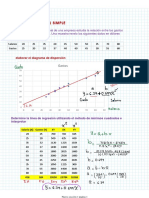
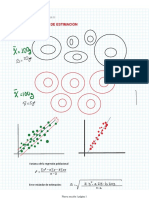
También podría gustarte
- Clase 13-02-2021Documento8 páginasClase 13-02-2021JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Clase 12-05-2022Documento5 páginasClase 12-05-2022Oscar Yana MartinezAún no hay calificaciones
- Producto Académico N°3 - ESTADÍSTICA APLICADADocumento10 páginasProducto Académico N°3 - ESTADÍSTICA APLICADAAPRUEBA18100% (7)
- Guía Evaluada Estadistica.Documento12 páginasGuía Evaluada Estadistica.Marcell Araya CastilloAún no hay calificaciones
- Parcial - FinalDocumento11 páginasParcial - FinalMapu SalazarAún no hay calificaciones
- Actividad 1 Analisis de DatosDocumento9 páginasActividad 1 Analisis de DatosErick Alvarado TenorioAún no hay calificaciones
- Mest2 U2 Ea DVCDocumento6 páginasMest2 U2 Ea DVCDaniel VillalobosAún no hay calificaciones
- Actividad No.7 Relaciones Entre Parejas de DatosDocumento17 páginasActividad No.7 Relaciones Entre Parejas de DatosROSA CADENAAún no hay calificaciones
- Actividad 4.2Documento2 páginasActividad 4.2Miguel Angel Armenta TaylorAún no hay calificaciones
- Actividad de Aprendizaje 1 Taller 1Documento11 páginasActividad de Aprendizaje 1 Taller 1Ange PatoAún no hay calificaciones
- Ejercicios Clase 6 de AbrilDocumento12 páginasEjercicios Clase 6 de AbrilKimberly Dayana AGUDELO RODRIGUEZAún no hay calificaciones
- PROB REG VARIOS CorregidosDocumento7 páginasPROB REG VARIOS CorregidosGabriel Rafael Cova ValeraAún no hay calificaciones
- Maf U1 Ea FRPVDocumento3 páginasMaf U1 Ea FRPVpukitokhun23Aún no hay calificaciones
- Grupo 7 EstadisticaDocumento6 páginasGrupo 7 EstadisticaADHELY JHOANA ANDRADE CONDORAún no hay calificaciones
- Trabajo de Investigacion Matematica (Costo de Producción)Documento13 páginasTrabajo de Investigacion Matematica (Costo de Producción)Rivelinho chavez juncoAún no hay calificaciones
- Producto Académico 3 2022 - 20Documento3 páginasProducto Académico 3 2022 - 20Raul Pascual Huisa MinayaAún no hay calificaciones
- Metodo de MontecarloDocumento18 páginasMetodo de MontecarloDJxDEXTER100% (1)
- A#1 Analisis de DatosDocumento9 páginasA#1 Analisis de DatosKatia CarreónAún no hay calificaciones
- Ejercicios de Ingresoso Costos y BeneficiosDocumento5 páginasEjercicios de Ingresoso Costos y BeneficiosSolanch alcarraz zavalaAún no hay calificaciones
- Actividad StarbucksDocumento3 páginasActividad StarbucksSergio Rodrigo Casasola SantanaAún no hay calificaciones
- Fatima Melissa Garfias Jimenez - 736375 - 0Documento5 páginasFatima Melissa Garfias Jimenez - 736375 - 0Fatima GarfiasAún no hay calificaciones
- Im2 Final Condori Catacora JhonatanDocumento7 páginasIm2 Final Condori Catacora JhonatanJhonatan CatacoraAún no hay calificaciones
- Producto Académico 3 2022 - 20Documento3 páginasProducto Académico 3 2022 - 20venta examenesAún no hay calificaciones
- Producto Académico 3 2022 GRUPO ADocumento9 páginasProducto Académico 3 2022 GRUPO AFREDDY EDUARDO CARRION SANCHEZAún no hay calificaciones
- Cálculo de Punto de Equilibrio-GRUPO 4Documento4 páginasCálculo de Punto de Equilibrio-GRUPO 4Nicole TesenAún no hay calificaciones
- Ku Noh Saul Enrique 4I2 ESTADISTICA 2Documento29 páginasKu Noh Saul Enrique 4I2 ESTADISTICA 2Saul KuAún no hay calificaciones
- Tema2 InfDocumento12 páginasTema2 InfjosepeAún no hay calificaciones
- Actividad de Aprendizaje 1 Taller 1Documento12 páginasActividad de Aprendizaje 1 Taller 1Ange PatoAún no hay calificaciones
- Producto Académico 3 2022 - 20Documento3 páginasProducto Académico 3 2022 - 20LUDINA ESTRELLA MALLQUI MARIÑASAún no hay calificaciones
