También podría gustarte
- Farmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1De EverandFarmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1Aún no hay calificaciones
- PARÁMETROS DE UNA DISTRIBUCIÓN ESTADÍSTICA Parte 4Documento16 páginasPARÁMETROS DE UNA DISTRIBUCIÓN ESTADÍSTICA Parte 4Cynthia RevollarAún no hay calificaciones
- Pruebas Parametricas y No Parametricas - Prueba de Signos, Aproximaciòn Normal A La Binomial y Prueba de Frank Wilcoxon Ejercicios DesarrolladosDocumento74 páginasPruebas Parametricas y No Parametricas - Prueba de Signos, Aproximaciòn Normal A La Binomial y Prueba de Frank Wilcoxon Ejercicios DesarrolladosAlex SanchezAún no hay calificaciones
- Metodos Estadisticos en Investigacion Parametrias y No ParametricasDocumento57 páginasMetodos Estadisticos en Investigacion Parametrias y No Parametricasmaseasy26Aún no hay calificaciones
- Semana 12 - Prueba No ParametricaDocumento23 páginasSemana 12 - Prueba No ParametricaEduardo BautistaAún no hay calificaciones
- Reconocimiento Unidad 2 InferenciaDocumento4 páginasReconocimiento Unidad 2 InferenciaOscar DelgadoAún no hay calificaciones
- Prueba de Hipótesis para PromediosDocumento15 páginasPrueba de Hipótesis para Promediosea2018060915Aún no hay calificaciones
- Estadistica InferencialDocumento17 páginasEstadistica InferencialFranco De La Cruz VargasAún no hay calificaciones
- 2018 60 Tema 3 G Hipótesis Dif 2 Pruebas PDFDocumento8 páginas2018 60 Tema 3 G Hipótesis Dif 2 Pruebas PDFJonaathan CabreraAún no hay calificaciones
- Pruebas de Hipotesis Con Una Muestra S9Documento16 páginasPruebas de Hipotesis Con Una Muestra S9ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- M4 SeparataDocumento20 páginasM4 SeparatacarlosAún no hay calificaciones
- Epn (4) Pruebas Hipotesis Bondad Ajuste AnovaDocumento35 páginasEpn (4) Pruebas Hipotesis Bondad Ajuste AnovaMarlon PachacamaAún no hay calificaciones
- Documento Parcial 1Documento6 páginasDocumento Parcial 1JHONATAN MORALESAún no hay calificaciones
- Determinación Del Tamaño de MuestraDocumento4 páginasDeterminación Del Tamaño de MuestraAraceli AbarcaAún no hay calificaciones
- ppt#8Documento38 páginasppt#8Alejandro Antonio Lopez GaitanAún no hay calificaciones
- Act 6 DmaicDocumento5 páginasAct 6 DmaicLuis ArangoAún no hay calificaciones
- Prueba de Mann Withney v20230508Documento26 páginasPrueba de Mann Withney v20230508Martina GRAún no hay calificaciones
- Prueba de Hipótesis de Proporción y Diferencia de ProporcionDocumento12 páginasPrueba de Hipótesis de Proporción y Diferencia de Proporcionjuan50% (2)
- BIOESTADÍSTICA - Pruebas ParamétricasDocumento10 páginasBIOESTADÍSTICA - Pruebas ParamétricasLUIS ENRIQUE BACALLA PAREDESAún no hay calificaciones
- Etapas Basicas en Pruebas de HipótesisDocumento8 páginasEtapas Basicas en Pruebas de HipótesisReynaEspinosaAún no hay calificaciones
- Pruevas ParametricasDocumento16 páginasPruevas ParametricasvisusAún no hay calificaciones
- Parametricas y No ParametricasDocumento5 páginasParametricas y No ParametricasChrisalbert27Aún no hay calificaciones
