También podría gustarte
- Estructuras de datos y algoritmos fundamentalesDe EverandEstructuras de datos y algoritmos fundamentalesAún no hay calificaciones
- Ejercicios C#Documento4 páginasEjercicios C#Kevin Acevedo100% (1)
- Análisis Algoritmos OrdenamientoDocumento9 páginasAnálisis Algoritmos OrdenamientogustavoAún no hay calificaciones
- Modelos de datos KipuDataDocumento4 páginasModelos de datos KipuDataJUAN EDUARDO ANDRIY RAMIREZ HUANACOAún no hay calificaciones
- tp1 Ep 2001 RecursionDocumento4 páginastp1 Ep 2001 RecursionMartin Acosta GálvezAún no hay calificaciones
- Actividad Semana 3 SoDocumento4 páginasActividad Semana 3 SoCristian Felipe Ga�an Andica100% (1)
- Estructura Lógica de La Memoria RAMDocumento5 páginasEstructura Lógica de La Memoria RAMIvans GonzalezAún no hay calificaciones
- Guia de Actividad N°18 - 5° - 2021Documento4 páginasGuia de Actividad N°18 - 5° - 2021Melissa OM100% (1)
- DS 06 Diagramas de ForresterDocumento3 páginasDS 06 Diagramas de ForresterMario YupanquiAún no hay calificaciones
- Introducción a la programación concurrente y concurrenciaDocumento12 páginasIntroducción a la programación concurrente y concurrenciaWalter Ramos RoblesAún no hay calificaciones
- Representación de Problemas de Juego Humano - Máquina Como Búsqueda en Un Espacio EstadoDocumento6 páginasRepresentación de Problemas de Juego Humano - Máquina Como Búsqueda en Un Espacio Estadojuan manuelAún no hay calificaciones
- Métodos Ordenamiento AnálisisDocumento30 páginasMétodos Ordenamiento AnálisisPablo Figueroa50% (2)
- Importancia de La Planificación Del DiscoDocumento6 páginasImportancia de La Planificación Del DiscoURSINEDANAún no hay calificaciones
- Pilares de La POODocumento6 páginasPilares de La POOanytrixaAún no hay calificaciones
- Lab Pap ChapDocumento6 páginasLab Pap ChapMarisa Paredes AguilarAún no hay calificaciones
- Sistema Informatico de Tramite Documentario de Registro CivilDocumento52 páginasSistema Informatico de Tramite Documentario de Registro CivilDani Meza Cardama100% (1)
- Monografia Familias LogicaDocumento33 páginasMonografia Familias LogicaMiguel DominguezAún no hay calificaciones
- Estructura Interna Del ComputadorDocumento8 páginasEstructura Interna Del ComputadorDAFRANCARAún no hay calificaciones
- Circuito Arduino LED Pulsador TinkercadDocumento2 páginasCircuito Arduino LED Pulsador TinkercadLuis Ramon Ramon CanelaAún no hay calificaciones
- Tutorial de Como Instalar Ciber ControlDocumento11 páginasTutorial de Como Instalar Ciber ControlJhon SamillanAún no hay calificaciones
- Informe Laboratorios de ComputoDocumento10 páginasInforme Laboratorios de ComputoALEJANDROAún no hay calificaciones
- La Planeacion y La Evaluacion en Los ProcesosDocumento9 páginasLa Planeacion y La Evaluacion en Los ProcesosyairmendezAún no hay calificaciones
- Examen EnsamblajeDocumento5 páginasExamen EnsamblajeKevin LopezAún no hay calificaciones
- Ejercicio Programación Orientada A ObjetosDocumento2 páginasEjercicio Programación Orientada A ObjetosJuan Marcos Hernandez OrozcoAún no hay calificaciones
- Notación CientíficaDocumento2 páginasNotación CientíficajeinerAún no hay calificaciones
- Automatización tareas SQL Server AgenteDocumento9 páginasAutomatización tareas SQL Server AgentePedro Alejandro SantanaAún no hay calificaciones
- Estructura de Datos C++Documento54 páginasEstructura de Datos C++DiogoLopesAún no hay calificaciones
- Algoritmo Round RobinDocumento4 páginasAlgoritmo Round RobinAdriana Drew0% (1)
- Manual y Configuracion Del Servidor de Correo ExchangeDocumento21 páginasManual y Configuracion Del Servidor de Correo ExchangeDaNi AlexisAún no hay calificaciones
- Introducción a las redes de computadorasDocumento27 páginasIntroducción a las redes de computadorasSarai Ramirez JimenezAún no hay calificaciones
- Ejemplos para Informatica II EPISDocumento46 páginasEjemplos para Informatica II EPISKever MallmaAún no hay calificaciones
