También podría gustarte
- Marketing Digital. Posicionamiento SEO, SEM y Redes SocialesDe EverandMarketing Digital. Posicionamiento SEO, SEM y Redes SocialesCalificación: 4 de 5 estrellas4/5 (2)
- (MEGA-REPELIS!) Barbie (2023) PELÍCULA Completa en Español Cuevana Gratis Latino Y CastellanoDocumento5 páginas(MEGA-REPELIS!) Barbie (2023) PELÍCULA Completa en Español Cuevana Gratis Latino Y CastellanoJOSE LOPEZAún no hay calificaciones
- Manual Seo: Para un posicionamiento web en Google más eficazDe EverandManual Seo: Para un posicionamiento web en Google más eficazCalificación: 4.5 de 5 estrellas4.5/5 (2)
- Algoritmos de BusquedaDocumento10 páginasAlgoritmos de BusquedaSkate RealAún no hay calificaciones
- Tipos de Motores de BusquedaDocumento3 páginasTipos de Motores de BusquedaDavid Lichi LizanoAún no hay calificaciones
- Qué Es Un Motor de BúsquedaDocumento9 páginasQué Es Un Motor de BúsquedaMagdoni GomezAún no hay calificaciones
- Cuestionario Herramientas de BúsquedaDocumento7 páginasCuestionario Herramientas de BúsquedaHarry MurdocAún no hay calificaciones
- El Marketing en BuscadoresDocumento13 páginasEl Marketing en BuscadoresSolmayra CárdenasAún no hay calificaciones
- Motores de Busqueda - H - DDocumento16 páginasMotores de Busqueda - H - DYmce CEAún no hay calificaciones
- Cuadro Resumen Sobre Los Motores de Busqueda y Las Paginas WebDocumento7 páginasCuadro Resumen Sobre Los Motores de Busqueda y Las Paginas WebCURAGUIREAún no hay calificaciones
- Buscadores JerárquicosDocumento4 páginasBuscadores JerárquicosFerney HernándezAún no hay calificaciones
- Tecnicas Avanzadas de SEODocumento24 páginasTecnicas Avanzadas de SEOFrancisco100% (1)
- NAVEGADORES Ancho de Banda BuscadoresDocumento43 páginasNAVEGADORES Ancho de Banda Buscadoresnestorcamilo111Aún no hay calificaciones
- Motores de Búsquesda1Documento16 páginasMotores de Búsquesda1Cinthya BenitezAún no hay calificaciones
- Seminario InfotecnologiaDocumento10 páginasSeminario InfotecnologiaGretik Marin GonzalezAún no hay calificaciones
- Qué Es Un Buscador de Internet y para Qué SirveDocumento2 páginasQué Es Un Buscador de Internet y para Qué Sirvevfreddyantonio50% (4)
- IndexaciónDocumento5 páginasIndexaciónIsantonio JuárezAún no hay calificaciones
- Buscadores JOOMLADocumento9 páginasBuscadores JOOMLAEsperanza Soto MendietaAún no hay calificaciones
- Buscadores GeneralesDocumento5 páginasBuscadores GeneralesDorily Neftaly Rodriguez VenturaAún no hay calificaciones
- Motor de BúsquedaDocumento4 páginasMotor de BúsquedaPablo ArevaloAún no hay calificaciones
- Motores de BúsquedaDocumento11 páginasMotores de BúsquedaFernada Muñoz 23Aún no hay calificaciones
- Marketing Digital 8 - SEO y PPCDocumento34 páginasMarketing Digital 8 - SEO y PPCedownsAún no hay calificaciones
- Motores de BúsquedaDocumento9 páginasMotores de BúsquedaPaola SuarezAún no hay calificaciones
- Unidad N°2 Navegadores Busqueda y Validacion de La InformacionDocumento13 páginasUnidad N°2 Navegadores Busqueda y Validacion de La InformacionSilvia ÁvilaAún no hay calificaciones
- Clasificación de Los BuscadoresDocumento4 páginasClasificación de Los BuscadoresROSY HERNANDESAún no hay calificaciones
- Clase Nº8 - InformáticaDocumento5 páginasClase Nº8 - InformáticaAgustina Ponce AbaúnzaAún no hay calificaciones
- 7 Qué Es Un BuscadorDocumento3 páginas7 Qué Es Un BuscadorDiana Aguilar Padilla100% (1)
- Manual Completo Posicionamiento BuscadoresDocumento39 páginasManual Completo Posicionamiento BuscadoresGonzaloZentnerAún no hay calificaciones
- Exposicion de BuscadoresDocumento32 páginasExposicion de BuscadoresLuchito RochaAún no hay calificaciones
- 1 Modulo - Introducción A SEODocumento16 páginas1 Modulo - Introducción A SEOmiryperaltaAún no hay calificaciones
- Glosario SEO-2-9CDocumento8 páginasGlosario SEO-2-9Calexbs11Aún no hay calificaciones
