También podría gustarte
- 4.2 Practica. Técnicas de Deep Learning en Datos LongitudinalesDocumento23 páginas4.2 Practica. Técnicas de Deep Learning en Datos Longitudinalesuwutumamaxd60Aún no hay calificaciones
- Model GardenDocumento21 páginasModel GardenEduardo David Olvera AguilarAún no hay calificaciones
- 4.2 Practica. Técnicas de Deep Learning en Datos LongitudinalesDocumento21 páginas4.2 Practica. Técnicas de Deep Learning en Datos Longitudinalesuwutumamaxd60Aún no hay calificaciones
- Deep Convolutional Neural Networks For Breast Cancer Histology Image Analysis PDFDocumento10 páginasDeep Convolutional Neural Networks For Breast Cancer Histology Image Analysis PDFDanny PáezAún no hay calificaciones
- Grupo 15 Paso TeoricoDocumento20 páginasGrupo 15 Paso Teoricoyenifer nietoAún no hay calificaciones
- ACT7 - SEMSISII - Equipo 7Documento4 páginasACT7 - SEMSISII - Equipo 7Deya RodriguezAún no hay calificaciones
- Informe de Trabajo Final de Inteligencia ArtificialDocumento4 páginasInforme de Trabajo Final de Inteligencia ArtificialDairo Estiben Beltran MartinezAún no hay calificaciones
- Sistema de Seguridad en El Hogar Orientado A La Detección en Tiempo Real de Patrones Sospechosos Utilizando Yolo v5Documento8 páginasSistema de Seguridad en El Hogar Orientado A La Detección en Tiempo Real de Patrones Sospechosos Utilizando Yolo v5Harold Cerda FloresAún no hay calificaciones
- IEEE Conference Template-2-6Documento5 páginasIEEE Conference Template-2-6Jesús Isabel Castillo MontesAún no hay calificaciones
- Practica 1 PDFDocumento4 páginasPractica 1 PDFAndres Perez0% (1)
- Tratamiento de ImagenesDocumento18 páginasTratamiento de ImagenesHernan Dario Alape GonzalezAún no hay calificaciones
- Articulo Cientifico DeeplearningDocumento7 páginasArticulo Cientifico DeeplearningCarlos Arroyo GabinoAún no hay calificaciones
- Aprendizaje Profundo: Implementación de Un Algoritmo para La Clasificación de Enfermedades Foliares Del Árbol Del ManzanoDocumento15 páginasAprendizaje Profundo: Implementación de Un Algoritmo para La Clasificación de Enfermedades Foliares Del Árbol Del ManzanoKilian Cañizares MataAún no hay calificaciones
- Formato AbedDocumento5 páginasFormato AbedLuis AlfredoAún no hay calificaciones
- Implementación de Un Algoritmo para La Detección y Conteo de Células en Imágenes MicroscópicasDocumento8 páginasImplementación de Un Algoritmo para La Detección y Conteo de Células en Imágenes MicroscópicasMario MongesAún no hay calificaciones
- Informe Deteccion de Rostros Santiago MorenoDocumento7 páginasInforme Deteccion de Rostros Santiago Morenosantiago andres moreno acevedoAún no hay calificaciones
- Trabajo Final Gestion de Analisis de Datos AvanzadosDocumento25 páginasTrabajo Final Gestion de Analisis de Datos AvanzadosCarlos Arroyo GabinoAún no hay calificaciones
- Red Neuronal Reconocimiento de Digitos Manuscritos - 1Documento16 páginasRed Neuronal Reconocimiento de Digitos Manuscritos - 1edyeAún no hay calificaciones
- Control de Aforo Con Raspberry Pi 2Documento12 páginasControl de Aforo Con Raspberry Pi 2Angelo Huaraca BerrospiAún no hay calificaciones
- Codigos Danny Martinez Etapa3Documento21 páginasCodigos Danny Martinez Etapa3Esteban Barragán TafurAún no hay calificaciones
