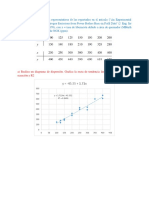
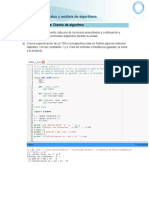
También podría gustarte
- Problemas Teoria de ColasDocumento10 páginasProblemas Teoria de ColasAngel Santos CR92% (12)
- Tarea 4 Estadistica - MergedDocumento11 páginasTarea 4 Estadistica - MergedEmanuel Isaías VélezAún no hay calificaciones
- TAREA No. 3 - EST-223Documento7 páginasTAREA No. 3 - EST-223lisbeth SCAún no hay calificaciones
- Problemas de Simulación de Sistemas para El Curso Agrupado Por TemasDocumento43 páginasProblemas de Simulación de Sistemas para El Curso Agrupado Por Temasluis zaravia rodriguezAún no hay calificaciones
- Fórmulas para Gráficas de ControlDocumento3 páginasFórmulas para Gráficas de ControlRosendo RizoAún no hay calificaciones
- Tabla de La Distribucion T - StudentDocumento9 páginasTabla de La Distribucion T - Studentrussel calderon chochoca100% (1)
- Simulacion de Pares y NonesDocumento18 páginasSimulacion de Pares y NonesSebastian VivasAún no hay calificaciones
- Pca 1 Grado Matematica 2023Documento13 páginasPca 1 Grado Matematica 2023JEANNETTE MONICA CUBA PALOMINO100% (1)
- ProbabilidadDocumento6 páginasProbabilidadSoniaQuispe100% (2)
- Actividad3 EstadisticayprobabilidadDocumento8 páginasActividad3 Estadisticayprobabilidadcarlos andres rivera ortiz100% (2)
- Metodo de MontecarloDocumento11 páginasMetodo de MontecarloAngel Andrade GarciaAún no hay calificaciones
- Estudio de Hidrologia Ala (Final)Documento25 páginasEstudio de Hidrologia Ala (Final)Anonymous mGD38TQBzAún no hay calificaciones
- Acin213 s8 EntregableDocumento4 páginasAcin213 s8 Entregableemaecone5956Aún no hay calificaciones
- Analisis Estadistico DXTDocumento14 páginasAnalisis Estadistico DXTRoberto VillanuevaAún no hay calificaciones
- Base Factorial (Modelo Factorial)Documento7 páginasBase Factorial (Modelo Factorial)Daniel ReyesAún no hay calificaciones
- Trabajo Kolmogorov1 - Ronnie RodriguezDocumento40 páginasTrabajo Kolmogorov1 - Ronnie RodriguezRonnie RodríguezAún no hay calificaciones
- Practica 3 MetodosDocumento14 páginasPractica 3 MetodosJoshua MendozaAún no hay calificaciones
- TALLER SOLIDOS PARTE I (Autoguardado)Documento9 páginasTALLER SOLIDOS PARTE I (Autoguardado)Alejandra RobayoAún no hay calificaciones
- Modelos1 PDFDocumento21 páginasModelos1 PDFKaty PachecoAún no hay calificaciones
- Econo Me TriaDocumento7 páginasEcono Me TriaAlexander Molina RamirezAún no hay calificaciones
- Ejemplo Carta R X BarraDocumento27 páginasEjemplo Carta R X BarraJULIETH ALEJANDRA OSPINA CALDERONAún no hay calificaciones
- Taller 1 Estadística InferencialDocumento3 páginasTaller 1 Estadística InferencialcharlesAún no hay calificaciones
- Intervalos de ConfianzafinalDocumento18 páginasIntervalos de Confianzafinalherlen lopezAún no hay calificaciones
- Ortega 2013 C3 S1Documento8 páginasOrtega 2013 C3 S1JUAN SEBASTIÁN MIÑOAún no hay calificaciones
- Pregunta Dinamizadora U2Documento4 páginasPregunta Dinamizadora U2andres ramirez sarmientoAún no hay calificaciones
- Ejemplo de Prueba de Hipótesis e Intervalos de Confianza v2Documento14 páginasEjemplo de Prueba de Hipótesis e Intervalos de Confianza v2ANGEL JESUS GONZALEZ PEREDOAún no hay calificaciones
- Lab4 Regresión ExponencialDocumento7 páginasLab4 Regresión ExponencialmitzelaAún no hay calificaciones
- División de Las ProbabilidadesDocumento70 páginasDivisión de Las ProbabilidadesZaid EstradaAún no hay calificaciones
