También podría gustarte
- Análisis y Diseño Experimental Electiva - Octubre 5 2010Documento61 páginasAnálisis y Diseño Experimental Electiva - Octubre 5 2010jonava666Aún no hay calificaciones
- Prueba de Hipótesis, Conclusiones Y RecomendacioenDocumento24 páginasPrueba de Hipótesis, Conclusiones Y RecomendacioenJorge luisAún no hay calificaciones
- LFQ1-2017.2 Análisis EstadísticoDocumento17 páginasLFQ1-2017.2 Análisis EstadísticoPrácticas 2021Aún no hay calificaciones
- Exposiciondistribuciondechicuadradogrupo21 120918120736 Phpapp01Documento31 páginasExposiciondistribuciondechicuadradogrupo21 120918120736 Phpapp01ELIBER DIONISIO RODR�GUEZ GONZALESAún no hay calificaciones
- Chi CuadradoDocumento10 páginasChi CuadradoBladimir Pin PosliguaAún no hay calificaciones
- Inferencia Estadística y Prueba Chi-cuadradoDocumento13 páginasInferencia Estadística y Prueba Chi-cuadradoElias Jose Albis PachecoAún no hay calificaciones
- E2 Tema 4 Prueba de Hipótesis (Met, Med, Prop)Documento44 páginasE2 Tema 4 Prueba de Hipótesis (Met, Med, Prop)Tony CastellanosAún no hay calificaciones
- Libro Estadistica II PDFDocumento103 páginasLibro Estadistica II PDFMilton Gardner33% (3)
- Análisis de Varianza 1Documento24 páginasAnálisis de Varianza 1Marco ContrerasAún no hay calificaciones
- Distribucion de Chi Cuadrado 33 PDFDocumento25 páginasDistribucion de Chi Cuadrado 33 PDFC3BAún no hay calificaciones
- Chi CuadradoDocumento21 páginasChi CuadradoViorica Ishuiza RamirezAún no hay calificaciones
- Laboratorio Semana 10Documento8 páginasLaboratorio Semana 10Nick Stiven Aguilar HuarangaAún no hay calificaciones
- Anova, Regresión y CorrelaciónDocumento37 páginasAnova, Regresión y CorrelaciónRichard Felipe100% (1)
- Aplicaciones de la prueba chi cuadradoDocumento39 páginasAplicaciones de la prueba chi cuadradoMilagros Cardenas0% (1)
- Texto2 - Estadistica Inferencial - PHDocumento9 páginasTexto2 - Estadistica Inferencial - PHElena QuispeAún no hay calificaciones
- Estudios LongitudinalesDocumento152 páginasEstudios LongitudinalesLuis LuengoAún no hay calificaciones
- JI CuadradaDocumento15 páginasJI CuadradaPerla JuarezAún no hay calificaciones
- Unidad 5 Prueba Chi-CuadradoDocumento10 páginasUnidad 5 Prueba Chi-CuadradoMarco Franco AparicioAún no hay calificaciones
- Tarea Correlacion y T-StudentDocumento7 páginasTarea Correlacion y T-StudentMary Gubio GómezAún no hay calificaciones
- Análisis Regresión Correlación RLS R2Documento15 páginasAnálisis Regresión Correlación RLS R2YHUREMA DEL CARMEN GELDRES TORRESAún no hay calificaciones
- Chi CuadradaDocumento10 páginasChi CuadradaManuel Durant100% (2)
- Pruebas de Hipótesis para La Varianza y El Cociente de Varianza ..Documento24 páginasPruebas de Hipótesis para La Varianza y El Cociente de Varianza ..Yanina AlvarezAún no hay calificaciones
- RES342 - Entregable 2Documento8 páginasRES342 - Entregable 2Margarita Carrillo50% (2)
- Unidad Iii Analisis de DatosDocumento5 páginasUnidad Iii Analisis de DatosFernanda Catalina Zarricueta EsquivelAún no hay calificaciones
- BinomialDocumento86 páginasBinomialJhoel EnriqueAún no hay calificaciones
- P_sem7_ses4_Prueba de homogeneidadDocumento19 páginasP_sem7_ses4_Prueba de homogeneidadChristian RodriguezAún no hay calificaciones
- Tema VDocumento26 páginasTema VRoberto García-AlvarezAún no hay calificaciones
- Prueba Chi CuadradoDocumento8 páginasPrueba Chi CuadradoSkafronDiazAún no hay calificaciones
