También podría gustarte
- Capitulo IXDocumento44 páginasCapitulo IXhadiAún no hay calificaciones
- Marco Teórico U6Documento23 páginasMarco Teórico U6Bianca CrupiAún no hay calificaciones
- Eercicios de Estadistica 2Documento76 páginasEercicios de Estadistica 2Wilmar Jose Gonzalez Palomino100% (1)
- Cap6 - Pruebas de HipótesisDocumento38 páginasCap6 - Pruebas de HipótesisJUAN ANTONIO EYZAGUIRRE ABARZUAAún no hay calificaciones
- Problemas Del Temario Examen FinalDocumento40 páginasProblemas Del Temario Examen FinalEIKO YATTOAún no hay calificaciones
- Hipotesis Estadistica CompletoDocumento70 páginasHipotesis Estadistica CompletoSergio OrtegaAún no hay calificaciones
- Hipotesis - Unj - Tecnologia MedicaDocumento29 páginasHipotesis - Unj - Tecnologia MedicaCAMEVA100% (1)
- Estadistica Prueba de HipotesisDocumento18 páginasEstadistica Prueba de HipotesisEberdRodriguezMinaya100% (3)
- ESTADISTICA TEORICA Tema 7. Contraste de HipotesisDocumento15 páginasESTADISTICA TEORICA Tema 7. Contraste de HipotesisAlejandra LopezAún no hay calificaciones
- Ejercicios Hipotesis PDFDocumento67 páginasEjercicios Hipotesis PDFmiguel hisacAún no hay calificaciones
- Modulo 2 - Investigacion de MercadosDocumento35 páginasModulo 2 - Investigacion de MercadosEvelyn MiravalAún no hay calificaciones
- Sesión 2. Hipótesis MediaDocumento32 páginasSesión 2. Hipótesis Mediamanuel.alvarezpadAún no hay calificaciones
- Inferencia Estadistica - Un ParametroDocumento26 páginasInferencia Estadistica - Un Parametroj.oswaldochanAún no hay calificaciones
- Prueba de HipótesisDocumento63 páginasPrueba de HipótesisGustavo PerezAún no hay calificaciones
- Eddymar - Contrastes de Hipótesis ListoDocumento22 páginasEddymar - Contrastes de Hipótesis ListocarmenAún no hay calificaciones
- Sesión 12Documento31 páginasSesión 12KeshuxAún no hay calificaciones
- Recurso 1Documento61 páginasRecurso 1Rafael SánchezAún no hay calificaciones
- Prueba de La Media y Prueba de Hipotesis de La MediaDocumento15 páginasPrueba de La Media y Prueba de Hipotesis de La Mediaederluna338Aún no hay calificaciones
- Docima de Hipotesis1Documento17 páginasDocima de Hipotesis1Marcelo JoaquínAún no hay calificaciones
- Prueba DE HIPOTESISDocumento12 páginasPrueba DE HIPOTESISJacob TerronesAún no hay calificaciones
- 1 Objetivos Con Chi CuadradoDocumento48 páginas1 Objetivos Con Chi CuadradoGuillermo Ppd100% (2)
- Sem15 Prueba Hipotesis Una muestra-EGDocumento28 páginasSem15 Prueba Hipotesis Una muestra-EGRonald Roosvelt NuñezAún no hay calificaciones
- Estadística Empresarial Ii: Conceptos Básicos de Pruebas de HipótesisDocumento8 páginasEstadística Empresarial Ii: Conceptos Básicos de Pruebas de HipótesisArturo LoayzaAún no hay calificaciones
- Repaso HypoDocumento37 páginasRepaso HypoKevin Roman PratsAún no hay calificaciones
- Sesion8 Prueba HipotesisDocumento12 páginasSesion8 Prueba HipotesisTERESAAún no hay calificaciones
- Tema 8 Completo Contrastes Parametricos PDFDocumento29 páginasTema 8 Completo Contrastes Parametricos PDFALEJANDRO GALÁN CANOAún no hay calificaciones
