También podría gustarte
- Trabajo de PreventivaaDocumento6 páginasTrabajo de Preventivaaerikson perezAún no hay calificaciones
- PROYECTO - Empleará El Método de Regresión Lineal para PronósticosDocumento20 páginasPROYECTO - Empleará El Método de Regresión Lineal para PronósticosBrian LozanoAún no hay calificaciones
- Regresion SimpleDocumento8 páginasRegresion SimplewendyAún no hay calificaciones
- Unidad 1Documento29 páginasUnidad 1Chemita Mendez100% (1)
- PROYECTO PROBABILIDAD CUARTO PARCIALDocumento15 páginasPROYECTO PROBABILIDAD CUARTO PARCIALmejiaa0430Aún no hay calificaciones
- Ajustes de Curvas e InterpolacionDocumento12 páginasAjustes de Curvas e InterpolacionKae EikōAún no hay calificaciones
- Regresion SimpleDocumento41 páginasRegresion Simplegeraldo campos100% (1)
- Unidad 5 PyEDocumento13 páginasUnidad 5 PyEAngel Meraz Lizarraga0% (1)
- Minimos CuadradosDocumento17 páginasMinimos CuadradosMarielissa DoradeaAún no hay calificaciones
- Regresión Lineal Simple (Jenniffer Rodriguez Solis)Documento12 páginasRegresión Lineal Simple (Jenniffer Rodriguez Solis)FullfilmerHd rodriguezAún no hay calificaciones
- Tema 7. Regresión y CorrelaciónDocumento15 páginasTema 7. Regresión y Correlaciónyenifer alexia colmenares camargoAún no hay calificaciones
- Regresion Lineal - J6I - Marco-Samuel-EudoricoDocumento12 páginasRegresion Lineal - J6I - Marco-Samuel-EudoricoMarco Antonio Mendoza CarranzaAún no hay calificaciones
- EstadisticaDocumento17 páginasEstadisticaMan GonzalezAún no hay calificaciones
- Regresión y correlaciónDocumento21 páginasRegresión y correlaciónÁngel Barboza LópezAún no hay calificaciones
- Regresión y Correlación Modelos Lineales 2018-IIDocumento26 páginasRegresión y Correlación Modelos Lineales 2018-IIJhon Gonzalez AnayaAún no hay calificaciones
- Estadistica GladysDocumento15 páginasEstadistica GladysMiguel HerreraAún no hay calificaciones
- AnálisisResidualRegresiónLinealDocumento6 páginasAnálisisResidualRegresiónLinealSam HernándezAún no hay calificaciones
- Inv - Doc.regresión Lineal Simple - U5 - Juan Pablo Olmos ContreraDocumento11 páginasInv - Doc.regresión Lineal Simple - U5 - Juan Pablo Olmos ContreraJuan Antonio Olmos ContreraAún no hay calificaciones
- Investigación #2 Chún Sierra Jeremy Stuart 202040759Documento17 páginasInvestigación #2 Chún Sierra Jeremy Stuart 202040759Jeremy Stuart Chun SierraAún no hay calificaciones
- RegresionDocumento23 páginasRegresionCesar Augusto Barrios FloresAún no hay calificaciones
- Unidades 5,6 y 7Documento31 páginasUnidades 5,6 y 7Luis VelasquezAún no hay calificaciones
- Práctica 3Documento26 páginasPráctica 3Juan Pedro Santos FernándezAún no hay calificaciones
- Regresión Lineal MúltipleDocumento5 páginasRegresión Lineal MúltipleAlvaro Atondo Leal0% (1)
- AsDocumento3 páginasAsYennifer OrtegozaAún no hay calificaciones
- Regrecion LinealDocumento10 páginasRegrecion LinealMeneces GabrielAún no hay calificaciones
- Regresion y Correlacion Lineal - ppt.1234567Documento21 páginasRegresion y Correlacion Lineal - ppt.1234567Jesús ParedesAún no hay calificaciones
- Análisiss de Regresión y CorrelaciónDocumento34 páginasAnálisiss de Regresión y CorrelaciónBETHIA KEREN ZEVALLOS SALAZARAún no hay calificaciones
- Estadistica II Unidad III Daniel HenriquezDocumento7 páginasEstadistica II Unidad III Daniel HenriquezYulimar Del Carmen Chirinos NeloAún no hay calificaciones
- Modelos CausalesDocumento2 páginasModelos CausalesRosa María Riveros Infante0% (1)
- Tema 3Documento24 páginasTema 3Ivan Gutierrez GarciaAún no hay calificaciones
- Clase y Tarea MatematicaDocumento23 páginasClase y Tarea Matematicagabrielquispemamani891Aún no hay calificaciones
- REGRESIONDocumento9 páginasREGRESIONJhonny Paul FGAún no hay calificaciones
- Actividad 2 Proyecto IntegradorDocumento18 páginasActividad 2 Proyecto IntegradorLuiggi Quiroz100% (1)
- Ilovepdf MergedDocumento13 páginasIlovepdf MergedVanesa CalHerreraAún no hay calificaciones
