También podría gustarte
- 11 - 12 Normalización II-1Documento5 páginas11 - 12 Normalización II-1J͟o͟e͟ ͟S͟l͟e͟y͟t͟e͟r͟ G̷i̷m̷e̷n̷e̷z̷̶Aún no hay calificaciones
- Ea 1895 Programacion Orientada A Objetos II t4dn 01 Cl2 Lhi Ugaz EdsonDocumento3 páginasEa 1895 Programacion Orientada A Objetos II t4dn 01 Cl2 Lhi Ugaz EdsonJack Edwards Zenozain FloresAún no hay calificaciones
- Construcción de Una Base de Datos Partiendo de Sus DiseñosDocumento15 páginasConstrucción de Una Base de Datos Partiendo de Sus DiseñosJerson Enrique Blanco OlmosAún no hay calificaciones
- Leer Archivo XML C#Documento3 páginasLeer Archivo XML C#jhonext3055Aún no hay calificaciones
- 2.1. Construcción de ProgramasDocumento6 páginas2.1. Construcción de ProgramasgerarAún no hay calificaciones
- Solemne N°1Documento3 páginasSolemne N°1Cok3_93Aún no hay calificaciones
- Proyecto Video Club El Gallo Sampedrano PDFDocumento81 páginasProyecto Video Club El Gallo Sampedrano PDFLuis GoQui50% (2)
- Parcial III BD Junio 12 2018Documento3 páginasParcial III BD Junio 12 2018andradeAún no hay calificaciones
- Lab04-BDAV - Modelado de DatosDocumento14 páginasLab04-BDAV - Modelado de Datospepe3456jAún no hay calificaciones
- Roll and DrillDocumento15 páginasRoll and DrillOmar Alvarado CondeAún no hay calificaciones
- Informe Herramientas de Monitoreo de Bases de DatosDocumento12 páginasInforme Herramientas de Monitoreo de Bases de DatosCristhian CruzAún no hay calificaciones
- Construir Sentencias SQL para La Definición y Manipulación Del Modelo de Base de DatosDocumento12 páginasConstruir Sentencias SQL para La Definición y Manipulación Del Modelo de Base de DatosJANSERAún no hay calificaciones
- Practica 1 EntregarDocumento1 páginaPractica 1 EntregarMiguel Sánchez PolonioAún no hay calificaciones
- Trabajo en Parejas Evolucion WebDocumento4 páginasTrabajo en Parejas Evolucion WebJirō ŌkamiAún no hay calificaciones
- Clase 03 PowerBI BasicoDocumento31 páginasClase 03 PowerBI BasicoKenneth KauffmanAún no hay calificaciones
- INFORME Extracción Transformación y CargaDocumento9 páginasINFORME Extracción Transformación y CargaVictor Andres YungaicelaAún no hay calificaciones
- 04 Ejercicios NormalizaciónDocumento4 páginas04 Ejercicios NormalizaciónMartaAún no hay calificaciones
- Actividad1 Usuarios y PermisosDocumento19 páginasActividad1 Usuarios y PermisosLöręną PąląføxAún no hay calificaciones
- EP 6 0203 02E23 Transact SQLDocumento2 páginasEP 6 0203 02E23 Transact SQLMario AnnAún no hay calificaciones
- Articulo de LA INTELIGENCIA EMPRESARIAL - GestionDocumento1 páginaArticulo de LA INTELIGENCIA EMPRESARIAL - GestionJazmín Esperanza100% (1)
- Fibonnaci Android StudioDocumento16 páginasFibonnaci Android StudioJuanCarlosMontalvoPerezAún no hay calificaciones
- Taller 3 Ejercicios de SQL 23112017Documento1 páginaTaller 3 Ejercicios de SQL 23112017Gota GotaxAún no hay calificaciones
- Tutorial ETL Dataware HouseDocumento75 páginasTutorial ETL Dataware HouseLuis EnriqueAún no hay calificaciones
