También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Razonamiento cuantitativo, 2ª edición: Notas de claseDe EverandRazonamiento cuantitativo, 2ª edición: Notas de claseCalificación: 5 de 5 estrellas5/5 (1)
- Entrenamiento Deportivo PDFDocumento37 páginasEntrenamiento Deportivo PDFMartin Fabián100% (1)
- Fichas Juegos PredeportivosDocumento7 páginasFichas Juegos PredeportivosAlvaro Yanquin MoralesAún no hay calificaciones
- Plantilla Elaboracio N Rutinas de EntrenamientoDocumento1 páginaPlantilla Elaboracio N Rutinas de EntrenamientoMartin FabiánAún no hay calificaciones
- Criterios de Evaluación Estadística DescriptivaDocumento8 páginasCriterios de Evaluación Estadística Descriptivarocio lizbeth RoblesAún no hay calificaciones
- Clase2 Repaso de EstadísticaDocumento41 páginasClase2 Repaso de EstadísticaMaria BotasAún no hay calificaciones
- Análisis Exploratorio de DatosDocumento22 páginasAnálisis Exploratorio de Datosrocio lizbeth RoblesAún no hay calificaciones
- Análisis de Datos DescriptivosDocumento13 páginasAnálisis de Datos DescriptivosJERRY ESTEVEN FIGUEROA SANDOVALAún no hay calificaciones
- Guía BioestadisticaDocumento6 páginasGuía BioestadisticaChris MorenoAún no hay calificaciones
- Tema 1Documento3 páginasTema 1100523954Aún no hay calificaciones
- Unidad 1Documento32 páginasUnidad 1Felipe de Jesús Sosa HerreraAún no hay calificaciones
- Wuolah Free Tema 3Documento32 páginasWuolah Free Tema 3LuciaAún no hay calificaciones
- 01 Tutoria 1 - TEMA 1 - Conceptos Basicos y Organizacion de DatosDocumento15 páginas01 Tutoria 1 - TEMA 1 - Conceptos Basicos y Organizacion de DatosKarina MontenegroAún no hay calificaciones
- Introduccion Geoestadistica UnambaDocumento41 páginasIntroduccion Geoestadistica UnambaOswald TorresAún no hay calificaciones
- Taller de EstadisticaDocumento11 páginasTaller de EstadisticaJh JjAún no hay calificaciones
- Resumen EstadsticaDocumento26 páginasResumen EstadsticaJosé Mijael Acosta CastroAún no hay calificaciones
- Resume NDocumento4 páginasResume NCristian DíazAún no hay calificaciones
- Unidad 1 - Clase 1.4Documento32 páginasUnidad 1 - Clase 1.4ntrey8Aún no hay calificaciones
- Estadística para Ciencia de DatosDocumento22 páginasEstadística para Ciencia de DatosOsvaldo Soruco100% (1)
- Act. 5 - Exposición - GII - Los AcoplaosDocumento23 páginasAct. 5 - Exposición - GII - Los AcoplaosLaopa otrocasAún no hay calificaciones
- Estadística (220137-2016-2) Estadística DescriptivaDocumento65 páginasEstadística (220137-2016-2) Estadística DescriptivaAdolfo Javier Carvallo ZentenoAún no hay calificaciones
- Estadística DescriptivaDocumento17 páginasEstadística Descriptivafrozt chAún no hay calificaciones
- Estadística RESUMENDocumento62 páginasEstadística RESUMENDenisse AguirreAún no hay calificaciones
- PROBASBILIDAD Y ESTADÍSTICA 1er ParcialDocumento50 páginasPROBASBILIDAD Y ESTADÍSTICA 1er ParcialYatniel BustamanteAún no hay calificaciones
- Tarea 1-PROB - 2006845Documento16 páginasTarea 1-PROB - 2006845Sergio MedellinAún no hay calificaciones
- De Qué Trata La EstadísticaDocumento88 páginasDe Qué Trata La EstadísticaMauricio AngelAún no hay calificaciones
- Análisis de Datos No AgrupadosDocumento38 páginasAnálisis de Datos No Agrupadosssolano4eAún no hay calificaciones
- TEMA 2 Herramientas de Tendencia CentralDocumento14 páginasTEMA 2 Herramientas de Tendencia CentralanahiescobaralanocaAún no hay calificaciones
- Introduccion Al Analisis de DatosDocumento29 páginasIntroduccion Al Analisis de DatosRocío MnAún no hay calificaciones
