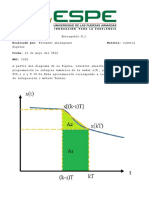
También podría gustarte
- Planificación en STRIPS/PDDLDocumento17 páginasPlanificación en STRIPS/PDDLFernandoQuisaguanoAún no hay calificaciones
- Descubre Cuánto Sabes de Microsoft EXCEL®Documento41 páginasDescubre Cuánto Sabes de Microsoft EXCEL®rau100% (1)
- Problemas Selectividad Soluciones NeumaticaDocumento14 páginasProblemas Selectividad Soluciones Neumaticakoala6969100% (1)
- Maestria Analisis Visualizacion Datos Masivos MXDocumento9 páginasMaestria Analisis Visualizacion Datos Masivos MXMarcus RoulAún no hay calificaciones
- Examen AutocorregibleDocumento4 páginasExamen AutocorregibleTechnical Support (A Computer Solutions)Aún no hay calificaciones
- Manual de Usuario Torno CNC Con GSK 980 TDC - Taller - CNC - Profesor - Lucas - Caula.Documento8 páginasManual de Usuario Torno CNC Con GSK 980 TDC - Taller - CNC - Profesor - Lucas - Caula.Tachi Duboscq0% (1)
- DERCASDocumento9 páginasDERCASVictor Perez100% (1)
- Laboratorio N°3 - SQL - UCVDocumento8 páginasLaboratorio N°3 - SQL - UCVMARIANA LAURENTE QUEQUEJANA100% (2)
- Estructura de datos: Un enfoque con Python, java y C++De EverandEstructura de datos: Un enfoque con Python, java y C++Aún no hay calificaciones
- Tema 5Documento41 páginasTema 5RaulAún no hay calificaciones
- TMP - 4875-Machine Learning - Libro Online de IAAR6425397170085804942Documento13 páginasTMP - 4875-Machine Learning - Libro Online de IAAR6425397170085804942alejandroAún no hay calificaciones
- Redes NeuronalesDocumento10 páginasRedes NeuronalesVALENTINA IGNACIA CAROCAAún no hay calificaciones
- Intro Data ScienceDocumento11 páginasIntro Data ScienceJavier Cabañas LerinAún no hay calificaciones
- Inteligencia de NegociosDocumento189 páginasInteligencia de NegociosJhonatan Jimenez100% (1)
- Act2 Aa E25Documento7 páginasAct2 Aa E25jhonnAún no hay calificaciones
- Libros y Videos HadoopDocumento14 páginasLibros y Videos Hadoopjesus alamillaAún no hay calificaciones
- Introducción al Big Data y macrodatosDocumento46 páginasIntroducción al Big Data y macrodatosJose Luis Velasquez AlemanAún no hay calificaciones
- Almacena y comparte archivos con OneDriveDocumento1 páginaAlmacena y comparte archivos con OneDriveSebastiánAún no hay calificaciones
- Seguridad y Data MiningDocumento9 páginasSeguridad y Data MiningJosé Rafael CruzAún no hay calificaciones
- Deep LearningDocumento5 páginasDeep LearningFELIPE CALDERON VACCAAún no hay calificaciones
- Big Data y Analitica Web Estudiar Las Corrientes y Pescar en Un Oceano de DatosDocumento6 páginasBig Data y Analitica Web Estudiar Las Corrientes y Pescar en Un Oceano de Datosidali morenoAún no hay calificaciones
- Guerrero Arturo ISC R3 U3Documento10 páginasGuerrero Arturo ISC R3 U3Arturo GuerreroAún no hay calificaciones
- Web Scraping Con Python EjemploDocumento4 páginasWeb Scraping Con Python EjemploJuanCamilo100% (1)
- Introduccion Al Machine LearningDocumento5 páginasIntroduccion Al Machine LearningJosé Ramón Espinosa MuñozAún no hay calificaciones
- Redes Neuronales Artificiales-1Documento14 páginasRedes Neuronales Artificiales-1carlosAún no hay calificaciones
- PracticaSVM PDFDocumento8 páginasPracticaSVM PDFPaul DiazAún no hay calificaciones
- Slides Del Curso de Python IntermedioDocumento91 páginasSlides Del Curso de Python Intermediocarlos arturo herrera beltran100% (1)
- Ejercicios Data MiningDocumento37 páginasEjercicios Data MiningStalin Camino RuizAún no hay calificaciones
- 2021 - Dcu - Repaso ExamenDocumento92 páginas2021 - Dcu - Repaso ExamenMary RC2Aún no hay calificaciones
- Libro de Data ScienceDocumento148 páginasLibro de Data ScienceluciaAún no hay calificaciones
- Guia de Preguntas Big DataDocumento10 páginasGuia de Preguntas Big DataFanny GarciaAún no hay calificaciones
- Científico de DatosDocumento38 páginasCientífico de DatosRuben DarioAún no hay calificaciones
