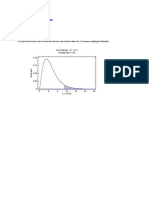
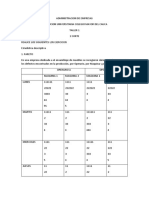
También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Estadística para veterinarios y zootecnistasDe EverandEstadística para veterinarios y zootecnistasCalificación: 5 de 5 estrellas5/5 (1)
- Tarea Bocos Unidad 4 ConceptosDocumento18 páginasTarea Bocos Unidad 4 ConceptosKevin A. ValleAún no hay calificaciones
- Estadistica InferencialDocumento9 páginasEstadistica Inferencialnicolai rondonAún no hay calificaciones
- TeoriaMuestreo PDFDocumento49 páginasTeoriaMuestreo PDFSebastian VillamizarAún no hay calificaciones
- Muestreo - Teoria y MetodologiaDocumento23 páginasMuestreo - Teoria y Metodologiacoldman10390Aún no hay calificaciones
- Conceptos 4ta UnidadDocumento32 páginasConceptos 4ta UnidadlariAún no hay calificaciones
- Criterios para La Selección de InvestigacionesDocumento3 páginasCriterios para La Selección de InvestigacionesJohan DeiAún no hay calificaciones
- Introducción A La Estadística InferencialDocumento31 páginasIntroducción A La Estadística InferencialRicardo Emmanuel Aldana DavilaAún no hay calificaciones
- Distribución de La Media MuestralDocumento14 páginasDistribución de La Media MuestralNicolas Pacheco OliveraAún no hay calificaciones
- Practica Final Estadistica IIDocumento5 páginasPractica Final Estadistica IIAngel LuisAún no hay calificaciones
- Secme 22659Documento111 páginasSecme 22659SkyblackPeruAún no hay calificaciones
- Muestreo Aleatorio Simple y EstratificadoDocumento54 páginasMuestreo Aleatorio Simple y Estratificadoeidan fuentesAún no hay calificaciones
- Etapas InvestigaciónDocumento4 páginasEtapas InvestigaciónMaribel RojasAún no hay calificaciones
- 1a Teoria Estadistica en La InvestigacionDocumento20 páginas1a Teoria Estadistica en La Investigacionjose luisAún no hay calificaciones
- Investigación de probabilidad y estadísticaDocumento78 páginasInvestigación de probabilidad y estadísticaJoaquin Fuentes SanchezAún no hay calificaciones
- Glosario Estadística EncuestasDocumento6 páginasGlosario Estadística EncuestasOlga Lucia Ramirez CameloAún no hay calificaciones
- 4 Act Tipos de MuestreoDocumento9 páginas4 Act Tipos de Muestreomonica mar cortesAún no hay calificaciones
- Secme-6833 1Documento90 páginasSecme-6833 1Elizabeth ZambranoAún no hay calificaciones
- Teoria Del MuestreoDocumento23 páginasTeoria Del Muestreocoldman10390Aún no hay calificaciones
- Ebook Modulo 2Documento20 páginasEbook Modulo 2Joel SuarezAún no hay calificaciones
- Introduccion AL Muestreo: Mg. Alejandro Jose AlcaideDocumento68 páginasIntroduccion AL Muestreo: Mg. Alejandro Jose Alcaidelelii.mamaniAún no hay calificaciones
- Tarea 7 Metodologia de La Invesyigacion IIDocumento7 páginasTarea 7 Metodologia de La Invesyigacion IIMiguel Henriquez100% (2)
- MétodosMuestreoDocumento27 páginasMétodosMuestreoAngel Eduardo Castillo Salinas33% (3)
- EstadísticaDocumento17 páginasEstadísticaEnzo VillarrealAún no hay calificaciones
- Módulo 2 - EADocumento60 páginasMódulo 2 - EADaniel Huachani CoripunaAún no hay calificaciones
- TAREA3PYEDocumento18 páginasTAREA3PYEHéctor Alexey EscobarAún no hay calificaciones
- Estadística Inferencial MuestreoDocumento13 páginasEstadística Inferencial Muestreoedgar sanchezAún no hay calificaciones
- Muestreo PDFDocumento38 páginasMuestreo PDFMiguel Angel Rozo ArangoAún no hay calificaciones
- Introducción al muestreo aleatorio y sus métodosDocumento2 páginasIntroducción al muestreo aleatorio y sus métodosWalt AguilarAún no hay calificaciones
