos de inmediato.
En la figura que se mostrará a continuación, tenemos un estado
en el que A tiene 3 instancias del recurso, pero puede necesitar hasta 9
en un momento dado. En la actualidad B tiene 2 y puede necesitar 4 en
total, más adelante. De manera similar, C también tiene 2, pero puede
necesitar 5 más.
Estado Seguro
Ilustración 7: Demostración de que el estado en (a) es seguro.
El estado de la figura (a) es seguro, debido a que existe una
secuencia de asignaciones que permite completar todos los procesos. El
programador podría simplemente ejecutar B, lo cual nos lleva al estado
de la figura (b). Al completarse B, obtenemos el estado de la figura (c).
Ingeniería de Sistemas Página 18
SISTEMAS OPERATIVOS
Después se puede ejecutar C, con lo que obtendríamos la figura (d).
Cuando C se complete, obtendremos la figura(e). Ahora A puede obtener
las seis instancias del recurso que necesita y también completarse. Por
ende, el estado de la figura (a) es seguro ya que el sistema, mediante
una programación cuidadosa, puede evitar el interbloqueo.
Estado Inseguro
Ahora, supongamos que tenemos el estado inicial que se muestra
en la figura (a), pero esta vez A solicita y obtiene otro recurso, con lo que
obtenemos la figura (b).
Ilustración 8: Demostración de que el estado en (b) no es seguro.
Se podrá ejecutar a B hasta que pida todos sus recursos, como
se muestra en la figura (c). Sin embargo, cuando B se complete,
llegaremos a la situación de la figura (d). En este punto estamos atorados.
Sólo tenemos cuatro instancias del recurso libres, y cada uno de los
procesos activos necesita cinco. No hay una secuencia que garantice que
los procesos se completarán. Así, la decisión de asignación que cambió
al sistema de la figura (a) a la figura (b) pasó de un estado seguro a uno
inseguro. En retrospectiva, la petición de A no debería haberse otorgado.
Un estado inseguro no es un estado en interbloqueo. La diferencia
entre un estado seguro y uno inseguro es que, desde un estado seguro,
el sistema puede garantizar que todos los procesos terminarán; desde un
estado inseguro, no se puede dar esa garantía.
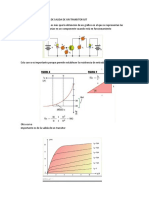
5.3. El algoritmo del banquero para un solo recurso
El algoritmo del banquero es un algoritmo de programación ideado
por Dijkstra en 1965 con el objetivo de evitar interbloqueos. Este
algoritmo usualmente es explicado usando la analogía con el
funcionamiento de un banco. Los clientes representan a los procesos,
que tienen un crédito límite, y el dinero representa a los recursos. El
banquero es el sistema operativo. Lo que hace el algoritmo es comprobar
Ingeniería de Sistemas Página 19
SISTEMAS OPERATIVOS
si al otorgar la petición se produce un estado inseguro.
Ilustración 9: Tres estados de asignación de recursos: (a) Seguro. (b) Seguro. (c) Inseguro.
Los clientes hacen sus respectivas labores, pidiendo préstamos
de vez en cuando (es decir, solicitando recursos). En cierto momento, la
situación es como se muestra en la figura (b). Este estado es seguro
debido a que, con dos unidades restantes, el banquero puede retrasar
cualquier petición excepto la de C, con lo cual deja que C termine y libere
todos sus cuatro recursos. Con cuatro unidades a la mano, el banquero
puede dejar que D o B tengan las unidades necesarias, y así
sucesivamente.
Considere lo que ocurriría si se otorgara una petición de B por una
o más unidades en la figura (b). Tendríamos la situación de la figura(c),
que es insegura. Si todos los clientes pidieran de manera repentina sus
préstamos máximos, el banquero no podría satisfacer a ninguno de ellos,
y tendríamos un interbloqueo.
Un estado inseguro no tiene que conducir a un interbloqueo, ya
que un cliente tal vez no necesitaría toda la línea de crédito disponible,
pero el banquero no podría contar con este comportamiento.
El algoritmo del banquero considera cada petición a medida que
va ocurriendo, y analiza si al otorgarla se produce un estado seguro. Si
es así, se otorga la petición; en caso contrario, se pospone hasta más
tarde. Para ver si un estado es seguro, el banquero comprueba si tiene
los suficientes recursos para satisfacer a algún cliente. De ser así, se
asume que esos préstamos volverán a pagarse y ahora se comprueba el
cliente más cercano al límite, etcétera. Si todos los préstamos se pueden
volver a pagar en un momento dado, el estado es seguro y la petición
inicial se puede otorgar.
Ingeniería de Sistemas Página 20
SISTEMAS OPERATIVOS
5.4. El algoritmo del banquero para varios recursos
El algoritmo del banquero se puede generalizar para manejar
varios recursos.
En la siguiente figura se muestran dos matrices. La de la izquierda
muestra cuántas instancias de cada recurso están asignadas a cada uno
de los cinco procesos. La matriz de la derecha muestra cuántos recursos
sigue necesitando cada proceso para poder completarse.
Ilustración 10: El algoritmo del banquero con varios recursos
Los tres vectores a la derecha de la figura muestran los recursos
existentes (E), los recursos poseídos (P) y los recursos disponibles (A).
De E podemos ver que el sistema tiene seis unidades de cinta, tres
trazadores, cuatro impresoras y dos unidades de CD-ROM. De éstos, ya
hay asignados cinco unidades de cinta, tres trazadores, dos impresoras
y dos unidades de CD-ROM. Este hecho puede verse al agregar las
cuatro columnas de recursos en la matriz izquierda. El vector de recursos
disponibles es simplemente la diferencia entre lo que tiene el sistema y
lo que está en uso en un momento dado.
Pasos para comprobar si un estado es seguro:
1) Buscar una fila R, cuyas necesidades de recursos no satisfechas
sean menores o iguales que A. Si no existe dicha fila, el sistema
entrará en interbloqueo en un momento dado, debido a que ningún
proceso se podrá ejecutar hasta completarse (suponiendo que los
procesos mantienen todos los recursos hasta que terminan).
2) Suponer que el proceso seleccionado de la fila solicita todos los
recursos que necesita (lo que se garantiza que es posible) y
Ingeniería de Sistemas Página 21
SISTEMAS OPERATIVOS
termina. Marcar ese proceso como terminado y agregar todos sus
recursos al vector A.
3) Repetir los pasos 1 y 2 hasta que todos los procesos se marquen
como terminados (en cuyo caso el estado inicial era seguro) o hasta
que no haya ningún proceso cuyas necesidades de recursos se
puedan satisfacer (en cuyo caso hay un interbloqueo).
Podemos concluir que el estado actual es seguro. Sin embargo, si
el proceso B ahora pide la impresora, y si después de otorgar a B una de
las dos impresoras restantes, E quiere la última impresora. Al otorgar esa
petición se reduciría el vector de recursos disponibles a (1 0 0 0), lo cual
produce un interbloqueo.
6. Como prevenir interbloqueos
Evitar los interbloqueos es algo en esencia imposible, debido a que se requiere
información sobre las peticiones futuras, que no se conocen. Los sistemas reales
evitan los interbloqueos volviendo a las cuatro condiciones establecidas por
Coffman y colaboradores (1971) para ver si pueden proporcionarnos una pista.
Si podemos asegurar que por lo menos una de estas condiciones nunca se
cumpla, entonces los interbloqueos serán estructuralmente imposibles
(Havender, 1968).
6.1. Cómo atacar la condición de exclusión mutua
Si ningún recurso se asignara de manera exclusiva a un solo proceso, nunca
tendríamos interbloqueos. Al permitir que dos procesos escriban en la impresora
al mismo tiempo se producirá un caos. Al colocar la salida de la impresora en
una cola de impresión, varios procesos pueden generar salida al mismo tiempo.
En este modelo, el único proceso que realmente solicita la impresora física es el
demonio de impresión. Como el demonio nunca solicita ningún otro recurso,
podemos eliminar el interbloqueo para la impresora. Si el demonio se programa
para imprimir aún y cuando toda la salida esté en una cola de impresión, la
impresora podría permanecer inactiva si un proceso de salida decide esperar
varias horas después de la primera ráfaga de salida. Por esta razón, los
demonios comúnmente se programan para imprimirse sólo hasta después que
esté disponible el archivo de salida completo. Sin embargo, esta decisión en sí
podría provocar un interbloqueo. Si dos procesos llenaran cada uno una mitad
Ingeniería de Sistemas Página 22
SISTEMAS OPERATIVOS
del espacio de la cola de impresión disponible con datos de salida y ninguno
terminara de producir su salida completa, tendríamos dos procesos en los que
cada uno ha terminado una parte, pero no toda su salida, y no pueden continuar.