- Distribución Chi CuadradoDocumento43 páginasDistribución Chi CuadradoCarlos Nomberto Conde0% (1)
- Unidad 1 Parte 2Documento38 páginasUnidad 1 Parte 2YessyMedinaAún no hay calificaciones
- Distribución Chi CuadradoDocumento26 páginasDistribución Chi CuadradoJëffy Affëctüëüx0% (1)
- Unidad 1 (1.1.2)Documento43 páginasUnidad 1 (1.1.2)Ramiro CartuchiAún no hay calificaciones
- Aplicaciones de La Distribución Chi-CuadradoDocumento36 páginasAplicaciones de La Distribución Chi-CuadradoEdson Arturo Quispe Sánchez100% (1)
- Prueba de Bondad de AjusteDocumento28 páginasPrueba de Bondad de AjusteArisbeth Bernal SalinasAún no hay calificaciones
- Chi Cuadrado y Forma de Elaborar Las Hipotesis y Ver RelacionDocumento31 páginasChi Cuadrado y Forma de Elaborar Las Hipotesis y Ver RelacionCarlos SanabriaAún no hay calificaciones
- Laboratorio 14 Solucion PDFDocumento6 páginasLaboratorio 14 Solucion PDFaraceliAún no hay calificaciones
- Prueba de Normalidad PDFDocumento29 páginasPrueba de Normalidad PDFPitter MAYTA CASOAún no hay calificaciones
- Clase04 - Estadistica ComparativaDocumento35 páginasClase04 - Estadistica ComparativaGabriel Orlando Lopez CordovaAún no hay calificaciones
- Ingenium ANOVA IngeniumDocumento55 páginasIngenium ANOVA IngeniumHAROLD DANIEL AYBAR HUAMANAún no hay calificaciones
- Inferencia EstadísticaDocumento53 páginasInferencia EstadísticaSCCAún no hay calificaciones
- Curso Practico de Bioestadistica Con Herramientas - 1Documento36 páginasCurso Practico de Bioestadistica Con Herramientas - 1VERONICA NAVIAAún no hay calificaciones
- Experimentos en Nutrición Animal Caso1Documento59 páginasExperimentos en Nutrición Animal Caso1jose raul perezAún no hay calificaciones
- Medidas de AsociacionDocumento53 páginasMedidas de AsociacionAmanda Castro CamposAún no hay calificaciones
- Fase 3 - Jeisson - CastellanosDocumento49 páginasFase 3 - Jeisson - CastellanosJeisson CastellanosAún no hay calificaciones
- 1Documento8 páginas1Mario atencia chavezAún no hay calificaciones
- EstadisticaDocumento16 páginasEstadisticaJohanCasadiegoAún no hay calificaciones
- Sesion 11 Del 6 MayoDocumento8 páginasSesion 11 Del 6 MayoMILAGROS GUADALUPE ZAMORA LOPEZAún no hay calificaciones
- 023ANOVADocumento49 páginas023ANOVAOswaldo LópezAún no hay calificaciones
- Tutoria 11 Introduccion Al Analisis de Datos 2019 2020Documento94 páginasTutoria 11 Introduccion Al Analisis de Datos 2019 2020Tito BoniAún no hay calificaciones
- TEMA - Regresion LinealDocumento34 páginasTEMA - Regresion LinealAlejandro GutierrezAún no hay calificaciones
- Prueba Shapiro-Wilk normalidad datosDocumento4 páginasPrueba Shapiro-Wilk normalidad datosrioscameyAún no hay calificaciones
- Producto Académico 3 - Verano 2022 (1)Documento9 páginasProducto Académico 3 - Verano 2022 (1)RUBI CAROLINA ESPICHAN MORENOAún no hay calificaciones
- PruebasDocumento37 páginasPruebasKAROLAY ALEXANDRA MENDOZA MILLAAún no hay calificaciones
- Auto Evaluacion Exm Final ESTADISTICA 1 SOLUCIONARIODocumento4 páginasAuto Evaluacion Exm Final ESTADISTICA 1 SOLUCIONARIOAldo Mendoza100% (1)
- Ejemplos Hipotesis-Chi-Cuadrado PDFDocumento14 páginasEjemplos Hipotesis-Chi-Cuadrado PDFfernalva2014Aún no hay calificaciones
- ANOVA ResueltoDocumento5 páginasANOVA ResueltoFranco CentAún no hay calificaciones
- Estadística inferencial aplicadaDe EverandEstadística inferencial aplicadaCalificación: 5 de 5 estrellas5/5 (1)