- Los Administradores de Páginas Web y Proveedores de Contenido Comenzaron A Optimizar Sitios Web en Los Motores de Búsqueda A Mediados de La Década de 1990Documento3 páginasLos Administradores de Páginas Web y Proveedores de Contenido Comenzaron A Optimizar Sitios Web en Los Motores de Búsqueda A Mediados de La Década de 1990Edelson Chavez TorresAún no hay calificaciones
- Buscadores GeneralesDocumento4 páginasBuscadores GeneralesFran Mart67% (3)
- Actividad 3.3Documento11 páginasActividad 3.3utp0152168Aún no hay calificaciones
- Veamos Cuales Son Los Tipos de Buscadores Que Existen en Internet y Sus Principales CaracterísticasDocumento4 páginasVeamos Cuales Son Los Tipos de Buscadores Que Existen en Internet y Sus Principales CaracterísticasAndrea Katherin GarciaAún no hay calificaciones
- Actividad Seo Parte IDocumento13 páginasActividad Seo Parte ISamuelAún no hay calificaciones
- Motores de Búsqueda y TiposDocumento16 páginasMotores de Búsqueda y TiposANGEL ERNESTO OROZCO RODRIGUEZAún no hay calificaciones
- Buscadores Jerarquicos y HuesosDocumento7 páginasBuscadores Jerarquicos y HuesosVictor HernandezAún no hay calificaciones
- Tics Unidad 3Documento48 páginasTics Unidad 3CRISTINA DANIELA RODRIGUEZ RAMOSAún no hay calificaciones
- Motor de Búsqueda - Wikipedia, La Enciclopedia LibreDocumento4 páginasMotor de Búsqueda - Wikipedia, La Enciclopedia LibrepedroAún no hay calificaciones
- Practica 22 de Marzo 7°Documento10 páginasPractica 22 de Marzo 7°Marlon RiveraAún no hay calificaciones
- Definición de BuscadorDocumento3 páginasDefinición de BuscadorANDRES FELIPE CRISTANCHO OLAYAAún no hay calificaciones
- Motores de BusquedaDocumento4 páginasMotores de BusquedahfertisseraAún no hay calificaciones
- Buscadores y MetabuscadoresDocumento9 páginasBuscadores y MetabuscadoresArturo CarcamoAún no hay calificaciones
- Motores de BusquedaDocumento9 páginasMotores de BusquedaCristian Campos 5100% (1)
- Descubre Qué Son Los Motores de Búsqueda, Qué Tipos Existen y para Qué Sirve Cada Uno de EllosDocumento5 páginasDescubre Qué Son Los Motores de Búsqueda, Qué Tipos Existen y para Qué Sirve Cada Uno de EllosMarlon SolanoAún no hay calificaciones
- Apuntes Diseño MultimediaDocumento22 páginasApuntes Diseño MultimediaRubén ChamorroAún no hay calificaciones
- Estructura de Un Motor de BúsquedaDocumento3 páginasEstructura de Un Motor de BúsquedaLeonardo BetancourtAún no hay calificaciones
- 5.fundamentos de Marketing DigitalDocumento12 páginas5.fundamentos de Marketing DigitalLuis Diego Solis EsquivelAún no hay calificaciones
- Motores de BusquedaDocumento8 páginasMotores de BusquedaKathya Natalya Muñoz PanameñoAún no hay calificaciones
- Glosario Marketing DigitalDocumento9 páginasGlosario Marketing DigitalGlorexy MacharekgiAún no hay calificaciones
- Clase 4 - Texto - HipertextoDocumento16 páginasClase 4 - Texto - Hipertextofacundo martin chavezAún no hay calificaciones
- Llllllmultimedia2 0Documento12 páginasLlllllmultimedia2 0jimenezisidoro42Aún no hay calificaciones
- Tema 6 Habilidades DijitalesDocumento24 páginasTema 6 Habilidades Dijitalesjovany111005Aún no hay calificaciones
- 2020-21 Tema 3 Recuperación en InternetDocumento14 páginas2020-21 Tema 3 Recuperación en InternetmdngAún no hay calificaciones
- TEMA 2 Comercio ElectrónicoDocumento2 páginasTEMA 2 Comercio Electrónicoruiz adrianaAún no hay calificaciones
- Motores de BusquedaDocumento8 páginasMotores de BusquedaKarla Duke 12Aún no hay calificaciones
- MK1 - 03 BuscadoresDocumento92 páginasMK1 - 03 Buscadorescuchy0904Aún no hay calificaciones
- Meta BuscadorDocumento3 páginasMeta BuscadorAndres RodriguezAún no hay calificaciones
- La Ética GerencialDocumento12 páginasLa Ética GerencialYurubis AlvaradoAún no hay calificaciones