- Guia para Examen de Estadistica Primer Parcial Upem (Versión 1) (Autoguardado)Documento6 páginasGuia para Examen de Estadistica Primer Parcial Upem (Versión 1) (Autoguardado)Sashá AlaksandriAún no hay calificaciones
- Regresion Lineal 2Documento22 páginasRegresion Lineal 2jvAún no hay calificaciones
- Latex 1Documento9 páginasLatex 1rommyAún no hay calificaciones
- Taller 6 Estadística IIDocumento4 páginasTaller 6 Estadística IISalomé EstradaAún no hay calificaciones
- TAREA IV. Diseño de La Calidad de La SimulaciónDocumento8 páginasTAREA IV. Diseño de La Calidad de La SimulaciónMaria del rosario VazquezAún no hay calificaciones
- 9 Prueba Bondad Ajuste S-KDocumento15 páginas9 Prueba Bondad Ajuste S-KSebastian Andres Miranda CuevasAún no hay calificaciones
- Vasquez Cazon Daniel Alexander FI220 Z2 I1Documento6 páginasVasquez Cazon Daniel Alexander FI220 Z2 I1Daniel Alexander Vasquez CazonAún no hay calificaciones
- Tabla de Constantes para Gráficas de Control PDFDocumento2 páginasTabla de Constantes para Gráficas de Control PDFRosendo RizoAún no hay calificaciones
- Copia de Excel SolverDocumento16 páginasCopia de Excel SolverWilliam Andres Angulo OspinoAún no hay calificaciones
- EstadisticaS3 ResueltoDocumento18 páginasEstadisticaS3 ResueltoFERNANDO JANESAún no hay calificaciones
- Trabajo Final Teoría Macroeconómica IIIDocumento29 páginasTrabajo Final Teoría Macroeconómica IIIELIZABETH GUILLENAún no hay calificaciones
- Taller Examen 3 Ecuación de EstadoDocumento6 páginasTaller Examen 3 Ecuación de Estadogustavo alzate patiñoAún no hay calificaciones
- 1.2 Generación de Pseudoaleatorios y Variables AleatoriasDocumento38 páginas1.2 Generación de Pseudoaleatorios y Variables AleatoriasJorge Jair CoronaAún no hay calificaciones
- Tarea5estadistica Gerardo Velasquez 31721531Documento4 páginasTarea5estadistica Gerardo Velasquez 31721531Gerardo VelasquezAún no hay calificaciones
- Regresión LM PDFDocumento14 páginasRegresión LM PDFCarolina AguilarAún no hay calificaciones
- EstimacionDocumento6 páginasEstimacionDARMA CCOÑISLLA ESPINOZAAún no hay calificaciones
- Trabajo Final de EstadisticaDocumento6 páginasTrabajo Final de EstadisticaLuis Antonio Diaz RomeroAún no hay calificaciones
- N Mist Sci Kit LearnDocumento6 páginasN Mist Sci Kit LearnRobinson Poveda CamargoAún no hay calificaciones
- Cuadernillo de Trabajo III UnidadDocumento19 páginasCuadernillo de Trabajo III UnidadWALTER SUEL ARROYOAún no hay calificaciones
- Aem Listado 1 Regresion 2023-1Documento6 páginasAem Listado 1 Regresion 2023-1Esteban AlarcónAún no hay calificaciones
- Problemas Metodos Numericos - Metodos Iterativos Ecuaciones LinealesDocumento5 páginasProblemas Metodos Numericos - Metodos Iterativos Ecuaciones LinealesCARLO DANIEL QUISPE VALENZUELAAún no hay calificaciones
- Trabajo Final Probabilidades y EstadísticasAngel Daniel Glez Glez TLE21Documento7 páginasTrabajo Final Probabilidades y EstadísticasAngel Daniel Glez Glez TLE21Angel Daniel GonzálezAún no hay calificaciones
- Anexo. Tablas de La Curva Normal de Probabilidades. Campana de GaussDocumento11 páginasAnexo. Tablas de La Curva Normal de Probabilidades. Campana de Gaussmags1980Aún no hay calificaciones
- Geba U3 A2 JipgDocumento11 páginasGeba U3 A2 JipgGaby PĝAún no hay calificaciones
- Regresión y Correlación LinealDocumento6 páginasRegresión y Correlación LinealGabriel CallejasAún no hay calificaciones
- HW 4 CHAP 2-1 - SimulacionDocumento5 páginasHW 4 CHAP 2-1 - SimulacionDenisse GrandaAún no hay calificaciones
