También podría gustarte
- Resumen de Diseño Estadístico Para Investigadores en Ciencias Sociales y del Comportamiento. Capítulo 2: Variables Estadísticas: RESÚMENES UNIVERSITARIOSDe EverandResumen de Diseño Estadístico Para Investigadores en Ciencias Sociales y del Comportamiento. Capítulo 2: Variables Estadísticas: RESÚMENES UNIVERSITARIOSAún no hay calificaciones
- Tema 3 EXPLORACION Y DESCRIPCION UNIVARIADADocumento4 páginasTema 3 EXPLORACION Y DESCRIPCION UNIVARIADAalbita183018Aún no hay calificaciones
- Trabajo 3Documento6 páginasTrabajo 3Juvenal carvajal cruzAún no hay calificaciones
- Tema 2 EstadísticaDocumento10 páginasTema 2 EstadísticaLucia AlmaguerAún no hay calificaciones
- Estadística Descriptiva y Teoría de La ProbabilidadDocumento9 páginasEstadística Descriptiva y Teoría de La ProbabilidadMelanie Nogue FructuosoAún no hay calificaciones
- Abp 2Documento12 páginasAbp 2Victor :/Aún no hay calificaciones
- Inv Teo 6Documento22 páginasInv Teo 6kevin zurita riosAún no hay calificaciones
- Medidas tendencia dispersión control procesosDocumento35 páginasMedidas tendencia dispersión control procesosCamilo De Jesus PipeAún no hay calificaciones
- Capítulo 3Documento22 páginasCapítulo 3Fabiana Gonzales CastilloAún no hay calificaciones
- Tema 3-Análisis Descriptivo V.cualitDocumento11 páginasTema 3-Análisis Descriptivo V.cualitalissaAún no hay calificaciones
- Series Simples y Datos AgrupadosDocumento29 páginasSeries Simples y Datos AgrupadosRene RiveraAún no hay calificaciones
- Medidas de Tendencia Central - Herrera Gutiérrez María Del RosarioDocumento9 páginasMedidas de Tendencia Central - Herrera Gutiérrez María Del RosarioMary HGAún no hay calificaciones
- INVESTIGACIÓNDocumento10 páginasINVESTIGACIÓNAnyi GarciaAún no hay calificaciones
- Actividad 1 Estadistica InferencialDocumento9 páginasActividad 1 Estadistica InferencialLizeth Hernández100% (1)
- Medidas de DispersionDocumento6 páginasMedidas de Dispersionhumberto solanoAún no hay calificaciones
- Análisis de datos y medidas estadísticasDocumento3 páginasAnálisis de datos y medidas estadísticasIvonneYulietPerezAún no hay calificaciones
- Cyd - Uabp 3 - Pediatría BioestadisticaDocumento2 páginasCyd - Uabp 3 - Pediatría BioestadisticaFlorencia BallardiniAún no hay calificaciones
- 01 Tutoria 1 - TEMA 1 - Conceptos Basicos y Organizacion de DatosDocumento15 páginas01 Tutoria 1 - TEMA 1 - Conceptos Basicos y Organizacion de DatosKarina MontenegroAún no hay calificaciones
- Introducción Al Análisis de DatosDocumento6 páginasIntroducción Al Análisis de DatosAlejandro García JiménezAún no hay calificaciones
- Preguntas Teorias de TendenciaDocumento3 páginasPreguntas Teorias de TendenciaRogelio GomezAún no hay calificaciones
- Tema 4Documento2 páginasTema 4Celia Romero BledaAún no hay calificaciones
- TTvr3Ysy7tcIvPUidt8i 2Documento9 páginasTTvr3Ysy7tcIvPUidt8i 2EDGAR GAEL RIVERA ESPINOZAAún no hay calificaciones
- Medidas de Tendencia CentralDocumento16 páginasMedidas de Tendencia CentralRaulMarmanilloAún no hay calificaciones
- Resúmenes TeoríaDocumento9 páginasResúmenes TeoríaDayAún no hay calificaciones
- Fase 2 - Variables Estadísticas - Folkenberg DíazDocumento13 páginasFase 2 - Variables Estadísticas - Folkenberg DíazFOLKENBERG DÍAZ PÉREZAún no hay calificaciones
- Mediana EstadisticaDocumento5 páginasMediana EstadisticaOscar Rene Polo BarrancoAún no hay calificaciones
- TAREA # 4 Medidas de Tendencia Central, Localización y DispersiónDocumento10 páginasTAREA # 4 Medidas de Tendencia Central, Localización y DispersiónCarlos HernandezAún no hay calificaciones
- REPUBLICA BOLIVARIANA DE VENEZUELA Gregory HoyDocumento17 páginasREPUBLICA BOLIVARIANA DE VENEZUELA Gregory Hoygregory peinadoAún no hay calificaciones
