También podría gustarte
- UC3 Analisis Rendimiento ParaleloDocumento4 páginasUC3 Analisis Rendimiento Paraleloalfredo marot100% (1)
- Matlab - Generación de Señales Continuas y DiscretasDocumento8 páginasMatlab - Generación de Señales Continuas y DiscretasOswaldo R. Lopez BaronAún no hay calificaciones
- Algoritmos y Estructuras de Datos IIIDocumento4 páginasAlgoritmos y Estructuras de Datos IIIJorge UriarteAún no hay calificaciones
- La Guía Definitiva en Matemáticas para el Ingreso a la UniversidadDe EverandLa Guía Definitiva en Matemáticas para el Ingreso a la UniversidadCalificación: 4 de 5 estrellas4/5 (11)
- Vida y Obra Del Compositor Colombiano Efraín OrozcoDocumento23 páginasVida y Obra Del Compositor Colombiano Efraín OrozcoAriel NaviaAún no hay calificaciones
- OMPDocumento22 páginasOMPJorge Díaz NavarroAún no hay calificaciones
- Examenes PasadosDocumento30 páginasExamenes PasadosSanti A SecasAún no hay calificaciones
- Computación ParalelaDocumento5 páginasComputación ParalelaKeyzan 7Aún no hay calificaciones
- Introduccion Al Diseño de Curvas Por OrdenadorDocumento13 páginasIntroduccion Al Diseño de Curvas Por OrdenadorRoger Lazaro CruzAún no hay calificaciones
- Examen 1Documento2 páginasExamen 1arturoclAún no hay calificaciones
- Solución Ecuaciones de RecurrenciaDocumento9 páginasSolución Ecuaciones de RecurrenciaJuan Pablo Faundez RoldanAún no hay calificaciones
- 04 AlgComp Tarea04 V2Documento6 páginas04 AlgComp Tarea04 V2Doris GonzalezAún no hay calificaciones
- Ejerc1 2Documento18 páginasEjerc1 2José LuisAún no hay calificaciones
- OE y Mejor - Peor - y - Caso - MedioDocumento6 páginasOE y Mejor - Peor - y - Caso - MedioJairo M-MuñozAún no hay calificaciones
- Ejercicios y Estructura de Datos PDFDocumento17 páginasEjercicios y Estructura de Datos PDFAlder Friederich Yacila EspinozaAún no hay calificaciones
- Tema2 TransparenciasDocumento107 páginasTema2 Transparenciastsuru108Aún no hay calificaciones
- 2P 2022 SolDocumento4 páginas2P 2022 SolKeyzan 7Aún no hay calificaciones
- Introduction ToDocumento15 páginasIntroduction ToLuisMiguelVillegasSantamaria100% (1)
- Lab 1 ModelamientoDocumento13 páginasLab 1 ModelamientoC Carlos100% (1)
- Practica para El Uso de MATLABDocumento10 páginasPractica para El Uso de MATLABDaniel MirandaAún no hay calificaciones
- Tarea1 WilderDocumento6 páginasTarea1 WilderWilder Gonzalez DiazAún no hay calificaciones
- Certamen 1 ELO-321 Parte 1: Profesor: Mauricio Araya 13 de Octubre Del 2022Documento2 páginasCertamen 1 ELO-321 Parte 1: Profesor: Mauricio Araya 13 de Octubre Del 2022Jorge Magaña NúñezAún no hay calificaciones
- Fundametos de La InformáticaDocumento8 páginasFundametos de La InformáticathaliaAún no hay calificaciones
- Informe 1Documento32 páginasInforme 1CarlaMuñozPescoránAún no hay calificaciones
- 1 EjerciciosTema1Documento3 páginas1 EjerciciosTema1foillassafrecei-9343Aún no hay calificaciones
- 66 Problemas Resueltos de Análisis y Diseño de AlgoritmosDocumento82 páginas66 Problemas Resueltos de Análisis y Diseño de AlgoritmosLaenetGalumetteJosephJuniorPaulAún no hay calificaciones
- Laboratorio 2 SeñalesDocumento9 páginasLaboratorio 2 SeñalesALEJANDRO NAVARRETE ROJASAún no hay calificaciones
- Ejercicios Basicos (Bucles y Arrays)Documento5 páginasEjercicios Basicos (Bucles y Arrays)Conxin Sanfelix AlfonsoAún no hay calificaciones
- Practica 1 Generación y Graficación de Señales Continuas y DiscretasDocumento4 páginasPractica 1 Generación y Graficación de Señales Continuas y DiscretasAnndy BarraganAún no hay calificaciones
