También podría gustarte
- Big Data TelcoDocumento27 páginasBig Data TelcoMarcoAún no hay calificaciones
- 3 - Omar Aguilar - Inteligencia Artificial Basada en El Empleo de Big Data, IOT y Redes Neuronales PDFDocumento43 páginas3 - Omar Aguilar - Inteligencia Artificial Basada en El Empleo de Big Data, IOT y Redes Neuronales PDFSteven Escate ChamorroAún no hay calificaciones
- 2021 Módulo 1 - v1 - Envio - Semana1Documento82 páginas2021 Módulo 1 - v1 - Envio - Semana1Leonardo Noriega CabreraAún no hay calificaciones
- 01 Sesion Introducción Al BIDocumento31 páginas01 Sesion Introducción Al BISANTOS CIRIACO SOTELO ANTAURCOAún no hay calificaciones
- Clase 1 Intro BI y ML 1Documento39 páginasClase 1 Intro BI y ML 1Felipe IgnacioAún no hay calificaciones
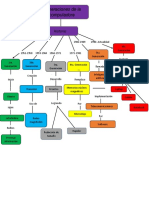
- Mapas ConceptualesDocumento5 páginasMapas ConceptualesJuan NaranjoAún no hay calificaciones
- MIERCOLESDocumento24 páginasMIERCOLESricardosusaAún no hay calificaciones
- Bigdatagrandesempresas PDFDocumento41 páginasBigdatagrandesempresas PDFaxel diazAún no hay calificaciones
- Gestión de Datos en Las Organizaciones - Sesiones 13 y 14Documento18 páginasGestión de Datos en Las Organizaciones - Sesiones 13 y 14joaquinAún no hay calificaciones
- 2022 C1 Fundamentos (Estudio)Documento55 páginas2022 C1 Fundamentos (Estudio)Javiera MatildaAún no hay calificaciones
- Tecnologías Disruptivas y Selección de PersonalDocumento44 páginasTecnologías Disruptivas y Selección de Personalsystem32.661Aún no hay calificaciones
- MD TecnologiasDocumento40 páginasMD Tecnologiasrvargascanhas3071Aún no hay calificaciones
- MasterClass 2h 4RI en SectElectr @AIR-E by FP7 - REV0FP-20220804Documento54 páginasMasterClass 2h 4RI en SectElectr @AIR-E by FP7 - REV0FP-20220804Oscar Iván Ballesteros ParraAún no hay calificaciones
- Abb Ability Soluciones de Monitoreo Energetico 13 MayoDocumento44 páginasAbb Ability Soluciones de Monitoreo Energetico 13 MayoPablo GonzálezAún no hay calificaciones
- Generaciones de La Computadora: HistoriaDocumento1 páginaGeneraciones de La Computadora: HistoriaTatiana mejiaAún no hay calificaciones
- Segunda Sesion 2022Documento21 páginasSegunda Sesion 2022HUAMANÍ OSTOS JESÚSAún no hay calificaciones
- Matlab CCDocumento151 páginasMatlab CCJean huayta fernandezAún no hay calificaciones
- NH Transformación Digital Clase 02Documento50 páginasNH Transformación Digital Clase 02Rolin MendozaAún no hay calificaciones
- Big DataDocumento11 páginasBig DataMike CRAún no hay calificaciones
- Unidad 3 Clase 2Documento39 páginasUnidad 3 Clase 2IFTS 17Aún no hay calificaciones
- p8 - e Business y Tecnología de La Información en La Cadena de SuministrosDocumento32 páginasp8 - e Business y Tecnología de La Información en La Cadena de SuministrosBrisa LinaresAún no hay calificaciones
- Qué Es La Ciencia de DatosDocumento31 páginasQué Es La Ciencia de DatosGinaMarcelaAyola100% (1)
- 2021-07-23 Clase 1a RW - IoT Big DataDocumento27 páginas2021-07-23 Clase 1a RW - IoT Big DataDiego A. TarazonaAún no hay calificaciones
- Caso 1 Ibm - Proceso de Cambio y AdaptabilidadDocumento3 páginasCaso 1 Ibm - Proceso de Cambio y AdaptabilidadCarlo Pa PuAún no hay calificaciones