- Medidas de Tendencia y dispersion terminadoDocumento5 páginasMedidas de Tendencia y dispersion terminadoManuel De Jesús Guinea SerranoAún no hay calificaciones
- Qué es la estadística: introducción a la estadística descriptiva e inferencialDocumento66 páginasQué es la estadística: introducción a la estadística descriptiva e inferencialMilton Benalcazar0% (1)
- Resumen EstadisticaDocumento9 páginasResumen EstadisticaCaterina KategoraAún no hay calificaciones
- Informática IDocumento6 páginasInformática IjoseAún no hay calificaciones
- Medidas centrales y dispersiónDocumento16 páginasMedidas centrales y dispersiónMadelyn ReyesAún no hay calificaciones
- Saber PHPDocumento23 páginasSaber PHPFernando GuerreroAún no hay calificaciones
- Medidas dispersiónDocumento17 páginasMedidas dispersióndanielaroa9Aún no hay calificaciones
- Apuntes de Descriptiva y EjerciciosDocumento16 páginasApuntes de Descriptiva y EjerciciosJeferson RamírezAún no hay calificaciones
- Medidas EstadisticaDocumento7 páginasMedidas EstadisticaYesenia ChinchillaAún no hay calificaciones
- Conocimientos en EstadísticaDocumento9 páginasConocimientos en EstadísticaEduardo HernandezAún no hay calificaciones
- estadística univariadaDocumento11 páginasestadística univariadaCLAUDIA LUCENDO GUILLANAún no hay calificaciones
- Resumen Tema 5Documento9 páginasResumen Tema 5nereaAún no hay calificaciones
- PolitecnicaDocumento9 páginasPolitecnicaJesús VargasAún no hay calificaciones
- Nuevo Documento de Microsoft WordDocumento11 páginasNuevo Documento de Microsoft WordEdgar PatinAún no hay calificaciones
- SESGODocumento6 páginasSESGOYovanna del J. Echazarreta PechAún no hay calificaciones
- DispersionyformaDocumento47 páginasDispersionyformaIgor Sadaba100% (1)
- Fase 4 Medidas EstadísticasDocumento31 páginasFase 4 Medidas EstadísticasdarwinyandreaAún no hay calificaciones
- Medidas de DispersionDocumento13 páginasMedidas de DispersionDora GómezAún no hay calificaciones
- estadistica instruccionalDocumento12 páginasestadistica instruccionalTeresa ZoghbiAún no hay calificaciones
- Apuntes Estadistica AplicadaDocumento82 páginasApuntes Estadistica AplicadasaretemaAún no hay calificaciones
- Reporte Video de La Unidad 3Documento8 páginasReporte Video de La Unidad 3Luz Ángela EspinosaAún no hay calificaciones
- TEMA Medidas DispersionDocumento8 páginasTEMA Medidas DispersionjuanflorocAún no hay calificaciones
- Medidas de DispersionDocumento9 páginasMedidas de DispersionMireya GomezAún no hay calificaciones
- Qué es la estadísticaDocumento66 páginasQué es la estadísticaWalter SainzAún no hay calificaciones
- Asimetria y ApuntamientoDocumento11 páginasAsimetria y ApuntamientoMaribeth Berrio RosadoAún no hay calificaciones
- Medidas de VariabilidadDocumento4 páginasMedidas de VariabilidadMiguel AngelAún no hay calificaciones
- Medidas de Dispersion - Mirvia AraguaDocumento5 páginasMedidas de Dispersion - Mirvia AraguaMirviaAraguaAún no hay calificaciones
- Punto de EstadisticaDocumento15 páginasPunto de EstadisticaJose David RomeroAún no hay calificaciones
- Tema 4 BioestDocumento43 páginasTema 4 BioestKatty BohorquezAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Ficha SilencioDocumento8 páginasFicha SilencioIvánAún no hay calificaciones
- Ficha Tiro Con ArcoDocumento1 páginaFicha Tiro Con ArcoIvánAún no hay calificaciones
- Ficha ColecciónDocumento1 páginaFicha ColecciónIvánAún no hay calificaciones
- Apuntes Tema 4Documento15 páginasApuntes Tema 4IvánAún no hay calificaciones
- Apuntes Tema 5Documento15 páginasApuntes Tema 5IvánAún no hay calificaciones
- Resultados Del Diagnóstico Con ObservacionesDocumento20 páginasResultados Del Diagnóstico Con Observacionesgonzaloperrito.2021Aún no hay calificaciones