- Razonamiento cuantitativo, 2ª edición: Notas de claseDe EverandRazonamiento cuantitativo, 2ª edición: Notas de claseCalificación: 5 de 5 estrellas5/5 (1)
- Diagrama y Sistema Eléctrico de Moto Kawasaki Ninja 300 - Manual de Taller, Reparación y Desarme PDFDocumento58 páginasDiagrama y Sistema Eléctrico de Moto Kawasaki Ninja 300 - Manual de Taller, Reparación y Desarme PDFTony Castellanos100% (1)
- Proceso Administrativo Consorcio Artesanas Santiago AtitlánDocumento6 páginasProceso Administrativo Consorcio Artesanas Santiago AtitlánTony CastellanosAún no hay calificaciones
- Pert Clase 2Documento3 páginasPert Clase 2Tony CastellanosAún no hay calificaciones
- El caso Volkswagen: análisis ASGDocumento14 páginasEl caso Volkswagen: análisis ASGTony CastellanosAún no hay calificaciones
- Base Seguimiento 1 Estadistica II 1er Ciclo 2020Documento2 páginasBase Seguimiento 1 Estadistica II 1er Ciclo 2020Tony CastellanosAún no hay calificaciones
- TRANSCRIPCIÓN ENTREVISTA Formato 2021Documento2 páginasTRANSCRIPCIÓN ENTREVISTA Formato 2021Tony CastellanosAún no hay calificaciones
- Estrategias de ProductoDocumento50 páginasEstrategias de ProductoTony CastellanosAún no hay calificaciones
- Ejercicio Flujo Efectivo Don Confusio ClasesDocumento3 páginasEjercicio Flujo Efectivo Don Confusio ClasesTony CastellanosAún no hay calificaciones
- Estrategias de Negocios Según Segmentación de MercadoDocumento18 páginasEstrategias de Negocios Según Segmentación de MercadoTony CastellanosAún no hay calificaciones
- Comportamiento Organizacional 2021Documento6 páginasComportamiento Organizacional 2021Tony CastellanosAún no hay calificaciones
- Cuadro A1 Población Total Por SexoDocumento7 páginasCuadro A1 Población Total Por SexonancyportilloAún no hay calificaciones
- Respuestas Tarea 5Documento8 páginasRespuestas Tarea 5Tony CastellanosAún no hay calificaciones
- Laboratorio 1 - Finanzas 1 Tony Castellanos 2421116Documento12 páginasLaboratorio 1 - Finanzas 1 Tony Castellanos 2421116Tony CastellanosAún no hay calificaciones
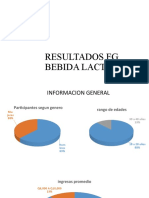
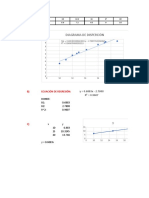
- FG Bebida LacteaDocumento9 páginasFG Bebida LacteaTony CastellanosAún no hay calificaciones
- Clase 4 de SeptiembreDocumento3 páginasClase 4 de SeptiembreTony CastellanosAún no hay calificaciones
- RegAnálisis tasas interés y casas vendidasDocumento11 páginasRegAnálisis tasas interés y casas vendidasTony CastellanosAún no hay calificaciones
- E2 Tema 4 Prueba de Hipótesis (Met, Med, Prop)Documento44 páginasE2 Tema 4 Prueba de Hipótesis (Met, Med, Prop)Tony CastellanosAún no hay calificaciones
- Tarea de Estadistica IIDocumento6 páginasTarea de Estadistica IITony CastellanosAún no hay calificaciones
- E2 07 Proyecto 4 Prueba de Hipã Tesis (Media y Proporciã N)Documento3 páginasE2 07 Proyecto 4 Prueba de Hipã Tesis (Media y Proporciã N)Tony CastellanosAún no hay calificaciones
- Prueba de Hipotesis de Dos MuestrasDocumento15 páginasPrueba de Hipotesis de Dos MuestrasTony CastellanosAún no hay calificaciones
- Ejemplos Del Video de Pruebas de Hipotesis Con Dos MuestrasDocumento22 páginasEjemplos Del Video de Pruebas de Hipotesis Con Dos MuestrasTony CastellanosAún no hay calificaciones
- E2 07 Proyecto 4 Prueba de Hipã Tesis (Media y Proporciã N)Documento3 páginasE2 07 Proyecto 4 Prueba de Hipã Tesis (Media y Proporciã N)Tony CastellanosAún no hay calificaciones
- Examen Final 2 Mef II-2016Documento5 páginasExamen Final 2 Mef II-2016Miguel Fernando Antezana AlbaAún no hay calificaciones