- Clase 6Documento46 páginasClase 6Leo MendezAún no hay calificaciones
- Flujo de DatosDocumento50 páginasFlujo de DatosMiguel Emmauel Iracheta Reyes100% (1)
- Arquitectura y Diseño de SoftwareDocumento8 páginasArquitectura y Diseño de SoftwareMatias Carrasco FloresAún no hay calificaciones
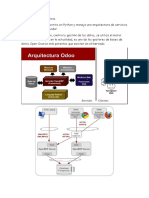
- Arquitectura OdooDocumento1 páginaArquitectura OdooChristian MillanAún no hay calificaciones
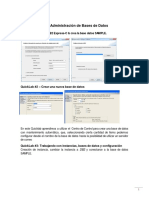
- LaboratoriosBDII PDFDocumento20 páginasLaboratoriosBDII PDFJosué MaidanaAún no hay calificaciones
- AP6-AA1-Ev2-Construir La Base de Datos para Proyecto de FormaciónDocumento13 páginasAP6-AA1-Ev2-Construir La Base de Datos para Proyecto de FormaciónEdwin UruetaAún no hay calificaciones
- Bases de Datos MultimediaDocumento11 páginasBases de Datos MultimediaAlbus DowbuldoreAún no hay calificaciones
- Actividad Unidad 3Documento3 páginasActividad Unidad 3pedrohernapok2020Aún no hay calificaciones
- Mongodb GuiaDocumento10 páginasMongodb GuiaRobinson Arley ROJAS NOVOAAún no hay calificaciones
- Ejemplo SADDocumento18 páginasEjemplo SADEdwin PalaciosAún no hay calificaciones
- EjerciciosDocumento39 páginasEjerciciosEmiliano Gonzalez100% (1)
- Examen Java StandarDocumento6 páginasExamen Java StandarGatoIvanAún no hay calificaciones
- Apuntes Diseña y Administra Data Bases 2019 - AlumnoDocumento58 páginasApuntes Diseña y Administra Data Bases 2019 - AlumnoDarko LemonsellosAún no hay calificaciones
- Estandar de Desarrollo y Buenas Practicas Con C# y SQLDocumento40 páginasEstandar de Desarrollo y Buenas Practicas Con C# y SQLjpereztmpAún no hay calificaciones
- Caso Práctico Dell - Jimena BarrancoDocumento10 páginasCaso Práctico Dell - Jimena Barrancojimena barrancoAún no hay calificaciones
- Ejercios SubredesDocumento5 páginasEjercios SubredesKevin Roman H.Aún no hay calificaciones
- Vázquez, Gabriel Clasificador Con Redes Neuronales para El Pronostico de La Enfermedad Renal CronicaDocumento105 páginasVázquez, Gabriel Clasificador Con Redes Neuronales para El Pronostico de La Enfermedad Renal CronicaMario GuillènAún no hay calificaciones
- Lab 1 Seguridad InformaticaDocumento20 páginasLab 1 Seguridad InformaticaMelky NavarroAún no hay calificaciones
- Spring MVCV 3 Paso APasoDocumento86 páginasSpring MVCV 3 Paso APasoVier RaffoAún no hay calificaciones
- Puntos de Funcion y Lineas de Codigo - ANÁLISIS DE LOS PUNTOS DE FUNCIÓN Y LINEAS DE CODIGODocumento3 páginasPuntos de Funcion y Lineas de Codigo - ANÁLISIS DE LOS PUNTOS DE FUNCIÓN Y LINEAS DE CODIGOAMILKAR JESUS MIRANDA ROMEROAún no hay calificaciones
- Ejercicios Power BiDocumento1 páginaEjercicios Power BiDiana BardónAún no hay calificaciones
- Soluciones de BI & BADocumento33 páginasSoluciones de BI & BAJose Luis Castilla100% (1)
- Taller 1 Programacion Orientada Al ObjetoDocumento2 páginasTaller 1 Programacion Orientada Al ObjetoKrysium moonbladeAún no hay calificaciones
- Practica de Laboratorio - Nslookup - WhoisDocumento7 páginasPractica de Laboratorio - Nslookup - WhoisTalito QuintoAún no hay calificaciones
