También podría gustarte
- Ejemplos y Ejercicios Tamaño Muestra-Ciro-Martinez-Bencardino PDFDocumento7 páginasEjemplos y Ejercicios Tamaño Muestra-Ciro-Martinez-Bencardino PDFDaniel Vargas Ardila100% (1)
- Voces Del Exilio. Canada Edmonton. Litzy Baeza KallensDocumento117 páginasVoces Del Exilio. Canada Edmonton. Litzy Baeza KallensAdriana Goñi GodoyAún no hay calificaciones
- Corotos Kia Rio LX 2012Documento1 páginaCorotos Kia Rio LX 2012jesus.beltre.rosoAún no hay calificaciones
- Gestión y Dirección Gloria S.ADocumento31 páginasGestión y Dirección Gloria S.APaolo Blancas GuerraAún no hay calificaciones
- Moises AmDocumento47 páginasMoises AmCct Juan DavidAún no hay calificaciones
- Centro Centro Universitario Universitario de de Baja Baja Verap Verapaz AZDocumento3 páginasCentro Centro Universitario Universitario de de Baja Baja Verap Verapaz AZdennis castañedaAún no hay calificaciones
- Calculo CasDocumento2 páginasCalculo CasKely Janeth Bocanegra PinedoAún no hay calificaciones
- Satyajeet V Varekar Catalog 2022 (E Catalog)Documento15 páginasSatyajeet V Varekar Catalog 2022 (E Catalog)kartykanakAún no hay calificaciones
- Puntos Extra 4 Autocalificable - Revisión Del IntentoDocumento3 páginasPuntos Extra 4 Autocalificable - Revisión Del IntentoLuis Carranza100% (1)
- Capítulo 2 - Necesidades de Agua Del CultivoDocumento10 páginasCapítulo 2 - Necesidades de Agua Del Cultivodavid esteban BarraAún no hay calificaciones
- Frases Cristianas de Amor y Amistad Rincón de La FeDocumento1 páginaFrases Cristianas de Amor y Amistad Rincón de La FeMarkAún no hay calificaciones
- ¿Marketing y Mercadotecnia Significan Lo MismoDocumento4 páginas¿Marketing y Mercadotecnia Significan Lo MismoLuis Fernando GalleguillosAún no hay calificaciones
- Problemas Tema 9 Con Soluciones Estatica de FluidosDocumento23 páginasProblemas Tema 9 Con Soluciones Estatica de FluidosDaniel CastilloAún no hay calificaciones
- PDF Aplicacion de La Programacion Lineal en La Industria Textil 2 4 - CompressDocumento5 páginasPDF Aplicacion de La Programacion Lineal en La Industria Textil 2 4 - CompressJOSHEP DOUGLAS ESTRELLA CONDORAún no hay calificaciones
- Manejo Ambiental de Los Residuos Solidos Industriales II PDFDocumento238 páginasManejo Ambiental de Los Residuos Solidos Industriales II PDFMarcoRamirzAún no hay calificaciones
- Una Línea Bifilar Tiene Conductores de Cobre Con Radio Igual A 5 MMDocumento2 páginasUna Línea Bifilar Tiene Conductores de Cobre Con Radio Igual A 5 MMCarlos BartoAún no hay calificaciones
- PDF Proyecto Comunitario n1 - CompressDocumento26 páginasPDF Proyecto Comunitario n1 - CompressCarlos LopezAún no hay calificaciones
- dAEWOO LANOS PDFDocumento318 páginasdAEWOO LANOS PDFSamuel Fernando Becerra Peña0% (1)
- Prueba N1 de A Numeros DecimalesDocumento11 páginasPrueba N1 de A Numeros DecimalesDenisse Balart SAún no hay calificaciones
- Diccionario Español PortuguesDocumento12 páginasDiccionario Español PortuguesgonaxlAún no hay calificaciones
- GastronomiaDocumento46 páginasGastronomiaGastronomía mexicanaAún no hay calificaciones
- Teoria de Circuitos - Paulino Sanchez BarriosDocumento296 páginasTeoria de Circuitos - Paulino Sanchez Barriosandresdaniel13100% (3)
- Matriz Legal SST Mineria Cielo Abierto Capitulo4Documento213 páginasMatriz Legal SST Mineria Cielo Abierto Capitulo4Carlos Alberto MesaAún no hay calificaciones
- Libro CumbiaDocumento238 páginasLibro CumbiaAmargados Sociologia Dos Mil Doce100% (4)
- Aparicio AkDocumento87 páginasAparicio AkLucy PonceAún no hay calificaciones
- NM1 AlgebraDocumento6 páginasNM1 AlgebraGiovanni JonathanAún no hay calificaciones
- Modulo de Ingles 3Documento24 páginasModulo de Ingles 3ctel54Aún no hay calificaciones
- Presentacion TelemáticaDocumento1 páginaPresentacion TelemáticafloresdenieveAún no hay calificaciones
- 3 Guia Participante 7 Clase 2Documento15 páginas3 Guia Participante 7 Clase 2Carlos PajueloAún no hay calificaciones
