También podría gustarte
- Diseño de ExperimentosDocumento17 páginasDiseño de Experimentosgeovana torreroAún no hay calificaciones
- Análisis de diseños experimentales en biometríaDocumento9 páginasAnálisis de diseños experimentales en biometríaJanet SánchezAún no hay calificaciones
- Diseños ExperimentalesDocumento13 páginasDiseños ExperimentalesIvan ToledoAún no hay calificaciones
- Métodos Experimentales en IngenieríaDocumento129 páginasMétodos Experimentales en IngenieríaSantiago J UmbarilaAún no hay calificaciones
- Estadistica ProyectosDocumento7 páginasEstadistica ProyectosAxl MalaverAún no hay calificaciones
- T.Ejercicios 1 - EQ#1Documento9 páginasT.Ejercicios 1 - EQ#1Dafne OchoaAún no hay calificaciones
- Cuestionario Diseño ExperimentalDocumento11 páginasCuestionario Diseño ExperimentalortilandiaAún no hay calificaciones
- Tarea 2Documento36 páginasTarea 2hecorjAún no hay calificaciones
- Clase Hipótesis Estadísticas - Segunda Parte 2022 (ANOVA)Documento36 páginasClase Hipótesis Estadísticas - Segunda Parte 2022 (ANOVA)PaulaAún no hay calificaciones
- Experimento de Un Solo FractorDocumento14 páginasExperimento de Un Solo FractorMariano ContrerasAún no hay calificaciones
- Tarea 2Documento34 páginasTarea 2anon_72815709263% (19)
- Disenos Experimetales UNIDAD 3Documento9 páginasDisenos Experimetales UNIDAD 3Pepe MejiaAún no hay calificaciones
- Trabajo Grupo 44Documento20 páginasTrabajo Grupo 44liliana margarita luna sanchesAún no hay calificaciones
- Análisis de Varianza DcaDocumento3 páginasAnálisis de Varianza Dcanao11100% (3)
- Actividad 1 t4 Ensayo PDFDocumento16 páginasActividad 1 t4 Ensayo PDFRosa TorresAún no hay calificaciones
- Trabajo de Diseño ExperimentalDocumento16 páginasTrabajo de Diseño ExperimentalMateria GrisAún no hay calificaciones
- Diseño Completamente AleatorioDocumento13 páginasDiseño Completamente AleatorioBibian Angela Vargas Leon80% (5)
- Taller 2. Est 3Documento25 páginasTaller 2. Est 3Paula RomeroAún no hay calificaciones
- Filminas ANOVA 1Documento75 páginasFilminas ANOVA 1JoscorbadAún no hay calificaciones
- Diseño de Experimentos Clase 2parcialesDocumento70 páginasDiseño de Experimentos Clase 2parcialesAleyda AriasAún no hay calificaciones
- Diseã o ExperimentalDocumento31 páginasDiseã o ExperimentalIBETH IDALIA CARRILLO QUISPEAún no hay calificaciones
- Diseño Completamente Al Azar (Dca)Documento21 páginasDiseño Completamente Al Azar (Dca)xygenAún no hay calificaciones
- Diseño de Un ExperimentoDocumento19 páginasDiseño de Un ExperimentoNiels Torres AguilarAún no hay calificaciones
- T.Ejercicios 1 - EQ#1Documento11 páginasT.Ejercicios 1 - EQ#1Dafne OchoaAún no hay calificaciones
- Diseño Completamente Aleatorio 2 RevisaloDocumento21 páginasDiseño Completamente Aleatorio 2 Revisalomishell estefany rojas mallmaAún no hay calificaciones
- Unidad 4Documento14 páginasUnidad 411430061Aún no hay calificaciones
- Análisis de varianza para comparar efectividad de sprays contra moscasDocumento21 páginasAnálisis de varianza para comparar efectividad de sprays contra moscasPriscila Alexandra67% (3)
- 2.1 DECA Rev 2016Documento8 páginas2.1 DECA Rev 2016Cruz Yamely Román federicoAún no hay calificaciones
- Fase 2 - CFDocumento13 páginasFase 2 - CFCEFACUNDOSAún no hay calificaciones
- Anova UnilateralDocumento10 páginasAnova UnilateralDaniel MartínezAún no hay calificaciones
