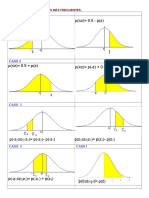
También podría gustarte
- Programación de microcontroladores paso a paso: Ejemplos prácticos desarrollados en la nubeDe EverandProgramación de microcontroladores paso a paso: Ejemplos prácticos desarrollados en la nubeAún no hay calificaciones
- tp1 ArquitecturaDocumento9 páginastp1 ArquitecturaReina Nv100% (3)
- National Semiconductor Exposición TelecomunicacionesDocumento29 páginasNational Semiconductor Exposición TelecomunicacionesAlejandro CoronadoAún no hay calificaciones
- Fundamentos de Redes Informáticas - 2ª EdiciónDe EverandFundamentos de Redes Informáticas - 2ª EdiciónCalificación: 3 de 5 estrellas3/5 (2)
- gr1 Ej4 v1Documento8 páginasgr1 Ej4 v1Joel Proaño Freire100% (3)
- Actividad 1.1 Conceptos Sistemas DistribuidosDocumento10 páginasActividad 1.1 Conceptos Sistemas DistribuidosKevin Ed'sAún no hay calificaciones
- Arquitectura ParalelaDocumento20 páginasArquitectura ParalelaJULIETHAún no hay calificaciones
- Diseño de Sistemas Con FPGADocumento80 páginasDiseño de Sistemas Con FPGAMEM_9763Aún no hay calificaciones
- Supercomputadoras PPTDocumento49 páginasSupercomputadoras PPTEdward Alexander RojasAún no hay calificaciones
- Evolución de Las ComputadoraDocumento9 páginasEvolución de Las ComputadoraCarlos Damian ArgañarazAún no hay calificaciones
- Trabajo 2 Franco Gomez OswaldoDocumento10 páginasTrabajo 2 Franco Gomez OswaldoOSWALDO FRANCO GOMEZAún no hay calificaciones
- 1 Introducción A Las ComputadorasDocumento26 páginas1 Introducción A Las ComputadorasRodrigo Yucra CaballeroAún no hay calificaciones
- Multiprocesadores ApuntesDocumento25 páginasMultiprocesadores ApuntesJacob Flores OrtizAún no hay calificaciones
- Capitulo 2Documento66 páginasCapitulo 2Danny tipanAún no hay calificaciones
- Modelo de Von NeumanDocumento4 páginasModelo de Von NeumanHerless FloresAún no hay calificaciones
- Tema 1 Parte 1 ACSODocumento37 páginasTema 1 Parte 1 ACSOSplit GamesAún no hay calificaciones
- Arquitectura SimdDocumento36 páginasArquitectura SimdXiomara Alvarado Delgado100% (1)
- PffreDocumento1 páginaPffreLuz AvigailAún no hay calificaciones
- Arquitecturas ParalelasDocumento22 páginasArquitecturas Paralelasbeldar_dbAún no hay calificaciones
- Sistemas MulticoreDocumento2 páginasSistemas MulticoreRicardo GinoAún no hay calificaciones
- Computacion 3Documento6 páginasComputacion 3FlorPerettiAún no hay calificaciones
- Computador Periferico y Sus AplicacionesDocumento32 páginasComputador Periferico y Sus AplicacionesMaycolPradoAún no hay calificaciones
- Gestion de Centros de ComputoDocumento30 páginasGestion de Centros de ComputoJared Oscanoa YantasAún no hay calificaciones
- Resumen Estructura Interna de La PC 1-6Documento27 páginasResumen Estructura Interna de La PC 1-6Cristian RuizAún no hay calificaciones
- Presentacion Tipos de Computadoras y Sus DispositivosDocumento22 páginasPresentacion Tipos de Computadoras y Sus DispositivosMasami Iwasawa0% (1)
- Risc - Cisc - Harvard - Von NewmanDocumento30 páginasRisc - Cisc - Harvard - Von NewmanmajesticbufoAún no hay calificaciones
- Clase 1 - Introduccion A Las ComputadorasDocumento23 páginasClase 1 - Introduccion A Las ComputadorasOliver RamosAún no hay calificaciones
- Generaciones de Las ComputadorasDocumento20 páginasGeneraciones de Las ComputadorasWillson Muñoz BernalAún no hay calificaciones
- Definicion de NUMA y OtrosDocumento41 páginasDefinicion de NUMA y OtrosRamón Moreno MalavéAún no hay calificaciones
- Guia de Aprendizaje 1 Microcontroladores.Documento16 páginasGuia de Aprendizaje 1 Microcontroladores.Mauricio AlfaroAún no hay calificaciones
- Sistemas Multiprocesadores 2004-2005 Parte 1Documento25 páginasSistemas Multiprocesadores 2004-2005 Parte 1Dani MaxiAún no hay calificaciones
