También podría gustarte
- Metodo Cientifico PROTOCOLO Y REGISTRODocumento41 páginasMetodo Cientifico PROTOCOLO Y REGISTROAlma Gaona AvilaAún no hay calificaciones
- Cancer EndometrialDocumento42 páginasCancer EndometrialAlma Gaona AvilaAún no hay calificaciones
- Guía Homeopatía 2018Documento32 páginasGuía Homeopatía 2018Alma Gaona AvilaAún no hay calificaciones
- Modulo3 Sesion1Documento41 páginasModulo3 Sesion1Alma Gaona AvilaAún no hay calificaciones
- Cancer EndometrialDocumento42 páginasCancer EndometrialAlma Gaona AvilaAún no hay calificaciones
- Cacu y EmbarazoDocumento19 páginasCacu y EmbarazoAlma Gaona AvilaAún no hay calificaciones
- Tarea EminusDocumento3 páginasTarea EminusAlma Gaona AvilaAún no hay calificaciones
- Medicinacritica PDFDocumento1 páginaMedicinacritica PDFAlma Gaona AvilaAún no hay calificaciones
- Pancreatirtis EmbarazadaDocumento2 páginasPancreatirtis EmbarazadaAlma Gaona AvilaAún no hay calificaciones
- Hidrosp ManejoDocumento5 páginasHidrosp ManejoAlma Gaona AvilaAún no hay calificaciones
- Endometrial SpanishDocumento13 páginasEndometrial SpanishAlma Gaona AvilaAún no hay calificaciones
- MiocardiopatiaDocumento75 páginasMiocardiopatiaAlma Gaona AvilaAún no hay calificaciones
- Guia Europea para El Tratamiento de La EPIDocumento10 páginasGuia Europea para El Tratamiento de La EPIGarcia RosaAún no hay calificaciones
- ValvulopatiasDocumento30 páginasValvulopatiasAlma Gaona AvilaAún no hay calificaciones
- Respuesta Auditiva Del Tallo CerebralDocumento15 páginasRespuesta Auditiva Del Tallo CerebralAlma Gaona AvilaAún no hay calificaciones
- Microcirculación y Sistema Linfático 2013Documento21 páginasMicrocirculación y Sistema Linfático 2013Alma Gaona AvilaAún no hay calificaciones
- MenopausiaDocumento18 páginasMenopausiaAlma Gaona AvilaAún no hay calificaciones
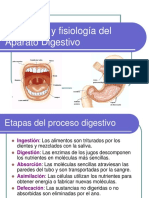
- Aparato Digestivo-1Documento28 páginasAparato Digestivo-1KAROLINAAún no hay calificaciones
- Desp AmenDocumento11 páginasDesp AmenAlma Gaona AvilaAún no hay calificaciones
- Tarea de Combinacion de EstrategiasDocumento4 páginasTarea de Combinacion de EstrategiasHéctor LafargaAún no hay calificaciones
- Libro de Matemática de 3er Grado Primaria - AritméticaDocumento59 páginasLibro de Matemática de 3er Grado Primaria - AritméticaROSABEL MARISA BAZAN CIRILO75% (4)
- Adonais y Otros PoemasDocumento62 páginasAdonais y Otros PoemasItalo Zeballos Leiva100% (3)
- Respuestas Consulta Pública Reglamento ExtintoresDocumento69 páginasRespuestas Consulta Pública Reglamento ExtintoresmarceloolearojasAún no hay calificaciones
- Experimento#1 Fisica LabDocumento7 páginasExperimento#1 Fisica LabIvanna TiburcioAún no hay calificaciones
- Facb0201-00033346 20210829084529 PDFDocumento1 páginaFacb0201-00033346 20210829084529 PDFGeronimo BeltrameAún no hay calificaciones
- Diagnostico SalaverryDocumento40 páginasDiagnostico SalaverryMorales Mrm75% (4)
- PARCIAL de ConsultorioDocumento11 páginasPARCIAL de ConsultorioFranco GarnicaAún no hay calificaciones