- Data WarehouseDocumento14 páginasData WarehousePaul Ramos DuranAún no hay calificaciones
- Modelo IDEALDocumento14 páginasModelo IDEALperla ceballosAún no hay calificaciones
- Base de Datos IiDocumento3 páginasBase de Datos IiJosé ToroAún no hay calificaciones
- Actividad - 1 - JupyterLabDocumento57 páginasActividad - 1 - JupyterLabJose Vergara100% (1)
- Practica SQLDocumento6 páginasPractica SQLROLANDO100% (1)
- Presentación MongoDBDocumento12 páginasPresentación MongoDBJose SalazarAún no hay calificaciones
- Consultas Ms SQL Server y MysqlDocumento6 páginasConsultas Ms SQL Server y MysqlyuriarciniegasAún no hay calificaciones
- Tesis DatamartDocumento65 páginasTesis DatamartMarilis Corzo67% (3)
- Modelo Entidad RelacionDocumento2 páginasModelo Entidad RelacionMauricio SarangoAún no hay calificaciones
- 2022-23 - Apuntes Bases de DatosDocumento198 páginas2022-23 - Apuntes Bases de DatosPQAún no hay calificaciones
- Py TablesDocumento30 páginasPy TablesAprender LibreAún no hay calificaciones
- Limites de FirebirdDocumento13 páginasLimites de FirebirdangelAún no hay calificaciones
- Fundamentos de Programación y Bases de Datos: 2ª EdiciónDe EverandFundamentos de Programación y Bases de Datos: 2ª EdiciónAún no hay calificaciones
- Repaso SubnettingDocumento3 páginasRepaso SubnettingJaime MoyaAún no hay calificaciones
- Unidad 8Documento38 páginasUnidad 8Jaime MoyaAún no hay calificaciones
- Actividad 7.1Documento7 páginasActividad 7.1Jaime MoyaAún no hay calificaciones
- Plantilla Actividad 7 y 8Documento2 páginasPlantilla Actividad 7 y 8Jaime MoyaAún no hay calificaciones
- Actividad 6.2 JAIMEDocumento4 páginasActividad 6.2 JAIMEJaime MoyaAún no hay calificaciones
- Actividad 6.2Documento1 páginaActividad 6.2Jaime MoyaAún no hay calificaciones
- Actividad 6.2Documento4 páginasActividad 6.2Jaime MoyaAún no hay calificaciones
- Actividad 1. Lenguaje de MarcasDocumento8 páginasActividad 1. Lenguaje de MarcasJaime MoyaAún no hay calificaciones
- Cálculo de La Huella EcológicaDocumento1 páginaCálculo de La Huella EcológicaJaime MoyaAún no hay calificaciones
- wuolah-free-AR1 Test de Clase 2017 11 21 Todos Los Modelos PDFDocumento26 páginaswuolah-free-AR1 Test de Clase 2017 11 21 Todos Los Modelos PDFJaime MoyaAún no hay calificaciones
- wuolah-free-AR1 Test de Clase Todos Los Modelos 2017 12 19Documento17 páginaswuolah-free-AR1 Test de Clase Todos Los Modelos 2017 12 19Jaime MoyaAún no hay calificaciones
- Actividad 1 Implantacion de Sistemas Operativos.Documento7 páginasActividad 1 Implantacion de Sistemas Operativos.Jaime MoyaAún no hay calificaciones
- 2022-07-11 - Configuración de CRM en Odoo Comunity - Proyecto GrupalDocumento14 páginas2022-07-11 - Configuración de CRM en Odoo Comunity - Proyecto GrupalKoner PaulAún no hay calificaciones
- Procedimientos Almacenados de MySQL en Visual BasicDocumento3 páginasProcedimientos Almacenados de MySQL en Visual Basicosmarcelo100% (1)