- DCA-Diseño Completamente al AzarDocumento28 páginasDCA-Diseño Completamente al Azarfitz130576% (21)
- Diseño experimental completamente al azar (DECADocumento8 páginasDiseño experimental completamente al azar (DECAChristian Javier VazquezAún no hay calificaciones
- Método Turkey y Diferencia Mínima SignificativaDocumento3 páginasMétodo Turkey y Diferencia Mínima SignificativaMauricio Alejandro PadillaAún no hay calificaciones
- Presentación Unidad IV. DBCADocumento19 páginasPresentación Unidad IV. DBCAWillians DelgadoAún no hay calificaciones
- Diseño Experimental DCA y ANDEVA Clase 12082022Documento29 páginasDiseño Experimental DCA y ANDEVA Clase 12082022Luis Felipe Alberti PeñaAún no hay calificaciones
- 2 Taller Estadistica 3Documento20 páginas2 Taller Estadistica 3carlos araqueAún no hay calificaciones
- Diseño de ExperimentosDocumento6 páginasDiseño de ExperimentosSandra Serrano100% (1)
- Diseño Completamente Al AzarDocumento5 páginasDiseño Completamente Al AzarInes HernándezAún no hay calificaciones
- Primer Metodo EstadisticoDocumento8 páginasPrimer Metodo EstadisticoCarmen Rosa Flores HuacreAún no hay calificaciones
- Etapas en El Diseño de ExperimentosDocumento5 páginasEtapas en El Diseño de ExperimentosAnderson LapaAún no hay calificaciones
- DISEÑO DE BLOQUES COMPLETOS AL AZAR (DBCADocumento24 páginasDISEÑO DE BLOQUES COMPLETOS AL AZAR (DBCARene PerezAún no hay calificaciones
- Fase 2 - Aplicacion de Diseños Completamente Al Azar - PAULADocumento12 páginasFase 2 - Aplicacion de Diseños Completamente Al Azar - PAULAMarin YancarlosAún no hay calificaciones
- Diseños Priscila EjerciciosDocumento13 páginasDiseños Priscila EjerciciosRonny BarreraAún no hay calificaciones
- Clase 11-12 - Exp - 1-factor-ANOVADocumento15 páginasClase 11-12 - Exp - 1-factor-ANOVAAndresFelipeSotoAún no hay calificaciones
- 4 Diseño Completamente Al AzarDocumento7 páginas4 Diseño Completamente Al AzarWilmer joel Ramirez sullonAún no hay calificaciones
- Problemario FJCCDocumento23 páginasProblemario FJCCRamos Cabrera Damian0% (1)
- Diseño ExperimentalDocumento137 páginasDiseño ExperimentalDiego Fernando Vega ChimarroAún no hay calificaciones
- Fase 2 Aplicación de Diseños Completamente Al Azar-ROSA MABEL ANDRADEDocumento17 páginasFase 2 Aplicación de Diseños Completamente Al Azar-ROSA MABEL ANDRADEmabel andrade estrellaAún no hay calificaciones
- Anova TareaDocumento27 páginasAnova TareaCristina Merino Rojas75% (4)
- Fase Reconocimiento Yurani Cárdenas YelaDocumento12 páginasFase Reconocimiento Yurani Cárdenas YelaDouglas Steven Hernandez PachonAún no hay calificaciones
- Dca 1Documento28 páginasDca 1Juan CisnerosAún no hay calificaciones
- Evaluación de la capacidad de un proceso alimentarioDocumento31 páginasEvaluación de la capacidad de un proceso alimentarioCristian VelásquezAún no hay calificaciones
- Diseño completamente al azar DCADocumento34 páginasDiseño completamente al azar DCAJohannaAún no hay calificaciones
- Diseño Tarea 5Documento11 páginasDiseño Tarea 5Arleen StephanieAún no hay calificaciones
- Experimentos en Nutricion Animal Caso3Documento40 páginasExperimentos en Nutricion Animal Caso3jose raul perezAún no hay calificaciones
- TI2U2 - Johana - Romero - Diseño Bloques Completamente Al AzarDocumento6 páginasTI2U2 - Johana - Romero - Diseño Bloques Completamente Al AzarJOHANA MARINA ROMERO SUAREZAún no hay calificaciones