- Clase 1 - Introduccion CursoDocumento20 páginasClase 1 - Introduccion CursoCarlos Mallqui AlayoAún no hay calificaciones
- Gestión de Datos en Las Organizaciones - Sesiones 9 y 10Documento9 páginasGestión de Datos en Las Organizaciones - Sesiones 9 y 10joaquinAún no hay calificaciones
- CV IsmaDocumento2 páginasCV IsmaIsmao liveAún no hay calificaciones
- Presentación Comercial InnervycsDocumento38 páginasPresentación Comercial Innervycskagaku09Aún no hay calificaciones
- S12 Platform StrategyPYDocumento64 páginasS12 Platform StrategyPYJhosselinAún no hay calificaciones
- Políticas de DepuraciónDocumento4 páginasPolíticas de DepuraciónjesuAún no hay calificaciones
- Infografía de La Historia de La Informática PDFDocumento1 páginaInfografía de La Historia de La Informática PDFGoyo Pas Gon100% (1)
- Venngage - EditorDocumento1 páginaVenngage - EditorMaría Emilia TorresAún no hay calificaciones
- Big Data - AdministracionDocumento37 páginasBig Data - AdministracionVictoria EscobarAún no hay calificaciones
- Articles-74968 Recurso 13Documento52 páginasArticles-74968 Recurso 13CAMILO ANDRES OBANDO ABRILAún no hay calificaciones
- 105 Ac China Inventa El Papel DC Se Construye La F 5b0388848ead0ed02e8b4604Documento37 páginas105 Ac China Inventa El Papel DC Se Construye La F 5b0388848ead0ed02e8b4604Carlos VelázquezAún no hay calificaciones
- .IBM Cloud, Data & AI Summit 2019. Estado Del Arte de La Analítica de Datos y La Inteligencia ArtificialDocumento19 páginas.IBM Cloud, Data & AI Summit 2019. Estado Del Arte de La Analítica de Datos y La Inteligencia ArtificialR B FujitsuAún no hay calificaciones
- Introducción - Base Teórica Semana 1 y 2Documento54 páginasIntroducción - Base Teórica Semana 1 y 2juanAún no hay calificaciones
- Presentacion 4sat Danielbarria v9Documento36 páginasPresentacion 4sat Danielbarria v9Yohanns FloresAún no hay calificaciones
- Seguridad InformaticaDocumento12 páginasSeguridad Informaticayamil enrique castillo suarezAún no hay calificaciones
- Data Mining Con KNimeDocumento114 páginasData Mining Con KNimeJose VeronAún no hay calificaciones
- Gestión Comercial en Venta DigitalDocumento16 páginasGestión Comercial en Venta DigitalSandra CanalesAún no hay calificaciones
- Presentacion WB Control de Movimiento 291116Documento34 páginasPresentacion WB Control de Movimiento 291116jimbo1978Aún no hay calificaciones
- Mapa Conceptual Big Data-Iot-BlockchainDocumento1 páginaMapa Conceptual Big Data-Iot-BlockchainManu HernandezAún no hay calificaciones
- Presentación Cirion Technologies 2024Documento21 páginasPresentación Cirion Technologies 2024Patricia Ramírez SantanaAún no hay calificaciones
- 001 IntroduccionDocumento28 páginas001 Introduccionpaula quirogaAún no hay calificaciones
- Madurez de La Red InternetDocumento8 páginasMadurez de La Red InternetEduardo GamerAún no hay calificaciones
- Web 3 y Plataformas DiguitalesDocumento27 páginasWeb 3 y Plataformas DiguitalesAriel LlumiquingaAún no hay calificaciones
- Data-Science Infographic ESDocumento4 páginasData-Science Infographic ESJhojan MamaniAún no hay calificaciones