- Estándares de CodificaciónDocumento13 páginasEstándares de CodificaciónEduardo CeballosAún no hay calificaciones
- Administración de Base de Datos Ii PDFDocumento8 páginasAdministración de Base de Datos Ii PDFroy saavedraAún no hay calificaciones
- Arquitectura de DatosDocumento40 páginasArquitectura de DatosjavierAún no hay calificaciones
- Redes Neuronales MulticapaDocumento66 páginasRedes Neuronales MulticapaEdwing Maquera FloresAún no hay calificaciones
- Redes ConvolucionalesDocumento32 páginasRedes ConvolucionalesRobinson Poveda CamargoAún no hay calificaciones
- PIN-1801 Business Intelligence SQL Server 2016 - 96 HDocumento15 páginasPIN-1801 Business Intelligence SQL Server 2016 - 96 HElmer John Pérez EspinozaAún no hay calificaciones
- MB-901 examen preguntas y respuestas página 8Documento3 páginasMB-901 examen preguntas y respuestas página 8DJ071286888Aún no hay calificaciones
- Las 4V S Del Big DataDocumento12 páginasLas 4V S Del Big DataMauroExe131100% (1)
- Arquitectura Big DataDocumento11 páginasArquitectura Big DataTitoAún no hay calificaciones
- Diseño centrado en el usuario guíaDocumento2 páginasDiseño centrado en el usuario guíapeabonsuAún no hay calificaciones
- La Nube PDFDocumento18 páginasLa Nube PDFenrique_tamayo_9Aún no hay calificaciones
- CD - M5 ExamenDocumento4 páginasCD - M5 ExamenMarco RamosAún no hay calificaciones
- Inteligencia de NegociosDocumento10 páginasInteligencia de NegociosramonAún no hay calificaciones
- Silabo de PythonDocumento8 páginasSilabo de PythonJackeline BalvinAún no hay calificaciones
- Diseño de Una Arquitectura para Big DataDocumento28 páginasDiseño de Una Arquitectura para Big DataCrist VillarAún no hay calificaciones
- Machine LearningDocumento2 páginasMachine LearningGuido YunganAún no hay calificaciones
- Big Data: qué es y para qué sirveDocumento12 páginasBig Data: qué es y para qué sirveHugo MorenoAún no hay calificaciones
- Modelo de Deteccion de Agresiones Verbales Por Medio de Algoritmos de Machine LearningDocumento70 páginasModelo de Deteccion de Agresiones Verbales Por Medio de Algoritmos de Machine LearningAlexander Ojeda AyalaAún no hay calificaciones
- Cap 3.a BIG DATA IntroduccionDocumento19 páginasCap 3.a BIG DATA IntroduccionJorge Bryan Soliz VidalAún no hay calificaciones
- Método de La Encriptación de Seguridad en Un Centro de CómputoDocumento10 páginasMétodo de La Encriptación de Seguridad en Un Centro de CómputoErbys CárdenasAún no hay calificaciones
- Fundamentos de Ciencia de DatosDocumento72 páginasFundamentos de Ciencia de DatosMelissa RuizAún no hay calificaciones
- Big Data Analytics Syllabus UDFJCDocumento8 páginasBig Data Analytics Syllabus UDFJCeshernanAún no hay calificaciones
- Funciones Heurísticas Búsqueda Por Ascenso de Colinas Algoritmos GenéticosDocumento13 páginasFunciones Heurísticas Búsqueda Por Ascenso de Colinas Algoritmos GenéticosYuly Y JavierAún no hay calificaciones
- Generalización y reconocimiento de patrones en MLDocumento11 páginasGeneralización y reconocimiento de patrones en MLFredy CastellanosAún no hay calificaciones
- Desarrollo de una aplicación de reconocimiento de imágenes utilizando Deep Learning con OpenCVDocumento104 páginasDesarrollo de una aplicación de reconocimiento de imágenes utilizando Deep Learning con OpenCVAlicia LaraAún no hay calificaciones
- Gerencia de Servicios TI - Semana 1 PDFDocumento30 páginasGerencia de Servicios TI - Semana 1 PDFJavier ARAún no hay calificaciones
- Introducción A La Ciencia de Datos y El Big DataDocumento11 páginasIntroducción A La Ciencia de Datos y El Big DataCrisAún no hay calificaciones
- Data Science A DistanciaDocumento14 páginasData Science A DistanciaMateo Osorio HiguitaAún no hay calificaciones
- SilaboPE 2021 2Documento4 páginasSilaboPE 2021 2Jhon Ortega GarciaAún no hay calificaciones
- Solemne N°1Documento3 páginasSolemne N°1Cok3_93Aún no hay calificaciones