- Programación I - Evaluación Parcial Bloque IIDocumento1 páginaProgramación I - Evaluación Parcial Bloque IIJesús G Romero MendozaAún no hay calificaciones
- Super Computadora SDocumento6 páginasSuper Computadora SF.c. JackersAún no hay calificaciones
- Laboratorio 1Documento4 páginasLaboratorio 1Ricardo Bermudez100% (1)
- SI para la gestión de procesos empresarialesDocumento10 páginasSI para la gestión de procesos empresarialesMiguel Angel RuizAún no hay calificaciones
- Practica Calificada 10 de Arquitectura de ComputadorasDocumento5 páginasPractica Calificada 10 de Arquitectura de ComputadorasCristian Yerson CausillasAún no hay calificaciones
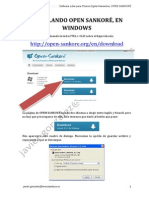
- Instalación OPEN SANKORÉDocumento6 páginasInstalación OPEN SANKORÉHabibi G DelamoAún no hay calificaciones
- Cuadro Pictografico Ultimoo CrissDocumento6 páginasCuadro Pictografico Ultimoo Crisslewislove17Aún no hay calificaciones
- 04 CN CotacachiCayapasDocumento35 páginas04 CN CotacachiCayapasSteven VillavicencioAún no hay calificaciones
- Sistemas Distribuidos: Invocación Remota y ComponentesDocumento2 páginasSistemas Distribuidos: Invocación Remota y ComponentesAlejandro Ramirez Hurtado0% (1)
- Redes Inalambricas MonografiaDocumento10 páginasRedes Inalambricas MonografiaAyarin Rbm100% (1)
- Suma, resta, multiplicación y división binaria, octal y hexadecimalDocumento5 páginasSuma, resta, multiplicación y división binaria, octal y hexadecimalターイー のグティエレスAún no hay calificaciones
- Silabo de Base de Datos IIDocumento7 páginasSilabo de Base de Datos IIJordan GonzalesAún no hay calificaciones
- Arquitectura Moderna de ComputadorasDocumento10 páginasArquitectura Moderna de Computadorasjoseantonio_figueroaAún no hay calificaciones
- Conceptos y Caracteristicas de Los Sistemas Operativos DistribuidosDocumento4 páginasConceptos y Caracteristicas de Los Sistemas Operativos DistribuidosDaniiel CamposAún no hay calificaciones
- Arquitecturas MultiprocesamientoDocumento9 páginasArquitecturas MultiprocesamientoMirzha RojasAún no hay calificaciones
- Guía de Lenguaje de Programación IIDocumento146 páginasGuía de Lenguaje de Programación IIEdison E Pariona RojasAún no hay calificaciones
- HilosDocumento12 páginasHilosAarónWálterÁvilaCórdovaAún no hay calificaciones
- Actividades Del Area de Informatica KFC 2016 Casa AbiertaDocumento11 páginasActividades Del Area de Informatica KFC 2016 Casa AbiertaJESSYAún no hay calificaciones
- Biblioteca Nacional DERDocumento5 páginasBiblioteca Nacional DERHillary ChumaceroAún no hay calificaciones
- ClementineDocumento29 páginasClementineJose AcAún no hay calificaciones
- Calcular raíces ecuación 2o gradoDocumento65 páginasCalcular raíces ecuación 2o gradoLee Soo AeAún no hay calificaciones
- Esquema Conceptual Del Sistema InformáticaDocumento1 páginaEsquema Conceptual Del Sistema InformáticaPaty LuxAún no hay calificaciones
- PROBLEMATIZACIÓNDocumento4 páginasPROBLEMATIZACIÓNTeFi ReyesAún no hay calificaciones
- Preguntas de Programacion ConcurrenteDocumento10 páginasPreguntas de Programacion ConcurrentePedro de la CruzAún no hay calificaciones
- monografia-TELEFONIA Red 4GDocumento30 páginasmonografia-TELEFONIA Red 4GMichaelAún no hay calificaciones
- Ejercicio MERDocumento4 páginasEjercicio MERTotti CruzAún no hay calificaciones
- Semana 30 Día 1 MatemáticaDocumento2 páginasSemana 30 Día 1 MatemáticaDiego AveraAún no hay calificaciones
- C++ introducción programaciónDocumento16 páginasC++ introducción programaciónJavier Ramirez DiazAún no hay calificaciones
- Elian Ayovi C++Documento8 páginasElian Ayovi C++pato2044Aún no hay calificaciones
- Ordenar lista alumnos por escuela y edad PythonDocumento8 páginasOrdenar lista alumnos por escuela y edad PythonJavier Ramirez DiazAún no hay calificaciones
