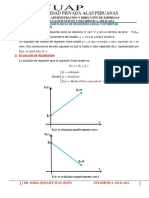
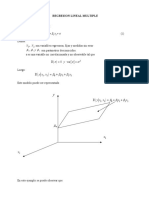
También podría gustarte
- Persige Tu LeonDocumento6 páginasPersige Tu LeonFabian100% (2)
- Regresion Lineal y Cuadratica MEDocumento10 páginasRegresion Lineal y Cuadratica MEYuri Llamocca BeltranAún no hay calificaciones
- Infancia y DDHH Liebel Martinez PDFDocumento484 páginasInfancia y DDHH Liebel Martinez PDFOrganización A La Ofensiva100% (1)
- Regresión Lineal Simple y MultipleDocumento26 páginasRegresión Lineal Simple y Multiplecristopher leon marceloAún no hay calificaciones
- Demostraciones Econometria PDFDocumento43 páginasDemostraciones Econometria PDFAlexisHernánGutierrezAún no hay calificaciones
- Guia de Obras Edf Ciudad Univ. de CaracasDocumento38 páginasGuia de Obras Edf Ciudad Univ. de Caracashm100Aún no hay calificaciones
- 3.-Teoria - Analisis de Regresion Lineal y MultipleDocumento37 páginas3.-Teoria - Analisis de Regresion Lineal y MultipleLuis MinayaAún no hay calificaciones
- Construccion de Graficas y Ecuaciones EmpiricasDocumento4 páginasConstruccion de Graficas y Ecuaciones EmpiricasWill LunaAún no hay calificaciones
- Reresion Lineal Multiple MDDocumento12 páginasReresion Lineal Multiple MDNelyda Ayde CondoriAún no hay calificaciones
- Guia 4 Regresion LinealDocumento7 páginasGuia 4 Regresion LinealGioman100% (2)
- AnÁlisis de RegresiÓn y de CorrelaciÓnDocumento13 páginasAnÁlisis de RegresiÓn y de CorrelaciÓnapi-3697274100% (7)
- Guia de Fisica I2020Documento30 páginasGuia de Fisica I2020Rodrigo Montenegro SolisAún no hay calificaciones
- Informe de LaboratorioDocumento5 páginasInforme de LaboratorioRodner Gutierrez SanchezAún no hay calificaciones
- Teoria Unidad 6 - RegresionDocumento18 páginasTeoria Unidad 6 - RegresionCarolina EspecheAún no hay calificaciones
- Análisis de VolátilesDocumento52 páginasAnálisis de VolátilesJosimar PasquelAún no hay calificaciones
- Regresion y CorrelacionDocumento52 páginasRegresion y CorrelacionAnonymous 8GWv4y0qjEAún no hay calificaciones
- Regresion Lineal Simple Usach 2017 286647Documento7 páginasRegresion Lineal Simple Usach 2017 286647Rodolfo Abel Hidalgo AriasAún no hay calificaciones
- Semana 14 S1 AQPDocumento7 páginasSemana 14 S1 AQPDiana GuillenAún no hay calificaciones
- 2022 Regresion y Correlacion LinealDocumento34 páginas2022 Regresion y Correlacion LinealFernanda AyonAún no hay calificaciones
- Regresion LinealDocumento26 páginasRegresion LinealSantiago Arbelaez GuzmánAún no hay calificaciones
- Regresion Lineal SimpleDocumento57 páginasRegresion Lineal SimpleChickita BastidasAún no hay calificaciones
- Apunte 2.0 Datos Bivariados 20210406 MartesDocumento5 páginasApunte 2.0 Datos Bivariados 20210406 MartesCaliope TaliaAún no hay calificaciones
- Regresión Lineal y Métodos No ParametricosDocumento50 páginasRegresión Lineal y Métodos No ParametricosKarolay Trillos BallesterosAún no hay calificaciones