- Resumen EST 3.2Documento5 páginasResumen EST 3.2Angel DíazAún no hay calificaciones
- DISENOS-EXPERIMENTALESDocumento33 páginasDISENOS-EXPERIMENTALESCamey Perez Pablo FiladelfoAún no hay calificaciones
- Evaluación de La Calidad de Los ResultadosDocumento19 páginasEvaluación de La Calidad de Los ResultadosKevin Borbor SalazarAún no hay calificaciones
- Test No ParametricosDocumento54 páginasTest No Parametricosandres cernaAún no hay calificaciones
- Parametric AsDocumento73 páginasParametric Asalfredo RamirezAún no hay calificaciones
- Resumen Capitulo 8 14Documento8 páginasResumen Capitulo 8 14Scarlett tatiana Membreño coto100% (1)
- Comparación de DatosDocumento4 páginasComparación de DatosMónica González GonzálezAún no hay calificaciones
- 4 Diseño Completamente Al AzarDocumento7 páginas4 Diseño Completamente Al AzarWilmer joel Ramirez sullonAún no hay calificaciones
- Estadística de Medidas Repetidas y Pruebas de Significación 2Documento6 páginasEstadística de Medidas Repetidas y Pruebas de Significación 2solecasalventuraAún no hay calificaciones
- 2020-D3-Prueba de Hipótesis para La MediaDocumento14 páginas2020-D3-Prueba de Hipótesis para La MediaKryspo Salsa FrescaAún no hay calificaciones
- Tema 5: Fiabilidad:: InstrumentosDocumento6 páginasTema 5: Fiabilidad:: Instrumentosbertin osborneAún no hay calificaciones
- Prueba de HipotesisDocumento8 páginasPrueba de HipotesisJean Carlos Piguave AlvaradoAún no hay calificaciones
- ObjetivosDocumento3 páginasObjetivosmas100% (1)
- Autoevaluación 5 - ESTADISTICA APLICADA PARA LOS NEGOCIOS (9431)Documento6 páginasAutoevaluación 5 - ESTADISTICA APLICADA PARA LOS NEGOCIOS (9431)milagros8pilar8merca100% (1)
- Pruebas de Hipotesis Con R CommanderDocumento22 páginasPruebas de Hipotesis Con R CommanderZero7984Aún no hay calificaciones
- Ejercicio 4Documento24 páginasEjercicio 4Angela LaraAún no hay calificaciones
- Verificación de SupuestosDocumento6 páginasVerificación de SupuestosJonathan RamírezAún no hay calificaciones
- 04 Pruebas de Hip TesisDocumento49 páginas04 Pruebas de Hip Tesisjuan carlos lozano quispeAún no hay calificaciones
- Pruebas de Hipotesis Con R Commander PDFDocumento24 páginasPruebas de Hipotesis Con R Commander PDFZdipolAún no hay calificaciones
- MetodologiDocumento5 páginasMetodologiAlberto RegaladoAún no hay calificaciones
- Modelos Especiales de Distribuciones de Probabilidad de Variable Discreta BinomialDocumento53 páginasModelos Especiales de Distribuciones de Probabilidad de Variable Discreta BinomiallautaritolibertiAún no hay calificaciones
- Taller 2 - Jesus EscalonaDocumento8 páginasTaller 2 - Jesus EscalonaJesus EscalonaAún no hay calificaciones
- Sesión 9 y 10 - Prueba de HipótesisDocumento21 páginasSesión 9 y 10 - Prueba de HipótesisAlejandra soto palaciosAún no hay calificaciones
- Prueba de Hipotesis y de IndependenciaDocumento54 páginasPrueba de Hipotesis y de IndependenciaSergio BerriosAún no hay calificaciones
- Pruebas No ParamétricasDocumento19 páginasPruebas No ParamétricasManuelEnriqueAragònVilcas100% (1)