- C++ Programa LenguajeDocumento16 páginasC++ Programa LenguajeJavier Ramirez DiazAún no hay calificaciones
- Ajustes ReologicosDocumento10 páginasAjustes ReologicosJavier Ramirez DiazAún no hay calificaciones
- PreguntasDocumento1 páginaPreguntasJavier Ramirez DiazAún no hay calificaciones
- Optica en Los AlimentosDocumento10 páginasOptica en Los AlimentosJavier Ramirez DiazAún no hay calificaciones
- Calculo de ÁreaDocumento5 páginasCalculo de ÁreaJavier Ramirez DiazAún no hay calificaciones
- C++ introducción programaciónDocumento16 páginasC++ introducción programaciónJavier Ramirez DiazAún no hay calificaciones
- Sis. DispersosDocumento11 páginasSis. DispersosJavier Ramirez DiazAún no hay calificaciones
- Metodos de ProteínasDocumento19 páginasMetodos de ProteínasJavier Ramirez DiazAún no hay calificaciones
- Recursos NaturalesDocumento1 páginaRecursos NaturalesJavier Ramirez DiazAún no hay calificaciones
- A.N. 1Documento33 páginasA.N. 1Javier Ramirez DiazAún no hay calificaciones
- Molinos y sus objetivos enDocumento4 páginasMolinos y sus objetivos enJavier Ramirez DiazAún no hay calificaciones
- Libro 5Documento3 páginasLibro 5Javier Ramirez DiazAún no hay calificaciones
- Empresas transnacionales y nacionales: cuestionario sobre características, innovaciones y factores claveDocumento2 páginasEmpresas transnacionales y nacionales: cuestionario sobre características, innovaciones y factores claveJavier Ramirez DiazAún no hay calificaciones
- Mapa Mental de Polisacaridos.Documento2 páginasMapa Mental de Polisacaridos.Javier Ramirez DiazAún no hay calificaciones
- Crucigrama Equipos de CentrifugaciónDocumento1 páginaCrucigrama Equipos de CentrifugaciónJavier Ramirez DiazAún no hay calificaciones
- Infografia Ljrd.Documento2 páginasInfografia Ljrd.Javier Ramirez DiazAún no hay calificaciones
- Cuestionario CarbohidratosDocumento3 páginasCuestionario CarbohidratosJavier Ramirez DiazAún no hay calificaciones
- Cómo afectan la temperatura, tiempo y cantidad a la disolución de la férula de maíz en aguaDocumento5 páginasCómo afectan la temperatura, tiempo y cantidad a la disolución de la férula de maíz en aguaJavier Ramirez DiazAún no hay calificaciones
- Acidos NuclerícosDocumento29 páginasAcidos NuclerícosJavier Ramirez DiazAún no hay calificaciones
- Mapa Mental de Polisacaridos.Documento2 páginasMapa Mental de Polisacaridos.Javier Ramirez DiazAún no hay calificaciones
- Mpa de Tema 4.0Documento2 páginasMpa de Tema 4.0Javier Ramirez DiazAún no hay calificaciones
- Mapa de Los Temas 3.0Documento2 páginasMapa de Los Temas 3.0Javier Ramirez DiazAún no hay calificaciones
- Propiedades funcionales de polisacáridos y proteínas UNAM FES CuautitlánDocumento20 páginasPropiedades funcionales de polisacáridos y proteínas UNAM FES CuautitlánJavier Ramirez DiazAún no hay calificaciones
- Ejercicios de ConsumoDocumento2 páginasEjercicios de ConsumoJavier Ramirez DiazAún no hay calificaciones
- Suspensiones 5210Documento45 páginasSuspensiones 5210Fito FloSaAún no hay calificaciones
- Aplicaciones de La Ecuaciones Diferenciales de Primer OrdenDocumento7 páginasAplicaciones de La Ecuaciones Diferenciales de Primer OrdenJavier Ramirez DiazAún no hay calificaciones
- SuspensionesDocumento44 páginasSuspensionesMilo IrigarayAún no hay calificaciones
- SuspensionesDocumento44 páginasSuspensionesMilo IrigarayAún no hay calificaciones
- SuspensionesDocumento44 páginasSuspensionesMilo IrigarayAún no hay calificaciones
- Curso Online de Reparacion de Ecus 2020Documento3 páginasCurso Online de Reparacion de Ecus 2020milsa rojasAún no hay calificaciones
- Informacion Base Curso CompetenciasDocumento2 páginasInformacion Base Curso CompetenciasSergio LunaAún no hay calificaciones
- Ergonomia InformaticaDocumento11 páginasErgonomia InformaticaClaudia LezcanoAún no hay calificaciones
- Manual Básico Comandos CiscoDocumento15 páginasManual Básico Comandos CiscoMario Garcia TorresAún no hay calificaciones