- Modelos de Regresión Lineal-Variables Ficticias - 1Documento36 páginasModelos de Regresión Lineal-Variables Ficticias - 1David BobadillaAún no hay calificaciones
- Regresion BIVARIADADocumento9 páginasRegresion BIVARIADAValentinaAún no hay calificaciones
- Examen 3 de Métodos Numéricos 14 JunioDocumento22 páginasExamen 3 de Métodos Numéricos 14 JunioJuan Jesus Soria QuijaiteAún no hay calificaciones
- Regresión Múltiple MatricialDocumento24 páginasRegresión Múltiple MatricialReinaldo PaxiAún no hay calificaciones
- 2da Practica FISICA I UAC 2024-IDocumento7 páginas2da Practica FISICA I UAC 2024-IMatias LisarazoAún no hay calificaciones
- Regre Lineal2015 Clase PDFDocumento16 páginasRegre Lineal2015 Clase PDFJonathan MartinezAún no hay calificaciones
- Regresion Lineal Simple FinalDocumento18 páginasRegresion Lineal Simple FinalMiguel MontealegreAún no hay calificaciones
- Tema 7 - Correlación y Regresión LinealDocumento39 páginasTema 7 - Correlación y Regresión LinealManuelAún no hay calificaciones
- 5 Ajuste PDFDocumento33 páginas5 Ajuste PDFCESAR MIERAún no hay calificaciones
- Lección 2 Modelo de Regresion MultipleDocumento48 páginasLección 2 Modelo de Regresion Multiple- Daniel Von Zedlitz -Aún no hay calificaciones
- S15.análisis Regresión Lineal MúltipleDocumento57 páginasS15.análisis Regresión Lineal MúltipleFABRIZIO JUNIOR BAUTISTA JIMENEZAún no hay calificaciones
- 1.1 Regresion Lineal TeoriaDocumento9 páginas1.1 Regresion Lineal TeoriaPedroza Mendiola K exul YumtsilAún no hay calificaciones
- DiapositivasRegresión (Samuel2012)Documento40 páginasDiapositivasRegresión (Samuel2012)SktSlayerAún no hay calificaciones
- P1. Tratamiento Estadístico de DatosDocumento13 páginasP1. Tratamiento Estadístico de DatosAdlin MachacaAún no hay calificaciones
- Regresion Multiple-Estimación 2022 1Documento12 páginasRegresion Multiple-Estimación 2022 1Dannis Omar Campos ZavaletaAún no hay calificaciones
- Laboratorio #1-Teoria de ErroresDocumento5 páginasLaboratorio #1-Teoria de ErroresJOSSIMAR JORDANO BACA CONDORIAún no hay calificaciones
- Estadística NotasDocumento23 páginasEstadística NotasDavid EspinozaAún no hay calificaciones
- Tarea Reg PDFDocumento5 páginasTarea Reg PDFJorge PontonAún no hay calificaciones
- Gráfica y Regresión de CurvasDocumento5 páginasGráfica y Regresión de CurvasALDAIR QUISPE AGUILARAún no hay calificaciones
- Tema 3Documento22 páginasTema 3Marc Pastor PouAún no hay calificaciones
- Ayudantía N°1 (Segundo Semestre 2014)Documento7 páginasAyudantía N°1 (Segundo Semestre 2014)David AhumadaAún no hay calificaciones
- Tipo Ejercicios DesarrolloDocumento62 páginasTipo Ejercicios DesarrolloAlberto PozuramaAún no hay calificaciones
- Regresión Lineal SimpleDocumento31 páginasRegresión Lineal SimpleYasely Lecca AvilaAún no hay calificaciones
- Estadistica Descriptiva y Probabilidades-470Documento1 páginaEstadistica Descriptiva y Probabilidades-470hernan ccorimanya sopantaAún no hay calificaciones