Ninguno de los procesos terminará nunca, por lo que tenemos un interbloqueo
en el disco. Sin embargo, hay un germen de una idea aquí, que se aplica con
frecuencia: evite asignar un recurso cuando no sea absolutamente necesario, y
trate de asegurarse que la menor cantidad posible de procesos reclamen ese
recurso.
6.2. Cómo atacar la condición de contención y espera
Si podemos evitar que los procesos que contienen recursos esperen por más
recursos, podemos eliminar los interbloqueos. Una forma de lograr esta meta es
requerir que todos los procesos soliciten todos sus recursos antes de empezar
su ejecución. Si todo está disponible, al proceso se le asignará lo que necesite y
podrá ejecutarse hasta completarse. Si uno o más recursos están ocupados, no
se asignará nada y el proceso sólo esperará. Un problema inmediato con este
método es que muchos procesos no saben cuántos recursos necesitarán hasta
que hayan empezado a ejecutarse. De hecho, si lo supieran se podría utilizar el
algoritmo del banquero. Otro problema es que los recursos no se utilizarán de
una manera óptima con este método. Sin embargo, algunos sistemas de
procesamiento por lotes de mainframes requieren que el usuario liste todos los
recursos en la primera línea de cada trabajo. Después el sistema adquiere todos
los recursos de inmediato, y los mantiene hasta que el trabajo termina. Aunque
este método impone una carga sobre el programador y desperdicia recursos,
evita los interbloqueos. Una manera ligeramente distinta de romper la condición
de contención y espera es requerir que un proceso que solicita un recurso libere
temporalmente todos los recursos que contiene en un momento dado. Después
puede tratar de obtener todo lo que necesite a la vez.
6.3. Cómo atacar la condición no apropiativa
Si a un proceso se le ha asignado la impresora y está a la mitad de imprimir su
salida, quitarle la impresora a la fuerza debido a que el trazador que necesita no
está disponible es algo engañoso como máximo, e imposible en el peor caso.
Sin embargo, ciertos recursos se pueden virtualizar para evitar esta situación. Al
colocar en una cola de impresión en el disco la salida de la impresora y permitir
Ingeniería de Sistemas Página 23
SISTEMAS OPERATIVOS
que sólo el demonio de impresión tenga acceso a la impresora real, se eliminan
los interbloqueos que involucran a la impresora, aunque se crea uno para el
espacio en disco. No obstante, con los discos grandes es muy improbable
quedarse sin espacio. Sin embargo, no todos los recursos se pueden virtualizar
de esta manera. Por ejemplo, los registros en las bases de datos o las tablas
dentro del sistema operativo se deben bloquear para poder utilizarse, y ahí es
donde se encuentra el potencial para el interbloqueo.
6.4. Cómo atacar la condición de espera circular
Sólo queda una condición. La espera circular se puede eliminar de varias formas.
Una de ellas es simplemente tener una regla que diga que un proceso tiene
derecho sólo a un recurso en cualquier momento. Si necesita un segundo
recurso, debe liberar el primero. Para un proceso que necesita copiar un enorme
archivo de una cinta a una impresora, esta restricción es inaceptable. Otra
manera de evitar la espera circular es proporcionar una numeración global de
todos los recursos, como se muestra en la figura 6-13(a). Ahora la regla es ésta:
los procesos pueden solicitar recursos cada vez que quieran, pero todas las
peticiones se deben realizar en orden numérico. Un proceso puede pedir primero
una impresora y después una unidad de cinta, pero tal vez no pueda pedir
primero un trazador y después una impresora.
Ilustración 11: (a) Recursos ordenados en forma numérica. (b) Un gráfico de recursos
Con esta regla, el gráfico de asignación de recursos nunca puede tener ciclos.
En la figura 6-13(b). Podemos obtener un interbloqueo sólo si A solicita el recurso
j y B solicita el recurso i. Suponiendo que i y j sean recursos distintos, tendrán
diferentes números. Si i > j, entonces A no puede solicitar a j debido a que es
menor de lo que ya tiene. Si i < j, entonces B no puede solicitar a i debido a que
es menor de lo que ya tiene. De cualquier forma, el interbloqueo es imposible.
Con más de dos procesos se aplica la misma lógica. En cada instante, uno de
Ingeniería de Sistemas Página 24
SISTEMAS OPERATIVOS
los recursos asignados será el más alto. El proceso que contiene ese recurso
nunca pedirá un recurso que ya esté asignado. Terminará o, en el peor caso,
solicitará recursos con mayor numeración, los cuales están disponibles. En un
momento dado, terminará y liberará sus recursos. En este punto, algún otro
proceso contendrá el recurso más alto y también podrá terminar. En resumen,
existe un escenario en el que todos los procesos terminan, por lo que no hay
interbloqueo presente. Una variación menor de este algoritmo es retirar el
requerimiento de que los recursos se adquieran en una secuencia cada vez más
estricta, y simplemente insistir que ningún proceso puede solicitar un recurso
menor del que ya contiene. Si al principio un proceso solicita 9 y 10, y después
libera ambos recursos, en efecto está empezando otra vez, por lo que no hay
razón de prohibirle que solicite el recurso 1. Aunque el ordenamiento numérico
de los recursos elimina el problema de los interbloqueos, puede ser imposible
encontrar un ordenamiento que satisfaga a todos. Cuando los recursos incluyen
entradas en la tabla de procesos, espacio en la cola de impresión del disco,
registros bloqueados de la base de datos y otros recursos abstractos, el número
de recursos potenciales y usos distintos puede ser tan grande que ningún
ordenamiento podría funcionar. Los diversos métodos para evitar el interbloqueo
se sintetizan en la figura 6-14.
Ilustración 12: Resumen de los métodos para evitar interbloqueos
7. Problema de los filósofos comensales
El problema de los filósofos comensales es, como su mismo nombre lo indica,
un problema que fue presentado por Dijkstra en el año de 1965.
El cual presenta una situación en la que se encuentran 5 filósofos viviendo en
una casa, quienes llevan una vida que consiste en pensar y comer, para esto,
los filósofos viven en una casa en la cual hay una mesa preparada para ellos,
que contiene un gran cuenco lleno de tallarines en el medio, pues, después de
estar años pensando, concluyeron que este es el único alimento que contribuye
a su fuerza mental.
Debido a su falta de habilidad manual, cada filosofo necesita de dos tenedores
para poder comer sus tallarines. La disposición de la mesa para los 5 filosofo
esta representada en la ilustración 13 (Stalling 2005).
Ingeniería de Sistemas Página 25
SISTEMAS OPERATIVOS
Ilustración 13: Disposición para los filósofos comensales.
Como podemos ver la disposición de la mesa es simple, una mesa redonda con
cinco platos, uno para cada filosofo y cinco tenedores. Para poder comer el
filosofo se debe sentar en el lugar de su plato y tomar los tenedores que se
encuentran a la izquierda y derecha de este.
El problema consiste en diseñar un algoritmo que permita a los filósofos comer
de manera correcta en la que para ninguno de los filosofo se presenten
problemas de interbloqueo o inanición. Para esto debe satisfacer la exclusión
mutua, es decir, que no puede haber dos filósofos que puedan hacer uso del
mismo tenedor al mismo tiempo.
El problema de los filosofo comensales en si no parece ser relevante en el
desarrollo de sistemas operativos. Sin embargo, representa uno de los
problemas clásicos de manejo de interbloqueos e inanición, problemas que son
la base de la programación concurrente además de uso de recursos
compartidos, que son comunes encontrar en sistemas que hacen uso de hilos
concurrentes.
7.1. Solución 1: Semáforos
La primera solución (Ilustración 14: Stallling 2005) representa el
procedimiento más común que se puede considerar para resolver el
problema, en el cual, cada filósofo toma primero el tenedor de la izquierda y
después el de la derecha. Una vez que el filósofo ha terminado de comer,
vuelve a colocar los dos tenedores en la mesa.
Por desgracia esta solución conduce irremediablemente al interbloqueo,
debido a que, si todos los filósofos están hambrientos al mismo tiempo, todos
ellos se sentarán cogerán el tenedor de la izquierda y tenderán la mano para
tomar el tenedor de su derecha, el cual no estará allí. Una vez producida esta
situación nos encontraremos en un caso de interbloqueo en el cual los
filósofos pasarán hambre.
