También podría gustarte
- Gestión Integral de Activos Físicos y MantenimientoDe EverandGestión Integral de Activos Físicos y MantenimientoAún no hay calificaciones
- Az 500 - Español PDFDocumento518 páginasAz 500 - Español PDFArturo TobiasAún no hay calificaciones
- Leonardo Rojas BoladosDocumento6 páginasLeonardo Rojas BoladosAntonio Leonardo Rojas BeckAún no hay calificaciones
- RCM EjemplosDocumento6 páginasRCM EjemplosMaite PromesaAún no hay calificaciones
- ConfiabilidadDocumento129 páginasConfiabilidadChiclla Quispe Percy100% (4)
- Manual de Confiabilidad SpanishDocumento61 páginasManual de Confiabilidad Spanishmaso_monin83% (12)
- Ingeniería de Confiabilidad FinalDocumento244 páginasIngeniería de Confiabilidad FinalJOHAN SEBASTIAN CUBILLOS HERNANDEZ100% (3)
- Analisis de Fallas - Pareto Vs Jack-KnifeDocumento10 páginasAnalisis de Fallas - Pareto Vs Jack-Knifempariaton5498100% (6)
- Manual de Confiabilidad (Spanish)Documento61 páginasManual de Confiabilidad (Spanish)bboy640100% (2)
- TBF Análisis Weibull 2PDocumento1 páginaTBF Análisis Weibull 2PMarco Arratia H.100% (3)
- Capitulo III Cuadro Mando Indicadores Básicos Parra Crespo 2017 SpanishDocumento22 páginasCapitulo III Cuadro Mando Indicadores Básicos Parra Crespo 2017 SpanishHugoCabanillasAún no hay calificaciones
- Guia SCO Ingenieria ConfiabilidadDocumento46 páginasGuia SCO Ingenieria ConfiabilidadBayronPalacioAún no hay calificaciones
- Libro Parra Crespo V20 2017 Capitulos I II ISO55000Documento48 páginasLibro Parra Crespo V20 2017 Capitulos I II ISO55000jparedesvillaltaAún no hay calificaciones
- Libro Parra Crespo V19 2017 Capitulos I II ISO55000Documento47 páginasLibro Parra Crespo V19 2017 Capitulos I II ISO55000Kriiss Pk Mur Allauca100% (1)
- Curso Confiabilidad 2015 PDFDocumento84 páginasCurso Confiabilidad 2015 PDFLuis Slend Corimanya100% (2)
- RCM y PAS 55Documento53 páginasRCM y PAS 55Judith Fiorella Huarancca Junes100% (2)
- Ingeniería de ConfiabilidadDocumento112 páginasIngeniería de ConfiabilidadDeyvi Lopez RiosAún no hay calificaciones
- Analisis Jack KnifeDocumento1 páginaAnalisis Jack Knifepcman30Aún no hay calificaciones
- Test de Mantenimiento y Confiabilidad SMRPDocumento6 páginasTest de Mantenimiento y Confiabilidad SMRPjoselito0371% (7)
- Analisis de ConfiabilidadDocumento16 páginasAnalisis de ConfiabilidadKJ79100% (3)
- 431 Mantenimiento Basado en CondicionDocumento6 páginas431 Mantenimiento Basado en CondicionAnonymous mI332q0uMOAún no hay calificaciones
- Modelos Matemáticos para Optimización de Reemplazo Preventivo e Inspecciones Preventivas PDFDocumento41 páginasModelos Matemáticos para Optimización de Reemplazo Preventivo e Inspecciones Preventivas PDFRodrigo Andres Vallejo CastroAún no hay calificaciones
- 12981-Editado-Alumno-Material AlumnoDocumento379 páginas12981-Editado-Alumno-Material AlumnoJames Márquez100% (1)
- M2 Ingenieria de ConfiabilidadDocumento99 páginasM2 Ingenieria de ConfiabilidadPedro Pablo Rojas Noguera100% (3)
- Parametros de Fallas y WeibullDocumento115 páginasParametros de Fallas y WeibullNicolas Recio Fdez-TresguerresAún no hay calificaciones
- Análisis Discreto de FallasDocumento1 páginaAnálisis Discreto de FallasMarco Arratia H.100% (3)
- RCM AsmeDocumento171 páginasRCM AsmeWalther Larico100% (5)
- XDDocumento3 páginasXDchristian huaman100% (1)
- CARLOS PARRA Índices Técnicos-EconómicosDocumento36 páginasCARLOS PARRA Índices Técnicos-EconómicosRichard Henry Sanchez Calderon100% (1)
- MANTENIMIENTO PREDICTIVO INDUSTRIAL 2010 Formato USACH (Modo de Compatibilidad) PDFDocumento436 páginasMANTENIMIENTO PREDICTIVO INDUSTRIAL 2010 Formato USACH (Modo de Compatibilidad) PDFCarlo MuñozAún no hay calificaciones
