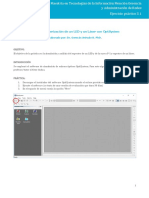
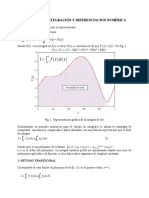
También podría gustarte
- Dsec-Conceptosbasicosconejemplos PDFDocumento80 páginasDsec-Conceptosbasicosconejemplos PDFTimo Calderon LetonaAún no hay calificaciones
- Paso 3 - 124asdDocumento12 páginasPaso 3 - 124asdJorge Mejias100% (1)
- Machine LearningDocumento27 páginasMachine Learningcarlosjulioph100% (1)
- Taller 2 Yohana Melo 151 Version1Documento10 páginasTaller 2 Yohana Melo 151 Version1Dani HerreraAún no hay calificaciones
- Condensación EstáticaDocumento6 páginasCondensación Estáticaropin14100% (1)
- Manu1 U2 Ea MaDocumento10 páginasManu1 U2 Ea MaMariella LimAún no hay calificaciones
- Informe N°3Documento9 páginasInforme N°3makens pomaAún no hay calificaciones
- Proyecto AI KERASDocumento34 páginasProyecto AI KERASAndrea JuliettAún no hay calificaciones
- Laboratorio 3 Diseño de Elementos de ProtecciónDocumento22 páginasLaboratorio 3 Diseño de Elementos de ProtecciónEver Rodríguez AlvarezAún no hay calificaciones
- Diagramas de SecuenciaDocumento79 páginasDiagramas de SecuenciaVladimir Alejandro FLOREZ NEIRAAún no hay calificaciones
- PracticaComputoEvolutivo EduardoDanielUcUicabDocumento12 páginasPracticaComputoEvolutivo EduardoDanielUcUicabEduardo D Uc UicabAún no hay calificaciones
- Consideraciones Diseño DL PDFDocumento10 páginasConsideraciones Diseño DL PDFLUIS FELIPE TOBAR SOTELOAún no hay calificaciones
- Entregable 3 - COMPONENTE PRÁCTICO - PRÁCTICAS SIMULADASDocumento23 páginasEntregable 3 - COMPONENTE PRÁCTICO - PRÁCTICAS SIMULADASYudy SanchezAún no hay calificaciones
- Modelos Predictivos de La Inteligencia ArtificialDocumento14 páginasModelos Predictivos de La Inteligencia ArtificialDanny Angelo MirandaAún no hay calificaciones
- Tratamiento de ImagenesDocumento18 páginasTratamiento de ImagenesHernan Dario Alape GonzalezAún no hay calificaciones
- Tecnicas de Busqueda Practica 1,2Documento16 páginasTecnicas de Busqueda Practica 1,2Mario Arturo Velasco AlegriaAún no hay calificaciones
- Guia de Practica de Lab #2 Ev 2.Documento2 páginasGuia de Practica de Lab #2 Ev 2.SirJupiterAún no hay calificaciones
- Guía de Laboratorio 7Documento19 páginasGuía de Laboratorio 7ANGIE CAROLINA LLAIQUE CHULLUNQUIAAún no hay calificaciones
- Lab 10 Identificacion de Sistemas Curva Reaccion MIRANDA Y LLUMPODocumento25 páginasLab 10 Identificacion de Sistemas Curva Reaccion MIRANDA Y LLUMPOSlayther Ortiz MalcaAún no hay calificaciones
- Inteligencia Artificial - Con Aplicaciones A La IngenieríaDocumento3 páginasInteligencia Artificial - Con Aplicaciones A La IngenieríaLuis Enrique López LeónAún no hay calificaciones
- 1030 TP1 - 2024Documento9 páginas1030 TP1 - 2024nicolastoscanoAún no hay calificaciones
- Semana 1. Teoria de ErroresDocumento5 páginasSemana 1. Teoria de ErroresJazmin Flores MondragónAún no hay calificaciones
- Descripción de Un Paquete de Simulación DisponibleDocumento15 páginasDescripción de Un Paquete de Simulación DisponibleEdwin GlezAún no hay calificaciones
- Estudio de CasoDocumento15 páginasEstudio de CasoJesus SotoAún no hay calificaciones