- Ideas principales y centrales de párrafosDocumento3 páginasIdeas principales y centrales de párrafosGladys NúñezAún no hay calificaciones
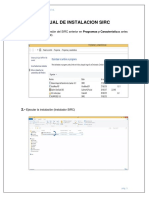
- Manual Instalacion Sirc PDFDocumento6 páginasManual Instalacion Sirc PDFEdgardAsuncionLazaroHuamaniAún no hay calificaciones
- DistociasDocumento15 páginasDistociasCamila FragaAún no hay calificaciones
- 3.3 Ejercicios Competencia Perfecta PDFDocumento2 páginas3.3 Ejercicios Competencia Perfecta PDFHERBERT DAVID DELGADO FLORIANAún no hay calificaciones
- Cortes y EstacasDocumento5 páginasCortes y EstacasOlvin Quispe NinasivinchaAún no hay calificaciones
- Memoria 2 Riesgos MecanicosDocumento11 páginasMemoria 2 Riesgos Mecanicossandra legardaAún no hay calificaciones
- La Esencia de La Iglesia Local en La Epístola A Los EfesiosDocumento10 páginasLa Esencia de La Iglesia Local en La Epístola A Los EfesiosIglesia de Dios PerúAún no hay calificaciones
- Justino El RetiranteDocumento156 páginasJustino El RetiranteNora Beatriz DiazAún no hay calificaciones
- Macronutrientes y MicronutrientesDocumento8 páginasMacronutrientes y MicronutrientesFRANCISCO ANTONIO PEÃ'A EPULEO50% (2)
- Temperatura de La Flama AdiabáticaDocumento2 páginasTemperatura de La Flama AdiabáticaEros GarciaAún no hay calificaciones
- Modulo de Salud PublicaDocumento84 páginasModulo de Salud PublicaAlejandra VasquezAún no hay calificaciones
- Entre Dos Pandemias Influenza y El Covid-19Documento23 páginasEntre Dos Pandemias Influenza y El Covid-19Miguel G.nAún no hay calificaciones
- Computación Cuántica Carlos ViviescasDocumento2 páginasComputación Cuántica Carlos ViviescasCarlos A Buitrago CAún no hay calificaciones
- Innovaciones Modernas en La Construccion de Pavimentos FlexiblesDocumento12 páginasInnovaciones Modernas en La Construccion de Pavimentos FlexiblesEduardoChavezAún no hay calificaciones
- Silabo de EstadisticaDocumento91 páginasSilabo de EstadisticaDragonbound Db CbAún no hay calificaciones
- Beneficios Productos MegahealthDocumento5 páginasBeneficios Productos MegahealthOlga AndradeAún no hay calificaciones
- AMILASADocumento1 páginaAMILASACorina BriggetteAún no hay calificaciones
- MEAD. Diseño Curricular. Febrero 2023. Tema II. C.I. 10.979.927 (2)Documento11 páginasMEAD. Diseño Curricular. Febrero 2023. Tema II. C.I. 10.979.927 (2)Héctor CastilloAún no hay calificaciones
- Agua de CalderaDocumento11 páginasAgua de CalderaTomas5102Aún no hay calificaciones
- Biografia de Carlos NoriegaDocumento5 páginasBiografia de Carlos NoriegaLuis Apaza100% (2)
- 12.1 - Anatomía Clínica de Los PárpadosDocumento5 páginas12.1 - Anatomía Clínica de Los PárpadosSary Rivadeneira100% (1)
- Dios Perrino ConsuelodeDocumento183 páginasDios Perrino ConsuelodeTrandafir GeorgianaAún no hay calificaciones
- Personajes conceptuales en Deleuze y NietzscheDocumento9 páginasPersonajes conceptuales en Deleuze y NietzschePablo Eugenio FernandezAún no hay calificaciones
- San Juan de La Cruz, Una Mística para Aprender A Vivir, Por Juan Antonio MarcosDocumento11 páginasSan Juan de La Cruz, Una Mística para Aprender A Vivir, Por Juan Antonio MarcosAbu Nadi100% (2)
- JCE VoleibolDocumento4 páginasJCE VoleibolpilarAún no hay calificaciones
- Album Multiculturalidad en Honduras (Eduar Rodriguez)Documento14 páginasAlbum Multiculturalidad en Honduras (Eduar Rodriguez)Eduar RodriguezAún no hay calificaciones
- 9.0 TDR Accesorios para Agua y DesagueDocumento7 páginas9.0 TDR Accesorios para Agua y DesagueJOSE BERRU USHIÑAHUAAún no hay calificaciones
- Adjetivos calificativos: clasificación y análisisDocumento2 páginasAdjetivos calificativos: clasificación y análisisSandra VidalAún no hay calificaciones
- Foro #3Documento4 páginasForo #3MARTINNA ALDANA CHAVARROAún no hay calificaciones