- TP1 Algoritmos Generales2018Documento10 páginasTP1 Algoritmos Generales2018fernando100% (1)
- Ipython E.DDocumento41 páginasIpython E.DCristian Brian ALMARAZ ROCHAAún no hay calificaciones
- Practica OMPDocumento10 páginasPractica OMPander_cid_rivasAún no hay calificaciones
- Practica 3 Transformadas Discretas Con Aplicaciones Al Procesamiento de Señales - Jupyter NotebookDocumento9 páginasPractica 3 Transformadas Discretas Con Aplicaciones Al Procesamiento de Señales - Jupyter Notebookgiovany.almeidaAún no hay calificaciones
- Julio2016 SolDocumento4 páginasJulio2016 SolJerónimoLisónAún no hay calificaciones
- Taller 1 Octave-2022Documento4 páginasTaller 1 Octave-2022Jovanis Gamero AAún no hay calificaciones
- ProcesosDocumento5 páginasProcesosPencitaAún no hay calificaciones
- MemoriaDocumento12 páginasMemoriaHouman RezakhanlouAún no hay calificaciones
- c1 Elo321 p1 PAUTADocumento4 páginasc1 Elo321 p1 PAUTAJorge Magaña NúñezAún no hay calificaciones
- 95.12 Algoritmos y Programación II 1. Arboles BinariosDocumento5 páginas95.12 Algoritmos y Programación II 1. Arboles BinariosPaloma Paloma GMAún no hay calificaciones
- PROGRAMACIONDocumento22 páginasPROGRAMACIONEsmeralda GuerreroAún no hay calificaciones
- Tarea 7Documento7 páginasTarea 7Tuto ZimmermannAún no hay calificaciones
- Ejercicios Analisis de AlgoritmosDocumento16 páginasEjercicios Analisis de AlgoritmosKarem VázquezAún no hay calificaciones
- Polinomio Cubico Generador de TrayectoriasDocumento4 páginasPolinomio Cubico Generador de TrayectoriasArgenys MoralesAún no hay calificaciones
- probsAnalAlg 2021Documento22 páginasprobsAnalAlg 2021Yaser JafarAún no hay calificaciones
- ScriptsDocumento5 páginasScriptsIvan Jahuira CervantesAún no hay calificaciones
- Informe - Tema 01Documento36 páginasInforme - Tema 01Raul Depaz NuñezAún no hay calificaciones
- Ejercicios 2006 ComplexDocumento47 páginasEjercicios 2006 ComplexGiovanni Malatesta0% (1)
- AyP2 - Gu°a de Problemas PDFDocumento17 páginasAyP2 - Gu°a de Problemas PDFLuis Carlos Somoza LedezmaAún no hay calificaciones
- Deber Métodos NuméricosDocumento3 páginasDeber Métodos NuméricosChristian Galarza CruzAún no hay calificaciones
- Ejercicios TipoParcial2y3Documento24 páginasEjercicios TipoParcial2y3EErnesto HernándezAún no hay calificaciones
- Examen R1 PDocumento3 páginasExamen R1 PLaraAún no hay calificaciones
- Practica 2.1Documento9 páginasPractica 2.1Moreno Reyes Eduardo MartinAún no hay calificaciones
- Uso Del Octave en FísicaDocumento5 páginasUso Del Octave en FísicaJose Luis Manso LoredoAún no hay calificaciones
- Guias de Metodos NumericosDocumento14 páginasGuias de Metodos NumericosLuis Diaz RodriguezAún no hay calificaciones
- S&S P1lu 20172Documento1 páginaS&S P1lu 20172JuanPajueloChipanaAún no hay calificaciones
- Eliminación de líneas ocultas: Revelando lo invisible: secretos de la visión por computadoraDe EverandEliminación de líneas ocultas: Revelando lo invisible: secretos de la visión por computadoraAún no hay calificaciones
- Matplotlib, Introducción a la Visualización 2D, Parte IIDe EverandMatplotlib, Introducción a la Visualización 2D, Parte IIAún no hay calificaciones
- NMX-AA - 047 Determinacion de MercurioDocumento4 páginasNMX-AA - 047 Determinacion de MercuriorrollerAún no hay calificaciones
- Preguntas 1 A La 5Documento5 páginasPreguntas 1 A La 5Jaime Esteban Opazo OpazoAún no hay calificaciones