- Gerencial Excepcional DubricDocumento12 páginasGerencial Excepcional DubricYurubis AlvaradoAún no hay calificaciones
- Resumen Ejecutivo de Lo Esencial de DruckerDocumento4 páginasResumen Ejecutivo de Lo Esencial de DruckerYurubis AlvaradoAún no hay calificaciones
- Pensamiento Gerencial Eduardo AzuajeDocumento1 páginaPensamiento Gerencial Eduardo AzuajeYurubis AlvaradoAún no hay calificaciones
- Brasil SlavikDocumento9 páginasBrasil SlavikyolandaAún no hay calificaciones
- Secuencias Didácticas ISRDocumento23 páginasSecuencias Didácticas ISRNidia Rosario Montoya AriasAún no hay calificaciones
- Bolívar (Serie de Televisión)Documento6 páginasBolívar (Serie de Televisión)Ente CognitaeAún no hay calificaciones
- Preparar Combustible Glow Zj0tiDocumento6 páginasPreparar Combustible Glow Zj0tiRoberto LopezAún no hay calificaciones
- Seleccion y Reclutamiento de PersonalDocumento6 páginasSeleccion y Reclutamiento de Personalmaria zanchesAún no hay calificaciones
- Instalar JDK y Eclipse en Windows para Programar en JavaDocumento33 páginasInstalar JDK y Eclipse en Windows para Programar en JavaMarcelo GustavoAún no hay calificaciones
- Ceramicos, Vidrios y VitroceramicosDocumento17 páginasCeramicos, Vidrios y VitroceramicosangelAún no hay calificaciones
- Ie0425 ProgramaDocumento5 páginasIe0425 Programabyson2200Aún no hay calificaciones
- CapecoDocumento8 páginasCapecoJoe AvilezAún no hay calificaciones
- Que Son Los Virus InformaticosDocumento5 páginasQue Son Los Virus InformaticosCarlos Enrique ChilelAún no hay calificaciones
- Cartas 9Documento5 páginasCartas 9alejandro PolinesioAún no hay calificaciones
- Manual Es400Documento218 páginasManual Es400Jose Moctezuma IglesiasAún no hay calificaciones
- Guia de Aprendizaje Word Unidad 2Documento5 páginasGuia de Aprendizaje Word Unidad 2Harlem Ibarguen MosqueraAún no hay calificaciones
- 1 WiresharkDocumento6 páginas1 WiresharkUriel TijerinoAún no hay calificaciones
- MQR ManualDocumento195 páginasMQR ManualCelina JimaAún no hay calificaciones
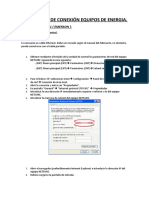
- Guia Rapida de Conexión Equipos de EnergiaDocumento34 páginasGuia Rapida de Conexión Equipos de EnergiaAlex VakulenkoAún no hay calificaciones
- Trabajo de Linux (Kazam)Documento6 páginasTrabajo de Linux (Kazam)Kevis Gomez MedezAún no hay calificaciones
- Capítulo 8 Dispositivos MóvilesDocumento33 páginasCapítulo 8 Dispositivos MóvilesGladys Medina100% (1)
- FaraonaDocumento2 páginasFaraonaNicolás Ugalde0% (1)
- Actuación. Concepto de Janet MurrayDocumento16 páginasActuación. Concepto de Janet MurrayNohemi LugoAún no hay calificaciones
- Señalizacion Telefónica 7Documento10 páginasSeñalizacion Telefónica 7Oscar PortilloAún no hay calificaciones
- Anexo 2 Mesas Temáticas y Coordinadores XVI Encuentro IberoamericanoDocumento18 páginasAnexo 2 Mesas Temáticas y Coordinadores XVI Encuentro IberoamericanoDiego A. Bernal B.Aún no hay calificaciones
- Macro en Excel PesosMNDocumento106 páginasMacro en Excel PesosMNJesus Velazquez Arias100% (1)
- Primeros Pasos en El Aula Virtual 3.0 PDFDocumento14 páginasPrimeros Pasos en El Aula Virtual 3.0 PDFSanyana Pamela Morales BorjaAún no hay calificaciones
- ARP EA-2018-2 Parcial 20181026Documento2 páginasARP EA-2018-2 Parcial 20181026Luis Fernando Ayasta PortocarreroAún no hay calificaciones
- Delitos y Ataques InformáticosDocumento3 páginasDelitos y Ataques InformáticosleovyAún no hay calificaciones
- Proyecto Educativo Redes Sociales 2018Documento30 páginasProyecto Educativo Redes Sociales 2018Jorge Molina100% (1)
- Manual para Modo Punto de Acceso Airos UbiquitilDocumento15 páginasManual para Modo Punto de Acceso Airos Ubiquitiltavo36Aún no hay calificaciones
- Diseño para Implementar Un Sistema de Video Vigilancia CCTVDocumento76 páginasDiseño para Implementar Un Sistema de Video Vigilancia CCTVJosé Luis Mancha100% (1)