- 6f. - Diapositivas de Estadistica y Probabilidades Introduccion Al MuestreoDocumento18 páginas6f. - Diapositivas de Estadistica y Probabilidades Introduccion Al MuestreoCristian aldairAún no hay calificaciones
- Tema IDocumento23 páginasTema IJose Luis Elizalde MorenoAún no hay calificaciones
- Estadisitca EnsayoDocumento13 páginasEstadisitca EnsayoPatico VelasquezAún no hay calificaciones
- Cuestionario MiércolesDocumento6 páginasCuestionario Miércolesjuan pablo zapata trujilloAún no hay calificaciones
- Muestreo, Correlacion, Regresion y Distribucion de ProbabilidadDocumento28 páginasMuestreo, Correlacion, Regresion y Distribucion de ProbabilidadCristina100% (1)
- Tema DDocumento11 páginasTema DAlba Huélamo IzquierdoAún no hay calificaciones
- Muest ReoDocumento43 páginasMuest ReoJazminPeñaAún no hay calificaciones
- La Epidemiología Analítica. ErrorDocumento7 páginasLa Epidemiología Analítica. ErrorGerman NuñezAún no hay calificaciones
- Metodo Clasico de La Estimacion PuntualDocumento10 páginasMetodo Clasico de La Estimacion PuntualwiliAún no hay calificaciones
- Lectura - Muestreo EstadisticoDocumento7 páginasLectura - Muestreo Estadisticoccasas80Aún no hay calificaciones
- Investigacion de Teoria de Decisiones MuestreoDocumento12 páginasInvestigacion de Teoria de Decisiones MuestreoAJ Rivera100% (1)
- Seleccion de La Muestra (Practica)Documento5 páginasSeleccion de La Muestra (Practica)Monse SotoAún no hay calificaciones
- Población y Muestra Presentacion Power PointDocumento22 páginasPoblación y Muestra Presentacion Power PointGabii SotoAún no hay calificaciones
- Cuestionario #5 - Maestria - Parte 2Documento5 páginasCuestionario #5 - Maestria - Parte 2ArmandoAvalosAún no hay calificaciones
- Estadistica para Administradores PDFDocumento8 páginasEstadistica para Administradores PDFMorales RebecaAún no hay calificaciones
- Teoria Del MuestreoDocumento22 páginasTeoria Del MuestreoJulio UmerezAún no hay calificaciones
- Trabajo Colaborativo No 1 Inferencia EstadisticaDocumento16 páginasTrabajo Colaborativo No 1 Inferencia EstadisticaJuan Carlos Restrepo SalcedoAún no hay calificaciones
- CUESTIONARIODocumento9 páginasCUESTIONARIONat TAún no hay calificaciones
- Teoria Basica Del Muestreo y La PrevalenciaDocumento27 páginasTeoria Basica Del Muestreo y La PrevalenciaeulerruizAún no hay calificaciones
- Técnicas de Muestreo EstadísticoDocumento5 páginasTécnicas de Muestreo EstadísticoRoyer Casaverde DiazAún no hay calificaciones
- PREIMERA ACTIVIDAD ConsultaDocumento11 páginasPREIMERA ACTIVIDAD ConsultaLILIANA A. RESTREPOAún no hay calificaciones
- Presentacion BioestadisticaDocumento14 páginasPresentacion BioestadisticaJhonatan Chugnas ChuquilinAún no hay calificaciones
- Parámetro EstadísticoDocumento7 páginasParámetro EstadísticoGleydis RodriguezAún no hay calificaciones
- Anexo - Guía Conceptos de Muestreo e Inferencia EstadísticaDocumento11 páginasAnexo - Guía Conceptos de Muestreo e Inferencia Estadísticayassy castillo0% (1)
- Acerca Del MuestreoDocumento4 páginasAcerca Del Muestreonoemi.arango.09Aún no hay calificaciones
- Trabajo de Muestreo EstadísticoDocumento11 páginasTrabajo de Muestreo EstadísticoValeria SalvatierraAún no hay calificaciones
- Exposición 2 - Datos y Rol Del EspacioDocumento49 páginasExposición 2 - Datos y Rol Del EspacioMichelAún no hay calificaciones
- Muestreo Aplicado A La AuditoriaDocumento17 páginasMuestreo Aplicado A La AuditoriaLiliana Karen BQAún no hay calificaciones
- Estadística muestreoDocumento5 páginasEstadística muestreoAlex ScoffyAún no hay calificaciones