- Estadística I: Tema 10 / Parte 2 Análisis de Regresión LinealDocumento5 páginasEstadística I: Tema 10 / Parte 2 Análisis de Regresión LinealJuan Carlos Chavez MoranAún no hay calificaciones
- Ejemplo Regresión Lineal Simple y MultipleDocumento19 páginasEjemplo Regresión Lineal Simple y MultipleJavier UcanAún no hay calificaciones
- 3.2 Diagrama de Dispersión.Documento21 páginas3.2 Diagrama de Dispersión.Karen Itzel RomeroAún no hay calificaciones
- Parcial 5N SRDocumento1 páginaParcial 5N SRNicolas RonderosAún no hay calificaciones
- Regres y CorrelDocumento13 páginasRegres y CorrelthaisAún no hay calificaciones
- Regresión Lineal SimpleDocumento28 páginasRegresión Lineal SimpleAzul Geronimo RojasAún no hay calificaciones
- Correlacion y Regresion Multiple 01 S15Documento32 páginasCorrelacion y Regresion Multiple 01 S15DIANA CAMILA FERNANDEZ MEDINAAún no hay calificaciones
- Ejercicios Soluciones Original MasterDocumento95 páginasEjercicios Soluciones Original Masteraurelio.fdezAún no hay calificaciones
- S1 - Apunte 2 - EconomnetríaDocumento9 páginasS1 - Apunte 2 - EconomnetríacRISTIANAún no hay calificaciones
- Clase3 Reg SimpleDocumento40 páginasClase3 Reg SimpleDiego Torres QuintrileoAún no hay calificaciones
- Regresion MultipleDocumento7 páginasRegresion Multiplejuan PabloAún no hay calificaciones
- 1 RegLinSDocumento20 páginas1 RegLinSManuel De Jesús Salas SalasAún no hay calificaciones
- Cocientes Notables para Quinto de SecundariaDocumento4 páginasCocientes Notables para Quinto de SecundariaCitlaliAún no hay calificaciones
- Sobre Nilálgebras Conmutativas de Potencias AsociativasDe EverandSobre Nilálgebras Conmutativas de Potencias AsociativasAún no hay calificaciones
- Cuadro Consolidado Semanal Noviembre 2022 Rulter-1Documento15 páginasCuadro Consolidado Semanal Noviembre 2022 Rulter-1andesonAún no hay calificaciones
- Reporte Semanal Noviembre 2022 - MonicaDocumento55 páginasReporte Semanal Noviembre 2022 - MonicaandesonAún no hay calificaciones
- ORGANIZACIÓN DE DATOS - Variable CualitativaDocumento5 páginasORGANIZACIÓN DE DATOS - Variable CualitativaandesonAún no hay calificaciones
- ELECTRODO DE VIDRIO PARA LA MEDICION DEL PHDocumento1 páginaELECTRODO DE VIDRIO PARA LA MEDICION DEL PHandeson100% (1)
- Semana 5 Fun Exponen y Log VBDocumento121 páginasSemana 5 Fun Exponen y Log VBandesonAún no hay calificaciones
- GAMARRA SOTO Fiorella Doris PDFDocumento139 páginasGAMARRA SOTO Fiorella Doris PDFandesonAún no hay calificaciones
- PRACTICA 5 SeparacionesDocumento8 páginasPRACTICA 5 SeparacionesandesonAún no hay calificaciones
- Hidrolisis AcidaDocumento6 páginasHidrolisis AcidaandesonAún no hay calificaciones
- Enzimas en Ing. de Bioprocesos PDFDocumento145 páginasEnzimas en Ing. de Bioprocesos PDFandesonAún no hay calificaciones
- Informe de RefrigeracionDocumento19 páginasInforme de RefrigeracionandesonAún no hay calificaciones
- Capitulo II de Radiacion UvDocumento11 páginasCapitulo II de Radiacion UvandesonAún no hay calificaciones