- Redes Neuronales Modelo KerasDocumento10 páginasRedes Neuronales Modelo KerasCharlixitho Polonio OrdoñesAún no hay calificaciones
- EjemploDocumento19 páginasEjemploJEAN PIERRE RUIZ ESPINOZAAún no hay calificaciones
- Analisis de Imagenes Médicas Usando MatLabDocumento5 páginasAnalisis de Imagenes Médicas Usando MatLabJenny SoriaAún no hay calificaciones
- Informe Clasidicacion FloresDocumento13 páginasInforme Clasidicacion FloresRuth Alicia Caceres QuispeAún no hay calificaciones
- Paso1 John MerchanDocumento28 páginasPaso1 John MerchanDong-YulHeiAún no hay calificaciones
- Reconocimiento PatronesDocumento10 páginasReconocimiento PatronesVictor Alfonso De Hoyos PaterninaAún no hay calificaciones
- Procesamiento Digital de Imagenes Medicas PDFDocumento6 páginasProcesamiento Digital de Imagenes Medicas PDFAdan MartinezAún no hay calificaciones
- MicrografiaDocumento5 páginasMicrografiamartiAún no hay calificaciones
- Presentacion ClasificacionDocumento10 páginasPresentacion ClasificacionStefanny Arboleda CAún no hay calificaciones
- Informe Final - Albeiro Pedrozo - Etapa3Documento13 páginasInforme Final - Albeiro Pedrozo - Etapa3albeiro pedrozoAún no hay calificaciones
- Implementacion de Machine Learning para Recetar Medicamentos Basado en SintomasDocumento11 páginasImplementacion de Machine Learning para Recetar Medicamentos Basado en Sintomaskillermariin99Aún no hay calificaciones
- 03 - Mediciones Microscopía PDFDocumento3 páginas03 - Mediciones Microscopía PDFEliana GonzalesAún no hay calificaciones
- Reconocimiento de Rasgos Fenotípicos Faciales Mediante Visión Artificial Utilizando Análisis de Componentes Principales e Histogramas DescriptivosDocumento10 páginasReconocimiento de Rasgos Fenotípicos Faciales Mediante Visión Artificial Utilizando Análisis de Componentes Principales e Histogramas DescriptivosCitlali Jaramillo FloresAún no hay calificaciones
- Realidad Virtual Imagenes MedicasDocumento5 páginasRealidad Virtual Imagenes MedicasJuan Manuel Reyes TroncosoAún no hay calificaciones
- Realidad Virtual Imagenes MedicasDocumento5 páginasRealidad Virtual Imagenes MedicasJuan Manuel Reyes TroncosoAún no hay calificaciones
- Codigos 2Documento15 páginasCodigos 2yenifer nietoAún no hay calificaciones
- Caibración Imagenes Image JDocumento8 páginasCaibración Imagenes Image Jsantiago malamboAún no hay calificaciones
- LAB 8 Filtro ImagenesDocumento3 páginasLAB 8 Filtro ImagenesAli FajardoAún no hay calificaciones
- Informe de ClasificadorDocumento6 páginasInforme de ClasificadorCarlos Andres CujiAún no hay calificaciones
- Reconocimiento de Frutas Por Contorno Utilizando Redes Neuronales ArtificialesDocumento5 páginasReconocimiento de Frutas Por Contorno Utilizando Redes Neuronales ArtificialesCarlo Villar CaniAún no hay calificaciones
- Practica 5 - JUAREZ CAMACHO JORGE LUISDocumento7 páginasPractica 5 - JUAREZ CAMACHO JORGE LUISJorge JuarezAún no hay calificaciones
- Codigo Sergio Sanclemente Fase3Documento10 páginasCodigo Sergio Sanclemente Fase3anaAún no hay calificaciones
- Articulo Cientifico - Control de Calidad - CONEIMERA - 2012 PDFDocumento7 páginasArticulo Cientifico - Control de Calidad - CONEIMERA - 2012 PDFJaime HuarcayaAún no hay calificaciones