- Informe SintadDocumento4 páginasInforme SintadFreddy Raymundo PalaciosAún no hay calificaciones
- Mapa Conceptual Hardware Editable Power PointDocumento1 páginaMapa Conceptual Hardware Editable Power PointLuis AcostaAún no hay calificaciones
- TP4 2021Documento5 páginasTP4 2021rodmigan89Aún no hay calificaciones
- U1 - Act4 - Edgar Adrian - Villegas Magaña - Topicos - AvanzadosDocumento9 páginasU1 - Act4 - Edgar Adrian - Villegas Magaña - Topicos - AvanzadosEDGAR ADRIAN VILLEGAS MAGANAAún no hay calificaciones
- Hackers, crackers y lamers: tipos y definicionesDocumento3 páginasHackers, crackers y lamers: tipos y definicionesXime MachorroAún no hay calificaciones
- Como Resolver Clavos de Turbonett y No Morir en El IntentoDocumento11 páginasComo Resolver Clavos de Turbonett y No Morir en El IntentoCesar RosalesAún no hay calificaciones
- Barras de Puesta A Tierra - 1Documento3 páginasBarras de Puesta A Tierra - 1FVCMAún no hay calificaciones
- Tipos de Redes WanDocumento7 páginasTipos de Redes WanMoisés SantiagoAún no hay calificaciones
- Cifrado y descifrado de archivos ZIPDocumento8 páginasCifrado y descifrado de archivos ZIPAna Belen Gavilanes EscobarAún no hay calificaciones
- 05 - Patrones de SoftwareDocumento101 páginas05 - Patrones de SoftwareEzequiel gonzalo PrudenteAún no hay calificaciones
- Laboratorio #2 - Python EsencialDocumento3 páginasLaboratorio #2 - Python EsencialIsrael MurilloAún no hay calificaciones
- Sistema Contable SeniorcontaDocumento6 páginasSistema Contable SeniorcontaAndrea DayanaAún no hay calificaciones
- 5 pasos para renovar IP y DNS desde línea de comandosDocumento3 páginas5 pasos para renovar IP y DNS desde línea de comandosC.V.H ElectronicAún no hay calificaciones
- Actividad 4 Fase de PlaneacionDocumento10 páginasActividad 4 Fase de Planeacioneduardo mejia garciaAún no hay calificaciones
- Prueba Inicial Informática 4º Eso 2012Documento4 páginasPrueba Inicial Informática 4º Eso 2012Javier Cabrera HernandezAún no hay calificaciones
- Ética en las redes sociales y seguridad de datos personalesDocumento4 páginasÉtica en las redes sociales y seguridad de datos personalesEneydo HgAún no hay calificaciones
- Comandos - PBX RLS2016Documento17 páginasComandos - PBX RLS2016Ana Belen Ramirez EspinosaAún no hay calificaciones
- Laboratorio 1 IPSECDocumento8 páginasLaboratorio 1 IPSECluchymaderaAún no hay calificaciones
- N8 L0 CalificableDocumento1 páginaN8 L0 CalificableDAaniel ZzhamaAkhoAún no hay calificaciones
- No Sitio Latitud Longitud Cluster Tipo: Nodo 2G Nodo 3GDocumento48 páginasNo Sitio Latitud Longitud Cluster Tipo: Nodo 2G Nodo 3GEdgar ToapantaAún no hay calificaciones
- Introducción a Python y Pensamiento ComputacionalDocumento26 páginasIntroducción a Python y Pensamiento ComputacionalShanira Lisset RamirezAún no hay calificaciones
- Conexion PC - PLCDocumento9 páginasConexion PC - PLCJesus Ortiz LopezAún no hay calificaciones
- Expo Segundo Parcial (Trabajo Por WB)Documento11 páginasExpo Segundo Parcial (Trabajo Por WB)Wilbert Alberto Beltre OrtizAún no hay calificaciones
- Ventajas Y Desventajas de La Telefonía MóvilDocumento2 páginasVentajas Y Desventajas de La Telefonía MóvilMarko RomeroAún no hay calificaciones
- Sistemas de Comunicaciones III - Tema 2Documento22 páginasSistemas de Comunicaciones III - Tema 2Augusto RadaelliAún no hay calificaciones
- Mesones Heredia PA1 IIDocumento11 páginasMesones Heredia PA1 IIMarcos MesonesAún no hay calificaciones
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (116)
- Estructuras de Datos Básicas: Programación orientada a objetos con JavaDe EverandEstructuras de Datos Básicas: Programación orientada a objetos con JavaCalificación: 5 de 5 estrellas5/5 (1)
- Resumen de El cuadro de mando integral paso a paso de Paul R. NivenDe EverandResumen de El cuadro de mando integral paso a paso de Paul R. NivenCalificación: 5 de 5 estrellas5/5 (2)