- Pruebas de Hipotesis AlinaDocumento39 páginasPruebas de Hipotesis AlinaJHON ANGEL AGUILAR CASTILLOAún no hay calificaciones
- Pruebadehip Inicio 1Documento10 páginasPruebadehip Inicio 1Julio Os MartinezAún no hay calificaciones
- S11 S1-HipotesisDocumento27 páginasS11 S1-HipotesisRoy Angelo Master Montes BarahonaAún no hay calificaciones
- Unidad Iii-Parte 2 - Docimas-2020-2Documento29 páginasUnidad Iii-Parte 2 - Docimas-2020-2Carlos Emilio CAún no hay calificaciones
- Pasos para El Contraste o Prueba de HipótesisDocumento4 páginasPasos para El Contraste o Prueba de HipótesisTony OcampoAún no hay calificaciones
- A4-Test y Asociacion de Variables PDFDocumento52 páginasA4-Test y Asociacion de Variables PDFAndrés Gana CortésAún no hay calificaciones
- Prueba de HipotesisDocumento24 páginasPrueba de HipotesisJonatan FassioAún no hay calificaciones
- Unidad Ii-Parte 3 - Docimas-Plan 2030-2022-1 - 221118 - 181426Documento39 páginasUnidad Ii-Parte 3 - Docimas-Plan 2030-2022-1 - 221118 - 181426Camila Retamal ValenzuelaAún no hay calificaciones
- Prueba de Hipotesis de Chi CuadradoDocumento49 páginasPrueba de Hipotesis de Chi CuadradoEriksen Mallma MoránAún no hay calificaciones
- Estadística General - Semana 11 - Sesión 22 - 2023-2 - Prueba de HipotesisDocumento56 páginasEstadística General - Semana 11 - Sesión 22 - 2023-2 - Prueba de HipotesisEvelyn CubillasAún no hay calificaciones
- Estadistica General Sem-11 2022-2Documento43 páginasEstadistica General Sem-11 2022-2Alejandra Morón LópezAún no hay calificaciones
- Prueba de HipotesisDocumento53 páginasPrueba de HipotesisCamila Fernanda Leon HurtadoAún no hay calificaciones
- Estadística General Semana 11 Sesión 21 2023-2 Prueba de HipotesisDocumento47 páginasEstadística General Semana 11 Sesión 21 2023-2 Prueba de HipotesisCarolayn MelendezAún no hay calificaciones
- Introducción A Las Pruebas de HipótesisDocumento36 páginasIntroducción A Las Pruebas de HipótesisJuan Cesar Beltran Morales67% (3)
- Unidad 4 Pruebas de HipotesisDocumento22 páginasUnidad 4 Pruebas de HipotesisSalvador HeriquezAún no hay calificaciones
- UTN FRH PyE TP2021 TP8Documento9 páginasUTN FRH PyE TP2021 TP8Nehuen PuppioAún no hay calificaciones
- Docimas de Hipotesis de Una PoblacionDocumento15 páginasDocimas de Hipotesis de Una PoblacionVale SalgadoAún no hay calificaciones
- Estind01 PDFDocumento93 páginasEstind01 PDFWilliam JaimeAún no hay calificaciones
- Dócima de HipótesisDocumento8 páginasDócima de HipótesisAleMaarkAún no hay calificaciones
- Unidad III Parte 2 Docimas 2022 1Documento39 páginasUnidad III Parte 2 Docimas 2022 1valentina belenAún no hay calificaciones
- Contrastes de HipotesisDocumento11 páginasContrastes de Hipotesisherdipa5260Aún no hay calificaciones
- Tema 2 EspDocumento36 páginasTema 2 Espgiby_90Aún no hay calificaciones
- Estadistica General - Sem-11 - 2022-1Documento44 páginasEstadistica General - Sem-11 - 2022-1Stefanie GeronimoAún no hay calificaciones
- Prueba HipotesisDocumento6 páginasPrueba HipotesisJovani GutierrezAún no hay calificaciones