- Proyecto Calculo IDocumento18 páginasProyecto Calculo IMiguel Angel Estrada PatiñoAún no hay calificaciones
- 111 EVALUACION 2 Rls UNPHUDocumento7 páginas111 EVALUACION 2 Rls UNPHUIlcania RodriguezAún no hay calificaciones
- Pa3 NRC-21207Documento6 páginasPa3 NRC-21207Luis LopezAún no hay calificaciones
- Ejercicios de AmortizaciónDocumento3 páginasEjercicios de AmortizaciónJuan Francisco Guanilo Cruzado67% (3)
- Producto Academico 3Documento10 páginasProducto Academico 3CHRISTIAN FIDEL VILCA OJEDAAún no hay calificaciones
- Cabrera Armando Act1Documento8 páginasCabrera Armando Act1Armando CabreraAún no hay calificaciones
- Producto Académico 3 ESTADISTICADocumento6 páginasProducto Académico 3 ESTADISTICAMaria HuamanAún no hay calificaciones
- Taller RegresionDocumento15 páginasTaller RegresionRaul PiedyAún no hay calificaciones
- Taller Estadistica 2Documento11 páginasTaller Estadistica 2Yecenia ZarateAún no hay calificaciones
- Produccion Regresion LinealDocumento6 páginasProduccion Regresion LinealHamilton MtzAún no hay calificaciones
- Taller Teoria de La ProbabilidadDocumento14 páginasTaller Teoria de La ProbabilidadVanessa Velásquez60% (5)
- Taller de Regresión y Correlación LinealDocumento6 páginasTaller de Regresión y Correlación LinealHeidy Tatiana CORTES BELTRANAún no hay calificaciones
- Análisis de Regresión y Correlación Tema 5 EADocumento31 páginasAnálisis de Regresión y Correlación Tema 5 EAyajanna.31874457Aún no hay calificaciones
- Endrik EstadisticaDocumento3 páginasEndrik EstadisticaVicky RamirezAún no hay calificaciones
- Libro 1Documento13 páginasLibro 1Jennifer CUELLAR VELASQUEZAún no hay calificaciones
- Examen Analisis 2Documento9 páginasExamen Analisis 2Scarlett tatiana Membreño cotoAún no hay calificaciones
- Actividad 8-Estdistica DescriptivaDocumento9 páginasActividad 8-Estdistica Descriptivajuan jesusAún no hay calificaciones
- Alejandro - Quiñones - s4 Estadistica.Documento7 páginasAlejandro - Quiñones - s4 Estadistica.Alejandro QuinonesAún no hay calificaciones
- Producto Académico 3 2022 - 20Documento7 páginasProducto Académico 3 2022 - 20Huber Rogger Marquina QuispeAún no hay calificaciones
- Libro 1Documento2 páginasLibro 1Elsa pitoAún no hay calificaciones
- Producto Academico 3Documento10 páginasProducto Academico 3CHRISTIAN FIDEL VILCA OJEDAAún no hay calificaciones
- Dispersion Datos AgrupadosDocumento2 páginasDispersion Datos AgrupadosMaria Sierra TorresAún no hay calificaciones
- Producto Académico 3 ESTADISTICA GENERALDocumento7 páginasProducto Académico 3 ESTADISTICA GENERALTakeshi OviedoAún no hay calificaciones
- Ejemplo Aplicación ABCDocumento6 páginasEjemplo Aplicación ABCAle HopAún no hay calificaciones
- Benavente Cusacani Jose EnriqueDocumento8 páginasBenavente Cusacani Jose EnriqueRaquelAún no hay calificaciones
- Producto Academico 1Documento4 páginasProducto Academico 1Paolo LopezAún no hay calificaciones
- Tarea - RegresionDocumento5 páginasTarea - RegresionCHAVEZ CABANILLAS LIZBETH JAQUELINAún no hay calificaciones
- Gutierrez Luis Natalia-ActDocumento12 páginasGutierrez Luis Natalia-ActNATALIA GUTIERREZ LUISAún no hay calificaciones
- Hoja de Trabajo No. 4Documento3 páginasHoja de Trabajo No. 4ANA ASENCIOAún no hay calificaciones
- Lo nuevo de Excel 2019: Incluye los mejores complementos y herramientas powerDe EverandLo nuevo de Excel 2019: Incluye los mejores complementos y herramientas powerAún no hay calificaciones