- Diseño factorial y cuadrado latinoDocumento16 páginasDiseño factorial y cuadrado latinoDavid GodoyAún no hay calificaciones
- Farmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1De EverandFarmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1Aún no hay calificaciones
- Estadística inferencial aplicadaDe EverandEstadística inferencial aplicadaCalificación: 5 de 5 estrellas5/5 (1)
- Ensayo Modulo II Componentes de Los Sistemas de InformacionDocumento9 páginasEnsayo Modulo II Componentes de Los Sistemas de InformacionIngeniera Genessis DiazAún no hay calificaciones
- Proceso administrativo clave para el desarrollo de MIPYMESDocumento21 páginasProceso administrativo clave para el desarrollo de MIPYMESIngeniera Genessis DiazAún no hay calificaciones
- Organizaciones Tradicionales y TrascomplejasDocumento5 páginasOrganizaciones Tradicionales y TrascomplejasIngeniera Genessis DiazAún no hay calificaciones
- Informacion de Modelo de GestionDocumento58 páginasInformacion de Modelo de GestionIngeniera Genessis DiazAún no hay calificaciones
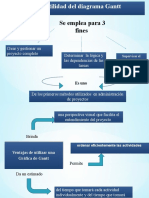
- Utilidad Del Diagrama GanttDocumento6 páginasUtilidad Del Diagrama GanttIngeniera Genessis DiazAún no hay calificaciones
- Recorrido de Actividades Cruz Roja BarinitasDocumento14 páginasRecorrido de Actividades Cruz Roja BarinitasIngeniera Genessis DiazAún no hay calificaciones
- Diseño en Bloques Al AzarDocumento2 páginasDiseño en Bloques Al AzarIngeniera Genessis DiazAún no hay calificaciones
- Ensayo de Pymes TranscomplejidadDocumento1 páginaEnsayo de Pymes TranscomplejidadIngeniera Genessis DiazAún no hay calificaciones
- Cruz Roja solicita espacio e insumos para voluntariadoDocumento3 páginasCruz Roja solicita espacio e insumos para voluntariadoIngeniera Genessis DiazAún no hay calificaciones
- Made O4Documento5 páginasMade O4Matteo Gonzalez LopezAún no hay calificaciones
- Sra Rosa Alvaray Documento1Documento3 páginasSra Rosa Alvaray Documento1Ingeniera Genessis DiazAún no hay calificaciones
- Sra Rosa Alvaray Documento1Documento3 páginasSra Rosa Alvaray Documento1Ingeniera Genessis DiazAún no hay calificaciones
- Qué Es y para Qué Sirve Un Diagrama de GanttDocumento17 páginasQué Es y para Qué Sirve Un Diagrama de GanttIngeniera Genessis DiazAún no hay calificaciones
- Pedir Esquema Que Se Necesita para Realizar El PoaDocumento1 páginaPedir Esquema Que Se Necesita para Realizar El PoaIngeniera Genessis DiazAún no hay calificaciones
- Attachment PDFDocumento12 páginasAttachment PDFIngeniera Genessis DiazAún no hay calificaciones
- Costo de Capital y OportunidadDocumento2 páginasCosto de Capital y OportunidadIngeniera Genessis DiazAún no hay calificaciones
- Organizacion Espacial de Las Actividades Economicas - ActualDocumento38 páginasOrganizacion Espacial de Las Actividades Economicas - ActualestefaniaAún no hay calificaciones
- Monografadepensamiento 130125112852 Phpapp01Documento136 páginasMonografadepensamiento 130125112852 Phpapp01Tatiana PérezAún no hay calificaciones
- Problemas Osc ColpittsDocumento8 páginasProblemas Osc ColpittsAngel GonzalesAún no hay calificaciones
- 1,3,5 TriazinaDocumento2 páginas1,3,5 TriazinaMoises Valdivia Baldomero100% (1)
- Dios te ama y quiere hijos no esclavosDocumento41 páginasDios te ama y quiere hijos no esclavosHeri Balderas100% (2)
- Cuento PolicialDocumento51 páginasCuento Policialjuega bautyAún no hay calificaciones