- Estadistica Descriptiva y Probabilidades-513Documento1 páginaEstadistica Descriptiva y Probabilidades-513hernan ccorimanya sopantaAún no hay calificaciones
- Regresión Lineal Simple 2Documento4 páginasRegresión Lineal Simple 2ERNESTO AQUILES REINOSA NERIOAún no hay calificaciones
- 02 em 04 Empe U1 A2Documento6 páginas02 em 04 Empe U1 A2Alejandra ZapataAún no hay calificaciones
- Unidad 3 - Actividad - 2 - González - RuizDocumento6 páginasUnidad 3 - Actividad - 2 - González - RuizAndy Goru100% (1)
- Matlab IIDocumento9 páginasMatlab IIJuan Umaña RamosAún no hay calificaciones
- Actividad3 EstadisticayprobabilidadDocumento9 páginasActividad3 EstadisticayprobabilidadMayra Cruz FernandezAún no hay calificaciones
- Mest2 A1 U2 MajjDocumento8 páginasMest2 A1 U2 MajjAvraham Ben AsherAún no hay calificaciones
- Tarea 1 Estadistica y Probabilidad - Rosalba Miossotti CruzDocumento17 páginasTarea 1 Estadistica y Probabilidad - Rosalba Miossotti CruzRosalba Miossotti HollingsAún no hay calificaciones
- Producto Académico #03Documento5 páginasProducto Académico #03Eduardo Vilca callaAún no hay calificaciones
- PASO - 3 - GRUPO SimulacionDocumento17 páginasPASO - 3 - GRUPO SimulacionNathalia Rodriguez AcevedoAún no hay calificaciones
- Usando Datos (Cont)Documento7 páginasUsando Datos (Cont)soundwave72Aún no hay calificaciones
- Universidad Abierta Y A Distancia de Mexico: Carmen Regina Navarrete GonzalezDocumento10 páginasUniversidad Abierta Y A Distancia de Mexico: Carmen Regina Navarrete Gonzalezsoundwave72Aún no hay calificaciones
- Introducción A ADDocumento16 páginasIntroducción A ADsoundwave72Aún no hay calificaciones
- Mcom2 U3 Ea FRCRDocumento3 páginasMcom2 U3 Ea FRCRsoundwave72Aún no hay calificaciones
- Mcom2 U2 A1 FRCRDocumento7 páginasMcom2 U2 A1 FRCRsoundwave72Aún no hay calificaciones
- Tormenta Solar - Arthur C. ClarkeDocumento292 páginasTormenta Solar - Arthur C. Clarkesoundwave72100% (1)
- Maco U3 A2 FRCRDocumento3 páginasMaco U3 A2 FRCRsoundwave72Aún no hay calificaciones
- MACO U3 A3 FRCR RevBDocumento6 páginasMACO U3 A3 FRCR RevBsoundwave72Aún no hay calificaciones
- Maco U3 A2 FRCRDocumento3 páginasMaco U3 A2 FRCRsoundwave72Aún no hay calificaciones
- MACO U2 A2 FRCR RevBDocumento8 páginasMACO U2 A2 FRCR RevBsoundwave72Aún no hay calificaciones
- MACO U3 A2 FRCR RevBDocumento4 páginasMACO U3 A2 FRCR RevBsoundwave72Aún no hay calificaciones
- Unidad 2, Evidencia de AprendizajeDocumento8 páginasUnidad 2, Evidencia de Aprendizajesoundwave72Aún no hay calificaciones
- Maco U2 Ea FRCRDocumento8 páginasMaco U2 Ea FRCRsoundwave72Aún no hay calificaciones
- Maco U2 A3 FRCRDocumento8 páginasMaco U2 A3 FRCRsoundwave72Aún no hay calificaciones
- Mcom2 U1 A3 FRCRDocumento5 páginasMcom2 U1 A3 FRCRsoundwave72Aún no hay calificaciones
- Act. 1. Inducción MatemáticaDocumento2 páginasAct. 1. Inducción Matemáticasoundwave72Aún no hay calificaciones
- EA. Introducción Al Análisis Combinatorio U1-1Documento1 páginaEA. Introducción Al Análisis Combinatorio U1-1soundwave72Aún no hay calificaciones
- Mcom2 U1 Ea FRCRDocumento3 páginasMcom2 U1 Ea FRCRsoundwave72Aún no hay calificaciones
- Act. 3. Ejercicios de Conteo U1.1Documento1 páginaAct. 3. Ejercicios de Conteo U1.1soundwave72Aún no hay calificaciones
- MT MAMT2 U1 EA FRCR RevBDocumento10 páginasMT MAMT2 U1 EA FRCR RevBsoundwave72Aún no hay calificaciones
- MT MAMT2 U2 A2 FRCR RevBDocumento10 páginasMT MAMT2 U2 A2 FRCR RevBsoundwave72Aún no hay calificaciones
- Mcom2 U1 A4 FRCRDocumento5 páginasMcom2 U1 A4 FRCRsoundwave72Aún no hay calificaciones