- Lóbulos Temporales Anatomía y FunciónDocumento1 páginaLóbulos Temporales Anatomía y FunciónJennie SupremacyAún no hay calificaciones
- Wiac - Info PDF Registros de Gasto A Condiciones de Pozopptx PRDocumento21 páginasWiac - Info PDF Registros de Gasto A Condiciones de Pozopptx PRivan friasAún no hay calificaciones
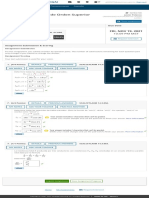
- Derivadas Parciales de Orden Superior - C Lculo III, Section 2, Fall 2021 - WebAssignDocumento1 páginaDerivadas Parciales de Orden Superior - C Lculo III, Section 2, Fall 2021 - WebAssignSaul CotaAún no hay calificaciones
- Normas Tesis (Modificado)Documento14 páginasNormas Tesis (Modificado)Antonio AguilarAún no hay calificaciones
- PDF Ficha de Evaluacion de TartamudezDocumento5 páginasPDF Ficha de Evaluacion de TartamudezKelvin MontesAún no hay calificaciones
- Cartel Vertical de Aviso de Atención Amarillo - PósterDocumento1 páginaCartel Vertical de Aviso de Atención Amarillo - PósterIngrid MartinezAún no hay calificaciones
- 1º Simposio LIJ - SaltaDocumento364 páginas1º Simposio LIJ - SaltaFlor PalermoAún no hay calificaciones
- Green Frog Mueca Navidad CompressDocumento18 páginasGreen Frog Mueca Navidad CompressmochicaramelliiAún no hay calificaciones
- 200 Verbos Avanzados en Inglés - Cathy English & More PDF Gramática SemióticaDocumento1 página200 Verbos Avanzados en Inglés - Cathy English & More PDF Gramática SemióticaDaniela SotoAún no hay calificaciones
- PDF Ficha de Evaluacion de TartamudezDocumento4 páginasPDF Ficha de Evaluacion de TartamudezKelvin MontesAún no hay calificaciones
- Las Pruebas de Corazón de Piedra de Fortnite ¡Juega y Obtén Recompensas en El Juego!Documento1 páginaLas Pruebas de Corazón de Piedra de Fortnite ¡Juega y Obtén Recompensas en El Juego!xnjh76fcccAún no hay calificaciones
- DIATDocumento1 páginaDIATMomo OwOAún no hay calificaciones
- Monografia Diseño DesarenadorDocumento14 páginasMonografia Diseño DesarenadorVale Ep0% (1)
- Matriz Legal SST Electrico Capitulo4Documento213 páginasMatriz Legal SST Electrico Capitulo4JOSE YOVANNI GARZON TRIANAAún no hay calificaciones
- DeluxeDocumento64 páginasDeluxeAlexander NarvaezAún no hay calificaciones
- Recambios Biomasa 2014-2015Documento53 páginasRecambios Biomasa 2014-2015diegoAún no hay calificaciones
- Bici MantasDocumento26 páginasBici MantasLuis BrunoAún no hay calificaciones
- 2015 Modelo Codigo Tributario CIAT PDFDocumento210 páginas2015 Modelo Codigo Tributario CIAT PDFAlvaroAún no hay calificaciones
- Calculadora de Metros Cúbicos Cómo Calcular LosDocumento1 páginaCalculadora de Metros Cúbicos Cómo Calcular LosRaquel OrtizAún no hay calificaciones
- Laboratorio Ciudadano PrototiLAB 2021Documento30 páginasLaboratorio Ciudadano PrototiLAB 2021Luis Fernando CastilloAún no hay calificaciones
- Distribución de La VelocidadDocumento18 páginasDistribución de La VelocidadDiana Laura VargasAún no hay calificaciones
- Familia de Verbos Irregulares InglésDocumento4 páginasFamilia de Verbos Irregulares InglésAdrián Jaén0% (2)
- Dodecil Sulfato de SodioDocumento4 páginasDodecil Sulfato de Sodio120984Aún no hay calificaciones
- Inteligencia de negocios y analítica de datosDe EverandInteligencia de negocios y analítica de datosAún no hay calificaciones
- Sistemas Digitales. Principios, análisis y diseñoDe EverandSistemas Digitales. Principios, análisis y diseñoAún no hay calificaciones
- Adm Finanzas 2-1Documento18 páginasAdm Finanzas 2-1mileystefitahAún no hay calificaciones
- Operaciones Con PolinomiosDocumento5 páginasOperaciones Con PolinomiosRominaAún no hay calificaciones
- Álgebra PDFDocumento18 páginasÁlgebra PDFoilujoinimiertAún no hay calificaciones
- Programación de ObraDocumento10 páginasProgramación de ObraSteven Hugo GuadamurAún no hay calificaciones
- Ex1020-Práctica1-Movilidad de MecanismosDocumento10 páginasEx1020-Práctica1-Movilidad de MecanismosDavid Soler OrtizAún no hay calificaciones