- Ciclo For y SwitchDocumento2 páginasCiclo For y SwitchJorge BriceñoAún no hay calificaciones
- MSP430 IDE ConfigurationDocumento5 páginasMSP430 IDE ConfigurationFabian Rene Costa MoraAún no hay calificaciones
- PPO ErDocumento111 páginasPPO ErEdson RonaldAún no hay calificaciones
- Proyecto LiderazgoDocumento19 páginasProyecto LiderazgoLady Espino BellidoAún no hay calificaciones
- Manual de FPM (Español) 1de2Documento61 páginasManual de FPM (Español) 1de2Alberto J. Garrido ChecaAún no hay calificaciones
- Evaluación Escrita de HTMLDocumento6 páginasEvaluación Escrita de HTMLKaren MontañoAún no hay calificaciones
- Formatos PSPDocumento42 páginasFormatos PSPzaider garciaAún no hay calificaciones
- Presentación Sesión 4Documento27 páginasPresentación Sesión 4Samuel FortinAún no hay calificaciones
- Programaciòn 1Documento10 páginasProgramaciòn 1P 0 L 0Aún no hay calificaciones
- Octubre 1 Del Mes.Documento2 páginasOctubre 1 Del Mes.Pierre Gustavo Cortez MelendrezAún no hay calificaciones
- Programación VisualDocumento4 páginasProgramación VisualJosé LozanoAún no hay calificaciones
- ProyectoDocumento12 páginasProyectoMatus HerreraAún no hay calificaciones
- Reiniciar Restore RX User GuideDocumento3 páginasReiniciar Restore RX User GuideANTONIO GIMENEZ MILLORAún no hay calificaciones
- Introtoicefaces2v1 110209110021 Phpapp02Documento25 páginasIntrotoicefaces2v1 110209110021 Phpapp02Edinso PerezAún no hay calificaciones
- Migración de Datos A Azure Synapse AnalyticsDocumento2 páginasMigración de Datos A Azure Synapse AnalyticsCoin ServiceAún no hay calificaciones
- Formato PRIMER EXAMEN PARCIALDocumento10 páginasFormato PRIMER EXAMEN PARCIALFernanda Vilca SalgadoAún no hay calificaciones
- El DFDDocumento7 páginasEl DFDWilliam EspinozaAún no hay calificaciones
- Dream Weaver Diapositivas de Kevin Vasquez SaavedraDocumento19 páginasDream Weaver Diapositivas de Kevin Vasquez Saavedraalligator_kevinAún no hay calificaciones
- Foro Temático de Informatica.Documento3 páginasForo Temático de Informatica.Sianeth GNAún no hay calificaciones
- Evaluacion de Taller de Programacion ConcurrenteDocumento3 páginasEvaluacion de Taller de Programacion ConcurrenteKAREN BRIGIT QUISPE MAMANIAún no hay calificaciones
- Estructuras Lineales JavaDocumento13 páginasEstructuras Lineales JavaJulio BelloAún no hay calificaciones
- 2.introducción A ScratchDocumento39 páginas2.introducción A ScratchmimaleconAún no hay calificaciones
- Programación en CDocumento122 páginasProgramación en CRicardo CerdánAún no hay calificaciones
- Trabajo de Lenguajes de ProgramacionDocumento12 páginasTrabajo de Lenguajes de ProgramacionbfgdhAún no hay calificaciones
- Sie Actividad 5Documento7 páginasSie Actividad 5Alejandro León GoveaAún no hay calificaciones
- Daw03 Serv AplicDocumento28 páginasDaw03 Serv Aplicraxis2010Aún no hay calificaciones
- Ejercicio Práctico Sobre Bases de Datos y SQLDocumento20 páginasEjercicio Práctico Sobre Bases de Datos y SQLJosé Eduardo CabreraAún no hay calificaciones