- Trabajo Formulas PolinomicasDocumento13 páginasTrabajo Formulas PolinomicasAlexander PCAún no hay calificaciones
- Géneros NarrativosDocumento9 páginasGéneros NarrativosCarlos HCAún no hay calificaciones
- Consola MinicomDocumento4 páginasConsola MinicomJhon GarciaAún no hay calificaciones
- Descripci+ N de Las Bases de La Did+íctica Del Idioma MaternoDocumento3 páginasDescripci+ N de Las Bases de La Did+íctica Del Idioma MaternoGreefy Slawn100% (1)
- APUNTES SOBRE EL CUENTO Julio OrtegaDocumento1 páginaAPUNTES SOBRE EL CUENTO Julio OrtegaLuchinGAún no hay calificaciones
- Comentario de Texto. Ejemplo.Documento8 páginasComentario de Texto. Ejemplo.Markpro8Aún no hay calificaciones
- Yixing (Libro) Permaneciendo Firme A Los 24Documento99 páginasYixing (Libro) Permaneciendo Firme A Los 24JesSyKuyocAún no hay calificaciones
- Reporte#6 Circuito ElectricoDocumento13 páginasReporte#6 Circuito ElectricoJoseph Alexander Molesky HerediaAún no hay calificaciones
- Cuadro SinopticoDocumento2 páginasCuadro SinopticotesssslAún no hay calificaciones
- Mercadeo de Productos PecuariosDocumento217 páginasMercadeo de Productos PecuariosGuido Eduardo Rojas CastilloAún no hay calificaciones
- Ensayo AcadémicoDocumento13 páginasEnsayo AcadémicoValeria100% (1)
- S4 Contenido Lidte1102Documento15 páginasS4 Contenido Lidte1102DADAún no hay calificaciones
- Actividad 2 CiceronDocumento5 páginasActividad 2 Cicerontania elizabethAún no hay calificaciones
- TrilateracionDocumento5 páginasTrilateracionJorge Tenorio TapiaAún no hay calificaciones
- Crecer en La FeDocumento4 páginasCrecer en La FeBodega PromalabAún no hay calificaciones
- MAT - U6 - 3er Grado - Sesion 11Documento5 páginasMAT - U6 - 3er Grado - Sesion 11Gladys Maria Quiroz TorrealvaAún no hay calificaciones
- FamiliaDocumento10 páginasFamiliaFlor Lucía Montoya SosaAún no hay calificaciones
- Cat A LogoDocumento67 páginasCat A LogoAlejandro RossiAún no hay calificaciones
- Teseo, El Vendedor Del Minotauro 7°A-BDocumento15 páginasTeseo, El Vendedor Del Minotauro 7°A-BPilar CamposAún no hay calificaciones
- Informe La Escalera de La AutoestimaDocumento5 páginasInforme La Escalera de La AutoestimaMarco GonzalesAún no hay calificaciones
- Calendario Laboral Cartagena 2016 PDFDocumento1 páginaCalendario Laboral Cartagena 2016 PDFanagarcias1979Aún no hay calificaciones
- Derechos HumanosDocumento3 páginasDerechos HumanosJean MalpicaAún no hay calificaciones
- TorniDocumento26 páginasTorniJuan Camilo MateusAún no hay calificaciones
- U2 Actividades Procesos de VentaDocumento5 páginasU2 Actividades Procesos de VentaIgnacio SantaeufemiaAún no hay calificaciones
- El Libro Del Jardín Mayo-Junio-Julio InicialDocumento9 páginasEl Libro Del Jardín Mayo-Junio-Julio InicialSoledad RamírezAún no hay calificaciones
- Ortopedia LPH en Dentición MixtaDocumento23 páginasOrtopedia LPH en Dentición MixtaMILADY ANGÉLICA FINO VENEGASAún no hay calificaciones
- Tarea 9Documento6 páginasTarea 9Martha Piero Barone OgnibeneAún no hay calificaciones