Ingeniería de Sistemas Página 26
SISTEMAS OPERATIVOS
Ilustración 14: Solución 1 (Problema de los filósofos comensales)
7.2. Solución 2: Semáforos
Ahora tomando en cuenta la solución 1 podemos diseñar una nueva solución
utilizando semáforos, considerando ahora sí, la necesidad de evitar
situaciones de interbloqueos e inanición. Para esto necesitaremos hacer uso
de un segundo semáforo el cual tendrá la función de permitir el acceso al
comedor a tan solo 4 de los 5 filósofos. Asegurándonos de esta forma que
por lo menos uno de los filósofos que se sienten a comer podrá hacer uso de
ambos tenedores, y a partir de este punto podremos permitir que cada uno
de los filósofos se sienten a comer por turnos. Esta solución esta
representada en la ilustración 15 extraída del libro de Sistemas Operativos
de Stalling 2005.
Ilustración 15: Solución 2 (Problema de los filósofos comensales)
Ingeniería de Sistemas Página 27
SISTEMAS OPERATIVOS
7.3. Solución 3: Monitor
Para esta tercera solución haremos uso de un monitor, representada en la
Ilustración 16 extraída nuevamente del libro de Stalin 2005.
Se define un vector de cinco variables de condición, una variable de
condición por cada tenedor. Estas variables de condición se utilizan para
permitir que un filósofo espere hasta que esté disponible un tenedor.
Además, hay un vector de tipo booleano que registra la disponibilidad de
cada tenedor. El monitor consta de dos procedimientos. El procedimiento
obtiene_tenedores lo utiliza un filósofo para obtener sus tenedores, el
situado a su izquierda y a su derecha. Si ambos tenedores están disponibles.
el proceso que corresponde con el filósofo se encola en la variable de
condición correspondiente. Esto permite que otro proceso filósofo entre en el
monitor. Se utiliza el procedimiento libera_tenedores para hacer que
queden disponibles los dos tenedores. Nótese que la estructura de esta
solución es similar a la solución 2 con semáforos propuesta en la Ilustración
14. Ya que, en ambos casos, un filósofo toma primero el tenedor de la
izquierda y después el de la derecha. A diferencia de la solución del
semáforo. esta solución del monitor no sufre interbloqueos, porque sólo
puede haber un proceso en cada momento en el monitor.
De esta manera, nos podemos asegurar de que un primer filosofo pueda
obtener el tenedor de la izquierda y luego el de la derecha antes de que un
segundo filósofo pueda obtener el tenedor de su izquierda que tienen
comparten.
Ingeniería de Sistemas Página 28
SISTEMAS OPERATIVOS
Ilustración 16: Solución 3 (Problema de los filósofos comensales)
8. Mecanismos de concurrencia de UNIX
UNIX proporciona diversos mecanismos de comunicación y sincronización entre
procesos.
• Tuberías(pipes)
• Mensajes
• Memoria compartida
• Semáforos
• Señales
Las tuberías, los mensajes y la memoria compartida pueden utilizarse para
comunicar datos entre procesos, mientras que los semáforos y las señales se
utilizan para disparar acciones en otros procesos.
8.1. TUBERIAS
La tubería es una de las contribuciones significativas de UNIX en el desarrollo
de los sistemas operativos. Inspirado por el concepto de corrutina [RITC84], es
un buffer circular que permite que dos procesos se comuniquen siguiendo el
modelo productor-consumidor. Por tanto, se trata de una cola de tipo “el primero
en entrar es el primero en salir”, en la que escribe un proceso y lee otro.
Al crear una tubería, se le establece un tamaño fijo en bytes. Cuando un proceso
intenta escribir en la tubería, la petición de escritura se ejecuta inmediatamente
si hay suficiente espacio; en caso contrario, el proceso se bloquea. De manera
similar, un proceso que lee se bloquea si intenta leer más bytes de los que están
actualmente en la tubería; en caso contrario, la petición de lectura se ejecuta
inmediatamente. El sistema operativo asegura la exclusión mutua: es decir, en
cada momento solo puede acceder a una tubería un único proceso.
Hay dos tipos de tuberías: con nombre y sin nombre. Solo los procesos
Ingeniería de Sistemas Página 29
SISTEMAS OPERATIVOS
relacionados pueden compartir tuberías sin nombre, mientras que, los procesos
pueden compartir tuberías con nombre tanto si están relacionadas como si no.
8.2. MENSAJES
Un mensaje es un conjunto de bytes con un tipo asociado. UNIX proporciona las
llamadas al sistema msgsnd y msgrcv para que los procesos puedan realizar la
transferencia de mensajes. Asociada con cada proceso existe una cola de
mensajes, que funciona como un buzón.
El emisor especifica el tipo de mensaje en cada mensaje que envía, por lo que
puede utilizarse como un criterio de selección por el receptor. El receptor puede
recuperar los mensajes tanto en orden de llegada o por su tipo. Un proceso se
bloqueará cuando intente enviar un mensaje a una cola llena, también cuando
intente leer un mensaje de una cola vacía. Si un proceso intenta leer un mensaje
de un cierto tipo y este no existe, el proceso no se bloquea.
8.3. MEMORIA COMPARTIDA
La forma mas rápida de comunicación entre procesos proporcionada por UNIX
es la memoria compartida. Se trata de un bloque de memoria virtual compartido
por multiples procesos. Los procesos leen y escriben en la memoria compartida
utilizando las mismas instrucciones de maquina que se utilizan para leer y
escribir otras partes de su espacio de memoria virtual. El permiso para un
determinado proceso puede ser de solo lectura o de lectura y escritura,
estableciéndose de forma individual para cada proceso. Las restricciones de
exclusión mutua no son parte de este mecanismo de memoria compartida, sino
que las deben proporcionar los procesos que utilizan la memoria compartida.
8.4. SEMAFOROS
Las llamadas al sistema de semáforos de UNIX System V son una generalización
de las funciones semWait y semSignal; se pueden realizar varias operaciones
simultáneamente y las operaciones de incremento y decremento pueden
corresponder con valores mayores que 1. El núcleo realiza todas las operaciones
solicitadas atómicamente; ningún otro proceso puede acceder al semáforo hasta
que se hayan completado todas las operaciones.
Un semáforo consta de los siguientes elementos:
• El valor actual del semáforo.
Ingeniería de Sistemas Página 30
SISTEMAS OPERATIVOS
• El identificador del último proceso que opero con el semáforo.
• El número de procesos en espera de que el valor del semáforo sea mayor
que su valor actual.
• El número de procesos en espera de que el valor del semáforo sea cero.
• Asociado con el semáforo están las colas de los procesos bloqueados en
ese semáforo.
Los semáforos se crean como conjuntos, donde cada uno de ellos consta de uno
o más semáforos. Hay una llamada al sistema semct1 que permite que todos los
valores de los semáforos del conjunto se fijen al mismo tiempo, asi mismo
tenemos a semop que toma como argumento una lista de operaciones de
semáforo, cada una definida sobre uno de los semáforos de un conjunto. Cuando
se realiza la llamada, el núcleo lleva a cabo sucesivamente las operaciones
indicadas. Por cada operación, la función real se especifica mediante el valor
sem_op, existiendo las siguientes posibilidades:
• Si sem_op es positivo, el núcleo incrementa el valor del semáforo y
despierta a todos los procesos en espera de que el valor del semáforo se
incremente.
• Si sem_op es 0, el núcleo comprueba el valor del semáforo. Si el valor
del semáforo es igual a 0, el núcleo continúa con las otras operaciones
de la lista. En caso contrario, el núcleo incrementa el número de procesos
en espera de que ese semáforo tenga el valor 0 y suspende al proceso
para que espere por el evento de que el valor del semáforo se haga igual
a 0.
• Si sem_op es negativo y su valor absoluto es menor o igual al valor del
semáforo, el nucleo añade sem_op(un numero negativo) al valor del
semáforo. Si el resultado es 0, el nucleo despierta a todos los procesos
en espera de que el semáforo tome ese valor.
• Si sem_op es negativo y su valor absoluto es mayor que el valor del
semáforo, el nucleo suspende al proceso en espera del evento de que el
valor del semáforo se incremente.
Esta generalización de los semáforos proporciona una considerable flexibilidad
para realizar la sincronización y coordinación de procesos.