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- ¿Cómo piensan las máquinas?: Inteligencia artificial para humanosDe Everand¿Cómo piensan las máquinas?: Inteligencia artificial para humanosCalificación: 5 de 5 estrellas5/5 (1)
- LAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.De EverandLAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.Calificación: 4.5 de 5 estrellas4.5/5 (54)
- Excel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteDe EverandExcel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteCalificación: 1 de 5 estrellas1/5 (1)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Auditoría de seguridad informática: Curso prácticoDe EverandAuditoría de seguridad informática: Curso prácticoCalificación: 5 de 5 estrellas5/5 (1)
- El trading online de una forma sencilla: Cómo convertirse en un inversionista online y descubrir las bases para lograr un trading de éxitoDe EverandEl trading online de una forma sencilla: Cómo convertirse en un inversionista online y descubrir las bases para lograr un trading de éxitoCalificación: 4 de 5 estrellas4/5 (30)
- Investigación de operaciones: Conceptos fundamentalesDe EverandInvestigación de operaciones: Conceptos fundamentalesCalificación: 4.5 de 5 estrellas4.5/5 (2)
- Excel 2021 y 365 Paso a Paso: Paso a PasoDe EverandExcel 2021 y 365 Paso a Paso: Paso a PasoCalificación: 5 de 5 estrellas5/5 (12)
- Aprender Illustrator 2020 con 100 ejercicios prácticosDe EverandAprender Illustrator 2020 con 100 ejercicios prácticosAún no hay calificaciones
- ChatGPT Ganar Dinero Desde Casa Nunca fue tan Fácil Las 7 mejores fuentes de ingresos pasivos con Inteligencia Artificial (IA): libros, redes sociales, marketing digital, programación...De EverandChatGPT Ganar Dinero Desde Casa Nunca fue tan Fácil Las 7 mejores fuentes de ingresos pasivos con Inteligencia Artificial (IA): libros, redes sociales, marketing digital, programación...Calificación: 5 de 5 estrellas5/5 (4)
- Minería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásDe EverandMinería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásCalificación: 4.5 de 5 estrellas4.5/5 (4)
- El mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosDe EverandEl mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosCalificación: 5 de 5 estrellas5/5 (2)
- Organizaciones Exponenciales: Por qué existen nuevas organizaciones diez veces más escalables y rentables que la tuya (y qué puedes hacer al respecto)De EverandOrganizaciones Exponenciales: Por qué existen nuevas organizaciones diez veces más escalables y rentables que la tuya (y qué puedes hacer al respecto)Calificación: 4.5 de 5 estrellas4.5/5 (11)
- AngularJS: Conviértete en el profesional que las compañías de software necesitan.De EverandAngularJS: Conviértete en el profesional que las compañías de software necesitan.Calificación: 3.5 de 5 estrellas3.5/5 (3)
- APLICACIONES PRACTICAS CON EXCELDe EverandAPLICACIONES PRACTICAS CON EXCELCalificación: 4.5 de 5 estrellas4.5/5 (6)
- Gestión de Proyectos con Microsoft Project 2013: Software de gestión de proyectosDe EverandGestión de Proyectos con Microsoft Project 2013: Software de gestión de proyectosCalificación: 5 de 5 estrellas5/5 (3)
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- La biblia del e-commerce: Los secretos de la venta online. Más de mil ideas para vender por internetDe EverandLa biblia del e-commerce: Los secretos de la venta online. Más de mil ideas para vender por internetCalificación: 5 de 5 estrellas5/5 (7)
- Diseño lógico. Fundamentos en electrónica digitalDe EverandDiseño lógico. Fundamentos en electrónica digitalAún no hay calificaciones
- Manual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasDe EverandManual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasCalificación: 4.5 de 5 estrellas4.5/5 (14)