- Aplicaciones de Las Redes NeuronalesDocumento13 páginasAplicaciones de Las Redes NeuronalesJose A. Bucheli CAún no hay calificaciones
- Lab4 CCV1Documento4 páginasLab4 CCV1Black JackAún no hay calificaciones
- Ia Tensorflow PdiDocumento5 páginasIa Tensorflow PdiDiego Alexandre Gutiérrez EspinozaAún no hay calificaciones
- Laboratorio N. 3 Mediciones y Manejo de ImagenesDocumento9 páginasLaboratorio N. 3 Mediciones y Manejo de ImagenesSergio Alejandro Peralta LópezAún no hay calificaciones
- Trabajo Final UnificadoDocumento15 páginasTrabajo Final UnificadoCARLOS ANDRES DIAZ MEJIA0% (1)
- Introduccion Al Machine LearningDocumento5 páginasIntroduccion Al Machine LearningJosé Ramón Espinosa MuñozAún no hay calificaciones
- M2 RetoNo2 VisorDeImagenDocumento3 páginasM2 RetoNo2 VisorDeImagencristianAún no hay calificaciones
- Extraccion de Caracteristicas en Imagenes DigitalesDocumento4 páginasExtraccion de Caracteristicas en Imagenes DigitalesGabriel HumpireAún no hay calificaciones
- RA para Tratamiento de La AcrofobiaDocumento4 páginasRA para Tratamiento de La AcrofobiaCarlos ReyesAún no hay calificaciones
- Manual de UsuarioDocumento8 páginasManual de Usuarioluis tellezAún no hay calificaciones
- Modelado y Simulación de Una Percepción TridimensionalDocumento7 páginasModelado y Simulación de Una Percepción TridimensionalJohann GutierrezAún no hay calificaciones
- Implementacion de Vision Computacional para El Diagnostico de La Correcta Ejecucion de Poses de RugbyDocumento18 páginasImplementacion de Vision Computacional para El Diagnostico de La Correcta Ejecucion de Poses de Rugbykillermariin99Aún no hay calificaciones
- ResumenProyecto - Valeria López - Etapa1Documento10 páginasResumenProyecto - Valeria López - Etapa1Valeriia López GarcíaAún no hay calificaciones
- Etapa1 - Jhonatan Fierro.Documento10 páginasEtapa1 - Jhonatan Fierro.jhonatanAún no hay calificaciones
- Experimento Reporte de Resultados Mineria de DatosDocumento4 páginasExperimento Reporte de Resultados Mineria de DatostatianaAún no hay calificaciones
- Técnicas de análisis de imagen, (2a ed.): Aplicaciones en BiologíaDe EverandTécnicas de análisis de imagen, (2a ed.): Aplicaciones en BiologíaAún no hay calificaciones
- Matriz fundamental de visión por computadora: Por favor, sugiera un subtítulo para un libro con el título 'Matriz fundamental de visión por computadora' dentro del ámbito de 'Visión por computadora'. El subtítulo sugerido no debe tener ':'.De EverandMatriz fundamental de visión por computadora: Por favor, sugiera un subtítulo para un libro con el título 'Matriz fundamental de visión por computadora' dentro del ámbito de 'Visión por computadora'. El subtítulo sugerido no debe tener ':'.Aún no hay calificaciones
- Taller LaftDocumento5 páginasTaller Laftmodesta araujoAún no hay calificaciones
- Adicciones y Trastornos AlimenticiosDocumento36 páginasAdicciones y Trastornos AlimenticiosVICTOR CARABEZ MANZOAún no hay calificaciones
- Todo Sobre MielDocumento50 páginasTodo Sobre MielPaula BuriticáAún no hay calificaciones
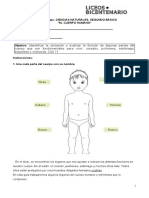