8.5. SEÑALES
Una señal es un mecanismo software que informa a un proceso de la existencia
de eventos asíncronos, es similar a las interrupciones hardware, pero no emplea
Ingeniería de Sistemas Página 31
SISTEMAS OPERATIVOS
prioridades. Es decir, todas las señales se tratan por igual; las señales que
ocurren al mismo tiempo se le presentan al proceso una detrás de otra, sin
ningún orden en particular.
Los procesos se pueden enviar señales entre sí, o puede ser el núcleo quien
envíe señales internamente. Para entregar una señal, se actualiza un campo en
la tabla de procesos correspondiente al proceso al que se le está enviando la
señal. Dado que por cada señal se mantiene un único bit, las señales de un
determinado tipo no pueden encolarse. Una señal solo se procesa después de
que un proceso se despierte para ejecutar o cuando el proceso está retornando
de una llamada al sistema. Un proceso puede responder a una señal realizando
alguna acción por defecto (por ejemplo, su terminación), ejecutando una función
de manejo de la señal o ignorando la señal.
Ilustración 17: Operaciones disponibles con señales
9. Mecanismos de concurrencia del núcleo de Linux
Como vimos en la sección anterior, existen diversos mecanismos de
concurrencia en general para los sistemas basados en UNIX, los cuales están
incluidos y son utilizados por SO’s tales como Solaris, Darwin, MacOS y Linux,
solo por mencionar algunos de los más importantes, y es a este último al cual le
vamos a dedicar un poco más de profundidad en esta sección.
Ingeniería de Sistemas Página 32
SISTEMAS OPERATIVOS
Puesto que Linux, además de incluir los mecanismos de concurrencia
clásicos de UNIX, como tuberías, mensajes, memoria compartida y señales;
incluye un conjunto de mecanismos de concurrencia específicos, para ser
usados cuando se ejecuta un hilo en modo núcleo. De esta manera, se definen
mecanismos especiales, que se utilizaran para proporcionar concurrencia en la
ejecución del código de núcleo.
A continuación, hablaremos más a detalle acerca de cada uno de ellos.
9.1. Operaciones Atómicas
Una operación atómica es aquella en la que un procesador puede
simultáneamente, leer una ubicación y escribirla en la misma operación
del bus. Linux cuenta con funciones que garantizan que las operaciones
sobre una variable en el núcleo sean atómicas, evitando así, condiciones
de carreras sencillas ya que se ejecuta sin interrupción o interferencia. Es
decir que, si un hilo empieza una operación atómica, no podrá ser
interrumpido hasta que finalice dicha operación, esto si el sistema es
uniprocesador; si, por el contrario, el sistema es multiprocesador, se
establecerá un cerrojo sobre la variable en la que se está operando, para
que de esta forma no se pueda dar acceso a otros hilos hasta después
de completada la operación.
Linux divide las operaciones atómicas en dos grupos, según los
tipos de variables que operan, operaciones con enteros y operaciones
con mapas de bits. Estas deben implementarse en cualquier arquitectura
sobre la cual se pretenda ejecutar Linux.
Las operaciones con enteros utilizan el tipo de datos especial
atomic_t, el cual solo puede ser usado en operaciones atómicas, usar
este tipo de variable trae beneficios como:
a. No se usan variables desprotegidas en condiciones de carrera.
b. Están protegidas de operaciones no atómicas.
c. El compilador no optimiza erróneamente el acceso al valor.
d. Estas variables esconden las diferencias de cada arquitectura en
implementación.
Las operaciones con mapas de bits operan sobre una secuencia
de bits almacenada en una posición de memoria la cual es definida por
Ingeniería de Sistemas Página 33
SISTEMAS OPERATIVOS
una variable puntero.
En la siguiente tabla se listan aquellas operaciones atómicas
definidas por Linux (Stalling 2005)
Ilustración 18: Operaciones atómicas en Linux
9.2. Cerrojos Cíclicos
Los cerrojos cíclicos o spinlocks son la manera más común de
proteger una sección crítica en Linux. Esos cerrojos funcionan
cerrándose después de haber sido adquiridos por un primer hilo, de esta
manera, si un segundo hilo intenta adquirir este mismo cerrojo seguirá
intentándolo (cíclicamente) hasta que el primer hilo lo abra nuevamente
y el segundo pueda adquirirlo.
Estos cerrojos se construyen usando una posición de memoria
que contiene un valor entero que indica si está abierto o cerrado; si un
hilo consulta el cerrojo y está en 0, le asigna el valor 1 y entra en su
sección crítica, si un hilo consulta el cerrojo y no es 0 seguirá
comprobando hasta que se vuelva 0. De esta forma un hilo que está a la
Ingeniería de Sistemas Página 34
SISTEMAS OPERATIVOS
espera de un cerrojo se quedará fuera de la sección crítica en modo de
espera activa. Por lo cual este tipo de mecanismo se recomienda para
procesos que se espera tengan un tiempo breve de espera.
9.2.1. Cerrojos cíclicos básicos
Presenta las siguientes 4 modalidades en su uso:
• Sencillo: Se usa si el código de la sección crítica no se ejecuta
desde manejadores de interrupciones o si las interrupciones están
inhabilitadas durante la ejecución de la sección critica.
• _irq: Se usa si las interrupciones están siempre inhabilitadas.
• _irqsave: Se usa si no se conoce si las interrupciones estarán
habilitadas o inhabilitadas en el momento de la ejecución. Al
adquirir el cerrojo se guarda el estado actual de las interrupciones
del procesador local y se recupera cuando se libera el cerrojo.
• _bh: Se usa para inhabilitar, y después habilitara ejecución de
rutinas bottom half para evitar conflictos con la sección crítica
protegida.
A continuación, se presentan las funciones para el uso de los cerrojos
cíclicos básicos (Stalling 2005).
Ilustración 19: Cerrojos cíclicos en Linux
Ingeniería de Sistemas Página 35
SISTEMAS OPERATIVOS
9.2.2. Cerrojos cíclicos de lectura-escritura
Permiten un mayor grado de concurrencia dentro del núcleo que
el cerrojo cíclico básico. Permite que múltiples hilos tengan acceso
simultaneo a la misma estructura de datos si solo pretenden un acceso
de lectura, pero da acceso exclusivo al cerrojo cíclico si un hilo desea
actualizar la estructura de datos. Cada uno de estos cerrojos consta de
un contador de lectores de 24 bits y un indicador de desbloqueo, que se
interpretan como la siguiente tabla extraída del libro de Stalling 2005.
Contador Indicador Interpretación
0 1 El cerrojo cíclico está disponible para su uso
El cerrojo cíclico se ha adquirido para la
0 0
escritura de 1 hilo
El cerrojo cíclico se ha adquirido para la
n (n>0) 0
escritura de n hilo
n (n>0) 1 Inválido
Al igual que el cerrojo básico, los cerrojos de lectura-escritura
tienen modalidades _irq e _irqsave.
Otra característica de los cerrojos cíclicos de lectura-escritura es
que da preferencia a los lectores sobre los escritores. Si existen lectores
manteniendo el cerrojo, un escritor no pobra adquirir el cerrojo y aún si
un escritor está esperando, se pueden incorporar nuevos lectores.
9.3. Semáforos
Como ya lo hemos mencionado, Linux incluye los mecanismos de
concurrencia comunes de UNIX, dentro de los cuales están los
semáforos, los cuales son usados únicamente en el nivel de usuario, esto
es debido a que para el propio uso del núcleo de Linux cuenta con la
implementación de semáforos exclusivos que no pueden accederse
directamente desde un programa de usuario mediante llamadas al
sistema, sino que son implementados como funciones dentro del núcleo
haciéndolos más eficientes que los semáforos visibles para el usuario.
9.3.1. Semáforos binarios y con contador
Los semáforos en Linux cuentan con la misma funcionalidad de
los semáforos comunes tanto de UNIX como los semáforos en general
Ingeniería de Sistemas Página 36
SISTEMAS OPERATIVOS
en sistemas operativos. Dentro de las pequeñas particularidades de los
semáforos de Linux, están las funciones “down” y “up”, las cuales
reemplazan a las funciones “semWait” y “semSignal” en los semáforos
comunes.
Los semáforos con contador se inician usando la función
“sem_init”, la cual da al semáforo un nombre y le asigna un valor inicial.
Mientras que los semáforos binarios, también llamados MUTEX en Linux,
se inician mediante la función “init_MUTEX” que inicia el semáforo con un
valor inicial 1 e “init_MUTEX_LOCKED” que inicia el semáforo con un
valor inicial de 0.