- Análisis de ModelosDocumento11 páginasAnálisis de ModelosAxel H. Ruelas PortadaAún no hay calificaciones
- Conceptos Básicos y Difiniciones de Aprendisajes de MaquinasDocumento6 páginasConceptos Básicos y Difiniciones de Aprendisajes de MaquinasGio ValenzuelaAún no hay calificaciones
- Algoritmo1 PDFDocumento3 páginasAlgoritmo1 PDFGregory Rojas PastorAún no hay calificaciones
- Aporte Individual - Paulino HDocumento5 páginasAporte Individual - Paulino HmaikolAún no hay calificaciones
- Tarea 2 y Tarea 3 ArenaDocumento13 páginasTarea 2 y Tarea 3 ArenaRoyer Palomino RodriguezAún no hay calificaciones
- Prueba Integral Nivel I Inicial 2020-1Documento5 páginasPrueba Integral Nivel I Inicial 2020-1OmarCarrion100% (1)
- Dia 2 Intro MLDocumento22 páginasDia 2 Intro MLjesus_larrazabal_salasAún no hay calificaciones
- Informe 5 Identificacion de Sistemas Con MatlabDocumento4 páginasInforme 5 Identificacion de Sistemas Con MatlabCarlos Leonardo Sanchez Contreras0% (1)
- Analisis ClusterDocumento35 páginasAnalisis ClusterOrlando SotoAún no hay calificaciones
- Matemática Aplicada A La ElectrónicaDocumento7 páginasMatemática Aplicada A La ElectrónicaAnonymous RaCE6IAún no hay calificaciones
- Unidad 2 AlgoritmosDocumento2 páginasUnidad 2 AlgoritmosMilagro SalinasAún no hay calificaciones
- Aplicaciones de Machine Learning para Sistemas de DistribuciónDocumento3 páginasAplicaciones de Machine Learning para Sistemas de DistribuciónqwrertyAún no hay calificaciones
- Guía Aprendizaje 07CDocumento38 páginasGuía Aprendizaje 07CTeresa Sanchez VillanuevaAún no hay calificaciones
- Evaluacion Ejemplo 3Documento7 páginasEvaluacion Ejemplo 3mari rojasAún no hay calificaciones
- Eficiencia en Algoritmos Paralelos - BrisDocumento17 páginasEficiencia en Algoritmos Paralelos - Brisjavier_brisAún no hay calificaciones
- TP02 - 2021 - Primera ParteDocumento5 páginasTP02 - 2021 - Primera ParteSebastian SanchezAún no hay calificaciones
- Cuestionario (FINAL)Documento10 páginasCuestionario (FINAL)adwed wadAún no hay calificaciones
- MemoriaDocumento14 páginasMemoriacarlosinfantediosAún no hay calificaciones
- Reporte de Practica Seleccion de Una Condicion, Angel Vergara ShamedDocumento2 páginasReporte de Practica Seleccion de Una Condicion, Angel Vergara ShamedShamed AngelAún no hay calificaciones
- LMP U1 Resumen Progrma Tda JymhDocumento7 páginasLMP U1 Resumen Progrma Tda JymhJonathan MartinezAún no hay calificaciones
- Estudio de Caso - U4-Soto - JesusDocumento16 páginasEstudio de Caso - U4-Soto - JesusJesus SotoAún no hay calificaciones
- PRINCIPIOSDEALGORITMOS UndefinedDocumento5 páginasPRINCIPIOSDEALGORITMOS UndefinedJulio Ayala IpanaquéAún no hay calificaciones
- Manual TecnicoDocumento20 páginasManual Tecnicoedson cepedaAún no hay calificaciones
- Fuzzy Minimals ClusteringDocumento25 páginasFuzzy Minimals ClusteringRonald RisAún no hay calificaciones
- Diapositiva 1 PresentacionDocumento4 páginasDiapositiva 1 Presentacionabraham david rodriguez cumplidoAún no hay calificaciones
- Trabajo UNIDAD 1Documento5 páginasTrabajo UNIDAD 1Marcos BayonaAún no hay calificaciones