- BIG DATA en Exploración y Producción by JL GelotDocumento17 páginasBIG DATA en Exploración y Producción by JL Gelotjmsfranz1224100% (1)
- HV - Detallado-Darwin Vega ZambranoDocumento3 páginasHV - Detallado-Darwin Vega ZambranoDarwin VegaAún no hay calificaciones
- Clases 1 Lean-SigmaDocumento14 páginasClases 1 Lean-SigmaThalía ÁlvarezAún no hay calificaciones
- Josue Acencio Rijo: Ingeniero de SistemasDocumento1 páginaJosue Acencio Rijo: Ingeniero de SistemasJosue Acencio RijoAún no hay calificaciones
- Portafolio Sigra Magna PDFDocumento6 páginasPortafolio Sigra Magna PDFÁngel Galvis CAún no hay calificaciones
- Unidad 1 - Clase 3 - Conectividad IoTDocumento29 páginasUnidad 1 - Clase 3 - Conectividad IoTJulio Cesar Jurado PerezAún no hay calificaciones
- Inteligencia ArtificailDocumento16 páginasInteligencia ArtificailJaime TellAún no hay calificaciones
- Industria 4.0 en El Mundo Del Acero. Ing. Matias BertoniDocumento34 páginasIndustria 4.0 en El Mundo Del Acero. Ing. Matias BertoniINGEACERO CONSTRUCCIONESAún no hay calificaciones
- U4 IntroducciónBigDataDocumento32 páginasU4 IntroducciónBigDataJuan Diego DuffAún no hay calificaciones
- Industry 4.0 Aplicada Según Lantek - EleconomistaDocumento2 páginasIndustry 4.0 Aplicada Según Lantek - EleconomistaAsier OrtizAún no hay calificaciones
- Gestión de Datos en Las Organizaciones - Sesiones 11 y 12Documento30 páginasGestión de Datos en Las Organizaciones - Sesiones 11 y 12joaquinAún no hay calificaciones
- Computación en la nube: Estrategias de cloud computing en las empresasDe EverandComputación en la nube: Estrategias de cloud computing en las empresasAún no hay calificaciones
- Big Data TELEFONICADocumento15 páginasBig Data TELEFONICAMarcoAún no hay calificaciones
- Handout Sesion5Documento21 páginasHandout Sesion5YosueAún no hay calificaciones
- Big Data en La Industria de Las Telecomunicaciones TELEFONICADocumento34 páginasBig Data en La Industria de Las Telecomunicaciones TELEFONICAMarcoAún no hay calificaciones
- Big DataDocumento27 páginasBig DataMarcoAún no hay calificaciones
- Big Data en La IndustriaDocumento34 páginasBig Data en La IndustriaMarcoAún no hay calificaciones
- Big Data en La IndustriaDocumento34 páginasBig Data en La IndustriaMarcoAún no hay calificaciones
- Error EstandarDocumento4 páginasError EstandarMarcoAún no hay calificaciones
- Distribucion MuestralDocumento4 páginasDistribucion MuestralMarcoAún no hay calificaciones
- MASTERDocumento4 páginasMASTERMarcoAún no hay calificaciones
- Manual Practico para R ProjectDocumento61 páginasManual Practico para R ProjectIsrael AvendañoAún no hay calificaciones
- MASTERDocumento4 páginasMASTERMarcoAún no hay calificaciones
- Respuesta de Evaluación FinalDocumento32 páginasRespuesta de Evaluación FinalhectorAún no hay calificaciones
- Informe Radio MobileDocumento7 páginasInforme Radio MobileLuisAmableGrandaArciniega0% (1)
- Mme Tema 5Documento6 páginasMme Tema 5Soka0% (1)
- Act4 ArquitDocumento2 páginasAct4 ArquitJavier Alfredo Vazquez GarzaAún no hay calificaciones
- Guion Informe Técnico III FinalDocumento12 páginasGuion Informe Técnico III FinalmesiasAún no hay calificaciones
- Manual de Usuario Sistema DeseretDocumento3 páginasManual de Usuario Sistema DeseretAlisa PageAún no hay calificaciones