- Tema 5. Excel. Tablas y Tablas DinámicasDocumento20 páginasTema 5. Excel. Tablas y Tablas Dinámicasalejandro gudiña sanzAún no hay calificaciones
- Machine Learning aplicado al rendimiento académico en educación superior: factores, variables y herramientasDe EverandMachine Learning aplicado al rendimiento académico en educación superior: factores, variables y herramientasAún no hay calificaciones
- Ciencia de los datos con Python - 1ra ediciónDe EverandCiencia de los datos con Python - 1ra ediciónAún no hay calificaciones
- DATABASE - Del modelo conceptual a la aplicación final en Access, Visual Basic, Pascal, Html y PhpDe EverandDATABASE - Del modelo conceptual a la aplicación final en Access, Visual Basic, Pascal, Html y PhpAún no hay calificaciones
- Tarea1 Unidad3 Quisaguano Alvarez 2696Documento16 páginasTarea1 Unidad3 Quisaguano Alvarez 2696FernandoQuisaguanoAún no hay calificaciones
- Lab3 3825 Alvarez Quisaguano PresentacionDocumento16 páginasLab3 3825 Alvarez Quisaguano PresentacionFernandoQuisaguanoAún no hay calificaciones
- Tarea2 Segundo Parcial - Control DigitalDocumento12 páginasTarea2 Segundo Parcial - Control DigitalFernandoQuisaguanoAún no hay calificaciones
- 1 - Presentación ClaseDocumento6 páginas1 - Presentación ClaseKatty Aguilar ZambranoAún no hay calificaciones
- Ejercicios de MatlabDocumento17 páginasEjercicios de MatlabFernandoQuisaguanoAún no hay calificaciones
- Vision Por Computador - Tema 3Documento31 páginasVision Por Computador - Tema 3Sebastián SandovalAún no hay calificaciones
- Tarea2 Unidad3 Aguirre Alvarez Quisaguano2696Documento12 páginasTarea2 Unidad3 Aguirre Alvarez Quisaguano2696FernandoQuisaguanoAún no hay calificaciones
- DEBER No 1.1 - 1 PDFDocumento2 páginasDEBER No 1.1 - 1 PDFJoseph BauerAún no hay calificaciones
- Vision Por Computador - Tema 1Documento41 páginasVision Por Computador - Tema 1Sebastián SandovalAún no hay calificaciones
- SEGUNDA - CLASE MicroprocesadoresDocumento9 páginasSEGUNDA - CLASE MicroprocesadoresFernandoQuisaguanoAún no hay calificaciones
- Primera Clase MicroprocesadoresDocumento44 páginasPrimera Clase MicroprocesadoresFernandoQuisaguanoAún no hay calificaciones
- Control Digital Deber Parcial 1Documento4 páginasControl Digital Deber Parcial 1FernandoQuisaguanoAún no hay calificaciones
- 2 Diagramas P Id PDFDocumento43 páginas2 Diagramas P Id PDFFreddy YugchaAún no hay calificaciones
- Guias y Trabajos Preparatorios 2Documento2 páginasGuias y Trabajos Preparatorios 2FernandoQuisaguanoAún no hay calificaciones
- Guias y Trabajos Preparatorios 1Documento2 páginasGuias y Trabajos Preparatorios 1FernandoQuisaguanoAún no hay calificaciones
- Automatizacion en La IndustriaDocumento31 páginasAutomatizacion en La IndustriaDarwinj90Aún no hay calificaciones
- GrafcetDocumento44 páginasGrafcetmartining23100% (2)
- Introducción A HMI (Interfaz Hombre Máquina)Documento5 páginasIntroducción A HMI (Interfaz Hombre Máquina)Teckelino100% (1)
- Guiapractica1 1 PDFDocumento3 páginasGuiapractica1 1 PDFFernandoQuisaguanoAún no hay calificaciones
- Documentos para GRADO Pregrado 2016Documento2 páginasDocumentos para GRADO Pregrado 2016FernandoQuisaguanoAún no hay calificaciones
- P3. PLC ConceptosDocumento34 páginasP3. PLC ConceptosFernandoQuisaguanoAún no hay calificaciones
- Guias y Trabajos Preparatorios 3Documento2 páginasGuias y Trabajos Preparatorios 3FernandoQuisaguanoAún no hay calificaciones
- SGCD FormularioIdentificaciónPersonagraduaciónDocumento1 páginaSGCD FormularioIdentificaciónPersonagraduaciónFernandoQuisaguanoAún no hay calificaciones
- Automatizacion en La IndustriaDocumento31 páginasAutomatizacion en La IndustriaDarwinj90Aún no hay calificaciones
- Tarea11 Industria 2681 PLC Equipo 2Documento1 páginaTarea11 Industria 2681 PLC Equipo 2FernandoQuisaguanoAún no hay calificaciones
