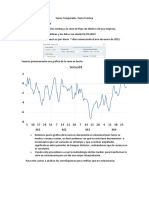
También podría gustarte
- Trabajo Final OrdinarioDocumento161 páginasTrabajo Final OrdinarioNaoAún no hay calificaciones
- Cap. 6 Regresión No Lineal NCDocumento28 páginasCap. 6 Regresión No Lineal NCana lizette lombrañaAún no hay calificaciones
- IG-102-104 Ingeniería de Confiabilidad V7 (06!04!2020)Documento165 páginasIG-102-104 Ingeniería de Confiabilidad V7 (06!04!2020)Leidy Alejandra Urquijo PastranaAún no hay calificaciones
- Diseño Unifactorial Con Covariable: Trabajo Fin de GradoDocumento35 páginasDiseño Unifactorial Con Covariable: Trabajo Fin de GradoMilagrOs Mendoza ManriqueAún no hay calificaciones
- Error de Especificación - Econometria IIDocumento5 páginasError de Especificación - Econometria IIHaruka Kumagai100% (1)
- Informe Regresion Multiple LaboratorioDocumento40 páginasInforme Regresion Multiple LaboratorioFrancisco Javier Fuentes JofréAún no hay calificaciones
- Guía de Lab Física 2Documento89 páginasGuía de Lab Física 2Ricardo CaballeroAún no hay calificaciones
- 35 Preguntas de EstadisticaDocumento12 páginas35 Preguntas de EstadisticaLilian PreciadoAún no hay calificaciones
- Resumen EconomíaDocumento16 páginasResumen EconomíaCRISTINA NICOLE CABEZAS CISNEROSAún no hay calificaciones
- Resumen Machine LearningDocumento3 páginasResumen Machine LearningNicolas PardoAún no hay calificaciones
- El Error Puro Es El Error AleatorioDocumento6 páginasEl Error Puro Es El Error AleatorioGuillermo MoralesAún no hay calificaciones
- Separata 04Documento17 páginasSeparata 04Robinson IbarraAún no hay calificaciones
- Econometria PreguntasDocumento16 páginasEconometria PreguntasHéctor D. Torres AponteAún no hay calificaciones
- Presentación Métodos Numéricos RegresiónDocumento23 páginasPresentación Métodos Numéricos RegresiónJazmin Jaramillo CorralesAún no hay calificaciones
- Ajustar Índices para El Modelado de Ecuaciones Estructurales1Documento7 páginasAjustar Índices para El Modelado de Ecuaciones Estructurales1henryAún no hay calificaciones
- Clase 12 - Guion de ClaseDocumento14 páginasClase 12 - Guion de ClaseNicolas CaminosAún no hay calificaciones
- IntroducciónDocumento13 páginasIntroducciónEdixonToroAún no hay calificaciones
- Pres DataDocumento5 páginasPres DataAdriana DonadioAún no hay calificaciones
- Goytia Fatima Problema 1Documento22 páginasGoytia Fatima Problema 1FatimaAún no hay calificaciones
- Trabajo EconometriaDocumento16 páginasTrabajo EconometriaMaldonado91Aún no hay calificaciones
- Cap 4-5 MetodosDocumento10 páginasCap 4-5 MetodosYazmin ElizondoAún no hay calificaciones
- Homework #3 - Metrics II (Adrian Tejeda)Documento11 páginasHomework #3 - Metrics II (Adrian Tejeda)Adrian TejedaAún no hay calificaciones
- Econometría Aplicada PPDocumento5 páginasEconometría Aplicada PPCarlos David Velázquez veraAún no hay calificaciones
- Modulo 3Documento6 páginasModulo 3jsdfkfdshfsdkfsAún no hay calificaciones
- ESTADISTICADocumento30 páginasESTADISTICAANGELICA RIVAS MUÑOZAún no hay calificaciones
- Trabajo Práctico N°2 2022Documento14 páginasTrabajo Práctico N°2 2022Agus GutiérrezAún no hay calificaciones
- 1er Trabajo E2-Grupo 36Documento7 páginas1er Trabajo E2-Grupo 36Pablo BlandonAún no hay calificaciones
- Invents ParcialDocumento22 páginasInvents ParcialYordy Fernando Cavero PalaciosAún no hay calificaciones
- Guia de Laboratorio DidactronDocumento27 páginasGuia de Laboratorio Didactronjose ruizAún no hay calificaciones
- Laboratorio 6 y 7 Modelos ProbabilisticosDocumento40 páginasLaboratorio 6 y 7 Modelos ProbabilisticosCristian CRAún no hay calificaciones
- Practica Econometría LabDocumento3 páginasPractica Econometría LabMari MSAún no hay calificaciones
