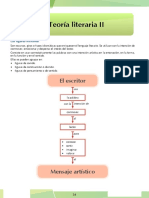
También podría gustarte
- Exposicion PythonDocumento9 páginasExposicion PythonOSCAR ENRIQUE GARCES QUINTEROAún no hay calificaciones
- Python InformeDocumento18 páginasPython InformeMARCO ANTONIO ALONSO DELGADILLOAún no hay calificaciones
- Villela Informe PythonDocumento8 páginasVillela Informe PythonJorge FerreraAún no hay calificaciones
- Notacion HungarDocumento14 páginasNotacion HungarFernando Smith TorresAún no hay calificaciones
- PDF Python Informe - CompressDocumento18 páginasPDF Python Informe - CompressHenry SalgadoAún no hay calificaciones
- Ev2.1 Ontiveros AndreaDocumento6 páginasEv2.1 Ontiveros AndreaLiizh Zl LugoAún no hay calificaciones
- Villela Sandy Informe PythonDocumento8 páginasVillela Sandy Informe PythonJorge FerreraAún no hay calificaciones
- Guía 1Documento12 páginasGuía 1Valeria Nathaly Puya CardenasAún no hay calificaciones
- Clase 1Documento31 páginasClase 1Gabriel VitelliAún no hay calificaciones
- Unidad 2-1 Django Codo A CodoDocumento13 páginasUnidad 2-1 Django Codo A CodoIván CarneiroAún no hay calificaciones
- Manual de Python Con Db2Documento13 páginasManual de Python Con Db2Milnoe de la CruzAún no hay calificaciones
- Python HistoriaDocumento5 páginasPython HistoriaEstuardo Regalado100% (1)
- Material de EstudioDocumento26 páginasMaterial de EstudioJonathan AndradeAún no hay calificaciones
- Pre Laboratorio LogicaDocumento5 páginasPre Laboratorio LogicaCarlangas ArizaAún no hay calificaciones
- Modulo 4.2022Documento21 páginasModulo 4.2022Nan AndreaAún no hay calificaciones
- Programacion en Python IDocumento84 páginasProgramacion en Python IvaleriaehAún no hay calificaciones
- Curso PythonDocumento41 páginasCurso PythonIván FarezAún no hay calificaciones
- EnsayoDocumento13 páginasEnsayoHector Adrian Archundia RodriguezAún no hay calificaciones
- 1.2.1 Programando Dispositivos para El IoT - Python RaspberryDocumento30 páginas1.2.1 Programando Dispositivos para El IoT - Python RaspberryignacioAún no hay calificaciones
- Django - 02. Python - FundamentosDocumento19 páginasDjango - 02. Python - FundamentosIván CarneiroAún no hay calificaciones
- Introducción A PythonDocumento11 páginasIntroducción A PythonTinaValenAún no hay calificaciones
- S2 D1 - 1 - Python Variables y Tipos de DatosDocumento27 páginasS2 D1 - 1 - Python Variables y Tipos de Datoscesda.carmoAún no hay calificaciones
- PythonDocumento9 páginasPythonJeraenca81Aún no hay calificaciones
- LyA2 U1 A3 Rosendo-Chable-DionisioDocumento23 páginasLyA2 U1 A3 Rosendo-Chable-DionisioRosendoAún no hay calificaciones
- Semana 3Documento50 páginasSemana 3Lenin BMAún no hay calificaciones
- Introduccion PythonDocumento22 páginasIntroduccion PythonGEISON STEEVEN ARTEAGA TITEAún no hay calificaciones
- Analisis SintacticoDocumento13 páginasAnalisis SintacticoLizeth RamiresAún no hay calificaciones
- Pyton Breve DescripcionDocumento45 páginasPyton Breve DescripcionJosé CriolloAún no hay calificaciones
- Tutorial de PythonDocumento74 páginasTutorial de PythonTania MancillaAún no hay calificaciones
- Historia de PythonDocumento7 páginasHistoria de PythonJhan Hader Muñoz BermudezAún no hay calificaciones
- Consulta Analisis Sintactico y GramaticoDocumento6 páginasConsulta Analisis Sintactico y GramaticoCarlos RestrepoAún no hay calificaciones
