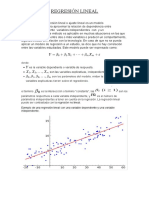
También podría gustarte
- Regresión Lineal SimpleDocumento9 páginasRegresión Lineal SimpleJorgeAún no hay calificaciones
- Contraste Hipotesis 3rDocumento15 páginasContraste Hipotesis 3rCesar Cieza SantillanAún no hay calificaciones
- Regrecion LinealDocumento10 páginasRegrecion LinealMeneces GabrielAún no hay calificaciones
- Libar SofiaDocumento6 páginasLibar SofiaHeni Sofia ORTIZ SERRANOAún no hay calificaciones
- 5.1 Regresión Lineal Simple y Correlación.Documento40 páginas5.1 Regresión Lineal Simple y Correlación.Ana Laura López OrocioAún no hay calificaciones
- Proyecto Integrador2 Analisis de Datos PDFDocumento65 páginasProyecto Integrador2 Analisis de Datos PDFJuan Manuel Garcia HernandezAún no hay calificaciones
- Regresión Lineal AvanzadaDocumento8 páginasRegresión Lineal AvanzadaangustxxxxAún no hay calificaciones
- Teoria Regresion y Correlacion LinealDocumento20 páginasTeoria Regresion y Correlacion LinealRaquel SantizoAún no hay calificaciones
- Unidad 5 PyEDocumento13 páginasUnidad 5 PyEAngel Meraz Lizarraga0% (1)
- Regresion LinealDocumento8 páginasRegresion LinealFernanfloo FooAún no hay calificaciones
- Regresión Lineal: Modelo, Análisis y AplicacionesDocumento4 páginasRegresión Lineal: Modelo, Análisis y AplicacionesMadeleine RodriguezAún no hay calificaciones
- Regresión y Correlación Lineal Simple ResumenDocumento6 páginasRegresión y Correlación Lineal Simple ResumenRocael OrozcoAún no hay calificaciones
- Unidad 1Documento29 páginasUnidad 1Chemita Mendez100% (1)
- Regresión Lineal SimpleDocumento18 páginasRegresión Lineal SimpleAldo BordaAún no hay calificaciones
- Regresión lineal simple: una técnica estadística para estimar valores desconocidos a partir de otros conocidosDocumento44 páginasRegresión lineal simple: una técnica estadística para estimar valores desconocidos a partir de otros conocidosVictor Daniel Hernandez33% (6)
- Abril Mollisaca - Resumen Cap 13 y 14Documento8 páginasAbril Mollisaca - Resumen Cap 13 y 14natalyAún no hay calificaciones
- Regresión correlación estadísticaDocumento10 páginasRegresión correlación estadísticatlapalamatl92Aún no hay calificaciones
- Expo 1Documento15 páginasExpo 1WilliamGuillermoVegaBocanegraAún no hay calificaciones
- RegresionDocumento23 páginasRegresionCesar Augusto Barrios FloresAún no hay calificaciones
- La Regresión Lineal Simple Se Aplica en Aquellas InvestigaciDocumento8 páginasLa Regresión Lineal Simple Se Aplica en Aquellas InvestigaciAnabel HiraldoAún no hay calificaciones
- Regresion Lineal - J6I - Marco-Samuel-EudoricoDocumento12 páginasRegresion Lineal - J6I - Marco-Samuel-EudoricoMarco Antonio Mendoza CarranzaAún no hay calificaciones
- Unidad 6 Cuestionario de Reforzamiento Subir ArchivoDocumento3 páginasUnidad 6 Cuestionario de Reforzamiento Subir ArchivoGerardo Hernandez GarmendiaAún no hay calificaciones
- Ensayo EstadisticoDocumento9 páginasEnsayo EstadisticoGino ReyesAún no hay calificaciones
- Regresión Lineal MúltipleDocumento5 páginasRegresión Lineal MúltipleAlvaro Atondo Leal0% (1)
- Regresión lineal: modelo estadístico para aproximar la relación entre variablesDocumento26 páginasRegresión lineal: modelo estadístico para aproximar la relación entre variablesjhonAún no hay calificaciones
- Proyecto AngelDocumento19 páginasProyecto AngelAngel Jesus Silva MorenoAún no hay calificaciones
- 5.2 Calidad Del Ajuste en Regresión Lineal SimpleDocumento4 páginas5.2 Calidad Del Ajuste en Regresión Lineal Simplejose rios25% (4)
- Estadística Inferencial IiDocumento8 páginasEstadística Inferencial IiNelsonTapiaVieraAún no hay calificaciones
- Diagrama de DispersiónDocumento13 páginasDiagrama de DispersiónCamila QuinteroAún no hay calificaciones
- Medidas Estadísticas BivariantesDocumento37 páginasMedidas Estadísticas BivariantesFabian Andres MoraAún no hay calificaciones
- Investigacion Regresión y Correlación PDFDocumento23 páginasInvestigacion Regresión y Correlación PDFRichardVelasquez100% (1)