En Linux la función “down” cuenta con 3 variantes que tienen
resultados diferentes en el comportamiento del semáforo.
1. La función “down” funciona exactamente igual que la función
tradicional “semWait”. Es decir que el hilo comprueba el valor del
semáforo y se bloquea si no está disponible. Y se despertará
cuando ocurra la función “up” del semáforo.
2. La función “down_interruptible” permite que el hilo reciba y
responda a una señal del núcleo mientras está bloqueado en la
operación “down”. Si una señal despierta al hilo, la función
“down_interruptible” incrementa el valor del contador del semáforo
y devuelve un código de error conocido en Linux como “EINTR”.
Este valor le indica al hilo que la función del semáforo se ha
abortado. En efecto, el hilo se ha visto forzado a “abandonar” el
semáforo.
3. La función “down_trylock” permite intentar adquirir un semáforo sin
ser bloqueado. Si el semáforo está disponible se adquiere. En caso
contrario, esta función devuelve un valor distinto de cero sin
bloquear el hilo.
9.3.2. Semáforos de Lectura-Escritura
El semáforo de lectura-escritura clasifica a los usuarios en
lectores y escritores, permitiendo múltiples lectores concurrentes, pero en
caso de que se adquiera un escritor, solo se permite uno y no se permiten
lectores mientras este el escritor. Es decir, el semáforo de lectura-
escritura funcionaria como un semáforo contador para los lectores
Ingeniería de Sistemas Página 37
SISTEMAS OPERATIVOS
mientras que para los escritores funcionaria como un semáforo binario.
Stalling especifica las funciones con semáforos tradicionales y de lectura
escritura en la tabla a continuación.
Ilustración 20: Semáforos en Linux
9.4. Barreras
En algunas arquitecturas, los compiladores o el hardware del
procesador pueden cambiar el orden de los accesos a memoria del
código fuente para optimizar el rendimiento. Este cambio, en ciertas
circunstancias donde el orden de la lectura y asignación de las variables
no es importante, es saludable para el optimizar el uso de las tuberías de
instrucciones del procesador. Sin embargo, cuando el orden de estas si
es importante para la ejecución debido al uso que se hace de la
información desde otro hilo o desde un dispositivo de hardware.
Las barreras en Linux son una solución para evitar el intercambio
Ingeniería de Sistemas Página 38
SISTEMAS OPERATIVOS
erróneo del orden de los accesos a memoria. La operación “rmb” asegura
que no se produce ninguna lectura después de la barrera definida por el
lugar en el que se definió. De igual manera, la operación “wmb” asegura
que no se puede realizar ninguna escritura después del lugar en el que
se define. La operación “mb” funciona como una barrera de Lectura-
Escritura.
A continuación, se muestra una tabla con las operaciones de barrera más
comunes en Linux (Stalling 2005)
Ilustración 21: Barreras en Linux
10. Funciones de sincronización de Hilos de Solaris
Solaris proporciona cuatro funciones de sincronización de hilos:
• Cerrojos de exclusión mutua (mutex)
• Semáforos
• Cerrojos de múltiples
lectores y un único
escritor
(lectores/escritores)
• Variables de
condición
La ilustración 9
muestra las estructuras de
datos asociadas a estas
funciones. Las funciones de iniciación de estos mecanismos rellenan algunos de
los campos de datos. Una vez que se crea un objeto sincronización, sólo se
pueden realizar dos operaciones: entrar (adquirir un cerrojo) y liberar
(desbloquearlo). Si un hilo Ilustración 22: Estructura de Datos de Sincronización de Solaris
Ingeniería de Sistemas Página 39
SISTEMAS OPERATIVOS
intenta acceder a un fragmento de datos o código que debería estar protegido,
pero no utiliza la función de sincronización apropiada, a pesar de ello, ese acceso
se produce.
Si un hilo establece un cerrojo sobre un objeto y después no lo
desbloquea, el núcleo no toma ninguna acción correctiva. Todas las primitivas
de sincronización requieren la existencia de una instrucción hardware que
permita que un objeto sea consultado y modificado en una operación atómica.
10.1. Cerrojo de Exclusión Mutua
Un mutex se utiliza para asegurarse que sólo un hilo en cada
momento puede acceder al recurso protegido por el mutex. El hilo que
obtiene el mutex debe ser el mismo que lo libera. Un hilo intenta adquirir
un cerrojo mutex ejecutando la función mutex_enter. Si mutex_enter no
puede establecer el cerrojo, la acción bloqueante depende de la
información específica de tipo almacenada en el objeto mutex. La política
bloqueante por defecto es la de un cerrojo cíclico: un hilo bloqueado
comprueba el estado del cerrojo mientras ejecuta un bucle de espera
activa. Deforma opcional, hay un mecanismo de espera bloqueante
basado en interrupciones. En este último caso, el mutex incluye un
identificador de turnstile que identifica una cola de los hilos bloqueados
en este cerrojo.
Las operaciones en un cerrojo mutex son las siguientes:
• mutex_enter () Adquiere el cerrojo, bloqueando
potencialmente si ya lo posee otro
• hilomutex_exit () Libera el cerrojo, desbloqueando
potencialmente a un hilo en espera
• mutex_tryenter () Adquiere un cerrojo si no lo posee otro
hilo.
La primitiva mutex_tryenter () proporciona una manera no
bloqueante de realizar una función de exclusión mutua.
10.2. Semáforos
Solaris proporciona los clásicos semáforos con contador,
ofreciendo las siguientes funciones:
• sema_p () Decrementa el semáforo, bloqueando
potencialmente el hilo
• sema_v () Incrementa el semáforo, desbloqueando
potencialmente un hilo en espera
Ingeniería de Sistemas Página 40
SISTEMAS OPERATIVOS
• sema_tryp () Decrementa el semáforo si no se requiere
un bloqueo
Una vez más, la función sema_tryp () permite una espera activa.
10.3. Cerrojo de Lectura/Escritura
Permite que múltiples hilos tengan acceso simultáneo de lectura
a objetos protegidos por un cerrojo. También permite que en cada
momento un único hilo acceda al objeto para modificarlo mientras se
excluye el acceso de todos los lectores.
Cuando se adquiere el cerrojo para realizar una escritura, éste
toma el estado de cerrojo de escritura: todos los hilos que intentan
acceder para leer o escribir deben esperar. Si uno o más lectores han
adquirido el cerrojo, su estado es de cerrojo de lectura. Las funciones son
las siguientes:
• rw_enter () Intenta adquirir un cerrojo como lector o escritor
• rw_exit () Libera un cerrojo como lector o escritor
• rw_tryenter () Decrementa el semáforo si no se requiere un
bloqueo
• rw_downgrade () Un hilo que ha adquirido un cerrojo de escritura
lo convierte en uno de lectura.
• rw_tryupgrade () Intenta convertir un cerrojo de lectura en uno
de escritura
10.4. Variables de Condición
Se utiliza para esperar hasta que se cumpla una determinada
condición. Este mecanismo debe utilizarse en conjunción con un cerrojo
mutex. Las primitivas son las siguientes:
• cv_wait () Bloquea hasta que se activa la condición
• cv_signal () Despierta uno de los hilos bloqueados en cv_wait ()
• cv_broadcast () Despierta todos los hilos bloqueados en cv_wait
()
La función cv_wait () libera el mutex asociado antes de
bloquearse y lo vuelve a adquirir antes de retornar. El uso típico es el
siguiente:
Ingeniería de Sistemas Página 41
SISTEMAS OPERATIVOS
Ilustración 23:Uso de la función cv_wait()
11. Mecanismos de concurrencia Windows
Windows XP y 2003 proporcionan sincronización entre hilos como parte
de su arquitectura de objetos. Los dos métodos de sincronización más
importantes son los objetos de sincronización y los de sección crítica. Los
objetos de sincronización utilizan funciones de espera.
11.1. Funciones de Espera
Permiten que un hilo bloquee su propia ejecución. Las funciones
de espera no retornan hasta que se cumplen los criterios especificados.
Determina el conjunto de criterios utilizado. Cuando se llama a una
función de espera, ésta comprueba si se satisface el criterio de espera.
En caso negativo, el hilo que realizó la llamada transita al estado de
espera, no usando tiempo de procesador mientras no se cumplan los
criterios de la misma.