- S.I Cap 6 y 7Documento23 páginasS.I Cap 6 y 7lizeth anilemaAún no hay calificaciones
- Clases de Microcontroladores - ESPEDocumento55 páginasClases de Microcontroladores - ESPEFreddy GarcíaAún no hay calificaciones
- Historia de Los Sistemas OperativosDocumento10 páginasHistoria de Los Sistemas OperativosJ Mauiricio CRAún no hay calificaciones
- Sistemas Multiprocesadores 2004-2005Documento38 páginasSistemas Multiprocesadores 2004-2005Sergio D Garcia QuirozAún no hay calificaciones
- Risc CiscDocumento20 páginasRisc Ciscalienarandas123Aún no hay calificaciones
- Risc Cisc PDFDocumento20 páginasRisc Cisc PDFalienarandas123Aún no hay calificaciones
- Conceptos VariosDocumento2 páginasConceptos VariosMindTecAún no hay calificaciones
- Procesadores Cisc y RiscDocumento6 páginasProcesadores Cisc y RiscJuan HernandezAún no hay calificaciones
- Maquina MultinivelDocumento23 páginasMaquina MultinivelJesús Antonio ReyesAún no hay calificaciones
- Capítulo 4 Sistemas Multiusuarios PDFDocumento56 páginasCapítulo 4 Sistemas Multiusuarios PDFDafne CaballeroAún no hay calificaciones
- Tercera Generación de ComputadoresDocumento10 páginasTercera Generación de ComputadoresWalter ChambaAún no hay calificaciones
- Una Computadora U Ordenador Es Un Aparato Electrónico Que Tiene El Fin de Recibir y Procesar Datos para La Realización de Diversas OperacionesDocumento12 páginasUna Computadora U Ordenador Es Un Aparato Electrónico Que Tiene El Fin de Recibir y Procesar Datos para La Realización de Diversas OperacionesNina JimenezAún no hay calificaciones
- Arquitectura de Von Neumann y RiscDocumento5 páginasArquitectura de Von Neumann y RiscKevin Vladimir CarrilloAún no hay calificaciones
- 1 - Sistemas InformáticosDocumento71 páginas1 - Sistemas InformáticosRaul JasoAún no hay calificaciones
- Introducción A Los Microprocesadores y MicrocontroladoresDocumento20 páginasIntroducción A Los Microprocesadores y MicrocontroladoresMartin HGAún no hay calificaciones
- INFORMATICADocumento5 páginasINFORMATICAMarielisAún no hay calificaciones
- MICROCONTROLADORES ConceptosDocumento5 páginasMICROCONTROLADORES ConceptosKarenAún no hay calificaciones
- Informatica 1Documento36 páginasInformatica 1Anonymous VVFncoWFvRAún no hay calificaciones
- Conceptos Generales de La Informática, Evidencia de Aprendizaje 1.Documento7 páginasConceptos Generales de La Informática, Evidencia de Aprendizaje 1.Miguel Angel Jaramillo MontoyaAún no hay calificaciones
- Sesion 1Documento89 páginasSesion 1Jerry JamesAún no hay calificaciones
- SCP - Apuntes.0 ConceptosbasicosDocumento14 páginasSCP - Apuntes.0 Conceptosbasicosmatalobos6Aún no hay calificaciones
- Tarea 1.1 de Micro ContriladoresDocumento28 páginasTarea 1.1 de Micro ContriladoresHil FalaAún no hay calificaciones
- Material Primer Parcial - 2022Documento6 páginasMaterial Primer Parcial - 2022Julio DureAún no hay calificaciones
- SD ContecsiDocumento48 páginasSD ContecsiCristian BravoAún no hay calificaciones
- Generaciones de Computadoras y Memoria Estado SolidoDocumento8 páginasGeneraciones de Computadoras y Memoria Estado SolidoErVelascoAún no hay calificaciones
- Trbajo de InformaticaDocumento13 páginasTrbajo de InformaticaLUIS ANGEL LLANOS ACUÑAAún no hay calificaciones
- Microcontroladores 1Documento48 páginasMicrocontroladores 1Gastón ValenzuelaAún no hay calificaciones
- MimdDocumento11 páginasMimddysanAún no hay calificaciones
- Microprocesadores. Estructura. Tipos. Comunicación Con El ExteriorDocumento10 páginasMicroprocesadores. Estructura. Tipos. Comunicación Con El ExteriorsirdegAún no hay calificaciones
- Fundamentos de Redes InformáticasDe EverandFundamentos de Redes InformáticasCalificación: 4.5 de 5 estrellas4.5/5 (9)
