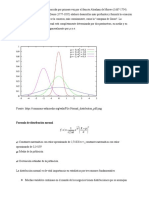
También podría gustarte
- Teorema de ChebyshevpdfDocumento9 páginasTeorema de ChebyshevpdfJosé Daniel Lopez100% (1)
- 2.4.1 S Distribuciones Continuas de ProbabilidadDocumento7 páginas2.4.1 S Distribuciones Continuas de ProbabilidadJassiel Eduardo Olivas HidalgoAún no hay calificaciones
- Trabajo Distribucion NormalDocumento9 páginasTrabajo Distribucion NormalGeiner Romero ZapataAún no hay calificaciones
- Sintesis de InfanciasDocumento8 páginasSintesis de Infanciasyenny torres100% (2)
- Apunte 9: Teoría Del Límite Central, Distribuciones MuestralesDocumento17 páginasApunte 9: Teoría Del Límite Central, Distribuciones Muestralesmatoto21Aún no hay calificaciones
- Texto Base de La Unidad 1Documento35 páginasTexto Base de La Unidad 1Jhonny Chambi MollericonaAún no hay calificaciones
- Unidad1 Paso2 Grupo551112 1Documento51 páginasUnidad1 Paso2 Grupo551112 1Flor Yadira Moreno GarzonAún no hay calificaciones
- Funciones de Distribucion de Probabilidad y Funciones de Densidad de ProbabilidadDocumento5 páginasFunciones de Distribucion de Probabilidad y Funciones de Densidad de ProbabilidadAbi TorresAún no hay calificaciones
- Sesion 8Documento0 páginasSesion 8jaime3quispe3vicenteAún no hay calificaciones
- Distribuciones de Probabilidad para Variables Aleatorias Continuas EstadisticasDocumento10 páginasDistribuciones de Probabilidad para Variables Aleatorias Continuas EstadisticasCesar Vega EscobedoAún no hay calificaciones
- 2 Distribución Normal y MuestreoDocumento54 páginas2 Distribución Normal y MuestreoKatherine Álvarez100% (1)
- 2 Medidas de Resumen de Una DistribuciónDocumento32 páginas2 Medidas de Resumen de Una DistribuciónEstefany CutipaAún no hay calificaciones
- 6 - Aea6947 - Cn°3 - Apunte AcademicoDocumento8 páginas6 - Aea6947 - Cn°3 - Apunte Academiconacho munozAún no hay calificaciones
- Tarea de Estadista Distribución de ProbabilidadesDocumento25 páginasTarea de Estadista Distribución de Probabilidadesam22039Aún no hay calificaciones
- Tema 3.1 Introduccion A La Estadistica Inferencial4 DistribuciónDocumento25 páginasTema 3.1 Introduccion A La Estadistica Inferencial4 DistribuciónMARIA TERESA COLMENAREZAún no hay calificaciones
- Concepto de Distribucion de ProbabilidadDocumento14 páginasConcepto de Distribucion de ProbabilidadToño PalominoAún no hay calificaciones
- Tema 11-12 Inferencia Estadistica Ccss IIDocumento29 páginasTema 11-12 Inferencia Estadistica Ccss IItoya123Aún no hay calificaciones
- La Distribución NormalDocumento3 páginasLa Distribución NormalAura GabrielaAún no hay calificaciones
- Repaso Estadistico 2da DiapoDocumento10 páginasRepaso Estadistico 2da DiapoAdamaris PinedoAún no hay calificaciones
- Centro Universitario de Ciencias Biológicas y Agropecuarias 3Documento8 páginasCentro Universitario de Ciencias Biológicas y Agropecuarias 3Gustavo MartinezAún no hay calificaciones
- Trabajo Completo EstadisticaDocumento27 páginasTrabajo Completo EstadisticaAnonymous 1SOmTklOVAún no hay calificaciones
- Tema 6 Distribuciones de Probabilidad ContinuaDocumento23 páginasTema 6 Distribuciones de Probabilidad ContinuaAlberto RuizAún no hay calificaciones
- Edier A Azofeifa Rodríguez Reporte de Teleclase IDocumento9 páginasEdier A Azofeifa Rodríguez Reporte de Teleclase IEdier Azofeifa RodríguezAún no hay calificaciones
- Distribución NormalDocumento16 páginasDistribución NormalNICKOL STEFANY GALLARDO CAMACHOAún no hay calificaciones
- ESTADISTICADocumento7 páginasESTADISTICARavago Camacho America MichellAún no hay calificaciones