- Pruebas de Hipótesis para Los Coeficientes de RegresiónDocumento8 páginasPruebas de Hipótesis para Los Coeficientes de RegresiónAmedaly PerezAún no hay calificaciones
- Final Bioestadística Medicina 12-06-2015 ResueltoDocumento8 páginasFinal Bioestadística Medicina 12-06-2015 ResueltoAitanaAún no hay calificaciones
- Teoria Regresión Lineal SimpleDocumento4 páginasTeoria Regresión Lineal SimpleDIABUROMON 35Aún no hay calificaciones
- JohannaCantuña P2 SeriesTemporalesDocumento9 páginasJohannaCantuña P2 SeriesTemporalesKairaChanAún no hay calificaciones
- Práctica 10 DAT IIDocumento3 páginasPráctica 10 DAT IIMaica Mendívil MartínezAún no hay calificaciones
- Rls. McoDocumento40 páginasRls. McoAbi LeguizamonAún no hay calificaciones
- TP DistriDocumento9 páginasTP DistriFelipe GutierrezAún no hay calificaciones
- Tarea 4 Aplicada IIDocumento6 páginasTarea 4 Aplicada IIVictoria PerdomoAún no hay calificaciones
- Avance de Clases 4ta. y 5ta Semana.Documento23 páginasAvance de Clases 4ta. y 5ta Semana.Maria Mendoza GonzalesAún no hay calificaciones
- Metodos - de - Regularizacion - y - Seleccion - Del - Mejor - Modelo - (Subset - Selection, - Ridge Regression, - Lasso, - PCA, - PCR, - PLS) PDFDocumento30 páginasMetodos - de - Regularizacion - y - Seleccion - Del - Mejor - Modelo - (Subset - Selection, - Ridge Regression, - Lasso, - PCA, - PCR, - PLS) PDFsalinastalamillaAún no hay calificaciones
- Hechos Clave 4Documento2 páginasHechos Clave 4Estefania CuartoSemestreAún no hay calificaciones
- Actividad 1 Contraste de Hipótesis Media Muestral BilateralDocumento6 páginasActividad 1 Contraste de Hipótesis Media Muestral BilateralwilgAún no hay calificaciones
- Regresión Lineal MúltipleDocumento14 páginasRegresión Lineal MúltipleRoberto GarcíaAún no hay calificaciones
- Curso Six Sigma 131 156Documento26 páginasCurso Six Sigma 131 156nubousoAún no hay calificaciones
- Cap. 6 Regresión No Lineal NCDocumento28 páginasCap. 6 Regresión No Lineal NCana lizette lombrañaAún no hay calificaciones
- Supuestos de ModelosDocumento9 páginasSupuestos de ModelosStefany De Los AngelesAún no hay calificaciones
- Modelos LinealesDocumento14 páginasModelos LinealesFernanda AlbánAún no hay calificaciones
- AutocorrelaciónDocumento5 páginasAutocorrelaciónPadawan De WookieeAún no hay calificaciones
- Minimos CuadradosDocumento15 páginasMinimos CuadradosKarla Esther Pérez ColánAún no hay calificaciones
- Sesión 15.1Documento41 páginasSesión 15.1Luigi ItaloAún no hay calificaciones
- RLM. InferenciaDocumento23 páginasRLM. InferenciaAbi LeguizamonAún no hay calificaciones
- Modelos Lineales Con RDocumento22 páginasModelos Lineales Con RVictor GarroAún no hay calificaciones
- Sesión 03 PDFDocumento38 páginasSesión 03 PDFHermanos Julcamoro CortezAún no hay calificaciones
- Supuestos de Violacion de ModeloDocumento5 páginasSupuestos de Violacion de ModeloManuel DiosAún no hay calificaciones
- Guía Práctica No 2Documento6 páginasGuía Práctica No 2Allison ArévaloAún no hay calificaciones
- Resumen Capitulo 15Documento11 páginasResumen Capitulo 15Eycol Gianpier Aguilar BuenoAún no hay calificaciones
- Análisis de Asociación y Correlación Entre Dos VariablesDocumento34 páginasAnálisis de Asociación y Correlación Entre Dos VariablesMichelle GonzalesAún no hay calificaciones
- Coeficiente de VariaciónDocumento5 páginasCoeficiente de VariaciónPaola Custodio GonzalesAún no hay calificaciones
- Regresion No Lineal y LogisticaDocumento15 páginasRegresion No Lineal y LogisticainGNOSYS IngenieriaAún no hay calificaciones
- Trabajo Final de EconometríaDocumento9 páginasTrabajo Final de EconometríaJose Rodolfo Huaraca QuispeAún no hay calificaciones