- Alejandro Velasquez Paso2 2150510 4Documento10 páginasAlejandro Velasquez Paso2 2150510 4jorge acostaAún no hay calificaciones
- Red Neuronal 2 Digitos JeffreeDocumento7 páginasRed Neuronal 2 Digitos JeffreeJeffree moralesAún no hay calificaciones
- Apef2 Ind G8Documento19 páginasApef2 Ind G8July Esther QuelcaAún no hay calificaciones
- Carrasco Cayambe Daniela RocioDocumento19 páginasCarrasco Cayambe Daniela RocioDanny CarrascoAún no hay calificaciones
- Aporte Final Sistemas DinamicosDocumento17 páginasAporte Final Sistemas Dinamicosbig dataAún no hay calificaciones
- Llata PsDocumento12 páginasLlata Pscacr_72Aún no hay calificaciones
- Introduccion Al Machine LearningDocumento5 páginasIntroduccion Al Machine LearningJosé Ramón Espinosa MuñozAún no hay calificaciones
- Glosario Intro A La ModelacionDocumento2 páginasGlosario Intro A La ModelacionAlicia LoyaAún no hay calificaciones
- Reporte - Hernandez Cano JaretDocumento12 páginasReporte - Hernandez Cano JaretLeonel SanchezAún no hay calificaciones
- Analisis de SensibilidadDocumento4 páginasAnalisis de SensibilidadAlejandra AlelitaAún no hay calificaciones
- Análisis de datos con Power Bi, R-Rstudio y KnimeDe EverandAnálisis de datos con Power Bi, R-Rstudio y KnimeAún no hay calificaciones
- CamScanner 21-03-2024 10.44Documento13 páginasCamScanner 21-03-2024 10.44InternetsuckerAún no hay calificaciones
- Rpaterni - Ejercicios Teóricos de Multiplicación de MatricesDocumento5 páginasRpaterni - Ejercicios Teóricos de Multiplicación de MatricesInternetsuckerAún no hay calificaciones
- Labos 1Documento5 páginasLabos 1InternetsuckerAún no hay calificaciones
- 9-Uni2-2-Como Solucionar ProblemasDocumento8 páginas9-Uni2-2-Como Solucionar ProblemasInternetsuckerAún no hay calificaciones
- FINALDocumento1 páginaFINALInternetsuckerAún no hay calificaciones
- La Realidad de Las Clases Virtuales RealDocumento1 páginaLa Realidad de Las Clases Virtuales RealInternetsuckerAún no hay calificaciones
- Aaaa ADocumento3 páginasAaaa AInternetsuckerAún no hay calificaciones
- Guia Castellano Undecimo 1 de Septiembre. EstudiantesDocumento11 páginasGuia Castellano Undecimo 1 de Septiembre. EstudiantesInternetsuckerAún no hay calificaciones
- Cuadro ComparativoDocumento1 páginaCuadro ComparativoInternetsucker100% (1)
- Guia-1 - Xi-Química-Grupos Funcionales PDFDocumento11 páginasGuia-1 - Xi-Química-Grupos Funcionales PDFInternetsuckerAún no hay calificaciones
- Prueba Icfes PDFDocumento5 páginasPrueba Icfes PDFInternetsuckerAún no hay calificaciones
- Arbol Binario AVL PDFDocumento9 páginasArbol Binario AVL PDFdevsco63Aún no hay calificaciones
- Compendio de Matematicas III VillaDocumento221 páginasCompendio de Matematicas III VillaCarlos RodriguezAún no hay calificaciones
- Control Digital Sim3 PDFDocumento4 páginasControl Digital Sim3 PDFJohann MedinaAún no hay calificaciones
- SEM 4 - Sesión 7Documento15 páginasSEM 4 - Sesión 7Luis Alberto Pecho BallarteAún no hay calificaciones
- QuirozYañez Fanny M17S1AI1Documento9 páginasQuirozYañez Fanny M17S1AI1Fanny QuirozAún no hay calificaciones