- Regresion y Correlacion LinealDocumento16 páginasRegresion y Correlacion LinealAlfredo Avendaño SerranoAún no hay calificaciones
- U1Portafolio de Evidencias - Torres Perea JavierDocumento7 páginasU1Portafolio de Evidencias - Torres Perea JavierJavier TorresAún no hay calificaciones
- Regresión lineal: ajuste de curva y mínimos cuadradosDocumento5 páginasRegresión lineal: ajuste de curva y mínimos cuadradosHéctor García JaimesAún no hay calificaciones
- Regresión Lineal: Modelo, Análisis y AplicacionesDocumento4 páginasRegresión Lineal: Modelo, Análisis y AplicacionesMadeleine RodriguezAún no hay calificaciones
- Esto No ExiteDocumento6 páginasEsto No ExiteBrayan AvendañoAún no hay calificaciones
- Regresión Lineal - Administracion de OperacionesDocumento5 páginasRegresión Lineal - Administracion de OperacionesAlejandro VargasAún no hay calificaciones
- Regresion LinealDocumento9 páginasRegresion LinealLuis GuerreroAún no hay calificaciones
- Estadísticas Inferencial NO.2Documento3 páginasEstadísticas Inferencial NO.2jsanchez20220881Aún no hay calificaciones
- Modulo 4Documento11 páginasModulo 4Daniel de Oliveira CorrêaAún no hay calificaciones
- Esta Di SticaDocumento5 páginasEsta Di SticaJuan Pablo RodriguezAún no hay calificaciones
- Análisis Del Método de Regresión Lineal Simple.Documento12 páginasAnálisis Del Método de Regresión Lineal Simple.alberto100% (1)
- Proyecto PrácticoDocumento22 páginasProyecto PrácticoPedroza Mendiola K exul YumtsilAún no hay calificaciones
- Actividad 7 Modelos Con Múltiples Variables ExplicativasDocumento7 páginasActividad 7 Modelos Con Múltiples Variables ExplicativasJeimmie Espino RamírezAún no hay calificaciones
- Analisis de RegresionDocumento2 páginasAnalisis de RegresionGonzalo HilarionAún no hay calificaciones
- Grupo 4 Analisi de RegresionDocumento7 páginasGrupo 4 Analisi de RegresionRuth SalinasAún no hay calificaciones
- Análisis de Regresión y CorrelaciónDocumento16 páginasAnálisis de Regresión y CorrelaciónDIANA ROSMELY MONTALVO SACAAún no hay calificaciones
- Cadena - Ramirez - U2 - T3 - Inv, Analisis de RegresionlinealDocumento4 páginasCadena - Ramirez - U2 - T3 - Inv, Analisis de RegresionlinealJose Ignacio Acuña BacaAún no hay calificaciones
- Unidad 5 Regresion y CorrelacionDocumento20 páginasUnidad 5 Regresion y Correlacioncic1998Aún no hay calificaciones
- Trabajo 5Documento10 páginasTrabajo 5maira mujicaAún no hay calificaciones
- Análisis de RegresiónDocumento5 páginasAnálisis de RegresiónMARLON CATAGUAAún no hay calificaciones
- Regresión Lineal SimpleDocumento4 páginasRegresión Lineal SimpleNoemyAún no hay calificaciones
- Medidas Estadísticas BivariantesDocumento37 páginasMedidas Estadísticas BivariantesFabian Andres MoraAún no hay calificaciones
- Regresión y Correlación Lineal Simple: Un Análisis Estadístico para Estimar VariablesDocumento21 páginasRegresión y Correlación Lineal Simple: Un Análisis Estadístico para Estimar VariablesLuisaAún no hay calificaciones
- Antologia Unidad 1 Estadistica InferencialDocumento59 páginasAntologia Unidad 1 Estadistica InferencialGaldinoAún no hay calificaciones
- PRUEBAS DE BONDAD DE AJUSTE - Jatziri AmbrizDocumento17 páginasPRUEBAS DE BONDAD DE AJUSTE - Jatziri AmbrizJatziri AmbrizAún no hay calificaciones
- ConclusionesDocumento1 páginaConclusionesJatziri AmbrizAún no hay calificaciones
- EstimacionDocumento8 páginasEstimacionJatziri AmbrizAún no hay calificaciones
- Aportadores A La Ingenieria IndustrialDocumento10 páginasAportadores A La Ingenieria IndustrialJatziri AmbrizAún no hay calificaciones
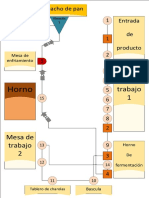
- DIagrama de Recorrido - Elaboracion de Una ConchaDocumento2 páginasDIagrama de Recorrido - Elaboracion de Una ConchaJatziri AmbrizAún no hay calificaciones
- Apéndice de TablasDocumento8 páginasApéndice de TablasJatziri AmbrizAún no hay calificaciones
- Formulario Pruebas de HipotesisDocumento2 páginasFormulario Pruebas de HipotesisLuis GuerreroAún no hay calificaciones