- Histograma y Distribuciones Empiricas ExposicionDocumento17 páginasHistograma y Distribuciones Empiricas ExposicionJose J. Zeballos MoyaAún no hay calificaciones
- Resumen 1° Parcial de EstadisticaDocumento10 páginasResumen 1° Parcial de EstadisticaDy guarnieriAún no hay calificaciones
- Semana 2 2023 ESTADISTICADocumento33 páginasSemana 2 2023 ESTADISTICAMarsAún no hay calificaciones
- Tema 1 - EstadísticaDocumento12 páginasTema 1 - EstadísticaLuciiaaruiizzAún no hay calificaciones
- Conceptos Básicos EstadísticaDocumento40 páginasConceptos Básicos Estadísticaadrianamargarita0007.amooAún no hay calificaciones
- Distribución de FrecuenciaDocumento4 páginasDistribución de FrecuenciaMichel DelvalleAún no hay calificaciones
- Estadisticas Equipo 2Documento16 páginasEstadisticas Equipo 2momklji iokomAún no hay calificaciones
- Análisis Estadistico de Datos PDFDocumento84 páginasAnálisis Estadistico de Datos PDFDiiäNä BêZzêrräAún no hay calificaciones
- Definiciones de EsctadisticaDocumento5 páginasDefiniciones de Esctadisticajulian natahael M.LAún no hay calificaciones
- Definiciones de Esctadistica PDFDocumento5 páginasDefiniciones de Esctadistica PDFjulian natahael M.LAún no hay calificaciones
- Estadisticas Equipo 2Documento16 páginasEstadisticas Equipo 2zitlali zitlalaAún no hay calificaciones
- Estadística Media Mediana ModaDocumento30 páginasEstadística Media Mediana ModaJCarlosAún no hay calificaciones
- Modelos GraficosDocumento23 páginasModelos GraficosfrandyAún no hay calificaciones
- Estadistica PracticoDocumento6 páginasEstadistica PracticoVan NanaAún no hay calificaciones
- Asimetria Positiva y NegativaDocumento51 páginasAsimetria Positiva y Negativalaflaca_ifigeniaAún no hay calificaciones
- Estadística I - TeoríaDocumento20 páginasEstadística I - TeoríagalaAún no hay calificaciones
- 1 - Panorama General y Estadística DescriptivaDocumento4 páginas1 - Panorama General y Estadística DescriptivaAlex SeguraAún no hay calificaciones
- Estadística DescriptivaDocumento23 páginasEstadística DescriptivaImelda BarrazaAún no hay calificaciones
- Estadistica Unidad Iii y IvDocumento83 páginasEstadistica Unidad Iii y IvPaola Gutierrez ChavesAún no hay calificaciones
- Sesión 1 Estadística Aplicada 2022 PDFDocumento30 páginasSesión 1 Estadística Aplicada 2022 PDFParras Pizza Club.Aún no hay calificaciones
- Estadistica Descriptiva ElementalDocumento3 páginasEstadistica Descriptiva ElementalRonald JiménezAún no hay calificaciones
- Resumen 1Documento10 páginasResumen 1Ariel CamposAún no hay calificaciones
- Tema 1A Estadística Descriptiva Univariante-1Documento22 páginasTema 1A Estadística Descriptiva Univariante-1bryggyttAún no hay calificaciones
- Clase de Estadistica Descriptiva Ing Electrica 2020 - 1Documento27 páginasClase de Estadistica Descriptiva Ing Electrica 2020 - 1bryan guiza ojedaAún no hay calificaciones
- Tema 2 EstadísticaDocumento10 páginasTema 2 EstadísticaLucia AlmaguerAún no hay calificaciones
- Trabajo Estadistica Unidad 1 Fase 2Documento11 páginasTrabajo Estadistica Unidad 1 Fase 2Angelina GamboaAún no hay calificaciones
- Taller EstadisticaDocumento7 páginasTaller EstadisticaJefferson MontañoAún no hay calificaciones
- ESTADISTICA ResumenDocumento15 páginasESTADISTICA ResumenmilagrosgoparnutriAún no hay calificaciones
- Estadística I Unidad 1 ResumenDocumento5 páginasEstadística I Unidad 1 ResumenmfrancoaquinoAún no hay calificaciones
- Tema 1Documento8 páginasTema 1Sergio Navarro GarcíaAún no hay calificaciones
- Histograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraDe EverandHistograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraAún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- MOOC2 - Ch1 - SpanishDocumento44 páginasMOOC2 - Ch1 - SpanishMartin FabiánAún no hay calificaciones
- Comienza Tu Viaje Por La Nueva Medicina Germanica PDFDocumento94 páginasComienza Tu Viaje Por La Nueva Medicina Germanica PDFSERGIO alarcon88% (8)
- MOOC3 - Ch1 - SpanishDocumento50 páginasMOOC3 - Ch1 - SpanishMartin FabiánAún no hay calificaciones
- Coaches Toolkit - Spanish - Play Well - OptimisedDocumento4 páginasCoaches Toolkit - Spanish - Play Well - OptimisedMartin FabiánAún no hay calificaciones
- Silo - Tips - Rugby Infantil Temporada 2010Documento39 páginasSilo - Tips - Rugby Infantil Temporada 2010Martin FabiánAún no hay calificaciones
- SCHLEIP Mecanotransducción TRADUCIDODocumento7 páginasSCHLEIP Mecanotransducción TRADUCIDOMartin FabiánAún no hay calificaciones
- Cart A Consent I Mien To Inform A DoDocumento1 páginaCart A Consent I Mien To Inform A DoMartin FabiánAún no hay calificaciones
- Actividad Fisica y Salud Integral - Medina JimenezDocumento252 páginasActividad Fisica y Salud Integral - Medina JimenezMartin FabiánAún no hay calificaciones
- Reglamento Nacional de Rugby Infantil 2020 PDFDocumento25 páginasReglamento Nacional de Rugby Infantil 2020 PDFsebas xdAún no hay calificaciones
- Vidaferia 20-11-21Documento5 páginasVidaferia 20-11-21Martin FabiánAún no hay calificaciones
- ReportDocumento1 páginaReportMartin FabiánAún no hay calificaciones
- Agenda Del Coach (Rugby)Documento20 páginasAgenda Del Coach (Rugby)Marcos BeltramellaAún no hay calificaciones
- Las Actividades de Lucha en Las Clases de EFDocumento35 páginasLas Actividades de Lucha en Las Clases de EFRoberto Carlos TiptonAún no hay calificaciones
- PDF - Translator PRUEBA ESPECIFICA BJJ PDFDocumento7 páginasPDF - Translator PRUEBA ESPECIFICA BJJ PDFMartin FabiánAún no hay calificaciones
- Dialnet SistemaFascial 6985068 PDFDocumento12 páginasDialnet SistemaFascial 6985068 PDFAmérica Marianela Vargas SalvatierraAún no hay calificaciones
- Efecto 20retardado 20de 20entrenamiento 20pliometriaDocumento9 páginasEfecto 20retardado 20de 20entrenamiento 20pliometriaMartin FabiánAún no hay calificaciones
- Las Actividades de Lucha en Las Clases de EFDocumento35 páginasLas Actividades de Lucha en Las Clases de EFRoberto Carlos TiptonAún no hay calificaciones
- Evaluacion de La Fuerza 2 PDFDocumento4 páginasEvaluacion de La Fuerza 2 PDFMartin FabiánAún no hay calificaciones
- 4 - Anexo BDocumento18 páginas4 - Anexo BMartin FabiánAún no hay calificaciones
- Tabla de AlimentosDocumento8 páginasTabla de AlimentosSilviaSanchezAriasAún no hay calificaciones
- Desarrollo de Fuerza en Boxeo PDFDocumento45 páginasDesarrollo de Fuerza en Boxeo PDFMartin FabiánAún no hay calificaciones
- BlogFE 2019 Reducido PDFDocumento224 páginasBlogFE 2019 Reducido PDFMartin FabiánAún no hay calificaciones
- Actualizaciones Fisiología Del Ejercicio 2019 PDFDocumento233 páginasActualizaciones Fisiología Del Ejercicio 2019 PDFJuan Andres Guzman WongAún no hay calificaciones
- BlogFE 2019 Reducido PDFDocumento224 páginasBlogFE 2019 Reducido PDFMartin FabiánAún no hay calificaciones
- Fche MFC 1045 PDFDocumento206 páginasFche MFC 1045 PDFMartin FabiánAún no hay calificaciones
- Anlisis de La Fuerza y La Potencia en Di20160404-12610-1h0kuvn PDFDocumento373 páginasAnlisis de La Fuerza y La Potencia en Di20160404-12610-1h0kuvn PDFLUIS ANTONIO GAVIRIA100% (1)
- Mapa de Progreso Educación MatematicaDocumento33 páginasMapa de Progreso Educación MatematicaDaniel Arenas AlmendaresAún no hay calificaciones