- ISF06. - Diseño, Dimensionado y Selección de Componentes de Instalaciones Fotovoltaica AutónomosDocumento62 páginasISF06. - Diseño, Dimensionado y Selección de Componentes de Instalaciones Fotovoltaica AutónomosraulslvaAún no hay calificaciones
- Calculo de La Precipitacion NetaDocumento8 páginasCalculo de La Precipitacion NetaYury Lenin RamirezAún no hay calificaciones
- Practica Ford FulkersonDocumento26 páginasPractica Ford FulkersonReparacion and ElectronicaAún no hay calificaciones
- Mecanica de Fluidos "Cuba de Reynolds"Documento19 páginasMecanica de Fluidos "Cuba de Reynolds"Cristhian Villa GonzalesAún no hay calificaciones
- Métodos y Diseños de Investigación en Psicología.Documento8 páginasMétodos y Diseños de Investigación en Psicología.Melanie IslasAún no hay calificaciones
- FactorizacionDocumento3 páginasFactorizacionCristhian FloresAún no hay calificaciones
- Mecanismo de BielaDocumento6 páginasMecanismo de Bielakikin312012Aún no hay calificaciones
- Asignación GPI 3Documento5 páginasAsignación GPI 3yorAún no hay calificaciones
- Demostraciones y Aplicaciones de ConicasDocumento14 páginasDemostraciones y Aplicaciones de ConicasJuan Diego Murguia100% (1)
- 03-Los Interface de MastercamDocumento12 páginas03-Los Interface de MastercamgonaleAún no hay calificaciones
- Cinemática y DinámicaDocumento11 páginasCinemática y DinámicaAldair Ü CalderónAún no hay calificaciones
- 10 Mart MAT Resuelven Operaciones de MultiplicacionDocumento3 páginas10 Mart MAT Resuelven Operaciones de MultiplicacionMatthew GlennAún no hay calificaciones
- P X Esuna Esfera de Radio7: 7. Considerar La Superficie Determinada Por La Ecuación + + 49. Se PideDocumento2 páginasP X Esuna Esfera de Radio7: 7. Considerar La Superficie Determinada Por La Ecuación + + 49. Se PideROYER MATTHEW BONIFACIO JULIANAún no hay calificaciones
- Ingeniería Económica AvancesDocumento6 páginasIngeniería Económica AvancesNeider SebastianAún no hay calificaciones
- Arcelormittal Norma Mexicana NMX B 457 Canacero 2013Documento21 páginasArcelormittal Norma Mexicana NMX B 457 Canacero 2013iso99Aún no hay calificaciones
- La Economía Del Virreinato Del Perú Bajo Los Habsburgo y La Denominada Crisis Del Siglo XviiDocumento23 páginasLa Economía Del Virreinato Del Perú Bajo Los Habsburgo y La Denominada Crisis Del Siglo Xviigdlo72Aún no hay calificaciones
- Informe 2 - Jose David y Eider GongoraDocumento14 páginasInforme 2 - Jose David y Eider GongoraJOSE DAVID HENAO DELGADOAún no hay calificaciones
- Tipos de Argumentos.19Documento16 páginasTipos de Argumentos.19Nathali TorresAún no hay calificaciones
- Ministerio Del Poder Popular para La Educación Municipio Escolar San Francisco I Liceo Nacional Eduardo Mathias Lossada San Francisco, Estado ZuliaDocumento7 páginasMinisterio Del Poder Popular para La Educación Municipio Escolar San Francisco I Liceo Nacional Eduardo Mathias Lossada San Francisco, Estado ZuliaSharon ArévaloAún no hay calificaciones
- MatemáticasDocumento18 páginasMatemáticasJacob ChavezAún no hay calificaciones
- Razonamiento Matemático - 3er Grado - Unidad 6 (SR)Documento4 páginasRazonamiento Matemático - 3er Grado - Unidad 6 (SR)GianinaToledoAún no hay calificaciones
- Sumador Restador y Sumador BCDDocumento10 páginasSumador Restador y Sumador BCDCarlosRodrigoGutierrezMamaniAún no hay calificaciones
- Metodologia de La Investigacion - Work Paper de La MateriaDocumento23 páginasMetodologia de La Investigacion - Work Paper de La MateriaAdhemar LedezmaAún no hay calificaciones
- Aplicaciones de Las Ecuaciones Diferenciales Ordinarias deDocumento15 páginasAplicaciones de Las Ecuaciones Diferenciales Ordinarias deDavid A GualpaAún no hay calificaciones
- Practica Dirigida Unidad 2-ProporcionesDocumento8 páginasPractica Dirigida Unidad 2-ProporcionesAngel Inconfundible Povis Ore100% (2)