- Consenso de muestra aleatoria: Estimación robusta en visión por computadoraDe EverandConsenso de muestra aleatoria: Estimación robusta en visión por computadoraAún no hay calificaciones
- Plantilla Queueing Model - TALLER - ClaseDocumento9 páginasPlantilla Queueing Model - TALLER - ClaseRoberto Jhanfranco Coaquira LastarriaAún no hay calificaciones
- Importancia de Cuidar Nuestro BienestarDocumento1 páginaImportancia de Cuidar Nuestro BienestarRoberto Jhanfranco Coaquira LastarriaAún no hay calificaciones
- Avance Total de Objetivo de Ventas enDocumento1 páginaAvance Total de Objetivo de Ventas enRoberto Jhanfranco Coaquira LastarriaAún no hay calificaciones
- Circular #021-2023RLC (PTDocumento3 páginasCircular #021-2023RLC (PTRoberto Jhanfranco Coaquira LastarriaAún no hay calificaciones
- Analisis GloriaDocumento8 páginasAnalisis GloriaRoberto Jhanfranco Coaquira LastarriaAún no hay calificaciones
- Guia 4 Regresion LinealDocumento7 páginasGuia 4 Regresion LinealGioman100% (2)
- Trabajo - Casi FinalDocumento52 páginasTrabajo - Casi FinalNils RodriguezAún no hay calificaciones
- Clases de RugosidadDocumento69 páginasClases de RugosidadAlejandro Lopez Zamudio50% (2)
- IntroducciónDocumento10 páginasIntroducciónnoe telonAún no hay calificaciones
- Resumen EconometrïaDocumento204 páginasResumen EconometrïaA Ga PiAún no hay calificaciones
- Fundamentos de Fluidos y Termodinámica (Guias de Practicas de Laboratorios Completa) - 1Documento125 páginasFundamentos de Fluidos y Termodinámica (Guias de Practicas de Laboratorios Completa) - 1DIANA PAJOYAún no hay calificaciones
- Reporte Regresion Lineal Simple Por Minimos CuadradosDocumento13 páginasReporte Regresion Lineal Simple Por Minimos CuadradosAlfredo Avendaño SerranoAún no hay calificaciones
- Evaluacion ContinuaDocumento19 páginasEvaluacion ContinuaDChicañaAún no hay calificaciones
- Regresión Lineal Simple y MultipleDocumento3 páginasRegresión Lineal Simple y MultipleAntonio ArceAún no hay calificaciones
- Método GraficoDocumento14 páginasMétodo GraficogregorioAún no hay calificaciones
- Informe de GeorreferenciacionDocumento64 páginasInforme de GeorreferenciacionYohany DOAún no hay calificaciones
- Trabajo (3) Modelos de Regresion-CuadráticaDocumento22 páginasTrabajo (3) Modelos de Regresion-CuadráticaPedro EspinozaAún no hay calificaciones
- Correlacion y Regresion Lineal Con EnlaceDocumento15 páginasCorrelacion y Regresion Lineal Con EnlaceIreneAún no hay calificaciones
- Regresion PolinomialDocumento16 páginasRegresion PolinomialDarling L. ClavijoAún no hay calificaciones
- Captulo VIIIDiagramadispersionDocumento20 páginasCaptulo VIIIDiagramadispersionyessi tamayoAún no hay calificaciones
- Proceso de Análisis EstructuralDocumento9 páginasProceso de Análisis EstructuralPaola Robles VásquezAún no hay calificaciones
- Actividad 2 Alejandra SernaDocumento8 páginasActividad 2 Alejandra SernaFabian TruqueAún no hay calificaciones
- Gomez Pedreros Tarea 3 Ing EconomicaDocumento9 páginasGomez Pedreros Tarea 3 Ing EconomicaMario SantiagoAún no hay calificaciones
- Revista Eco 11 DigitalDocumento116 páginasRevista Eco 11 DigitalVicky RamirezAún no hay calificaciones
- Módulo IV Modelos de RegresiónDocumento16 páginasMódulo IV Modelos de RegresiónDiego Armando Ramirez HernandezAún no hay calificaciones
- Tema 2Documento59 páginasTema 2Susana González RuizAún no hay calificaciones
- 003 Procedimiento Colocado Pares Geodesicos Rev. 0 - 1Documento8 páginas003 Procedimiento Colocado Pares Geodesicos Rev. 0 - 1JUAN CHOQUECARDENASAún no hay calificaciones
- ORTOGONALIDADDocumento27 páginasORTOGONALIDADPedroAún no hay calificaciones
- Poblacion Futura - MetodosDocumento10 páginasPoblacion Futura - MetodosedisonAún no hay calificaciones