- CMRP Spanish Exam ApplicationDocumento5 páginasCMRP Spanish Exam Applicationhectorcotes197960% (5)
- 4.técnicas de Auditoría-Módulo IV PDFDocumento33 páginas4.técnicas de Auditoría-Módulo IV PDFLeonel HidalgoAún no hay calificaciones
- IG-102 Ingeniería de Confiabilidad SDVDocumento137 páginasIG-102 Ingeniería de Confiabilidad SDVRafael Torres Sabalza100% (1)
- Ingeniería de Mantenimiento y Fiabilidad Aplicada en La Gestión de ActivosDocumento282 páginasIngeniería de Mantenimiento y Fiabilidad Aplicada en La Gestión de ActivosPablo LazoAún no hay calificaciones
- Ingeniería de Mantenimiento OCP PDFDocumento32 páginasIngeniería de Mantenimiento OCP PDFjipercriperAún no hay calificaciones
- Confiabilidad OperacionalDocumento42 páginasConfiabilidad OperacionalRogger Melchor100% (3)
- Matriz Criticidad de EquiposDocumento4 páginasMatriz Criticidad de EquiposJuan Josue Paz Villanueva100% (5)
- Diseño y Optiización Planes de Inspección - MIDOPI PDFDocumento13 páginasDiseño y Optiización Planes de Inspección - MIDOPI PDFeduseghe3814Aún no hay calificaciones
- CMRP 5 PilaresDocumento185 páginasCMRP 5 PilaresrenzoAún no hay calificaciones
- Estudio Curva P-FDocumento8 páginasEstudio Curva P-FallmcbeallAún no hay calificaciones
- Análisis RAMDocumento23 páginasAnálisis RAMJordy Bernabe Salas100% (1)
- Ing. de Confiabilidad Aplicada Al Mantenimiento - Cliente - TECSUPDocumento184 páginasIng. de Confiabilidad Aplicada Al Mantenimiento - Cliente - TECSUPMayckAún no hay calificaciones
- Ejercicio Frec. InspecciónDocumento1 páginaEjercicio Frec. InspecciónMarco Arratia H.100% (2)
- Mantenimiento Centrado en ConfiabilidadDocumento23 páginasMantenimiento Centrado en ConfiabilidadandreavgrAún no hay calificaciones
- Contenido CMRPDocumento39 páginasContenido CMRPGiovanni Mancini100% (2)
- 10 - Apunte RCM - Teoría de La ConfiabilidadDocumento46 páginas10 - Apunte RCM - Teoría de La ConfiabilidadChristian Aguayo SeguelAún no hay calificaciones
- RCM Jhon MoubrayDocumento95 páginasRCM Jhon MoubrayLuis Felipe Gomez DiazAún no hay calificaciones
- Calculando La Frecuencia Optima de Mantenimiento o Reemplazo PreventivoDocumento13 páginasCalculando La Frecuencia Optima de Mantenimiento o Reemplazo Preventivorpercy01Aún no hay calificaciones
- RS480 - Mantenimiento Centrado en La Confiabilidad PDFDocumento244 páginasRS480 - Mantenimiento Centrado en La Confiabilidad PDFWalther Larico67% (3)
- Manual de gestión de activos y mantenimientoDe EverandManual de gestión de activos y mantenimientoCalificación: 5 de 5 estrellas5/5 (1)
- Investigación MTTR y MTBF PDFDocumento6 páginasInvestigación MTTR y MTBF PDFBriseidaa MartinezAún no hay calificaciones
- Comparaciones para MTBBDocumento18 páginasComparaciones para MTBBRichis LopezAún no hay calificaciones
- Conteste Las Preguntas 8.1 - 8.11 y 8.14 - 8.15Documento5 páginasConteste Las Preguntas 8.1 - 8.11 y 8.14 - 8.15info.growgrindrealestateAún no hay calificaciones
- Calculo y Analisis de RCM y AMEFDocumento34 páginasCalculo y Analisis de RCM y AMEFElizabeth Barrón Portillo100% (6)
- Confiabilidad en MVDDocumento11 páginasConfiabilidad en MVDiCOLAB - Gte IngenieriaAún no hay calificaciones
- Tiempo Medio Entre Fallas y Tiempo Medio para RepararDocumento14 páginasTiempo Medio Entre Fallas y Tiempo Medio para RepararGustavo Mario Torres SantamaríaAún no hay calificaciones
- RCMDocumento23 páginasRCMRicardo Fabio Medina DelgadoAún no hay calificaciones
- Factores A Considerar en La Selección y Determinación de Equipos CríticosDocumento9 páginasFactores A Considerar en La Selección y Determinación de Equipos Críticosangel6459Aún no hay calificaciones