- Clase 090-01-2021Documento12 páginasClase 090-01-2021JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Clase 16-01-2021Documento12 páginasClase 16-01-2021JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Clase 20-01-2021Documento7 páginasClase 20-01-2021JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Clase 23-01-2021Documento8 páginasClase 23-01-2021JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Clase 30-01-2021Documento8 páginasClase 30-01-2021JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 15. DAHH BlendedDocumento47 páginasVideoclase Gestión de Operaciones, Sesión 15. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 13. DAHH BlendedDocumento13 páginasVideoclase Gestión de Operaciones, Sesión 13. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 4. DAHH BlendedDocumento54 páginasVideoclase Gestión de Operaciones, Sesión 4. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 11. DAHH BlendedDocumento44 páginasVideoclase Gestión de Operaciones, Sesión 11. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 10. DAHH BlendedDocumento38 páginasVideoclase Gestión de Operaciones, Sesión 10. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 14. DAHH BlendedDocumento6 páginasVideoclase Gestión de Operaciones, Sesión 14. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 12. DAHH BlendedDocumento55 páginasVideoclase Gestión de Operaciones, Sesión 12. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- PDF Tarea 4 Caso Cadena de Suministros CompressDocumento4 páginasPDF Tarea 4 Caso Cadena de Suministros CompressJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Sesion 01 Alcance, Linea Base Politica y Objetivos GQTDocumento23 páginasSesion 01 Alcance, Linea Base Politica y Objetivos GQTJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 9. DAHH BlendedDocumento41 páginasVideoclase Gestión de Operaciones, Sesión 9. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- PDF Actividad Despues de Clase Grupal Caso Zara CompressDocumento23 páginasPDF Actividad Despues de Clase Grupal Caso Zara CompressJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- PA 1 (Tarea) .VFDocumento3 páginasPA 1 (Tarea) .VFJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gestión de Operaciones, Sesión 8. DAHH BlendedDocumento38 páginasVideoclase Gestión de Operaciones, Sesión 8. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gerencia de Operaciones, Semana 1. DAHHDocumento50 páginasVideoclase Gerencia de Operaciones, Semana 1. DAHHJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Videoclase Gerencia de Operaciones, Semana 2. DAHH BlendedDocumento27 páginasVideoclase Gerencia de Operaciones, Semana 2. DAHH BlendedJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Portal Del Estudiante - Servicos VirtualesDocumento1 páginaPortal Del Estudiante - Servicos VirtualesJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Gestión Profesional 4 GPPDocumento11 páginasGestión Profesional 4 GPPJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Gestión Profesional 1 GPPDocumento13 páginasGestión Profesional 1 GPPJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Portal Del Estudiante - Servicos VirtualesDocumento1 páginaPortal Del Estudiante - Servicos VirtualesJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Prueba Mixta - Individual - Unidad 1Documento5 páginasPrueba Mixta - Individual - Unidad 1JERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Gestión Profesional - 7 - GPPDocumento16 páginasGestión Profesional - 7 - GPPJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Gestión Profesional 3 GPPDocumento15 páginasGestión Profesional 3 GPPJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- Gestión Profesional 5 GPPDocumento12 páginasGestión Profesional 5 GPPJERSIN JULINHO ZEVALLOS ARZAPALOAún no hay calificaciones
- HistogramaDocumento29 páginasHistogramajesus_m_b25100% (1)