- Metodología de Investigación IiDocumento8 páginasMetodología de Investigación IiYaniber Castillejo RealesAún no hay calificaciones
- 3 ACTIVIDAD 10% II CORTE MatematicaDocumento9 páginas3 ACTIVIDAD 10% II CORTE Matematicamaria jose moretty MendozaAún no hay calificaciones
- 3C - Jose Manuel Sanchez GutierrezDocumento10 páginas3C - Jose Manuel Sanchez GutierrezManuel SanchezAún no hay calificaciones
- Libro - Como Hacer La Tesis Universitaria CanahuireDocumento66 páginasLibro - Como Hacer La Tesis Universitaria CanahuireDeltaNubs DeltaNubsAún no hay calificaciones
- Examen Parcial 3Documento4 páginasExamen Parcial 3Cristian Santiago GuerreroAún no hay calificaciones
- Ejercicios Parcial 3Documento5 páginasEjercicios Parcial 3Jose Miguel MuñozAún no hay calificaciones
- Mapa Método SimplexDocumento1 páginaMapa Método SimplexDayanna Jazmín Vergara CastilloAún no hay calificaciones
- Analisis Numerico Apunte Regresion Lineal PDFDocumento7 páginasAnalisis Numerico Apunte Regresion Lineal PDFArlette Ramirez ValdesAún no hay calificaciones
- REGRESIONDocumento6 páginasREGRESIONAngAbi RodriguezAún no hay calificaciones
- Media Cuadrática - WikipediaDocumento2 páginasMedia Cuadrática - WikipediaRicardo Villalonga0% (1)
- Lab04 521230 2018 PDFDocumento10 páginasLab04 521230 2018 PDFAndres LAún no hay calificaciones
- U PR 10.004.003 Procedimiento Aseguramiento Metrologico PDFDocumento9 páginasU PR 10.004.003 Procedimiento Aseguramiento Metrologico PDFJGlobexAún no hay calificaciones
- Relatividad general: Notas de Luis J. GarayDocumento186 páginasRelatividad general: Notas de Luis J. Garayberto3493Aún no hay calificaciones
- UntitledDocumento32 páginasUntitledwcv587Aún no hay calificaciones
- Análisis Numérico PDFDocumento488 páginasAnálisis Numérico PDFJosé Miguel Gómez GuzmánAún no hay calificaciones
- Cálculo I Ejercicios 02 18-06-2023Documento3 páginasCálculo I Ejercicios 02 18-06-2023nikol dayanna henao barreraAún no hay calificaciones
- 5.equilibrio QuímicoDocumento18 páginas5.equilibrio QuímicoHuaira Tardio María IsabelAún no hay calificaciones
- Modulo 3º Raz. Matematico - II BimestreDocumento25 páginasModulo 3º Raz. Matematico - II BimestreDiego Rod MontAún no hay calificaciones
- LETRA DDocumento6 páginasLETRA Dfredy alexander arenas bedoyaAún no hay calificaciones
- Actividad de Aprendizaje Unidad 3Documento7 páginasActividad de Aprendizaje Unidad 3Mafe Sabrina RodriguezAún no hay calificaciones
- Matematicas GeneralDocumento138 páginasMatematicas GeneralRoyAún no hay calificaciones
- Lab 4 ControlDocumento5 páginasLab 4 ControlGerardo VieraAún no hay calificaciones
- Examenes Mateco 1Documento4 páginasExamenes Mateco 1Enrique Barrientos ApumaytaAún no hay calificaciones
- ESTADISTICA Trabajo Grupal Regresion MultiplefinalDocumento28 páginasESTADISTICA Trabajo Grupal Regresion MultiplefinalDavid SincheAún no hay calificaciones
- Calculo IDocumento53 páginasCalculo IAnthonyCondeMuñozAún no hay calificaciones
- Ejercicios Medidas de Tendencia CentralDocumento2 páginasEjercicios Medidas de Tendencia CentralInes Yolanda Vasquez Atanacio100% (2)
- Equilibrio y PHDocumento2 páginasEquilibrio y PHIrene CastilleroAún no hay calificaciones
- Pronosticos. Semana 8 I Parte Cap 4Documento35 páginasPronosticos. Semana 8 I Parte Cap 4Rolando PalaciosAún no hay calificaciones
- Parcial2 CD 2017 II PDFDocumento3 páginasParcial2 CD 2017 II PDFPedro Luis Ramos TiradoAún no hay calificaciones