- Medidas de FormaDocumento10 páginasMedidas de FormaDAVID ENRIQUE TORRES GONZALEZAún no hay calificaciones
- Distribucion de Probabilidad NormalDocumento18 páginasDistribucion de Probabilidad Normalluaxd.comAún no hay calificaciones
- Paso 4 de La Fase 1Documento7 páginasPaso 4 de La Fase 1Jhonatan Ortiz CastroAún no hay calificaciones
- LNS Black BeltDocumento126 páginasLNS Black BeltMariana Bravo GonzalezAún no hay calificaciones
- Distribucion Normal - EstadisticaDocumento16 páginasDistribucion Normal - EstadisticaPaola RoseroAún no hay calificaciones
- Clase 1 EstadísticaDocumento19 páginasClase 1 EstadísticaLamonega Milena RocioAún no hay calificaciones
- Aporte de Inf. EstadisticaDocumento9 páginasAporte de Inf. Estadisticajose cantilloAún no hay calificaciones
- Medidas de DispersiónDocumento26 páginasMedidas de DispersiónJosé Arturo HenriquezAún no hay calificaciones
- GuerraJosmary - Unidad 3Documento13 páginasGuerraJosmary - Unidad 3JosmaryAún no hay calificaciones
- Asimetría y KurtosisDocumento6 páginasAsimetría y KurtosisBrayan LlanosAún no hay calificaciones
- Resumen Capitulo 7Documento5 páginasResumen Capitulo 7Luis José Rodríguez PérezAún no hay calificaciones
- Esp U1 A1 MascDocumento6 páginasEsp U1 A1 MascEnrique FoyoAún no hay calificaciones
- TTvr3Ysy7tcIvPUidt8i 2Documento9 páginasTTvr3Ysy7tcIvPUidt8i 2EDGAR GAEL RIVERA ESPINOZAAún no hay calificaciones
- 10 NormalDocumento25 páginas10 NormalBranco Palma RodriguezAún no hay calificaciones
- Asimetria y CurtosisDocumento6 páginasAsimetria y CurtosisJeimer Abel Jimenez EscobarAún no hay calificaciones
- Unidad 5 - Curva Normal, Correlación Lineal y Regresión LinealDocumento29 páginasUnidad 5 - Curva Normal, Correlación Lineal y Regresión LinealPicciola Julio NicolásAún no hay calificaciones
- Curvas de DistribucionDocumento7 páginasCurvas de DistribucionAndrés FernándezAún no hay calificaciones
- Distribucion NormalDocumento13 páginasDistribucion NormalrodrigoAún no hay calificaciones
- Medidas de Sesgo y CurtosisDocumento7 páginasMedidas de Sesgo y CurtosisDany RubioAún no hay calificaciones
- Probabilidades EstadisticaDocumento17 páginasProbabilidades EstadisticaFran SillaAún no hay calificaciones
- Teorema Del Límite CentralDocumento3 páginasTeorema Del Límite Centralalex cabreraAún no hay calificaciones
- Estadística-Multivariada (Analisis de Una Variable) 2019Documento17 páginasEstadística-Multivariada (Analisis de Una Variable) 2019Valería GarcíaAún no hay calificaciones
- Hidrología EstadisticaDocumento16 páginasHidrología Estadisticadibuchobonifacio2013Aún no hay calificaciones
- EnsayoDocumento5 páginasEnsayoAngelAún no hay calificaciones
- Yaramsie - 2. Introducción A Distribuciones Muestrales.Documento36 páginasYaramsie - 2. Introducción A Distribuciones Muestrales.Diana cardonaAún no hay calificaciones
- Practica 8Documento16 páginasPractica 8Freddy GuerreroAún no hay calificaciones
- Estadística DescriptivaDocumento5 páginasEstadística DescriptivaHenry MistAún no hay calificaciones
- Consultas ProbabilidadDocumento3 páginasConsultas ProbabilidadPipe GonzalezAún no hay calificaciones
- Estadística InferencialDocumento8 páginasEstadística InferencialEDISON ALEXANDER PALOMO ALLAUCAAún no hay calificaciones
- Distribucion Normal JDocumento10 páginasDistribucion Normal JPablo Ramirez MendozaAún no hay calificaciones
- Distribuciónes Probabilistacas Continuas.Documento5 páginasDistribuciónes Probabilistacas Continuas.Maria HernandezAún no hay calificaciones
- La Distribución NormalDocumento45 páginasLa Distribución NormalTrevor DixonAún no hay calificaciones