- Historia de PhitonDocumento7 páginasHistoria de PhitonVictor Gustavo Pantigozo OcañaAún no hay calificaciones
- Recapitulación (Preguntas)Documento3 páginasRecapitulación (Preguntas)JAVIERAún no hay calificaciones
- ¿Qué Es PHP?Documento13 páginas¿Qué Es PHP?Antonio Franco RodríguezAún no hay calificaciones
- Ensayo Sobre La Teoría de Lenguajes Formales PDFDocumento7 páginasEnsayo Sobre La Teoría de Lenguajes Formales PDFRamon Gabriel Burruel ValenzuelaAún no hay calificaciones
- Manejo de Cadenas en PythonDocumento3 páginasManejo de Cadenas en PythonVero CortesAún no hay calificaciones
- Modulo 2Documento11 páginasModulo 2Reychell ÁvilaAún no hay calificaciones
- Guía de Estudio - Conociendo Python (Parte I)Documento12 páginasGuía de Estudio - Conociendo Python (Parte I)rodrigo_ibaceta_1983Aún no hay calificaciones
- Manual de Phyton PDFDocumento20 páginasManual de Phyton PDFLuis Escobar NuñezAún no hay calificaciones
- Desacargable Semana 2Documento37 páginasDesacargable Semana 2Nathacha Silva RiveroAún no hay calificaciones
- UNIDAD 1 Primera ParteDocumento98 páginasUNIDAD 1 Primera ParteTadeoAún no hay calificaciones
- 03-Estructura General de Python 3Documento8 páginas03-Estructura General de Python 3Prof. Claudio VarelaAún no hay calificaciones
- Apuntes de PythonDocumento5 páginasApuntes de PythonVictoria RendonAún no hay calificaciones
- Introducción A PythonDocumento9 páginasIntroducción A PythonMaría DovaleAún no hay calificaciones
- PYTHON Tema 2 - 2Documento3 páginasPYTHON Tema 2 - 2manamanmanamanAún no hay calificaciones
- Clase 1Documento24 páginasClase 1ulisesromero616Aún no hay calificaciones
- Python para Ingenieros CivilespdfDocumento124 páginasPython para Ingenieros CivilespdfLuis Rafael Carreño OjedaAún no hay calificaciones
- Unidad 5. PYTHONDocumento60 páginasUnidad 5. PYTHONjessua.carvajalAún no hay calificaciones
- Analisis Lexico - Traductores, CompiladoresDocumento15 páginasAnalisis Lexico - Traductores, CompiladoresJose Angel QuinteroAún no hay calificaciones
- Manual LuaDocumento69 páginasManual LuaBenjamín AllendesAún no hay calificaciones
- Programa Como Un Pythonista - Python IdiomáticoDocumento29 páginasPrograma Como Un Pythonista - Python IdiomáticorfuenzalidavergaraAún no hay calificaciones
- LaboratorioDocumento6 páginasLaboratorioYorlin Joan Encarnacion EugenioAún no hay calificaciones
- Notacion HungaraDocumento7 páginasNotacion HungaraAshley Stronghold WitwickyAún no hay calificaciones
- Basic PythonDocumento66 páginasBasic PythonneoslayferAún no hay calificaciones
- Automatas 1Documento27 páginasAutomatas 1Roxana PoloAún no hay calificaciones
- Leng y Aut.Documento6 páginasLeng y Aut.Guillermo SanchezAún no hay calificaciones
- 10mandamientos TallerPython 180409Documento1 página10mandamientos TallerPython 180409afp1506Aún no hay calificaciones
- Protocolo 2.0Documento12 páginasProtocolo 2.0Gabriel Itzael EscamillaAún no hay calificaciones
- Programa de Multiplicar MatricesDocumento8 páginasPrograma de Multiplicar MatricesGabriel Itzael EscamillaAún no hay calificaciones