- ACTIVIDAD 2 (Ensayo)Documento3 páginasACTIVIDAD 2 (Ensayo)Jacqueline García HernándezAún no hay calificaciones
- Proceso de Almacenamiento Del Documento.Documento1 páginaProceso de Almacenamiento Del Documento.pauleth canAún no hay calificaciones
- Investigacion de MercadoDocumento2 páginasInvestigacion de Mercadopauleth canAún no hay calificaciones
- Conceptos de La Unidad 5 SAULDocumento16 páginasConceptos de La Unidad 5 SAULpauleth canAún no hay calificaciones
- Inciso 3 Proyecto 3Documento3 páginasInciso 3 Proyecto 3pauleth canAún no hay calificaciones
- Ejercicios de PrácticaDocumento24 páginasEjercicios de Prácticapauleth canAún no hay calificaciones
- Proyecto 1 - Estadistica DescriptivaDocumento9 páginasProyecto 1 - Estadistica Descriptivaangel herrera50% (2)
- Tareas de La Unidad 1Documento11 páginasTareas de La Unidad 1pauleth canAún no hay calificaciones
- Unidad 3 TareasDocumento9 páginasUnidad 3 Tareaspauleth canAún no hay calificaciones
- Chi Cuadrada A)Documento1 páginaChi Cuadrada A)pauleth canAún no hay calificaciones
- Regresión lineal simple y correlación en estadísticaDocumento7 páginasRegresión lineal simple y correlación en estadísticapauleth canAún no hay calificaciones
- AlondraDocumento2 páginasAlondrapauleth canAún no hay calificaciones
- Unidad ConceptosDocumento14 páginasUnidad Conceptospauleth canAún no hay calificaciones
- Unidad 3 Tarea 3Documento3 páginasUnidad 3 Tarea 3pauleth canAún no hay calificaciones
- Proyecto Unidad 3Documento3 páginasProyecto Unidad 3pauleth canAún no hay calificaciones
- Temario U.4 Prob. y Estadística MS-2Documento5 páginasTemario U.4 Prob. y Estadística MS-2pauleth canAún no hay calificaciones
- Mapa ConceptualDocumento1 páginaMapa Conceptualpauleth canAún no hay calificaciones
- Unidad ConceptosDocumento14 páginasUnidad Conceptospauleth canAún no hay calificaciones
- Fotos de Las Tarea de La Unidad 3 y 4 de Probabilidad y EstadisticaDocumento14 páginasFotos de Las Tarea de La Unidad 3 y 4 de Probabilidad y Estadisticapauleth canAún no hay calificaciones
- La Prueba de HipótesisDocumento7 páginasLa Prueba de Hipótesispauleth canAún no hay calificaciones
- TabulaciónDocumento2 páginasTabulaciónpauleth canAún no hay calificaciones
- Conceptos de La Unidad 5 SAULDocumento20 páginasConceptos de La Unidad 5 SAULpauleth canAún no hay calificaciones
- El Analisis de CorrelacionDocumento5 páginasEl Analisis de Correlacionpauleth canAún no hay calificaciones
- Conceptos Unidad 3Documento18 páginasConceptos Unidad 3pauleth canAún no hay calificaciones
- Proyecto 6Documento9 páginasProyecto 6pauleth canAún no hay calificaciones
- Proyecto de Probabilidad y EstadisticaDocumento5 páginasProyecto de Probabilidad y Estadisticapauleth canAún no hay calificaciones
- Regresión lineal y correlación en variables de estudiantesDocumento4 páginasRegresión lineal y correlación en variables de estudiantespauleth canAún no hay calificaciones
- Eval. Formativa 1.1 2016 - 2Documento1 páginaEval. Formativa 1.1 2016 - 2pauleth canAún no hay calificaciones
- Conceptos Unidad 1Documento21 páginasConceptos Unidad 1pauleth canAún no hay calificaciones
- Gráficas de distribución de probabilidadDocumento9 páginasGráficas de distribución de probabilidadpauleth canAún no hay calificaciones
- 1er - Intento-Evaluacion Final - Escenario 8 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO7)Documento7 páginas1er - Intento-Evaluacion Final - Escenario 8 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO7)Mary SánchezAún no hay calificaciones