- Unidad 1 Act 3 Caso Practico Costo de La Energia Electrica en La Colonia Popotla Juvenal Martinez LunaDocumento9 páginasUnidad 1 Act 3 Caso Practico Costo de La Energia Electrica en La Colonia Popotla Juvenal Martinez LunamarioAún no hay calificaciones
- Apuntes de ClaseDocumento9 páginasApuntes de ClaseDiana CaviedesAún no hay calificaciones
- Ole Ay Jimenez To MoiDocumento119 páginasOle Ay Jimenez To MoiCRISTIAN GARCIA BERMUDEZAún no hay calificaciones
- Unidad 4 y 5Documento57 páginasUnidad 4 y 5José Miguel MarAún no hay calificaciones
- REGRESION LINEAL SIMPLE Martinez Sanchezx EdgarDocumento8 páginasREGRESION LINEAL SIMPLE Martinez Sanchezx EdgarJuan Carlos HsedanoAún no hay calificaciones
- Contenido (MyE)Documento3 páginasContenido (MyE)JOHANA OLLARVEAún no hay calificaciones
- Ejercicios Resueltos en ConferenciaDocumento12 páginasEjercicios Resueltos en ConferenciaGilberto CarbajalAún no hay calificaciones
- Práctica 02072021Documento2 páginasPráctica 02072021Joselin ParedesAún no hay calificaciones
- Ing CivilDocumento13 páginasIng Civilstevew apellidosAún no hay calificaciones
- 5 - Modelo Lineal GeneralDocumento22 páginas5 - Modelo Lineal GeneralARIEL FUENTES FORONDAAún no hay calificaciones
- Intervalo de Confianza para La Varianza2Documento5 páginasIntervalo de Confianza para La Varianza2BRIAN SMIDTH ARIAS CHICLLAAún no hay calificaciones
- CuasivarianzaDocumento6 páginasCuasivarianzaBelen Eileen SaldañaAún no hay calificaciones
- Taller de Tendencia y RegresiónDocumento9 páginasTaller de Tendencia y RegresiónStephanie PachónAún no hay calificaciones
- I2 1189Documento234 páginasI2 1189marcial cabreraAún no hay calificaciones
- Final Virtual 1C2020 - SoluciónDocumento4 páginasFinal Virtual 1C2020 - SoluciónsandraAún no hay calificaciones
- Stata Evaluacion FinalDocumento5 páginasStata Evaluacion FinalEduardo Sanchez RoselloAún no hay calificaciones
- Silabo Inferencia Estadistica (2021 A)Documento6 páginasSilabo Inferencia Estadistica (2021 A)Edward ZarateAún no hay calificaciones
- Ejercicios Mates 1 Bach - Estadística Bidimensional Con SolucionesDocumento3 páginasEjercicios Mates 1 Bach - Estadística Bidimensional Con SolucionesBeatriz FelipeAún no hay calificaciones
- Regresión Lineal MúltipleDocumento6 páginasRegresión Lineal Múltipledavid iturbideAún no hay calificaciones
- Ejercicio 9.6 SalvatoreDocumento22 páginasEjercicio 9.6 SalvatoreAleP_lAún no hay calificaciones
- BidimensionalDocumento88 páginasBidimensionalPaolaAún no hay calificaciones
- Segundo Parcial Grupo ADocumento8 páginasSegundo Parcial Grupo AJASVEILY YULIANY SALAZAR CARRASCALAún no hay calificaciones
- Datos de PanelDocumento24 páginasDatos de PanelMarck Lizondo AriAún no hay calificaciones
- 9.2.1 Calculo Del Numero Optimo de SimulacionesDocumento15 páginas9.2.1 Calculo Del Numero Optimo de SimulacionesLuis AngelAún no hay calificaciones
- Evaluacion Final - Escenario 8 - Primer Bloque-Ciencias Basicas - Virtual - Estadística Inferencial - (Grupo b01)Documento10 páginasEvaluacion Final - Escenario 8 - Primer Bloque-Ciencias Basicas - Virtual - Estadística Inferencial - (Grupo b01)bryan giovanny Cardenas AcostaAún no hay calificaciones
- Ejemplo Regresion MultipleDocumento6 páginasEjemplo Regresion MultipleSandra Martinez100% (1)
- AutocorrelaciónDocumento29 páginasAutocorrelaciónDarwin CaipeAún no hay calificaciones
- Ejercicios Regresion MultipleDocumento8 páginasEjercicios Regresion Multipleelver galargauisAún no hay calificaciones
- Trabajo Grupal Evaluado Maestria Civil 2Documento26 páginasTrabajo Grupal Evaluado Maestria Civil 2Jean PiereAún no hay calificaciones