La función WaitForSingleObject requiere un manejador que
corresponda con un objeto de sincronización. La función retorna cuando
se produce las siguientes circunstancias:
• El objeto especificado está en el estado de señalado.
• Ha transcurrido el plazo máximo de espera.
11.2. Objetos de Sincronización
Mecanismo utilizado por el ejecutivo de Windows para
implementar las funciones de sincronización.
Ilustración 24: Objetos de sincronización en Windows
Los primeros cuatro tipos de objetos de la tabla están diseñados
específicamente para dar soporte a la sincronización. Los tipos de objetos
restantes tienen otros usos adicionales, pero también pueden utilizarse
para la sincronización.
Cada instancia de un objeto de sincronización puede estar en el
Ingeniería de Sistemas Página 42
SISTEMAS OPERATIVOS
estado de señalado o de no señalado. Un hilo se puede bloquear en un
objeto si está en el estado de no señalado, desbloqueándose cuando el
objeto transite al estado de señalado.
Un hilo realiza una petición de espera al ejecutivo de Windows,
utilizando el manejador del objeto de sincronización. Cuando el objeto
transita al estado de señalado, el ejecutivo de Windows desbloquea todos
los objetos de tipo hilo que están esperando en ese objeto de
sincronización.
El objeto evento es útil para enviar una señal a un hilo para
indicarle que ha ocurrido un determinado evento. El objeto mutex se usa
para garantizar el acceso mutuamente exclusivo a un recurso,
permitiendo que, en cada momento, sólo un hilo pueda conseguir el
acceso al mismo.
Este tipo de objeto funciona, por tanto, como un semáforo binario.
Cuando el objeto mutex pasa al estado de señalado, sólo se desbloquea
uno de los hilos que estaba esperando por el mutex. Los mutex se pueden
utilizar para sincronizar hilos que se ejecutan en procesos diferentes.
Como los mutex, los objetos semáforo pueden compartir los hilos
pertenecientes a distintos procesos. El semáforo de Windows es un
semáforo con contador. Básicamente, el objeto temporizador con espera
avisa cuando ha transcurrido un cierto tiempo o en intervalos regulares.
Ingeniería de Sistemas Página 43
SISTEMAS OPERATIVOS
11.3. Objetos de Sección Crítica
Proporcionan un mecanismo de sincronización similar al
proporcionado por los objetos mutex, excepto que los objetos de sección
crítica sólo los pueden utilizar hilos del mismo proceso. Los objetos
mutex, eventos y semáforos se pueden utilizar también en una aplicación
que tenga un único proceso, pero los objetos de sección crítica
proporcionan un mecanismo de sincronización para exclusión mutua
ligeramente más rápido y más eficiente.
El proceso es el responsable de asignar la memoria utilizada por
una sección crítica. Normalmente, esto se hace simplemente declarando
una variable de tipo CRITICAL_SECTION. Antes de que los hilos del
proceso puedan utilizarla, la sección crítica se inicia utilizando las
funciones Initialize-CriticalSection o
InitializeCriticalSectionAndSpinCount.
Un hilo usa las funciones EnterCriticalSection o
TryEnterCriticalSection para solicitar la posesión de una sección crítica,
utilizando la función LeaveCriticalSection para liberarla posesión de la
misma. Si el objeto de sección crítica lo posee actualmente otro hilo,
EnterCriticalSection espera indefinidamente hasta poder obtener su
posesión. En contraste, cuando se utiliza un objeto mutex para lograr
exclusión mutua, las funciones de espera aceptan que se especifique un
plazo de tiempo de espera máximo. La función TryEnterCriticalSection
intenta entrar en una sección crítica sin bloquear el hilo que realizó la
llamada.
Ingeniería de Sistemas Página 44
SISTEMAS OPERATIVOS
CONCLUSIONES
• Los interbloqueos son producidos por procesos que compiten por recursos,
estos recursos pueden afectar o no al cómputo.
• En la programación de procesos, el orden con la que se realicen estos, a la hora
de adquirir un recurso es determinante para determinar si se realiza un
interbloqueo.
• No siempre tratar los interbloqueos es la mejor opción puesto que estos se dan
con mucha frecuencia a comparación de errores del compilador y errores en el
sistema operativo.
• La detección y recuperación de interbloqueos proporcionan un mayor grado de
concurrencia potencial que la prevención o evitación de interbloqueos. Además,
la sobrecarga del tiempo de ejecución de detección de interbloqueo puede ser
un parámetro ajustable en el sistema. Una vez que se encuentra un punto muerto
y el proceso de reinicio o reversión desperdicia el uso de los recursos del
sistema, el precio que se paga es el recargo por recuperación. La recuperación
de interbloqueo puede resultar atractiva en sistemas con baja probabilidad de
interbloqueo. En un sistema de alta carga, es bien sabido que la concesión de
solicitudes de recursos sin restricción resultará en una inversión de recursos
excesiva, lo que resultará en frecuentes bloqueos. El impacto negativo del
interbloqueo aumenta a medida que aumenta la carga del sistema y la frecuencia
del interbloqueo, aumentando así el desaprovechamiento de los recursos del
sistema justo cuando son más necesarios.
• La prevención de interbloqueos es algo importante que podemos analizar,
sabemos que evitar los interbloqueos es algo imposible ya que se necesita
información de peticiones futuras, la cuales no se conocen, pero los sistemas
pueden tratar de evitarlos según las 4 condiciones de Coffman y colaboradores
las cuales son: exclusión mutua, contención y espera, no apropiativa y espera
circular.
• Los mecanismos de concurrencia de UNIX permiten la comunicación y
sincronización entre procesos en las que podemos encontrar a las tuberías, los
mensajes y la memoria compartida los cuales comunican datos entre procesos
y también tenemos a los semáforos y las señales las cuales disparan acciones
en otros procesos.
• Linux es un Sistema Operativo complejo, que requiere del uso correcto de
mecanismos de concurrencia para el óptimo desempeño en su ejecución. Para
lograr esto, cuenta con mecanismos que están a su disposición, por estar basado
Ingeniería de Sistemas Página 45
SISTEMAS OPERATIVOS
en UNIX, sin embargo, al tener procesos extras, necesita manejar la
concurrencia de forma más específica, es por eso que añade nuevos
mecanismos importantes para su ejecución, como barreras, operaciones
atómicas y cerrojos.
• La implementación de funciones para la sincronización de hilos en Solaris
permite que las funciones de iniciación de estos mecanismos rellenan algunos
de los campos de datos. Una vez que se crea un objeto sincronización, sólo se
pueden realizar dos operaciones: entrar y liberar.
Ingeniería de Sistemas Página 46
SISTEMAS OPERATIVOS
BIBLIOGRAFÍA
• STALLINGS, William (2005). Sinopsis de SISTEMAS OPERATIVOS:
ASPECTOS INTERNOS Y PRINCIPIOS DE DISEÑO. Editorial Pearson Prentice
Hall, 5ta. ed., España. 208p. ISBN: 9788420544625
• TANENBAUM, Andrew S. (2009). Sistemas operativos modernos. Editorial
PEARSON EDUCACIÓN., 3ra Ed., México., 1104p., ISBN: 978-607-442-046-3
• Tecnologico de pinotepa. (2021). Deteccion Y Recuperacion De Un Interbloqueo.