- Anexo 1 - Implementación de Códigos en El Software - Paso 2Documento5 páginasAnexo 1 - Implementación de Códigos en El Software - Paso 2Fabian TorresAún no hay calificaciones
- Comunicado Profesores EATICEDocumento5 páginasComunicado Profesores EATICEHector MesaAún no hay calificaciones
- Apps para ProfesDocumento16 páginasApps para ProfesAdriana AlonsoAún no hay calificaciones
- MicropilotesDocumento11 páginasMicropilotesAndres GarciaAún no hay calificaciones
- La Guia Del Freelancer PDFDocumento40 páginasLa Guia Del Freelancer PDFFernando Florez100% (2)
- 1.6. Los Recursos Humanos en La Conservación. 1.6.1. Administración. 1.6.2. Educación, Capacitación para en Trabajo y EntrenamientoDocumento4 páginas1.6. Los Recursos Humanos en La Conservación. 1.6.1. Administración. 1.6.2. Educación, Capacitación para en Trabajo y EntrenamientoRoman TorresAún no hay calificaciones
- EOCB0109 GUIA Operaciones Auxiliares Revestimientos Continuos ConstruccionDocumento241 páginasEOCB0109 GUIA Operaciones Auxiliares Revestimientos Continuos Construccionguindi3Aún no hay calificaciones
- Guia Acceso Portal Estudiantil CorreoDocumento11 páginasGuia Acceso Portal Estudiantil CorreoDavid PérezAún no hay calificaciones
- InfografiaDocumento1 páginaInfografiaMartha Cecilia Villadiego GamarraAún no hay calificaciones
- Manual - PlomeriaDocumento58 páginasManual - PlomeriaLorena Lòpez DolandeAún no hay calificaciones
- Eddy Bryan Gabriel Yupanqui 10524-3Documento2 páginasEddy Bryan Gabriel Yupanqui 10524-3GaboYTrgc GabrielAún no hay calificaciones
- Registro de gastos de mantenimiento de vehículosDocumento8 páginasRegistro de gastos de mantenimiento de vehículosJEANAún no hay calificaciones
- Tarea UVAs 2 y 3 - Secuenciales y Condicionales PDFDocumento3 páginasTarea UVAs 2 y 3 - Secuenciales y Condicionales PDFMarco LavizzariAún no hay calificaciones
- Revlic 23 IDocumento1 páginaRevlic 23 IKinichAún no hay calificaciones
- Comprensión y Redacción de Textos PC1Documento6 páginasComprensión y Redacción de Textos PC1KEYMER ARAMIX MIÑAN TRELLESAún no hay calificaciones
- Ventajas y DesventajasDocumento3 páginasVentajas y DesventajasJim Raynor Cris RonaldAún no hay calificaciones
- Practica 4Documento6 páginasPractica 4GEOVANNIAún no hay calificaciones
- Metodos de Optimizacion MultiobjetivoDocumento25 páginasMetodos de Optimizacion MultiobjetivoJavierAún no hay calificaciones
- Evaluación desempeño ingeniero ambientalDocumento3 páginasEvaluación desempeño ingeniero ambientalMARCO ANTONIO ROJAS CCOLQQUEHUANCAAún no hay calificaciones
- Conociendo los espacios de Prepa en Línea-SEPDocumento10 páginasConociendo los espacios de Prepa en Línea-SEPGabriel AmbrizAún no hay calificaciones
- CTM Ensayo 2Documento2 páginasCTM Ensayo 2Robbinson Segura GAún no hay calificaciones
- S03.s1 y s2 - Niveles de Control Ene L Sistema de PotenciaDocumento33 páginasS03.s1 y s2 - Niveles de Control Ene L Sistema de PotenciaNico GallegosAún no hay calificaciones
- Sylvania Evo FolletoDocumento24 páginasSylvania Evo FolletoVEMATELAún no hay calificaciones
- Spectra Estacion Total Focus 8 Replanteo Survey ProDocumento8 páginasSpectra Estacion Total Focus 8 Replanteo Survey ProWillyAún no hay calificaciones
- UNIDAD III Innovacion Empresarial CLASEDocumento74 páginasUNIDAD III Innovacion Empresarial CLASEJhuber Franco Cardenas ChoqueAún no hay calificaciones
- SCRUMDocumento39 páginasSCRUMMerZio PlayAún no hay calificaciones
- 1 Heizer Rezner Capitulo 1 Operaciones y ProductividadDocumento68 páginas1 Heizer Rezner Capitulo 1 Operaciones y ProductividadUriela MedinaAún no hay calificaciones
- Golf-Jetta 1.8 L. Turbo PDFDocumento126 páginasGolf-Jetta 1.8 L. Turbo PDFAlan100% (10)
- Guia Lab 2 Etn-703l FMDocumento9 páginasGuia Lab 2 Etn-703l FMJuan Luis Mamani SirpaAún no hay calificaciones
- Ingenieria Industrial 2019Documento2 páginasIngenieria Industrial 2019fabricio88Aún no hay calificaciones