- Liberación de Los SentidosDocumento3 páginasLiberación de Los SentidosmarxwehllAún no hay calificaciones
- Leccion 1. DESARROLLO SOSTENIBLE PDFDocumento5 páginasLeccion 1. DESARROLLO SOSTENIBLE PDFFabian PerillaAún no hay calificaciones
- Biografía de Rafael RangelDocumento11 páginasBiografía de Rafael RangelGabriel TorresAún no hay calificaciones
- Instrumento de Valoración 6to GradoDocumento4 páginasInstrumento de Valoración 6to GradoElizabeth Francisco HernándezAún no hay calificaciones
- El Brindis de Kosmos 7Documento7 páginasEl Brindis de Kosmos 7Rls Kosmos SieteAún no hay calificaciones
- Evaluación #2Documento2 páginasEvaluación #2robierAún no hay calificaciones
- Software para La Simulación de Circuitos EléctricosDocumento9 páginasSoftware para La Simulación de Circuitos Eléctricoserickpatriciodp1Aún no hay calificaciones
- Roncadora CajamarcaDocumento13 páginasRoncadora CajamarcaAlessandra herrera gongoraAún no hay calificaciones
- CUESTIONARIO PARA EXAMEN de SOCIALIZACIONDocumento11 páginasCUESTIONARIO PARA EXAMEN de SOCIALIZACIONVanesa Gisel León SilvaAún no hay calificaciones
- Método dual-simplex para resolver problemas de optimización linealDocumento6 páginasMétodo dual-simplex para resolver problemas de optimización linealUsuario 22Aún no hay calificaciones
- Investigacion Subtema (7.1 Conocimiento Vulgar)Documento4 páginasInvestigacion Subtema (7.1 Conocimiento Vulgar)KarolynAún no hay calificaciones
- Salida UGCADocumento2 páginasSalida UGCAGisela Ramirez LopezAún no hay calificaciones
- Ex. Parcial EE647 - FIEE UNIDocumento2 páginasEx. Parcial EE647 - FIEE UNIDavid100% (1)
- Informe Factores Contaminantes Del Medio AmbienteDocumento9 páginasInforme Factores Contaminantes Del Medio AmbienteNataly CubidesAún no hay calificaciones
- Válvula Motorizada Comparato Diamant Pro, Válvulas MotorizadasDocumento2 páginasVálvula Motorizada Comparato Diamant Pro, Válvulas MotorizadaslilymaulenAún no hay calificaciones
- Estabilidad Criterios Routh HurwitzDocumento20 páginasEstabilidad Criterios Routh HurwitzFernando Vasquez CornejoAún no hay calificaciones
- HistoDocumento110 páginasHistodaniluks3674Aún no hay calificaciones
- Un Nuevo DestinoDocumento5 páginasUn Nuevo DestinoLuna Vicent CamposAún no hay calificaciones
- Monografia Etica ProfesionalDocumento24 páginasMonografia Etica ProfesionalYudith GuaraAún no hay calificaciones
- Sin Patria Ni TumbaDocumento61 páginasSin Patria Ni TumbaJosé da CruzAún no hay calificaciones
- Disartria. Práctica Basada en La Evidencia y Guías de Práctica ClínicaDocumento14 páginasDisartria. Práctica Basada en La Evidencia y Guías de Práctica ClínicaDaniela García ZavalaAún no hay calificaciones
- Conmutable 4 Vias ElectricidadDocumento9 páginasConmutable 4 Vias ElectricidadLuis Carlos RodríguezAún no hay calificaciones
- Tema 6 - Instalacion de Redes Inalambricas y VSAT - Introduccion para AlumnadoDocumento3 páginasTema 6 - Instalacion de Redes Inalambricas y VSAT - Introduccion para Alumnadoperiquito pinpinAún no hay calificaciones
- Tarea Lógica DifusaDocumento8 páginasTarea Lógica DifusaSergio GaramendiAún no hay calificaciones



























































![Diseño de Experimentos [Métodos y Aplicaciones]](https://imgv2-2-f.scribdassets.com/img/word_document/436271314/149x198/596c96deb2/1654336147?v=1)