- Prueba de ShapiroDocumento4 páginasPrueba de ShapirocharlyerealesAún no hay calificaciones
- Cálculo Del Punto de Pedido Cuando La Demanda Es AleatoriaDocumento6 páginasCálculo Del Punto de Pedido Cuando La Demanda Es AleatoriaantonorosaAún no hay calificaciones
- Nomina Del 01 Al 15 de Octubre de 2023-SerDocumento8 páginasNomina Del 01 Al 15 de Octubre de 2023-SerVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Examen MKTDocumento3 páginasExamen MKTVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Práctica 4Documento2 páginasPráctica 41aalumno1Aún no hay calificaciones
- Plan Estrategico RH 2015 - 2018Documento28 páginasPlan Estrategico RH 2015 - 2018Victoria Stephania Hinojosa GarridoAún no hay calificaciones
- Nomina Del 16 Al 31 de Septiembre de 2023-SerDocumento8 páginasNomina Del 16 Al 31 de Septiembre de 2023-SerVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Nomina Siglo Xxi 2023Documento21 páginasNomina Siglo Xxi 2023Victoria Stephania Hinojosa GarridoAún no hay calificaciones
- Práctica 4Documento2 páginasPráctica 41aalumno1Aún no hay calificaciones
- Tecnología Limpia PDFDocumento1 páginaTecnología Limpia PDFJose Guadalupe Valdes AvilesAún no hay calificaciones
- ANUALIDAD Ant, COSTO27-VIII-22 UNIMEC MAT FINDocumento2 páginasANUALIDAD Ant, COSTO27-VIII-22 UNIMEC MAT FINVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- UNIDAD I Introduccion A La EconomiaDocumento2 páginasUNIDAD I Introduccion A La EconomiaVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Resumen 6Documento3 páginasResumen 6Victoria Stephania Hinojosa GarridoAún no hay calificaciones
- Amortización 27-Viii-22 UnimecDocumento8 páginasAmortización 27-Viii-22 UnimecVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Examen ContaDocumento1 páginaExamen ContaVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Manual de Organizacion AgrofuturaDocumento67 páginasManual de Organizacion AgrofuturaVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Inicio: Si NoDocumento1 páginaInicio: Si NoVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Lineamientos - Proceso AdministrativoDocumento1 páginaLineamientos - Proceso AdministrativoVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- GUIA MicroeconomíaDocumento1 páginaGUIA MicroeconomíaVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Ejemplos de Empresas ParaestatalesDocumento3 páginasEjemplos de Empresas ParaestatalesVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Consejo, Comite y ComisiónDocumento3 páginasConsejo, Comite y ComisiónVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Politicas y ProgramasDocumento3 páginasPoliticas y ProgramasVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Ficha Descriptiva - Del Grado y Grupo " - "Documento2 páginasFicha Descriptiva - Del Grado y Grupo " - "Victoria Stephania Hinojosa GarridoAún no hay calificaciones
- Articulos Examen ContaDocumento7 páginasArticulos Examen ContaVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Bloque 3Documento4 páginasBloque 3Victoria Stephania Hinojosa GarridoAún no hay calificaciones
- Centro Universitario ImecDocumento2 páginasCentro Universitario ImecVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Tarea Ingeniería ConstDocumento4 páginasTarea Ingeniería ConstVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Reporte VideoDocumento3 páginasReporte VideoVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Contrato de Joint VentureDocumento8 páginasContrato de Joint VentureVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Centro de DevolucionesDocumento3 páginasCentro de DevolucionesVictoria Stephania Hinojosa GarridoAún no hay calificaciones