- Clase 1 (25-08-21)Documento28 páginasClase 1 (25-08-21)Agustin PiñeiroAún no hay calificaciones
- Informe Lab1Documento10 páginasInforme Lab1Kenly DeffittAún no hay calificaciones
- Criptosistemas de Cifrado en Flujo: Tema 3Documento52 páginasCriptosistemas de Cifrado en Flujo: Tema 3John ParraAún no hay calificaciones
- MII PUJ Optimizacion Avanzada Syllabus21012020 PDFDocumento2 páginasMII PUJ Optimizacion Avanzada Syllabus21012020 PDFsedase1990Aún no hay calificaciones
- Funciones FiltrosDocumento3 páginasFunciones FiltrosUrbano Vargas CoemanAún no hay calificaciones
- Curso Taller Validacion - 2020Documento95 páginasCurso Taller Validacion - 2020Elard Pedro Vilca CutimboAún no hay calificaciones
- Foro IndividualDocumento2 páginasForo IndividualAngelo HernándezAún no hay calificaciones
- Modelo Probabilistico ContinuoDocumento44 páginasModelo Probabilistico ContinuoVICTOR OLIVER LEON BERROCALAún no hay calificaciones
- CS61 Lizbeth Cuba Samaniego 26/09/2022 120 MinutosDocumento17 páginasCS61 Lizbeth Cuba Samaniego 26/09/2022 120 MinutosMauricio Antony Amado AguilarAún no hay calificaciones
- Unidad 3 - Fase 3 - Representación Del Conocimiento en Ia: GRUPO: 90169 - 1Documento13 páginasUnidad 3 - Fase 3 - Representación Del Conocimiento en Ia: GRUPO: 90169 - 1naujAún no hay calificaciones
- Taller Ecuaciones LinealesDocumento2 páginasTaller Ecuaciones LinealesDiego MonáAún no hay calificaciones
- MetodosdeintegracionDocumento14 páginasMetodosdeintegracionyaniher pradaAún no hay calificaciones
- Ejercicio de Aplicación.2QQDocumento10 páginasEjercicio de Aplicación.2QQmiltonm6Aún no hay calificaciones
- Examen Ingenieria MatematicaDocumento12 páginasExamen Ingenieria MatematicaSamuel SantamariaAún no hay calificaciones
- S13.s2 - Evaluación Continua - Sistemas de Ecuaciones y Números Complejos - INTRODUCCION A LA MATEMATICA PARA INGENIERIA (42585)Documento4 páginasS13.s2 - Evaluación Continua - Sistemas de Ecuaciones y Números Complejos - INTRODUCCION A LA MATEMATICA PARA INGENIERIA (42585)William Aguirre67% (3)
- Agrupamiento Espectral NormalizadoDocumento4 páginasAgrupamiento Espectral NormalizadoStalin IbarraAún no hay calificaciones
- Teorema de Kleene Y Lema de ArdenDocumento14 páginasTeorema de Kleene Y Lema de Ardenddd100% (1)
- Clase 6. Transformada de FourierDocumento8 páginasClase 6. Transformada de FourierWllfredo MoralesAún no hay calificaciones
- Laboratorio 2 PDFDocumento5 páginasLaboratorio 2 PDFEinar PérezAún no hay calificaciones
- Algoritmo VectoresDocumento9 páginasAlgoritmo VectoresDerlystorresAún no hay calificaciones
- Gilbert Alexander Murillo Corales - 177025 - 0Documento5 páginasGilbert Alexander Murillo Corales - 177025 - 0Gilbert Alexander MURILLO CORALESAún no hay calificaciones
- Diseño de Controladores en El Dominio de La FrecuenciaDocumento23 páginasDiseño de Controladores en El Dominio de La FrecuenciaArturo CMAún no hay calificaciones
- Programacion Lineal - Metodo SimplexDocumento8 páginasProgramacion Lineal - Metodo SimplexFanor Rojas FernandezAún no hay calificaciones
- Metodo InealDocumento3 páginasMetodo InealRodriguez Vasquez OsvaldoAún no hay calificaciones