- Unidad 5 Pruebas de Hipotesis Con Dos Muestras Datos CategoricosDocumento4 páginasUnidad 5 Pruebas de Hipotesis Con Dos Muestras Datos CategoricosNancy Cano75% (8)
- Unidad 1Documento24 páginasUnidad 1Gianni GiulianoAún no hay calificaciones
- Mes 11Documento20 páginasMes 11Juan PerezAún no hay calificaciones
- Prueba U de Mann WhitneyDocumento23 páginasPrueba U de Mann WhitneyAlberto Olmos Mendez100% (1)
- P. de HipótesisDocumento34 páginasP. de HipótesisJUNIOR RAFAEL RODRIGUEZ ALVAREZAún no hay calificaciones
- Clase 11, Investigación de MercadosDocumento55 páginasClase 11, Investigación de MercadosvglusevicAún no hay calificaciones
- EXPOSICIÓN DE ESTADÍSTICA 3.0pipipiDocumento72 páginasEXPOSICIÓN DE ESTADÍSTICA 3.0pipipiPaolo De Los Santos NonatoAún no hay calificaciones
- ActividadDocumento5 páginasActividadMateo Medina EscamillaAún no hay calificaciones
- Principios y SupuestosDocumento6 páginasPrincipios y SupuestosJohancito VillarroelAún no hay calificaciones
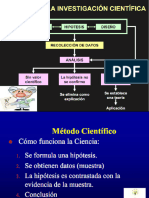
- Resumen Del Capítulo II Del Método Científico Del Libro, Estadística Experimental, Herramienta para La InvestigaciónDocumento10 páginasResumen Del Capítulo II Del Método Científico Del Libro, Estadística Experimental, Herramienta para La InvestigaciónRafael Puma CondoriAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Grado Ciberseguridad OnlineDocumento8 páginasGrado Ciberseguridad Onlinesape2001Aún no hay calificaciones
- Un Proyecto de Innovación Docente Sobre Discusiones Asíncronas en Linea para Aprender en La UniversidadDocumento13 páginasUn Proyecto de Innovación Docente Sobre Discusiones Asíncronas en Linea para Aprender en La Universidadsape2001Aún no hay calificaciones
- Mid 185Documento72 páginasMid 185sape2001Aún no hay calificaciones
- Diseño de Un SIEMDocumento124 páginasDiseño de Un SIEMsape2001Aún no hay calificaciones
- M-O Proteccion Datos EspDocumento11 páginasM-O Proteccion Datos Espsape2001Aún no hay calificaciones
- 2003 Pa Report Ryuk ESDocumento27 páginas2003 Pa Report Ryuk ESsape2001Aún no hay calificaciones
- Mi2º ADE EXA. 30 Enero 2020. 1 S PDFDocumento8 páginasMi2º ADE EXA. 30 Enero 2020. 1 S PDFsape2001100% (1)
- Convenio Colectivo Tad Dts Cit 2016-2018Documento55 páginasConvenio Colectivo Tad Dts Cit 2016-2018sape2001Aún no hay calificaciones
- Examen Semana 1 Febrero 2020Documento3 páginasExamen Semana 1 Febrero 2020sape2001Aún no hay calificaciones
- Bases de Datos NoSQL Caso de Estudio Apa PDFDocumento12 páginasBases de Datos NoSQL Caso de Estudio Apa PDFsape2001Aún no hay calificaciones
- 281 360Documento80 páginas281 360Jorge Ignacio MVAún no hay calificaciones
- PROCEDIMIENTO MetrologíaDocumento2 páginasPROCEDIMIENTO MetrologíaLayfloAún no hay calificaciones
- FacturaDocumento6 páginasFacturaAMPARO INOA SERVICE SRLAún no hay calificaciones
- Semana05 Guia Del Alumno Office BasicoDocumento15 páginasSemana05 Guia Del Alumno Office BasicoEmily GonzalesAún no hay calificaciones