- CTE08 Actividad PreviaDocumento5 páginasCTE08 Actividad PreviaMaestra CynthiaAún no hay calificaciones
- Lab3 Algoritmia 2020BDocumento4 páginasLab3 Algoritmia 2020BGabriel ArangoAún no hay calificaciones
- AMP Modulo 4 Clase2Documento30 páginasAMP Modulo 4 Clase2Naty SanabriaAún no hay calificaciones
- Tarea 5 Propiedades de Los Determinante MegaDocumento3 páginasTarea 5 Propiedades de Los Determinante MegaCarlos ValleAún no hay calificaciones
- Tema 1Documento11 páginasTema 1Angelo Gustavo Donayre LozaAún no hay calificaciones
- Clase 11 - Interpretación de PBUDocumento25 páginasClase 11 - Interpretación de PBUCosm FulaneAún no hay calificaciones
- Logica Matiematica Tarea Virtual 6Documento3 páginasLogica Matiematica Tarea Virtual 6Tutos y Algo más LibraryAún no hay calificaciones
- Normal 5d07a49ef1dffDocumento28 páginasNormal 5d07a49ef1dffFandom Boice BarranquillaAún no hay calificaciones
- ExamenesDocumento13 páginasExameneselex_merinoAún no hay calificaciones
- Lenguaje Algebraico ResueltoDocumento3 páginasLenguaje Algebraico ResueltoNICOL TELLEZAún no hay calificaciones
- Propiedades Algebraicas de Los Números RealesDocumento11 páginasPropiedades Algebraicas de Los Números Realesleopoldonachvin100% (3)
- 3 Transformada de LaplaceDocumento20 páginas3 Transformada de LaplacejhonAún no hay calificaciones
- Final 5 Digitales 1Documento19 páginasFinal 5 Digitales 1Victor Manuel CanahuiriAún no hay calificaciones
- Calculo Vectorial...Documento4 páginasCalculo Vectorial...Misael Yam CanulAún no hay calificaciones
- Matematicas para Economistas Capitulo 6Documento23 páginasMatematicas para Economistas Capitulo 6Alvaro ChevalierAún no hay calificaciones
- Planificacion Mat 1ro 2019Documento8 páginasPlanificacion Mat 1ro 2019Julián Rodolfo Pérez KnulstAún no hay calificaciones
- Curtosis y Asimetria-HernándezDocumento43 páginasCurtosis y Asimetria-HernándezJaret LopezAún no hay calificaciones
- Holokinesis y Su Formulacion Matematica 1Documento12 páginasHolokinesis y Su Formulacion Matematica 1ivanAún no hay calificaciones
- Los Numeros ComplejosDocumento13 páginasLos Numeros ComplejosDeivis PerezAún no hay calificaciones
- Angulo SDocumento12 páginasAngulo SMáran Champi ApazaAún no hay calificaciones
- Multiplicación Por Dos y Tres CifrasDocumento9 páginasMultiplicación Por Dos y Tres CifrasReynaBurgosRocioAún no hay calificaciones
- Actividad de Puntos Evaluables - Escenario 6 - PRIMER BLOQUE-CIENCIAS BASICAS - VIRTUAL - MÉTODOS NUMÉRICOS - (GRUPO B01) 2Documento7 páginasActividad de Puntos Evaluables - Escenario 6 - PRIMER BLOQUE-CIENCIAS BASICAS - VIRTUAL - MÉTODOS NUMÉRICOS - (GRUPO B01) 2Carlos Yesid Ascencio CelyAún no hay calificaciones
- Fa014 - Plan de Clase Grado 10º..Documento11 páginasFa014 - Plan de Clase Grado 10º..davids_94_08100% (4)
- MatemáticasDocumento6 páginasMatemáticasMiriis AngllsAún no hay calificaciones
- 203057A - G761 - Tarea 4 PDFDocumento45 páginas203057A - G761 - Tarea 4 PDFluz yaneth taborda restrepoAún no hay calificaciones
- LA PC COMO MEDIO DE APRENDIZAJEArcavi (2000)Documento21 páginasLA PC COMO MEDIO DE APRENDIZAJEArcavi (2000)Francisco GurrolaAún no hay calificaciones
- Prueba Matemática NT2Documento10 páginasPrueba Matemática NT2Nicole ZapataAún no hay calificaciones
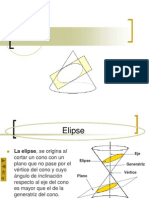
- ElipseDocumento18 páginasElipseLomas Raquelita LomasAún no hay calificaciones
- S09 - Fracciones - Aritm5° - 2022Documento10 páginasS09 - Fracciones - Aritm5° - 2022Rosslady PizarroAún no hay calificaciones