- Pliegos Del Procedimiento De: Subasta Inversa Electronica Versión SERCOP 1.1 (20 de Febrero 2014)Documento21 páginasPliegos Del Procedimiento De: Subasta Inversa Electronica Versión SERCOP 1.1 (20 de Febrero 2014)daniel alejoAún no hay calificaciones
- 8,-EXP-IR-GS-10-N Methodology For Production Segregation - En.esDocumento10 páginas8,-EXP-IR-GS-10-N Methodology For Production Segregation - En.esReymy Alexis Munive TorresAún no hay calificaciones
- Asfaltos LiquidosDocumento4 páginasAsfaltos LiquidosErmenegildo Graterol Vielma Caceres0% (1)
- Depreciacion Contable Activos FijosDocumento2 páginasDepreciacion Contable Activos FijosElmer RomeroAún no hay calificaciones
- Características de Una Organizaciones VirtualDocumento9 páginasCaracterísticas de Una Organizaciones Virtuallalo0% (1)
- Folleto de MesDocumento36 páginasFolleto de MesAlejandra L. ArreguinAún no hay calificaciones
- Formato Afiliación Partido AsiDocumento1 páginaFormato Afiliación Partido AsiDAVID SOTOAún no hay calificaciones
- Menús Tradición 2024Documento21 páginasMenús Tradición 2024Racam10Aún no hay calificaciones
- Flores de Arnica Montana, Interes TerapeuticoDocumento7 páginasFlores de Arnica Montana, Interes TerapeuticoSarita CadenaAún no hay calificaciones
- Plan Estrategico de Ia para HotelesDocumento22 páginasPlan Estrategico de Ia para HotelesconsultastjoAún no hay calificaciones
- Bobina DesmagnetizadoraDocumento12 páginasBobina DesmagnetizadoraSusi Moreno DíazAún no hay calificaciones
- Efecto DopplerDocumento5 páginasEfecto DopplerEstephany GuevaraAún no hay calificaciones
- Ejercicios de Control de Calidad RtyDocumento10 páginasEjercicios de Control de Calidad RtyAlex Sean Figueroa AyalaAún no hay calificaciones
- Actividad 2. Variables MacoeconómicasDocumento12 páginasActividad 2. Variables Macoeconómicasmaria arango67% (3)
- Transmision Señales ConceptosDocumento10 páginasTransmision Señales Conceptosmetaphysics18Aún no hay calificaciones
- Chlorella VulgarisDocumento1 páginaChlorella VulgarisSantiago Ospina CortesAún no hay calificaciones
- Triptico 1Documento2 páginasTriptico 1DAYRA XIOMARA GARCIA ZABALETA ALBURQUEQUEAún no hay calificaciones
- Paper - Estimación Del Requerimiento de Aminoácidos en SalmónidosDocumento5 páginasPaper - Estimación Del Requerimiento de Aminoácidos en SalmónidosRogelio Alfredo Utrilla ArellanoAún no hay calificaciones
- Perfil Profesional: EducaciónDocumento2 páginasPerfil Profesional: EducaciónMagda Yesenia Luna SalazarAún no hay calificaciones
- PSICOLOGIA EDUCATIVA Actividad 12Documento5 páginasPSICOLOGIA EDUCATIVA Actividad 12Zaira Tibaduisa CharryAún no hay calificaciones
- Planillas de Mantenimiento de MáquinasDocumento11 páginasPlanillas de Mantenimiento de MáquinasAnonymous 4lIAJ1Lk2Aún no hay calificaciones
- Desarrollo Caso Practico 2 Sport Athletic S.A AlumnosDocumento14 páginasDesarrollo Caso Practico 2 Sport Athletic S.A AlumnosAnthonny Montalván100% (1)