- Modelamiento de Datos 1Documento22 páginasModelamiento de Datos 1-Andrea NoloAún no hay calificaciones
- Comprobante de Asistencia Al Proceso EducativoDocumento2 páginasComprobante de Asistencia Al Proceso EducativoWanda PizarroAún no hay calificaciones
- Informe HerokuDocumento29 páginasInforme HerokuAngelica Hurtado OteroAún no hay calificaciones
- Capitulo-6.pdf Investigación, Fundamentos y Metodología. Alma Del Cid, Franco Sandoval, Rosemary MéndezDocumento29 páginasCapitulo-6.pdf Investigación, Fundamentos y Metodología. Alma Del Cid, Franco Sandoval, Rosemary MéndezMaria Fernanda Cun RomeroAún no hay calificaciones
- Software Contable Gbs 05 Ficha Tecnica Cuentas Por CobrarDocumento3 páginasSoftware Contable Gbs 05 Ficha Tecnica Cuentas Por CobrarGBS, La Casa Colombiana de SoftwareAún no hay calificaciones
- EL69 Procesamiento Digital de Señales 201202Documento4 páginasEL69 Procesamiento Digital de Señales 201202Tatiana Paucar RimacAún no hay calificaciones
- Analisis Del Valor AgragdoDocumento4 páginasAnalisis Del Valor AgragdoIbeth Carolina GualotoAún no hay calificaciones
- Cat ETDocumento27 páginasCat ETChrystian Meller Vasquez Mayta100% (5)
- Calibrador de SoldaduraDocumento4 páginasCalibrador de Soldaduraapi-118986524Aún no hay calificaciones
- AlgebraDocumento12 páginasAlgebraEvelyn Cartes de LagosAún no hay calificaciones
- Black BerryDocumento21 páginasBlack Berryfcovenegas69Aún no hay calificaciones
- Manual A2K4 Usuario PDFDocumento28 páginasManual A2K4 Usuario PDFJuan Pablo BelettiAún no hay calificaciones
- Unidad 1: Administración de Operaciones IIDocumento3 páginasUnidad 1: Administración de Operaciones IIÁngel LabouraceAún no hay calificaciones
- Casos y Tipos de Problemas de La NormalDocumento2 páginasCasos y Tipos de Problemas de La NormalAlejandrina De BoutaudAún no hay calificaciones
- Derivadas en RDocumento14 páginasDerivadas en RCristian CarrascoAún no hay calificaciones
- Ejercicios Resueltos EcuacionesDocumento27 páginasEjercicios Resueltos EcuacionessantiagoAún no hay calificaciones
- Mapa Conceptual PDFDocumento1 páginaMapa Conceptual PDFMARIA100% (2)
- Cómo Resolver Problemas de ProbabilidadsDocumento2 páginasCómo Resolver Problemas de ProbabilidadsLizbethAbalosChipana0% (1)
- Clave de Producto de Microsoft Office Professional Plus 2010 BetaDocumento2 páginasClave de Producto de Microsoft Office Professional Plus 2010 BetaJonathan MartínezAún no hay calificaciones
- Acuerdo de ResponsabilidadDocumento2 páginasAcuerdo de ResponsabilidadJose JamaAún no hay calificaciones
- Guia 3 - WORD EDICIÓN BÁSICADocumento10 páginasGuia 3 - WORD EDICIÓN BÁSICAJT100% (1)
- Problemas Del MilenioDocumento4 páginasProblemas Del MilenioWendyAguilarAún no hay calificaciones
- Fund. de Programación - Tema 3Documento32 páginasFund. de Programación - Tema 3Miguel MorontaAún no hay calificaciones
- Introduccion A La Seguridad de Redes Telematicas EjerciciosIntypedia004Documento3 páginasIntroduccion A La Seguridad de Redes Telematicas EjerciciosIntypedia004Sergyo ValarezoAún no hay calificaciones
- Criterio de Jury Con RetroalimentaciónDocumento9 páginasCriterio de Jury Con RetroalimentaciónHerlan Ricardo Ortuño PasquierAún no hay calificaciones
- Transformacion de Ed50 A Etrs89Documento11 páginasTransformacion de Ed50 A Etrs89pollodelaabuelaAún no hay calificaciones
- Itinerario FormativoDocumento2 páginasItinerario FormativoLali AronésAún no hay calificaciones
- Manual Fotocopiadora Ricoh 2800Documento9 páginasManual Fotocopiadora Ricoh 2800Roberto Díaz NogalesAún no hay calificaciones
- Watt Stopper Legrand Chile PDFDocumento40 páginasWatt Stopper Legrand Chile PDFFercho HuancaAún no hay calificaciones