- Instituto Tecnológico de Tehuacán División de Estudios Profesionales Residencias Profesionales Solicitud de Residencias ProfesionalesDocumento2 páginasInstituto Tecnológico de Tehuacán División de Estudios Profesionales Residencias Profesionales Solicitud de Residencias ProfesionalesedmichelAún no hay calificaciones
- Introducción Al Análisis de Regresión Simple - EstadíticaDocumento62 páginasIntroducción Al Análisis de Regresión Simple - EstadíticaRafael Meza GarcíaAún no hay calificaciones
- Sistemas de ControlDocumento49 páginasSistemas de ControlGloria Cuero Gonzalez100% (1)
- Cooperativa Abaco Asesorada Por Prime Capital de Ramesh AgrawalDocumento2 páginasCooperativa Abaco Asesorada Por Prime Capital de Ramesh AgrawalginoromanAún no hay calificaciones
- 1.1. Evolucion de La Conservacion IndustrialDocumento12 páginas1.1. Evolucion de La Conservacion IndustrialOsvaldo MonroyAún no hay calificaciones
- Fundamentos de Los Computadores - Introducción PDFDocumento4 páginasFundamentos de Los Computadores - Introducción PDFjjcuestaAún no hay calificaciones
- Varios Azure PDFDocumento169 páginasVarios Azure PDFCarlos AriasAún no hay calificaciones
- Juan Salvador GaviotaDocumento20 páginasJuan Salvador GaviotaEnoc Tercero100% (1)
- Informe 1: Circuitos Eléctricos y Sus Elementos Utp PanamaDocumento10 páginasInforme 1: Circuitos Eléctricos y Sus Elementos Utp PanamaJoséMendozaAún no hay calificaciones
- TELECOMUNICACIONESDocumento178 páginasTELECOMUNICACIONESyoriam67% (3)
- Modulacion FM y AskDocumento8 páginasModulacion FM y Askoscar riseroAún no hay calificaciones
- Evaluación 3Documento2 páginasEvaluación 3Dj MC100% (2)
- Presentacion Encendido ElectronicoDocumento39 páginasPresentacion Encendido ElectronicoDaniel Pedales100% (2)
- Introduccion A RAPIDDocumento60 páginasIntroduccion A RAPIDRafael Ricardo Beltrán López100% (1)
- Tarea5 RedesDocumento81 páginasTarea5 RedesCristian NossaAún no hay calificaciones
- Monografias Del Trabajo de WordDocumento6 páginasMonografias Del Trabajo de WordroscondezoAún no hay calificaciones
- Mof Gerencia Administracion y Finanzas v05Documento54 páginasMof Gerencia Administracion y Finanzas v05Guiver Santisteban Ibañez100% (2)
- Libertya Instalacion Ubuntu DebianDocumento11 páginasLibertya Instalacion Ubuntu DebianGino Rojas EtdmegAún no hay calificaciones
- Color 1Documento25 páginasColor 1Nacho MartinezAún no hay calificaciones
- CONCURSO AREAS Y VOLUMENES 10 y 11Documento6 páginasCONCURSO AREAS Y VOLUMENES 10 y 11JuanAndresRiveroArrietaAún no hay calificaciones
- Access Point.Documento10 páginasAccess Point.Erendira MuñizAún no hay calificaciones
- Modelo de Sesión - ZoilaDocumento2 páginasModelo de Sesión - ZoilaAlejandro Nolasco EstradaAún no hay calificaciones
- Cieep SCILAB 20071220Documento47 páginasCieep SCILAB 20071220Diego E. Quimbert MontesAún no hay calificaciones
- Semana 01 - Tarea 2 EstadisticaDocumento19 páginasSemana 01 - Tarea 2 EstadisticaJosé Alonso Mendoza CarvoAún no hay calificaciones
- Informe Centro de PresiónDocumento2 páginasInforme Centro de PresióneduarAún no hay calificaciones
- Taller 1Documento5 páginasTaller 1Maria Ruiz LinoAún no hay calificaciones