- 6.4 Método de Solución de Las Ecuaciones Diferenciales Parciales (Directos, Equiparables Con Las Ordinarias, Separación de Variables)Documento10 páginas6.4 Método de Solución de Las Ecuaciones Diferenciales Parciales (Directos, Equiparables Con Las Ordinarias, Separación de Variables)Gabriel Itzael EscamillaAún no hay calificaciones
- Programar en EnsambladorDocumento8 páginasProgramar en EnsambladorGabriel Itzael EscamillaAún no hay calificaciones
- Pirámide de MaslowDocumento1 páginaPirámide de MaslowGabriel Itzael EscamillaAún no hay calificaciones
- Programar en EnsambladorDocumento10 páginasProgramar en EnsambladorGabriel Itzael EscamillaAún no hay calificaciones
- Expo de Teoria de CompDocumento2 páginasExpo de Teoria de CompGabriel Itzael EscamillaAún no hay calificaciones
- Protocolo 3.0Documento20 páginasProtocolo 3.0Gabriel Itzael EscamillaAún no hay calificaciones
- Diseño de Los Lenguajes de ProgramacionDocumento1 páginaDiseño de Los Lenguajes de ProgramacionGabriel Itzael EscamillaAún no hay calificaciones
- Código Intermedio PythonDocumento2 páginasCódigo Intermedio PythonGabriel Itzael EscamillaAún no hay calificaciones
- Práctica para La Insatalación y Configuración de Un ModemDocumento2 páginasPráctica para La Insatalación y Configuración de Un ModemGabriel Itzael EscamillaAún no hay calificaciones
- Expo Diseño Detallado Ver 2Documento13 páginasExpo Diseño Detallado Ver 2Gabriel Itzael EscamillaAún no hay calificaciones
- CircuitoDocumento2 páginasCircuitoGabriel Itzael EscamillaAún no hay calificaciones
- Descuento de ProductosDocumento1 páginaDescuento de ProductosGabriel Itzael EscamillaAún no hay calificaciones
- MISCELANEADocumento10 páginasMISCELANEAGabriel Itzael EscamillaAún no hay calificaciones
- Código Intermedio PythonDocumento2 páginasCódigo Intermedio PythonGabriel Itzael EscamillaAún no hay calificaciones
- Micro Pro Ces AdoresDocumento8 páginasMicro Pro Ces AdoresGabriel Itzael EscamillaAún no hay calificaciones
- Diagrama Entidad RelacionDocumento1 páginaDiagrama Entidad RelacionGabriel Itzael EscamillaAún no hay calificaciones
- ApuntadoresDocumento14 páginasApuntadoresGabriel Itzael EscamillaAún no hay calificaciones
- Diagrama RelacionalDocumento1 páginaDiagrama RelacionalGabriel Itzael EscamillaAún no hay calificaciones
- Cultura CorporativaDocumento3 páginasCultura CorporativaGabriel Itzael EscamillaAún no hay calificaciones
- BIBLIOTECADocumento3 páginasBIBLIOTECAGabriel Itzael EscamillaAún no hay calificaciones
- Estados de HilosDocumento4 páginasEstados de HilosGabriel Itzael EscamillaAún no hay calificaciones
- AutolavadoDocumento3 páginasAutolavadoGabriel Itzael EscamillaAún no hay calificaciones
- Tipos de ErroresDocumento2 páginasTipos de ErroresGabriel Itzael EscamillaAún no hay calificaciones
- Errores Metodos NumericosDocumento3 páginasErrores Metodos NumericosGabriel Itzael EscamillaAún no hay calificaciones
- Arquitectura de Los PuertosDocumento5 páginasArquitectura de Los PuertosGabriel Itzael EscamillaAún no hay calificaciones
- Lenguaje MiscelaneaDocumento4 páginasLenguaje MiscelaneaCiroikiko Mena FloresAún no hay calificaciones
- Figuras Literaria. Figuras de Sonido. 1eroDocumento4 páginasFiguras Literaria. Figuras de Sonido. 1eroruben tupayachi100% (1)
- T4+Rúbrica Caso+Práctico AOI-B+II2021Documento4 páginasT4+Rúbrica Caso+Práctico AOI-B+II2021Damaris Ortiz FloresAún no hay calificaciones