- Proyecto Fiabilidad Embutidora La IbericaDocumento31 páginasProyecto Fiabilidad Embutidora La IbericaJavier GavilánezAún no hay calificaciones
- Movimiento Armonico SimpleDocumento8 páginasMovimiento Armonico SimpleRicardo Antonio Carrasco HuancasAún no hay calificaciones
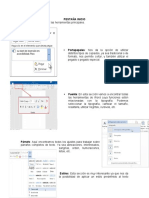
- Pestaña InicioDocumento7 páginasPestaña InicioGuadalupe XoyAún no hay calificaciones
- ArchivoPDF-5cruzar El PuenteDocumento34 páginasArchivoPDF-5cruzar El PuenteambaicaAún no hay calificaciones
- Transistores BJT 2Documento12 páginasTransistores BJT 2Natanael F'dezAún no hay calificaciones
- Reparaciones PS4Documento4 páginasReparaciones PS4Juan Torres VásquezAún no hay calificaciones
- Sistema de Inyeccion Directa de CombustibleDocumento29 páginasSistema de Inyeccion Directa de CombustibleMaikol Vallejos100% (1)
- Proyecto Digitalización Colecciones Ayuntamiento de LeonDocumento63 páginasProyecto Digitalización Colecciones Ayuntamiento de LeonVerd MentAún no hay calificaciones
- Conversores ADDocumento7 páginasConversores ADPablo RafaelAún no hay calificaciones
- Calculo Diferencial 1 PDFDocumento10 páginasCalculo Diferencial 1 PDFYuri Simraura MoreanoAún no hay calificaciones
- Samsung Rv510Documento4 páginasSamsung Rv510saexdanyAún no hay calificaciones
- Informe de LaboratorioDocumento8 páginasInforme de LaboratorioDanna CruzAún no hay calificaciones
- Supervision y Manejo Efectivo de Centro de ControlDocumento9 páginasSupervision y Manejo Efectivo de Centro de ControlRosita Natalia Farfan Vasquez100% (1)
- SSYMA D03.12 Programa Anual de Capacitacion de Medio Ambiente V9Documento5 páginasSSYMA D03.12 Programa Anual de Capacitacion de Medio Ambiente V9MARS BELL DANCE100% (1)
- Inventario Katherine Moya BrenesDocumento3 páginasInventario Katherine Moya BrenesKatherine BrenesAún no hay calificaciones
- Modbus RTUDocumento8 páginasModbus RTUJimmy GilcesAún no hay calificaciones
- Delito en El Comercio ElectrónicoDocumento8 páginasDelito en El Comercio ElectrónicoDáŕiél Aléxíś NBAún no hay calificaciones
- Metodos de Estudio 2022Documento44 páginasMetodos de Estudio 2022Elizabeth TeletorAún no hay calificaciones
- Sisa OriginalDocumento38 páginasSisa OriginalViorika Pamela Tuanama Hidalgo100% (1)
- Proyectos BIM - Arquitectura - Familias - Estructuras - MEPDocumento74 páginasProyectos BIM - Arquitectura - Familias - Estructuras - MEPAna AlbaAún no hay calificaciones
- Analizador de ArmonicosDocumento44 páginasAnalizador de Armonicosluis2006041380Aún no hay calificaciones
- Aporte Preguntas Orientadoras Paso 3Documento12 páginasAporte Preguntas Orientadoras Paso 3pablo caroAún no hay calificaciones
- 3 Diseño Curricular Administración de Empresas DUAL NAED MATRICULA 202210Documento256 páginas3 Diseño Curricular Administración de Empresas DUAL NAED MATRICULA 202210OSCAR OLAYAAún no hay calificaciones
- Numeros Reales ResumenDocumento3 páginasNumeros Reales Resumenjag1709Aún no hay calificaciones
- Conjunto Megalítico de RosasDocumento3 páginasConjunto Megalítico de Rosasandrea martinezAún no hay calificaciones
- Manual TrakerDocumento17 páginasManual TrakerSandra RenteriaAún no hay calificaciones
- DWES06. - Servicios WebDocumento48 páginasDWES06. - Servicios WebSoniaAún no hay calificaciones
- MF1 ContenidoDocumento66 páginasMF1 ContenidoSilvia Moreno TurrilloAún no hay calificaciones
- 03 Guias Mantenimiento Dispositivos PerifericosDocumento97 páginas03 Guias Mantenimiento Dispositivos PerifericosMiguel Salvador Aguilar RoblesAún no hay calificaciones