- S12-Hipotesis MediaDocumento27 páginasS12-Hipotesis MediaChristian RodriguezAún no hay calificaciones
- S11 HipotesisDocumento27 páginasS11 HipotesisChristian RodriguezAún no hay calificaciones
- Practica de Pruebas de Hipótesis I PDFDocumento12 páginasPractica de Pruebas de Hipótesis I PDFEzequiel MezaAún no hay calificaciones
- Mic Hipotesis PracticaDocumento66 páginasMic Hipotesis PracticaManuel JuanAún no hay calificaciones
- Prueba de HipotesisDocumento17 páginasPrueba de HipotesisKazu Diaz RaymundoAún no hay calificaciones
- Tema 8 Contrastes de HipotesisDocumento11 páginasTema 8 Contrastes de HipotesisIrwin Barrera MioAún no hay calificaciones
- Sesión 7 - Prueba de HipótesisDocumento53 páginasSesión 7 - Prueba de HipótesisSTERVER DARKSO0% (1)
- 2 5lenguajeSebastiánRengifo4aDocumento2 páginas2 5lenguajeSebastiánRengifo4aSebax RengifoAún no hay calificaciones
- 2,3 Lenguaje Sebastián Rengifo 4 ADocumento5 páginas2,3 Lenguaje Sebastián Rengifo 4 ASebax RengifoAún no hay calificaciones
- EAA1520 - 2023 - 02 - Taller R - 08 (Notas de Clase V6)Documento4 páginasEAA1520 - 2023 - 02 - Taller R - 08 (Notas de Clase V6)Sebax RengifoAún no hay calificaciones
- 2,1 Lenguaje Sebastián Rengifo 4 ADocumento5 páginas2,1 Lenguaje Sebastián Rengifo 4 ASebax RengifoAún no hay calificaciones
- 1,3 Lenguaje Sebastián Rengifo 4 ADocumento9 páginas1,3 Lenguaje Sebastián Rengifo 4 ASebax RengifoAún no hay calificaciones
- EAA1520 - 2023 - 02 - Taller R - 12Documento22 páginasEAA1520 - 2023 - 02 - Taller R - 12Sebax RengifoAún no hay calificaciones
- EAA1520 - 2023 - 02 - Taller R - 11Documento9 páginasEAA1520 - 2023 - 02 - Taller R - 11Sebax RengifoAún no hay calificaciones
- EAA1520 - 2023 - 02 - Taller R - 13Documento30 páginasEAA1520 - 2023 - 02 - Taller R - 13Sebax RengifoAún no hay calificaciones
- EAA1520 - 2023 - 02 - Taller R - 10Documento7 páginasEAA1520 - 2023 - 02 - Taller R - 10Sebax RengifoAún no hay calificaciones
- MATEMATICA - GUIA 3.valor Posicional Hasta El MillónDocumento5 páginasMATEMATICA - GUIA 3.valor Posicional Hasta El MillónBoris AllendesAún no hay calificaciones
- Grupos de Trabajo T SDocumento8 páginasGrupos de Trabajo T SIsaac Eduardo Hans Rojas RomeroAún no hay calificaciones
- Actividad Final Hipotesis-1Documento11 páginasActividad Final Hipotesis-1Karen SanchezAún no hay calificaciones
- Tarea 3 Ejecución Economia PoliticaDocumento5 páginasTarea 3 Ejecución Economia Politicamanuel carrilloAún no hay calificaciones
- Explicación Resolución 1407 de 2018Documento1 páginaExplicación Resolución 1407 de 2018DAVID HERNANDO HENAO MARULANDA100% (1)
- Cuestionario Capitulo 1-8 Mas 3Documento38 páginasCuestionario Capitulo 1-8 Mas 3evelyn moreliaAún no hay calificaciones
- Cofil Primavera2024Documento3 páginasCofil Primavera2024viborasolitariaAún no hay calificaciones
- Metodología - Silva CorvalánDocumento31 páginasMetodología - Silva CorvalánIgualita A Mi SantiagoAún no hay calificaciones
- Caso MartinDocumento2 páginasCaso MartinLinda EspaillatAún no hay calificaciones