Retrieved January 8, 2021, from Slideshare.net website:
https://es.slideshare.net/basince/deteccion-y-recuperacion-de-un-interbloqueo
• 2.4.3.2 DETECCIÓN Y RECUPERACIÓN. - VeronicaRF_SO. (2021). 2.4.3.2
DETECCIÓN Y RECUPERACIÓN. - VeronicaRF_SO. Retrieved January 8,
2021, from Google.com website:
https://sites.google.com/site/veronicarfso/home/2-6-3-rr/2-6-2-sjf/2-6-tecnicas-
de-administracion-del-planificador/2-5-niveles-objetivos-y-criterios-de-
planificacion/2-4-3-2-deteccion-y-recuperacion
Ingeniería de Sistemas Página 47
También podría gustarte
- Microsoft Visual Basic .NET. Lenguaje y aplicaciones. 3ª Edición.: Diseño de juegos de PC/ordenadorDe EverandMicrosoft Visual Basic .NET. Lenguaje y aplicaciones. 3ª Edición.: Diseño de juegos de PC/ordenadorAún no hay calificaciones
- Microsoft C#. Lenguaje y Aplicaciones. 2ª Edición.De EverandMicrosoft C#. Lenguaje y Aplicaciones. 2ª Edición.Aún no hay calificaciones
- KNX. Domótica e Inmótica: Guía Práctica para el instaladorDe EverandKNX. Domótica e Inmótica: Guía Práctica para el instaladorCalificación: 5 de 5 estrellas5/5 (1)
- Fundamentos de Programación para VideojuegosDocumento23 páginasFundamentos de Programación para VideojuegosTIRZO ANTONIO MEDINA CARDENASAún no hay calificaciones
- 01MIARDocumento144 páginas01MIARSuarez RuízAún no hay calificaciones
- Grupo 58 - Sistemas Eléctricos de Potencia - TECSUP VirtualDocumento25 páginasGrupo 58 - Sistemas Eléctricos de Potencia - TECSUP VirtualPaul Portilla Achata0% (2)
- Proyecto de InvestigacionDocumento62 páginasProyecto de InvestigacionFernando AtalayaAún no hay calificaciones
- Audiologia PDFDocumento19 páginasAudiologia PDFXian-liAún no hay calificaciones
- Introducción A La ProgramaciónDocumento128 páginasIntroducción A La Programaciónpeter100% (1)
- EdSintesis PSP MuestraDocumento25 páginasEdSintesis PSP MuestramrnovoaAún no hay calificaciones
- 9788413571874Documento23 páginas9788413571874osman choque rojas0% (1)
- Diseño de Almacén para La Nueva Planta de Almacén de Jean para La Nueva Empresa Textil Del Perú SACDocumento165 páginasDiseño de Almacén para La Nueva Planta de Almacén de Jean para La Nueva Empresa Textil Del Perú SACIbet Maria Paucar DonayreAún no hay calificaciones
- Instrumentos ópticos y optométricos: Teoría y prácticasDe EverandInstrumentos ópticos y optométricos: Teoría y prácticasAún no hay calificaciones
- Modelado de Sistemas FisiologicosDocumento109 páginasModelado de Sistemas FisiologicosNancyJuárezAún no hay calificaciones
- Grupo6 - Informe Final - Machine LearningDocumento66 páginasGrupo6 - Informe Final - Machine Learninghector salinasAún no hay calificaciones
- Sistema Operativo MonopuestoDocumento22 páginasSistema Operativo MonopuestoSamuel Reyes PuertoAún no hay calificaciones
- Manual Tecnico DP-2065R PLUS MEMOSOFT V FinalDocumento45 páginasManual Tecnico DP-2065R PLUS MEMOSOFT V FinalCesar Daniel100% (5)
- El mecano macroeconómico: Problemas con ExcelDe EverandEl mecano macroeconómico: Problemas con ExcelAún no hay calificaciones
- 3 - Fase 2 - Trabajo ColaborativoDocumento48 páginas3 - Fase 2 - Trabajo ColaborativoEduardo SolorzanoAún no hay calificaciones
- Cisco IosDocumento51 páginasCisco IosFrancisco Andrés Parra CáceresAún no hay calificaciones
- PrimcipiosytecnicasDocumento130 páginasPrimcipiosytecnicasboscogilersAún no hay calificaciones
- Marco TeoricoDocumento81 páginasMarco TeoricoJorge PilcoAún no hay calificaciones
- 4 EntregaDocumento74 páginas4 EntregaLuis LuqueAún no hay calificaciones
- Tesis - Davinci Concurrente - v1.0Documento107 páginasTesis - Davinci Concurrente - v1.0Silvina ArriondoAún no hay calificaciones
- Control Industrial - RedDocumento102 páginasControl Industrial - Rednando maowAún no hay calificaciones
- Dokumen - Tips Electronica Digital PracticasDocumento119 páginasDokumen - Tips Electronica Digital PracticasDiego Trinidad TapiaAún no hay calificaciones
- PFC Ignacio Olivares deLasEras PDFDocumento185 páginasPFC Ignacio Olivares deLasEras PDFJulian AndresAún no hay calificaciones
- Desarrollo de Software RupDocumento91 páginasDesarrollo de Software RupItachiSempaiAún no hay calificaciones
- Grupo 8 TesisDocumento118 páginasGrupo 8 TesisMARI LUZ MAMANI MOLLEAPAZA100% (1)
- Análisis y Determinación de Requerimientos (V 3.0.0) PDFDocumento219 páginasAnálisis y Determinación de Requerimientos (V 3.0.0) PDFAgustin RomeroAún no hay calificaciones
- Tesis KEEODocumento126 páginasTesis KEEOPedrito OrangeAún no hay calificaciones
- Estadia FinalDocumento169 páginasEstadia FinalGissel FloresAún no hay calificaciones
- Proyecto mejora economías regionalesDocumento37 páginasProyecto mejora economías regionalesantonioAún no hay calificaciones
- PAREJA - Estudio para La Puesta en Marcha de Un Robot SCARA AdeptThree-XLDocumento62 páginasPAREJA - Estudio para La Puesta en Marcha de Un Robot SCARA AdeptThree-XLDomms DommsAún no hay calificaciones
- Informe Final GESDOC 2019Documento179 páginasInforme Final GESDOC 2019JuanCarlosAravenaAún no hay calificaciones
- Cristian Carranza Puerta Proyecto de TesisDocumento45 páginasCristian Carranza Puerta Proyecto de TesisCristian Bueno ChAún no hay calificaciones
- SI - Tecnologias de La Informacion - Modulo 5Documento62 páginasSI - Tecnologias de La Informacion - Modulo 5Alejandro PereyraAún no hay calificaciones
- Tesis PDFDocumento90 páginasTesis PDFMilthon Ttito CusiAún no hay calificaciones
- Proyecto TDS 2022Documento25 páginasProyecto TDS 2022Villanueva Lino DominguezAún no hay calificaciones
- MANUAL Cell - DesbloqueadoDocumento79 páginasMANUAL Cell - Desbloqueadoprofesor.antonioamAún no hay calificaciones
- CopifinisloDocumentación Sindicato WebDocumento115 páginasCopifinisloDocumentación Sindicato WebAyelen Estevez SegoviaAún no hay calificaciones
- Romero Ochoa Daniel Fernando 2017Documento68 páginasRomero Ochoa Daniel Fernando 2017Auteco LogisticaAún no hay calificaciones
- Plan de Emergencias Mercaneiva IpsDocumento62 páginasPlan de Emergencias Mercaneiva IpsCRC MERCANEIVA IpsAún no hay calificaciones
- Ene P1 A 7Documento129 páginasEne P1 A 7Charly MaciasAún no hay calificaciones
- P.d.g-Adilson Proyecto de Grado Final UpeaDocumento147 páginasP.d.g-Adilson Proyecto de Grado Final UpeaᏞιмʙᴇʀ MᴀмᴀɴιAún no hay calificaciones
- Proyecto III Final (Sistema de Alarma Via GSM)Documento33 páginasProyecto III Final (Sistema de Alarma Via GSM)Luis Carlos PalomequeAún no hay calificaciones
- 71 0530 IsDocumento216 páginas71 0530 IsRogelio Cueto CubillasAún no hay calificaciones
- Erlang IDocumento189 páginasErlang IKarelBRG100% (1)
- UNADDocumento136 páginasUNADyarid rodriguezAún no hay calificaciones
- 4ESO TEMA3 Sistemas OperativosDocumento28 páginas4ESO TEMA3 Sistemas Operativospablo girona perezAún no hay calificaciones
- TEG Javier Chirinos 4.0Documento80 páginasTEG Javier Chirinos 4.0Fernando PeñaAún no hay calificaciones
- 4SC Grupo 3Documento81 páginas4SC Grupo 3Johnn JimenezAún no hay calificaciones
- Perspectivas de la teoría de sistemas en la ingeniería industrialDocumento57 páginasPerspectivas de la teoría de sistemas en la ingeniería industrialDiana ValdiviaAún no hay calificaciones