- Contador de Programa Del Microprocesador Z80Documento10 páginasContador de Programa Del Microprocesador Z80FernandoQuisaguano0% (1)
- MONICA Curriculo-Educacion-Inicial PDFDocumento37 páginasMONICA Curriculo-Educacion-Inicial PDFElvis Honores RiveraAún no hay calificaciones
- Preguntas de TelecomunicacionesDocumento91 páginasPreguntas de TelecomunicacionesJORGE LUIS AUQUILLA VILLAMAGUAAún no hay calificaciones
- 01 - Clase N°1 - Introduccion A RedesDocumento32 páginas01 - Clase N°1 - Introduccion A RedesNicolás La TorreAún no hay calificaciones
- Ensayo MatematicasDocumento9 páginasEnsayo MatematicasDaniel CarrionAún no hay calificaciones
- Act - 04 - U4 - Movilidad en Ambientes Escolares para Invidentes PDFDocumento15 páginasAct - 04 - U4 - Movilidad en Ambientes Escolares para Invidentes PDFAnnie LopezAún no hay calificaciones
- BJGS-Evidencia de Aprendizaje 4Documento37 páginasBJGS-Evidencia de Aprendizaje 4Bruno GarciaAún no hay calificaciones
- Ficha Informacion de Docentes de IeDocumento1 páginaFicha Informacion de Docentes de IeRuperto CahuanaAún no hay calificaciones
- Migitación de Riesgos 1.4Documento3 páginasMigitación de Riesgos 1.4Ignacio CruzAún no hay calificaciones
- Codigos Base de Datos Sis Ventas Java - SQLDocumento4 páginasCodigos Base de Datos Sis Ventas Java - SQLjorge25_25_7Aún no hay calificaciones
- Formato Condicional - Luis QuintanaDocumento4 páginasFormato Condicional - Luis QuintanaDome CortijoAún no hay calificaciones
- Claves y Habilidades Prueba Unidad I - 1° Basico - MatematicaDocumento1 páginaClaves y Habilidades Prueba Unidad I - 1° Basico - MatematicaVary Palominos GonzalezAún no hay calificaciones
- Silabo Matemática DiscretaDocumento4 páginasSilabo Matemática DiscretaDavid VegaAún no hay calificaciones
- Configuracion Instalacion POS Bettle MII Plus Desde CeroDocumento13 páginasConfiguracion Instalacion POS Bettle MII Plus Desde CeroGerman ArciniegasAún no hay calificaciones
- Ficha Tecnica Comercial SI9220DV ELITEDocumento1 páginaFicha Tecnica Comercial SI9220DV ELITEedwin eduardo martinez paipaAún no hay calificaciones
- Diseño de Un Brazo Robotico de Configuracion CilindricaDocumento33 páginasDiseño de Un Brazo Robotico de Configuracion CilindricaMayc HerreraAún no hay calificaciones
- Matriz Antecedentes Actualizado 15102023Documento50 páginasMatriz Antecedentes Actualizado 15102023Fernando LopezAún no hay calificaciones
- Planeación Didáctica Sesión 2Documento12 páginasPlaneación Didáctica Sesión 2Angel Gustavo Avila HernandezAún no hay calificaciones
- Ima040 2Documento18 páginasIma040 2Michael MayoAún no hay calificaciones
- Estructuras condicionales anidadas - Separata de trabajo 08Documento3 páginasEstructuras condicionales anidadas - Separata de trabajo 08Raul SAún no hay calificaciones
- High Power - Estabilizador - Solido Transformador Aislamiento Trifasico 50kVA 120kVADocumento3 páginasHigh Power - Estabilizador - Solido Transformador Aislamiento Trifasico 50kVA 120kVASoporte PiuraAún no hay calificaciones
- Informatica FacilDocumento83 páginasInformatica Facilpatricianoemi.rAún no hay calificaciones
- Mapa Conceptual PDFDocumento1 páginaMapa Conceptual PDFEmilio MendietaAún no hay calificaciones
- Partes del computadorDocumento3 páginasPartes del computadorernesto gutierrez pintaAún no hay calificaciones
- 12 51 Resumen Sobre Trigon PDFDocumento19 páginas12 51 Resumen Sobre Trigon PDFCarlos Adrian Matos AmitaAún no hay calificaciones
- Practico 4 Parte I EXCELDocumento8 páginasPractico 4 Parte I EXCELEmmanuel GmaAún no hay calificaciones
- Cinema Global Sistema de Alquiler VideoDocumento2 páginasCinema Global Sistema de Alquiler VideoEdwin CuevaAún no hay calificaciones
- Anexo 2 - Desarrollo de Actividades de MantenimientoDocumento8 páginasAnexo 2 - Desarrollo de Actividades de MantenimientoMarco Rogelio Taype FelixAún no hay calificaciones