- Diseño de BloquesDocumento6 páginasDiseño de BloquesSergio CuetoAún no hay calificaciones
- Capitulo 2Documento28 páginasCapitulo 2Enrique TAún no hay calificaciones
- Pruebas de HipotesisDocumento8 páginasPruebas de HipotesisdahianAún no hay calificaciones
- Examen parcial - Semana 4: Estadística IIDocumento9 páginasExamen parcial - Semana 4: Estadística IIYesid CotrinaAún no hay calificaciones
- Taller de Estadistica 4Documento10 páginasTaller de Estadistica 4maria fernanda luna gomezAún no hay calificaciones
- Administracion de EstadisticaDocumento3 páginasAdministracion de EstadisticaNICOLE CASTILLOAún no hay calificaciones
- Regresión lineal asfalteno-resinaDocumento11 páginasRegresión lineal asfalteno-resinamanuAún no hay calificaciones
- Trabajo Estadistica Actividad 2 FinalDocumento23 páginasTrabajo Estadistica Actividad 2 FinalLorena Triana QuinteroAún no hay calificaciones
- Actividad 4 - Fundamentos de InvestigaciónDocumento6 páginasActividad 4 - Fundamentos de InvestigaciónMercedes Meneses Meneses91% (11)
- Prueba de HipótesisDocumento32 páginasPrueba de HipótesisDamián Hdez100% (1)
- Análisis KPI horas búsqueda información ChamiloDocumento5 páginasAnálisis KPI horas búsqueda información ChamiloJose Luis PgAún no hay calificaciones
- Ficha Informativa - Matemática IV - 7 SemanaDocumento5 páginasFicha Informativa - Matemática IV - 7 SemanaAna PerezAún no hay calificaciones
- Prueba de Hipotesis - ANOVADocumento138 páginasPrueba de Hipotesis - ANOVAfrancojahAún no hay calificaciones
- Estadistica - Sem 10 - Medidas de Tendencia Central IIDocumento11 páginasEstadistica - Sem 10 - Medidas de Tendencia Central IIlizeth çAún no hay calificaciones
- Control ProtocolosDocumento783 páginasControl ProtocolosPablocumillafAún no hay calificaciones
- Prueba de Shapiro Will y KolmovorowDocumento4 páginasPrueba de Shapiro Will y KolmovorowDiana Trujillo Amado100% (1)
- Trabajo Estadistica 1Documento8 páginasTrabajo Estadistica 1DIEGO GARCIAAún no hay calificaciones
- Laboratorio N°1Documento15 páginasLaboratorio N°1Marlon SepúlvedaAún no hay calificaciones
- Intervalo de Confianza para La Diferencia de Dos ProporcionesDocumento13 páginasIntervalo de Confianza para La Diferencia de Dos ProporcionesDunia Liz LaquidamianAún no hay calificaciones
- Taller Estadistica Colmayor 2017Documento7 páginasTaller Estadistica Colmayor 2017Leydy MoralesAún no hay calificaciones
- WORD Estadistica TallerDocumento5 páginasWORD Estadistica Tallerstefany riveraAún no hay calificaciones
- EstadisticaDocumento4 páginasEstadisticaOscar IzquierdoAún no hay calificaciones
- 4.5 La Importancia de La Aleatorizacion de PruebaDocumento1 página4.5 La Importancia de La Aleatorizacion de PruebaDavid Beltran Hernandez100% (1)
- Esp U3 Ea MiasDocumento8 páginasEsp U3 Ea MiasMicheel AlcoparAún no hay calificaciones
- 15° Sesion de AprendizajeDocumento13 páginas15° Sesion de AprendizajeJoseling Calderon MayorcaAún no hay calificaciones
- Estimación e intervalos de confianza en muestras aleatoriasDocumento5 páginasEstimación e intervalos de confianza en muestras aleatoriasMirianAún no hay calificaciones
- Ejercicios Diseño-Alonzo-PadillaDocumento13 páginasEjercicios Diseño-Alonzo-Padillaisabel m gomero100% (1)
- 119 111 Valvuladebolade12 7mmACC VAL 001 ConsultoraCostarricenseparaProgramasdeDesarrolloS.a FirmadoDocumento3 páginas119 111 Valvuladebolade12 7mmACC VAL 001 ConsultoraCostarricenseparaProgramasdeDesarrolloS.a FirmadoJohan ChavesAún no hay calificaciones