- Informe #4. Superficies Equipotenciales y Líneas de Campo eléctrico.M2BDocumento6 páginasInforme #4. Superficies Equipotenciales y Líneas de Campo eléctrico.M2BArteta Alvarez Daniel EstebanAún no hay calificaciones
- Catalogo de CuentasDocumento13 páginasCatalogo de CuentasGeidi VelezAún no hay calificaciones
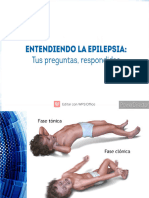
- 1 Convulsion 11Documento22 páginas1 Convulsion 11Judith ArandanosAún no hay calificaciones
- PPT. Region Cabeza - Osteología - PRACTICADocumento33 páginasPPT. Region Cabeza - Osteología - PRACTICAAlice MaldonadoAún no hay calificaciones
- Smart-UPS en Línea - SRT1000XLIDocumento4 páginasSmart-UPS en Línea - SRT1000XLIFernando JoseAún no hay calificaciones
- Hacer Una Paya SeñoresDocumento1 páginaHacer Una Paya SeñoresBrad WillisAún no hay calificaciones
- Tarea 2 - Ing - Sismorresistente-20192Documento2 páginasTarea 2 - Ing - Sismorresistente-20192RonaldAún no hay calificaciones
- Tabata Mendoza Aparato Reproductor en MamiferosDocumento21 páginasTabata Mendoza Aparato Reproductor en MamiferosTabhita MendozaAún no hay calificaciones
- Ficha Técnica Centro de Fuerza y CombateDocumento15 páginasFicha Técnica Centro de Fuerza y CombateArturo Aguilar RamirezAún no hay calificaciones
- M4 U1 S1 IntegradoraDocumento7 páginasM4 U1 S1 Integradoraminerva sanchezAún no hay calificaciones
- Actividad Peligro y Riesgo Salud OcupacionalDocumento10 páginasActividad Peligro y Riesgo Salud OcupacionalJose RodriguezAún no hay calificaciones
- UT2. Sistemas de Aprendizaje Automático (Machine Learning)Documento48 páginasUT2. Sistemas de Aprendizaje Automático (Machine Learning)russellAún no hay calificaciones
- N° 021 Pets Inspección Preoperativo de Equipos de Flotación de MolibdenoDocumento10 páginasN° 021 Pets Inspección Preoperativo de Equipos de Flotación de MolibdenoMarco A. MirandaAún no hay calificaciones
- Informe GPSDocumento9 páginasInforme GPSAngelica RiveraAún no hay calificaciones
- Herramientas Ingenieria IndustrialDocumento8 páginasHerramientas Ingenieria IndustrialScm PaqueteriaAún no hay calificaciones
- Cuaderno - de - Informes - #13 - Juan Daniel EstradaDocumento14 páginasCuaderno - de - Informes - #13 - Juan Daniel EstradaJose EstradaAún no hay calificaciones
- El Homenaje en Jardines y Parques EscultDocumento228 páginasEl Homenaje en Jardines y Parques EscultMaría Elena Masís MuñozAún no hay calificaciones
- FilogenómicaDocumento4 páginasFilogenómicaVanessa Cruz CondoriAún no hay calificaciones
- Economia de Los Paises de CentroamericaDocumento3 páginasEconomia de Los Paises de CentroamericaAriel CabreraAún no hay calificaciones
- Cartera de Proyectos para EndeudamientoDocumento64 páginasCartera de Proyectos para EndeudamientoOrlando Llaya WongAún no hay calificaciones
- Actividad 4 SS ADJMGDocumento6 páginasActividad 4 SS ADJMGArturo De Jesus MedinaAún no hay calificaciones
- Protocolo de Toma CitologiaDocumento9 páginasProtocolo de Toma CitologiaZairaAún no hay calificaciones
- BIOQUIMICAII GRUPO Enf - HersDocumento9 páginasBIOQUIMICAII GRUPO Enf - HersWily Oviedo CarpioAún no hay calificaciones
- Informe Del Abono OrganicoDocumento5 páginasInforme Del Abono OrganicoAlejandro Pony SalvajeAún no hay calificaciones
- Primer Grado Lecto Esctitura Exclusivo Ma CA 1Documento246 páginasPrimer Grado Lecto Esctitura Exclusivo Ma CA 1Lady RinconAún no hay calificaciones
- Mue2306260002-Cesar Humberto Rosales PerezDocumento2 páginasMue2306260002-Cesar Humberto Rosales PerezCarmen PeñaAún no hay calificaciones
- Pendiente DeflexionDocumento20 páginasPendiente DeflexionRicardoAún no hay calificaciones