- SCADA para planta envasado líquidosDocumento117 páginasSCADA para planta envasado líquidosjhl1981Aún no hay calificaciones
- Antologia Simulación SistemaDocumento165 páginasAntologia Simulación SistemaJayder Antonio Gomez Moha100% (1)
- Solar Centauro 50 Mexixo 5 Presidentes PDFDocumento89 páginasSolar Centauro 50 Mexixo 5 Presidentes PDFraulAún no hay calificaciones
- 2019 Alejos PalaciosDocumento60 páginas2019 Alejos PalaciosCristian Proyecting PeruAún no hay calificaciones
- Filtracion y UltrafiltracionDocumento170 páginasFiltracion y UltrafiltracionRuben Angel Ponte HuayllaAún no hay calificaciones
- Te We 007466 Man Usu 002Documento94 páginasTe We 007466 Man Usu 002Daniel De AvilaAún no hay calificaciones
- EquiposDocumento87 páginasEquiposA1fr3d1t0Aún no hay calificaciones
- Tema 12 - InformeDocumento24 páginasTema 12 - InformeLuis villanuevaAún no hay calificaciones
- Informe Examen PrácticoDocumento36 páginasInforme Examen PrácticoLuis villanuevaAún no hay calificaciones
- Examen FinanzasDocumento4 páginasExamen FinanzasLuis villanuevaAún no hay calificaciones
- DiapoSitivas - Capital de Trabajo - Van - TirDocumento32 páginasDiapoSitivas - Capital de Trabajo - Van - TirLuis villanuevaAún no hay calificaciones
- DIAPOSITIVASDocumento52 páginasDIAPOSITIVASLuis villanuevaAún no hay calificaciones
- Viabilidad EconomicaDocumento35 páginasViabilidad EconomicaLuis villanuevaAún no hay calificaciones
- Ex Amen Junio 2004Documento6 páginasEx Amen Junio 2004otaku quloAún no hay calificaciones
- ADMINDocumento1 páginaADMINLuis villanuevaAún no hay calificaciones
- Fisica Electronica Semana IDocumento33 páginasFisica Electronica Semana IArturo PaulinoAún no hay calificaciones
- TablasDocumento1 páginaTablasLuis villanuevaAún no hay calificaciones
- Sesion 02 - ADMINISTRACIONDocumento8 páginasSesion 02 - ADMINISTRACIONLuis villanuevaAún no hay calificaciones
- Fisica Electronica Semana IiDocumento36 páginasFisica Electronica Semana IiRosa Emily Rodríguez HuamánAún no hay calificaciones
- Examen grupal de unidad 2 de Ingeniería de Datos IIDocumento5 páginasExamen grupal de unidad 2 de Ingeniería de Datos IILuis villanuevaAún no hay calificaciones
- Estruct BoyDocumento6 páginasEstruct BoyLuis villanuevaAún no hay calificaciones
- Estructura ProyectoDocumento5 páginasEstructura ProyectoLuis villanuevaAún no hay calificaciones
- 3Documento2 páginas3Luis villanuevaAún no hay calificaciones
- CodigoDocumento1 páginaCodigoLuis villanuevaAún no hay calificaciones
- Estruct BoyDocumento6 páginasEstruct BoyLuis villanuevaAún no hay calificaciones
- EXPOSICIÓNDocumento18 páginasEXPOSICIÓNLuis villanuevaAún no hay calificaciones
- Caso Clínico #1 FarmacoDocumento6 páginasCaso Clínico #1 FarmacoLuis villanuevaAún no hay calificaciones
- Relacion Entre Cultura y ÉticaDocumento13 páginasRelacion Entre Cultura y ÉticaLuis villanuevaAún no hay calificaciones
- Ejercicio 7Documento1 páginaEjercicio 7Luis villanuevaAún no hay calificaciones
- Sesion02 - Poo2Documento7 páginasSesion02 - Poo2Luis villanuevaAún no hay calificaciones
- SdgfagfDocumento1 páginaSdgfagfLuis villanuevaAún no hay calificaciones
- 05 ExcepcionesDocumento8 páginas05 ExcepcionesHans Cubeños MontoyaAún no hay calificaciones
- SdgfagfDocumento1 páginaSdgfagfLuis villanuevaAún no hay calificaciones
- SasaDocumento1 páginaSasaLuis villanuevaAún no hay calificaciones
- POO Excepciones JavaDocumento15 páginasPOO Excepciones JavaLuis villanuevaAún no hay calificaciones
- Sesion 05 - Archivos de TextoDocumento5 páginasSesion 05 - Archivos de TextoLuis villanuevaAún no hay calificaciones
- Linea de Conduccion, Linea de AduccionDocumento17 páginasLinea de Conduccion, Linea de AduccionHeidyAún no hay calificaciones
- Presiones atmosférica, absoluta y manométricaDocumento3 páginasPresiones atmosférica, absoluta y manométricaJoel UrrutiaAún no hay calificaciones
- Osi Experiencia Senior Ejercicios y Actividades Practicas PDFDocumento67 páginasOsi Experiencia Senior Ejercicios y Actividades Practicas PDFNoelnamreg100% (1)
- Novedades Wordpress 6.1 - Artículo KinstaDocumento41 páginasNovedades Wordpress 6.1 - Artículo KinstaJesúsAún no hay calificaciones
- Proceso de Compras INMARK SAC IIDocumento9 páginasProceso de Compras INMARK SAC IIAdolfo Jesus Ilizarbe SerranoAún no hay calificaciones
- Cuestionario de Historia de La IngenieriaDocumento6 páginasCuestionario de Historia de La Ingenieriayeisson cortesAún no hay calificaciones
- Radiaciones ionizantes y no ionizantesDocumento10 páginasRadiaciones ionizantes y no ionizantesHospitalizacion PediatricaAún no hay calificaciones
- Guía rápida del analizador de hemocultivos BD Bactec FXDocumento6 páginasGuía rápida del analizador de hemocultivos BD Bactec FXpepito523Aún no hay calificaciones
- Ficha Tecnica S17 1 BOCKDocumento1 páginaFicha Tecnica S17 1 BOCKDiureyAún no hay calificaciones
- Cuestionario de Capacidad de RespuestaDocumento1 páginaCuestionario de Capacidad de RespuestaEric GalindoAún no hay calificaciones
- Anexo Volumenes de ObraDocumento34 páginasAnexo Volumenes de ObraMonica IdrovoAún no hay calificaciones
- Análisis y Evaluación Del Plan Maestro de La Ciudad de Hong Kong, China (Presentación)Documento42 páginasAnálisis y Evaluación Del Plan Maestro de La Ciudad de Hong Kong, China (Presentación)David MantillaAún no hay calificaciones
- Microsoft Excel y Google SheetsDocumento2 páginasMicrosoft Excel y Google SheetsJhonatan Fernandez BuriticaAún no hay calificaciones
- Entregable 2. Ensayo ArgumentativoDocumento6 páginasEntregable 2. Ensayo ArgumentativoEdwin H.CruzAún no hay calificaciones
- 15-Diseno de Circuitos SecuencialesDocumento50 páginas15-Diseno de Circuitos SecuencialesBrent DonedAún no hay calificaciones
- Capitulo 7Documento8 páginasCapitulo 7efrain GonzalezAún no hay calificaciones
- Estructura de TesisDocumento3 páginasEstructura de TesisBrayan Max ZuñigaAún no hay calificaciones
- Ensayo Las Tic en Escuelas RuralesDocumento4 páginasEnsayo Las Tic en Escuelas RuralesYERIS ALEXANDRA HENAO RODRIGUEZAún no hay calificaciones
- UNIDAD 1 A 9Documento108 páginasUNIDAD 1 A 9Servando Rueda VargasAún no hay calificaciones
- Ejercicio de Sistema Operativo de Disco.Documento4 páginasEjercicio de Sistema Operativo de Disco.Leticia OlmedaAún no hay calificaciones
- Conceptos de Obra y Partidas de ObrasDocumento4 páginasConceptos de Obra y Partidas de ObrasRay LeonAún no hay calificaciones
- Informe de Obra y Plan de TrabajoDocumento10 páginasInforme de Obra y Plan de TrabajoFelipeQuinteroAún no hay calificaciones
- Cotizacion KañarisDocumento5 páginasCotizacion Kañarisjose elmer bances santamariaAún no hay calificaciones
- DosatronD25RE5 - SpanishDocumento1 páginaDosatronD25RE5 - SpanishJulio DoriaAún no hay calificaciones
- Recomendaciones para Un Adecuado Uso Del Mail en Una EmpresaDocumento3 páginasRecomendaciones para Un Adecuado Uso Del Mail en Una EmpresaMaria ChromechekAún no hay calificaciones
- Axor ApexDocumento23 páginasAxor ApexDavid OlayaAún no hay calificaciones
- Regresion Lineal Con Series de Tiempo.Documento6 páginasRegresion Lineal Con Series de Tiempo.Ximena IbarraAún no hay calificaciones
- 3 - Diseño de BadenDocumento8 páginas3 - Diseño de BadenVictor Carrasco AvilesAún no hay calificaciones