- Unidad I Teoria Estadistica Inferencial IIDocumento9 páginasUnidad I Teoria Estadistica Inferencial IIanaafloresAún no hay calificaciones
- Regresión Lineal MúltipleDocumento3 páginasRegresión Lineal MúltipleVictor Parra QuirozAún no hay calificaciones
- LinealDocumento46 páginasLinealcarlos051186Aún no hay calificaciones
- Regresión Lineal Simple, de Las Páginas 360 A La 366Documento7 páginasRegresión Lineal Simple, de Las Páginas 360 A La 366Ernesto RamírezAún no hay calificaciones
- Regresión y Correlación LinealDocumento14 páginasRegresión y Correlación LinealPedro Orlando Gonzalez CorderoAún no hay calificaciones
- BivariantesDocumento11 páginasBivariantesMayra HernandezAún no hay calificaciones
- Regresion SimpleDocumento8 páginasRegresion SimplewendyAún no hay calificaciones
- Resumen de La Clase de Estadistica II Modulo IxDocumento5 páginasResumen de La Clase de Estadistica II Modulo IxLesly VillatoroAún no hay calificaciones
- Modelo Probabilístico Lineal SimpleDocumento4 páginasModelo Probabilístico Lineal SimpleSami JamaleddinAún no hay calificaciones
- Tema 3Documento24 páginasTema 3Ivan Gutierrez GarciaAún no hay calificaciones
- Análisis de RegresiónDocumento5 páginasAnálisis de RegresiónMARLON CATAGUAAún no hay calificaciones
- Regresión Múltiple LinealDocumento8 páginasRegresión Múltiple LinealGustavo Rodríguez DíazAún no hay calificaciones
- Unidad 1 de EstadisticaDocumento7 páginasUnidad 1 de EstadisticaGLuis AiditaAún no hay calificaciones
- Regresión Lineal Simple (Jenniffer Rodriguez Solis)Documento12 páginasRegresión Lineal Simple (Jenniffer Rodriguez Solis)FullfilmerHd rodriguezAún no hay calificaciones
- UntitledDocumento4 páginasUntitledSebastiánAún no hay calificaciones
- Regresion SimpleDocumento41 páginasRegresion Simplegeraldo campos100% (1)
- Probab I LidaDocumento23 páginasProbab I LidaJavier TorresAún no hay calificaciones
- Segundo Parcial EstadisticaDocumento213 páginasSegundo Parcial EstadisticaMichael VelezAún no hay calificaciones
- Análisiss de Regresión y CorrelaciónDocumento34 páginasAnálisiss de Regresión y CorrelaciónBETHIA KEREN ZEVALLOS SALAZARAún no hay calificaciones
- Regresión y Correlación Lineal Simple: Un Análisis Estadístico para Estimar VariablesDocumento21 páginasRegresión y Correlación Lineal Simple: Un Análisis Estadístico para Estimar VariablesLuisaAún no hay calificaciones
- Análisis de Regresión y CorrelaciónDocumento16 páginasAnálisis de Regresión y CorrelaciónDIANA ROSMELY MONTALVO SACAAún no hay calificaciones
- 1.1.2 Calidad de Ajuste y 1.1.3 Intervalo de ConfianzaDocumento8 páginas1.1.2 Calidad de Ajuste y 1.1.3 Intervalo de ConfianzaUlises Diaz Castillo100% (1)
- Modelo de Correlacion y Regresion LinealDocumento17 páginasModelo de Correlacion y Regresion LinealHenoch FandiñoAún no hay calificaciones
- Regresión: conceptos claveDocumento4 páginasRegresión: conceptos claveÁngel Alfredo Ponce ZavalaAún no hay calificaciones
- Trabajo de PreventivaaDocumento6 páginasTrabajo de Preventivaaerikson perezAún no hay calificaciones
- Estadisticaregresión LinealDocumento12 páginasEstadisticaregresión LinealLuis Fernando Ochoa YahuitaAún no hay calificaciones
- Analisis de Regresion y CorrelacionDocumento7 páginasAnalisis de Regresion y CorrelacionRicardo Garcia GuzmanAún no hay calificaciones
- Regresión y Correlación Lineal SimpleDocumento18 páginasRegresión y Correlación Lineal SimpleEfrain Meza GonzálezAún no hay calificaciones
- EOQ y costos de inventario para libros de ejercicios y válvulas de riegoDocumento3 páginasEOQ y costos de inventario para libros de ejercicios y válvulas de riegoIzumi NyaAún no hay calificaciones
- UNIDAD 3 2a OPDocumento1 páginaUNIDAD 3 2a OPIzumi NyaAún no hay calificaciones
- Ensayo Eq7 5i1Documento14 páginasEnsayo Eq7 5i1Izumi NyaAún no hay calificaciones
- Ensayo Eq7 5i1Documento14 páginasEnsayo Eq7 5i1Izumi NyaAún no hay calificaciones
- ADO1 T5 A2 Resumen Equipo5Documento13 páginasADO1 T5 A2 Resumen Equipo5Izumi NyaAún no hay calificaciones
- Administración de almacenes en KekénDocumento13 páginasAdministración de almacenes en KekénIzumi NyaAún no hay calificaciones