- MT Mamt2 U2 A2 FRCRDocumento10 páginasMT Mamt2 U2 A2 FRCRsoundwave72Aún no hay calificaciones
- MT MAMT2 U1 A1 FRCR RevBDocumento6 páginasMT MAMT2 U1 A1 FRCR RevBsoundwave72Aún no hay calificaciones
- MT Mamt2 U2 A1 ForoDocumento2 páginasMT Mamt2 U2 A1 Forosoundwave72Aún no hay calificaciones
- MT Mamt2 U1 A3 FRCRDocumento5 páginasMT Mamt2 U1 A3 FRCRsoundwave72Aún no hay calificaciones
- MT Mamt2 U1 A1 FRCRDocumento6 páginasMT Mamt2 U1 A1 FRCRsoundwave72Aún no hay calificaciones
- EstadisticaDocumento13 páginasEstadisticaLuz GamboaAún no hay calificaciones
- ECA 3 Probabilidad y Estadística Agosto 2013-Enero 2014Documento17 páginasECA 3 Probabilidad y Estadística Agosto 2013-Enero 2014M. en C. Arturo Vázquez Córdova100% (1)
- Newbold Ejercicios Variables AleatoriasDocumento13 páginasNewbold Ejercicios Variables AleatoriasVale López Díaz0% (1)
- AES300catedra1 2g3b376Documento19 páginasAES300catedra1 2g3b376Gia D LZAún no hay calificaciones
- De Boer Et Al SeriacionDocumento14 páginasDe Boer Et Al SeriacionmcscattolinAún no hay calificaciones
- Plan de Muestreo Simple y DobleDocumento4 páginasPlan de Muestreo Simple y DobleDanielMangles100% (1)
- Formulario PDFDocumento4 páginasFormulario PDFNancy Segura RodríguezAún no hay calificaciones
- PracticasDocumento54 páginasPracticasjaime perezAún no hay calificaciones
- MAGERITDocumento27 páginasMAGERITArtyom FernandezAún no hay calificaciones
- Boletin 3 Variables AleatoriasDocumento7 páginasBoletin 3 Variables AleatoriasEvaAún no hay calificaciones
- RP - MAT5 - K10 - Manual de CorrecciónDocumento11 páginasRP - MAT5 - K10 - Manual de CorrecciónMargot Gomez100% (3)
- Ejercicios de RA EP 2021 ADocumento12 páginasEjercicios de RA EP 2021 AJ Jeff TorocheAún no hay calificaciones
- Curva Caracteristica de OperacionDocumento17 páginasCurva Caracteristica de OperacionIsrael Pando GarcíaAún no hay calificaciones
- Guia de Ejercicios, Principios de Administracion de Operaciones-1Documento9 páginasGuia de Ejercicios, Principios de Administracion de Operaciones-1Luis Colocho100% (2)
- Auditoria - ResumenDocumento2 páginasAuditoria - ResumenDaniel Augusto DUQUE CALDERONAún no hay calificaciones
- S04. Distribuciones de Probabilidad PDFDocumento21 páginasS04. Distribuciones de Probabilidad PDFraul andres contreras ortizAún no hay calificaciones
- Quiz 2 Semana 6 2 Intento-Estadistica I - (Grupo2) PDFDocumento8 páginasQuiz 2 Semana 6 2 Intento-Estadistica I - (Grupo2) PDFYENNYAún no hay calificaciones
- Problemas Teoria de La DecisiónDocumento8 páginasProblemas Teoria de La DecisiónDa SiAún no hay calificaciones
- Probabilidad Condicional y Teorema de BayesDocumento43 páginasProbabilidad Condicional y Teorema de BayesRafael Gonzalez SanchezAún no hay calificaciones
- Trabajo Colaborativo III - REV 03Documento9 páginasTrabajo Colaborativo III - REV 03Sara Priscila Terrones Checco100% (1)
- Tipos VULNERABILIDADocumento21 páginasTipos VULNERABILIDAJonathan JimenezAún no hay calificaciones
- Taller 1 EstadisticaDocumento2 páginasTaller 1 EstadisticaHeidy Mariana RIOS BERNALAún no hay calificaciones
- Tarea 2 Problemas 1.3.1 Hasta 1.3.5Documento6 páginasTarea 2 Problemas 1.3.1 Hasta 1.3.5Racsa ConstructoraAún no hay calificaciones
- Treball Estad SticaDocumento9 páginasTreball Estad SticaMarc Manrique BuadesAún no hay calificaciones
- Taller Funciones de Distribucion - 01 - 2024Documento4 páginasTaller Funciones de Distribucion - 01 - 2024ruma.10Aún no hay calificaciones