- Tarea 2 - Diseño de AutómatasDocumento22 páginasTarea 2 - Diseño de AutómatasCristian AndresAún no hay calificaciones
- 2 EvaluaciónDocumento1 página2 Evaluaciónnikolasriosmo20Aún no hay calificaciones
- La Conjugación VerbalDocumento3 páginasLa Conjugación VerbalMarFuVaAún no hay calificaciones
- Cosas de Niños - Comentario de TextoDocumento2 páginasCosas de Niños - Comentario de TextoAna Lucía Pacheco Romero100% (5)
- Control de Lectura - Nuestro Iceberg Se DerriteDocumento4 páginasControl de Lectura - Nuestro Iceberg Se DerriteSorange Noemi MendozaAún no hay calificaciones
- Gaceta 1023 Dautor 20171227 1Documento44 páginasGaceta 1023 Dautor 20171227 1Romer C. Pita G.Aún no hay calificaciones
- Test TokenDocumento4 páginasTest TokenWilmer Burgos LopezAún no hay calificaciones
- Ejercicio de Simple Past Tense (Regular-Irregular Verbs)Documento6 páginasEjercicio de Simple Past Tense (Regular-Irregular Verbs)samantaAún no hay calificaciones
- English Homework 1Documento2 páginasEnglish Homework 1Pérez Sánchez AdriánAún no hay calificaciones
- Guia EgiptoDocumento2 páginasGuia EgiptoMxñekitah NyappyAún no hay calificaciones
- Listado1.1 EjerciciosResueltos LogicaDocumento6 páginasListado1.1 EjerciciosResueltos LogicaJimmy RebitAún no hay calificaciones
- Guía de Aprendizaje AdverbiosDocumento4 páginasGuía de Aprendizaje Adverbiosjhonnyv3Aún no hay calificaciones
- Importancia de La OrtografíaDocumento3 páginasImportancia de La OrtografíaKaren MNinaAún no hay calificaciones
- Ficha Verbo I PDFDocumento4 páginasFicha Verbo I PDFRichard Avendaño MamaniAún no hay calificaciones
- Mapa Conceptual PooDocumento1 páginaMapa Conceptual PooMANUEL FARID RODRIGUEZAún no hay calificaciones
- 1.5 Greetings by Bunny Bonita PDFDocumento3 páginas1.5 Greetings by Bunny Bonita PDFMarcelita MurciaAún no hay calificaciones
- Catd Paz 11Documento3 páginasCatd Paz 11Jose Anatolio Vargas SaenzAún no hay calificaciones
- MateraDocumento10 páginasMateraValentina CastilloAún no hay calificaciones
- Cuentos Inteligencia EmocionalDocumento2 páginasCuentos Inteligencia Emocionalfreddy andres farfan cañadulceAún no hay calificaciones
- Gutierrez ViñualesDocumento13 páginasGutierrez ViñualesalexhibbettAún no hay calificaciones
- Acceso 3 Octubre 2023-PrintDocumento16 páginasAcceso 3 Octubre 2023-PrintAnais SantamaríaAún no hay calificaciones
- Ruiz Gurillo L. - Hechos Pragmaticos Del Espanol-Uni. de Alicante (2006)Documento181 páginasRuiz Gurillo L. - Hechos Pragmaticos Del Espanol-Uni. de Alicante (2006)Richard Immanuel O'BreganAún no hay calificaciones
- Modulo 1. Adquisicion Del Lenguaje EscritoDocumento2 páginasModulo 1. Adquisicion Del Lenguaje EscritoDeysii AlvarezAún no hay calificaciones
- Topicos Avanzados en ProgramacionDocumento15 páginasTopicos Avanzados en ProgramacionRoberto EscareñoAún no hay calificaciones
- POR QUÉ ESTUDIAR EL LENGUAJE-Mairal Uson Ricardo - Teorias LinguisticasDocumento12 páginasPOR QUÉ ESTUDIAR EL LENGUAJE-Mairal Uson Ricardo - Teorias LinguisticasabogadojaviergimenezAún no hay calificaciones
- Asignaturas de BachilleratoDocumento3 páginasAsignaturas de BachilleratoJavierCremadesPerezAún no hay calificaciones
- Modelo de SupervisiónDocumento10 páginasModelo de Supervisiónalberto cabassoAún no hay calificaciones