- ADO1 T4 A2 Resumen Equipo5Documento28 páginasADO1 T4 A2 Resumen Equipo5Izumi NyaAún no hay calificaciones
- ADO1 T4 A3 SolucionesDeCaso Equipo5Documento9 páginasADO1 T4 A3 SolucionesDeCaso Equipo5Izumi NyaAún no hay calificaciones
- Administración de inventariosDocumento6 páginasAdministración de inventariosIzumi NyaAún no hay calificaciones
- ADO111Documento2 páginasADO111Izumi NyaAún no hay calificaciones
- Cifrado de mensajes con el método de HillDocumento21 páginasCifrado de mensajes con el método de HillCARLOS ALIRIO BALLESTEROS TORRESAún no hay calificaciones
- Matrices 3 X 3Documento2 páginasMatrices 3 X 3Villosca Quispe MamaniAún no hay calificaciones
- OperacionesconpolinomiosDocumento42 páginasOperacionesconpolinomiosFernanda Pérez GarcíaAún no hay calificaciones
- Comparacion de Diagramas A BloquesDocumento1 páginaComparacion de Diagramas A BloquesLaLo CuraAún no hay calificaciones
- Tarea 1 Analisis Probabilistico PDFDocumento2 páginasTarea 1 Analisis Probabilistico PDFEddy CatúAún no hay calificaciones
- Multiplicadores de Lagrange y Ajustes de CurvasDocumento15 páginasMultiplicadores de Lagrange y Ajustes de CurvasMajo :3Aún no hay calificaciones
- Algoritmo de Ordenamiento BurbujaDocumento6 páginasAlgoritmo de Ordenamiento BurbujaalexAún no hay calificaciones
- Metodo de CholeskyDocumento12 páginasMetodo de CholeskyAbel SanchezAún no hay calificaciones
- SílaboDocumento3 páginasSílaboCesar VeraAún no hay calificaciones
- Procesos Reversibles e IrreversiblesDocumento7 páginasProcesos Reversibles e Irreversiblespapa jhonAún no hay calificaciones
- Regresión nota PA-CálculoDocumento1 páginaRegresión nota PA-CálculoCarlos FrancoAún no hay calificaciones
- Métodos determinísticos y programación linealDocumento10 páginasMétodos determinísticos y programación linealIvan rodriguez100% (2)
- Guia1 EconometriaDocumento7 páginasGuia1 EconometriaMichelle Castiblanco FernandezAún no hay calificaciones
- Sem4 Jazmin JimenezDocumento38 páginasSem4 Jazmin JimenezJAZMIN VALESKA JOHANNA JIMENEZ FABIANAún no hay calificaciones
- Metodos NumericosDocumento20 páginasMetodos NumericosJANSON CASTILLO ACOSTAAún no hay calificaciones
- Teoría de La EstabilidadDocumento2 páginasTeoría de La EstabilidadTommyKMerinoAlamaAún no hay calificaciones
- Practica 1 Control 2Documento10 páginasPractica 1 Control 2David Mtz SotoAún no hay calificaciones
- Ejercicios de Impulsos, Rampas y Escalares de SeñalesDocumento4 páginasEjercicios de Impulsos, Rampas y Escalares de SeñalesAntonioAún no hay calificaciones
- UTESA-Investigación de OperacionesDocumento25 páginasUTESA-Investigación de OperacionesadrianAún no hay calificaciones
- Estadística y Probabilidad-Taller 3Documento2 páginasEstadística y Probabilidad-Taller 3Julian David ÑañezAún no hay calificaciones
- UNIDAD 1 Introduccion A La Simulacion de Eventos DiscretosDocumento3 páginasUNIDAD 1 Introduccion A La Simulacion de Eventos DiscretosGermainGonzalezAún no hay calificaciones
- Máquinas de Turing: Modelo computacional fundamentalDocumento16 páginasMáquinas de Turing: Modelo computacional fundamentalJonathan Linch GonzalezAún no hay calificaciones
- La Factorización LUDocumento4 páginasLa Factorización LUJulio Alberto Martinez CabreraAún no hay calificaciones
- Proceso Poisson PDFDocumento22 páginasProceso Poisson PDFMatias BasualtoAún no hay calificaciones
- Estructuras SecuencialesDocumento12 páginasEstructuras SecuencialesJuvenal Quispe SernaAún no hay calificaciones
- Mat - 300 - Investigacion Operativa IDocumento11 páginasMat - 300 - Investigacion Operativa ICamilaAún no hay calificaciones
- Tarea 1 - Yamile - BecerraDocumento8 páginasTarea 1 - Yamile - BecerraSergio OrzuelaAún no hay calificaciones
- Control DigitalDocumento8 páginasControl DigitalRubenLopezAguilarAún no hay calificaciones
- Evaluación final de Cálculo 1 para Ingeniería AgroindustrialDocumento2 páginasEvaluación final de Cálculo 1 para Ingeniería AgroindustrialIsaac Elias Rivas FloresAún no hay calificaciones