- Guía Ciencias 2°Documento6 páginasGuía Ciencias 2°Brenda angelica Rozas márquezAún no hay calificaciones
- Resume NDocumento5 páginasResume NpedroAún no hay calificaciones
- AnabólicosDocumento4 páginasAnabólicosNicole Rodríguez SalasAún no hay calificaciones
- Tumores OsteoarticularesDocumento49 páginasTumores OsteoarticularesRicardo RochaAún no hay calificaciones
- BoletaDocumento3 páginasBoletaDora Cristina Pflücker MuñozAún no hay calificaciones
- René Kaës - La Transmisión de La Vida Psíquica Entre Generaciones: Aportes Del Psicoanálisis GrupalDocumento20 páginasRené Kaës - La Transmisión de La Vida Psíquica Entre Generaciones: Aportes Del Psicoanálisis Grupalmblanco15100% (1)
- SOSIADocumento13 páginasSOSIACatalina Galleguillos González0% (1)
- PGIRDocumento6 páginasPGIRJuan Manuel GutiérrezAún no hay calificaciones
- Chagas CongenitoDocumento50 páginasChagas CongenitoDeisy MatiasAún no hay calificaciones
- ACT - 3.2 LEGUMBRES y HORTALIZASDocumento4 páginasACT - 3.2 LEGUMBRES y HORTALIZASbrandon478Aún no hay calificaciones
- Instalacion de Drenajes PDFDocumento39 páginasInstalacion de Drenajes PDFrodstyle93% (30)
- Tratamiento de La Timidez AmorosaDocumento3 páginasTratamiento de La Timidez Amorosajose alvaradoAún no hay calificaciones
- Tecnicas Cognitivo Conductual (Mapa Conceptual-Intervencion)Documento3 páginasTecnicas Cognitivo Conductual (Mapa Conceptual-Intervencion)nclerque2572Aún no hay calificaciones
- Su JokDocumento12 páginasSu Jokkudum33Aún no hay calificaciones
- Diseño Plan de Manejo AmbientalDocumento13 páginasDiseño Plan de Manejo AmbientalKaren Julieth RodriguezAún no hay calificaciones
- Vidal Contesta Informe Art. 8Documento5 páginasVidal Contesta Informe Art. 8Horacio RodriguezAún no hay calificaciones
- Cuadro # 2 Analisis Del Caso de CarlosDocumento11 páginasCuadro # 2 Analisis Del Caso de Carlosclaudia priscilaAún no hay calificaciones
- Tesis Educando Desde El Vientre MaternoDocumento260 páginasTesis Educando Desde El Vientre MaternoOmar Andrés HenríquezAún no hay calificaciones
- Organigrama 2021Documento2 páginasOrganigrama 2021Angel León MasgoAún no hay calificaciones
- Mannual de Seguridad Empresa Argentina METALURGICADocumento104 páginasMannual de Seguridad Empresa Argentina METALURGICAagustin2003Aún no hay calificaciones
- UCIDocumento14 páginasUCIDamián López RangelAún no hay calificaciones
- Refrigeracion Del PescadoDocumento4 páginasRefrigeracion Del PescadorafaelAún no hay calificaciones
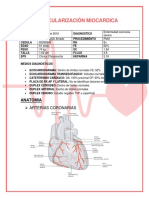
- Revascularización MiocardicaDocumento9 páginasRevascularización MiocardicaDIANAAún no hay calificaciones
- Contactos Mujeres Plaza España 20 en MadridDocumento3 páginasContactos Mujeres Plaza España 20 en MadridConocer mujeres en MadridAún no hay calificaciones
- Generalidades de La MalnutricionDocumento10 páginasGeneralidades de La MalnutricionLINDA JAZMIN MOSQUERA AGUDELOAún no hay calificaciones
- 17.30 Hs DR Brea Folco Gonzalez (Caminata)Documento18 páginas17.30 Hs DR Brea Folco Gonzalez (Caminata)Mauro Salamanca ElguetaAún no hay calificaciones
- Historia de La Anatomia PatológicaDocumento3 páginasHistoria de La Anatomia PatológicaJaneth SolórzanoAún no hay calificaciones