- Semana 12Documento22 páginasSemana 12Luis Mamani BlanquilloAún no hay calificaciones
- Prevencion Muelas Abrasivas PDFDocumento164 páginasPrevencion Muelas Abrasivas PDFJorge Alberto De La Cruz LopezAún no hay calificaciones
- Sistema de LenguajesDocumento22 páginasSistema de LenguajesPaulaAún no hay calificaciones
- Evaluación Parcial de Ciencias Sociales Grado Octavo Segundo PeriodoDocumento5 páginasEvaluación Parcial de Ciencias Sociales Grado Octavo Segundo PeriodoAlex Araque Lizarazo100% (2)
- Geografía Económica TP1Documento4 páginasGeografía Económica TP1Cande BiancoAún no hay calificaciones
- Infografía Agricultura Del AñilDocumento2 páginasInfografía Agricultura Del AñilIngrid EscobarAún no hay calificaciones
- Indice de Riesgo de Victimización - Metodología 2012Documento331 páginasIndice de Riesgo de Victimización - Metodología 2012iphsAún no hay calificaciones
- IV BIM SEM 35 - EXP 9 Activ 4 Problemáticas Que Afectan Joel Condori TiconaDocumento6 páginasIV BIM SEM 35 - EXP 9 Activ 4 Problemáticas Que Afectan Joel Condori TiconaYonhy William Condori TiconaAún no hay calificaciones
- Mar Adentro ExcursionesDocumento14 páginasMar Adentro ExcursionesMayer nonalayaAún no hay calificaciones
- Actividad N° 5 Metodologia de Abordaje en Obras PatrimonialesDocumento3 páginasActividad N° 5 Metodologia de Abordaje en Obras PatrimonialesEduardo Higuera100% (1)
- Ejercicio-Identificar Programas en La ParejaDocumento1 páginaEjercicio-Identificar Programas en La ParejaVanii AizcorbeAún no hay calificaciones
- Docsity Resumen Primer Capitulo Allain Roquie Que Es America LatinaDocumento4 páginasDocsity Resumen Primer Capitulo Allain Roquie Que Es America LatinaMelina LanieriAún no hay calificaciones
- Teoria CriticaDocumento2 páginasTeoria CriticaLisbeth HuertaAún no hay calificaciones
- El Lenguaje Del CuerpoDocumento85 páginasEl Lenguaje Del CuerpoRuben RosalesAún no hay calificaciones
- 10 Consejos para Envejecer Con GraciaDocumento2 páginas10 Consejos para Envejecer Con GraciaYaneth Vivas de SandovalAún no hay calificaciones
- 1 - Introduccion A La Teoria General de Sistemas - Oscar Johansen2-LibreDocumento173 páginas1 - Introduccion A La Teoria General de Sistemas - Oscar Johansen2-Librejaime.maza5804Aún no hay calificaciones
- Cuadro Comparativo y RedaccionDocumento1 páginaCuadro Comparativo y Redacciongloria viviana herrera ochoaAún no hay calificaciones
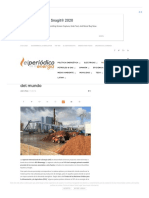
- Las 10 Mayores Plantas de Biomasa Del Mundo: Techsmith Snagit® 2020Documento9 páginasLas 10 Mayores Plantas de Biomasa Del Mundo: Techsmith Snagit® 2020ajrivera1Aún no hay calificaciones
- Ciencias SocialesDocumento1 páginaCiencias SocialesDafne Elizabeth Ríos HernándezAún no hay calificaciones
- Aspectos Generales de La Expresion OralDocumento6 páginasAspectos Generales de La Expresion OralNoiralis AponteAún no hay calificaciones
- Informe de Lectura Una Idea de Las Ciencias SocialesDocumento3 páginasInforme de Lectura Una Idea de Las Ciencias SocialesJuan Gabriel Alcántara Mateo100% (1)