- Tarea 6Documento4 páginasTarea 6Victoria Stephania Hinojosa GarridoAún no hay calificaciones
- Solicito Respuesta y Aclaracion A La Carta #068-2020-Wec - IcDocumento2 páginasSolicito Respuesta y Aclaracion A La Carta #068-2020-Wec - IcJose SotoAún no hay calificaciones
- Escuela NeoclasistaDocumento14 páginasEscuela Neoclasistahugo sotoAún no hay calificaciones
- GrafiasDocumento25 páginasGrafiasErika BarraganAún no hay calificaciones
- Informe Estadística, Data PokemonDocumento14 páginasInforme Estadística, Data PokemonChristian NarvaezAún no hay calificaciones
- LosgenesdelamemoriaDocumento135 páginasLosgenesdelamemoriaSantiago ArcilaAún no hay calificaciones
- Conociendo Mis EmocionesDocumento30 páginasConociendo Mis EmocionesJoe KugeAún no hay calificaciones
- M5 - Multiplicación NaturalesDocumento3 páginasM5 - Multiplicación NaturalesYani VidelaAún no hay calificaciones
- Guía de Aprendizaje Nº1Documento24 páginasGuía de Aprendizaje Nº1Marvin Dianthony Silva RiosAún no hay calificaciones
- Exposición - Norma Británica BS 3811Documento2 páginasExposición - Norma Británica BS 3811jesusx7422Aún no hay calificaciones
- 01 Formato de Prueba de Hidraulica 1Documento10 páginas01 Formato de Prueba de Hidraulica 1April JansonAún no hay calificaciones
- Luis Antonio Tamariz RamirezDocumento2 páginasLuis Antonio Tamariz RamirezCris KrisAún no hay calificaciones
- Inyeccion DieselDocumento6 páginasInyeccion DieseledelmolinaAún no hay calificaciones
- Castrol Hyspin ZZ 32 ES PDFDocumento12 páginasCastrol Hyspin ZZ 32 ES PDFDieudonne Yannick Martinez ViteAún no hay calificaciones
- UDI TP Fernandez MansillaDocumento10 páginasUDI TP Fernandez MansillaJohana Belen NiñoAún no hay calificaciones
- Actividad 2Documento5 páginasActividad 2Leon VásquezAún no hay calificaciones
- Sobre La Búsqueda de La Verdad - Nicolás de MalebrancheDocumento10 páginasSobre La Búsqueda de La Verdad - Nicolás de MalebrancheGermán LizcanoAún no hay calificaciones
- Tipos de AtenciónDocumento1 páginaTipos de AtenciónYerica GalvanAún no hay calificaciones
- Iqi-041e-Paucarchuco Castillo Ricardo Wilder PDFDocumento7 páginasIqi-041e-Paucarchuco Castillo Ricardo Wilder PDFErick Gómez RomeroAún no hay calificaciones
- Estudio Topografico Av. Garcilazo y Jr. San MartinDocumento33 páginasEstudio Topografico Av. Garcilazo y Jr. San MartinEsau Cabanillas CristobalAún no hay calificaciones
- Anexos 315Documento9 páginasAnexos 315Daniel Osvaldo Tubac RiveraAún no hay calificaciones
- INTELIGENCIADocumento2 páginasINTELIGENCIAluis gabrielAún no hay calificaciones
- Consecuencias (RSE)Documento2 páginasConsecuencias (RSE)Yeslin Eunice García AlvarezAún no hay calificaciones
- Varsol o Disolvente StoddardDocumento10 páginasVarsol o Disolvente StoddardJuan Carlos RojasAún no hay calificaciones
- TrifolioDocumento3 páginasTrifolioAndrea OrtizAún no hay calificaciones
- Frecuencia - Tarea 2 de Autoamtizacion y ElectricaDocumento5 páginasFrecuencia - Tarea 2 de Autoamtizacion y ElectricaSandra MaribelAún no hay calificaciones
- Simulado 3 MUEDocumento11 páginasSimulado 3 MUESebastianAún no hay calificaciones
- Tratamientos de Sindrome de Down PorDocumento22 páginasTratamientos de Sindrome de Down PorCésar MéndezAún no hay calificaciones
- Golpe de Ariete en Estaciones de BombeoDocumento5 páginasGolpe de Ariete en Estaciones de BombeoDelia Yakelen Huamani CcalloAún no hay calificaciones
- Análisis Mate ECO Tutorías 1º Cuatrimestre 2021Documento3 páginasAnálisis Mate ECO Tutorías 1º Cuatrimestre 2021Pepe Le PeuAún no hay calificaciones