- Evaluación Por Áreas Y Niveles Industrial III: Página Principal Mis Cursos Industrial EVA - 3II - 17 Examen DemoDocumento25 páginasEvaluación Por Áreas Y Niveles Industrial III: Página Principal Mis Cursos Industrial EVA - 3II - 17 Examen DemoËďdýsson ČhüqűïîanaAún no hay calificaciones
- LogosDocumento1 páginaLogosprofecni31Aún no hay calificaciones
- Factura de Servicio CelularDocumento317 páginasFactura de Servicio CelularJeiler Velázquez HechavarriaAún no hay calificaciones
- InvOper I - Pert CPMDocumento4 páginasInvOper I - Pert CPMYesi Andre CaceresAún no hay calificaciones
- Funciones (Parte 1-MatI) (1°2023) )Documento38 páginasFunciones (Parte 1-MatI) (1°2023) )ALBERTO PEREZ DIAZAún no hay calificaciones
- Manual PASOPDocumento49 páginasManual PASOPPorfirio CadenaAún no hay calificaciones
- Ejercicios en WindowsDocumento18 páginasEjercicios en Windowsange2064@hotmail.comAún no hay calificaciones
- Amplificadores TransistorizadosDocumento7 páginasAmplificadores TransistorizadosJesus SanchezAún no hay calificaciones
- Ditch Witch 2150 Manual ESPAÑOL PDFDocumento39 páginasDitch Witch 2150 Manual ESPAÑOL PDFFabian Alonso Figueroa Cogollos100% (1)
- Plancha GCPDocumento25 páginasPlancha GCPNoé Joel Martinez HanccoAún no hay calificaciones
- Guia PolinomiosDocumento10 páginasGuia PolinomiosJuanAún no hay calificaciones
- 1.5 Katherine Cáceres Taller 2 de InformáticaDocumento5 páginas1.5 Katherine Cáceres Taller 2 de InformáticaKatherine CaceresAún no hay calificaciones
- GT-P1010 UM Open Galaxy Tab WiFiDocumento74 páginasGT-P1010 UM Open Galaxy Tab WiFijose luisAún no hay calificaciones
- Líneas Eróticas Casadas en MadridDocumento2 páginasLíneas Eróticas Casadas en MadridEroticoAún no hay calificaciones
- Autoevaluacion 3Documento17 páginasAutoevaluacion 3Frank Alder Osc100% (1)
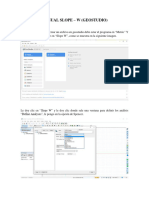
- Manual Slope W 2018Documento44 páginasManual Slope W 2018Fabian Rondon MuñozAún no hay calificaciones
- Revisión The Common European Framework of Reference For Languages and Ict: A New ChallengeDocumento11 páginasRevisión The Common European Framework of Reference For Languages and Ict: A New ChallengeAnastasiia AntonovaAún no hay calificaciones
- Jared Heredia Guillermo 8A MT Trabajo de Investigacion Unidad 1Documento32 páginasJared Heredia Guillermo 8A MT Trabajo de Investigacion Unidad 1Jared Heredia GuillermoAún no hay calificaciones
- Direcciones y Divisiones Del CicpcDocumento29 páginasDirecciones y Divisiones Del Cicpcluiisa100% (1)
- JGR - Fundamentos de Redes y Seguridad - Sem04 - 04 - FNRSDocumento5 páginasJGR - Fundamentos de Redes y Seguridad - Sem04 - 04 - FNRSpduranp18018Aún no hay calificaciones
- bLStkxcatalogo Ofertas Jampar v75Documento42 páginasbLStkxcatalogo Ofertas Jampar v75noemi sanchezAún no hay calificaciones
- (Print) Operadores en JavaScript v1.0.0Documento13 páginas(Print) Operadores en JavaScript v1.0.0Amtwan EdwardAún no hay calificaciones
- Código de Exceso 3Documento7 páginasCódigo de Exceso 3Ing Luis RojasAún no hay calificaciones
- Tablet InicialDocumento15 páginasTablet InicialPara el JardínAún no hay calificaciones