También podría gustarte
- SISTEMA ELECTRICO Nissan Primera p11Documento408 páginasSISTEMA ELECTRICO Nissan Primera p11seregap8485% (74)
- Java 2: Manual de Usuario y Tutorial. 5ª EdiciónDe EverandJava 2: Manual de Usuario y Tutorial. 5ª EdiciónAún no hay calificaciones
- ISO 22301 - CertMind&ExinDocumento95 páginasISO 22301 - CertMind&ExinByronAún no hay calificaciones
- Manual Sistemas Electricos Conductores Magnitudes Bateria Motor Arranque Carga Encendido Convencional ElectronicoDocumento182 páginasManual Sistemas Electricos Conductores Magnitudes Bateria Motor Arranque Carga Encendido Convencional ElectronicoClaudio Hernan Ortiz Molina0% (1)
- Actividad en Contexto - Escenario 6Documento32 páginasActividad en Contexto - Escenario 6Heidy Milena100% (1)
- 1 - Introducción Spark Curso BIT (Medio)Documento25 páginas1 - Introducción Spark Curso BIT (Medio)Deogracias PlaudAún no hay calificaciones
- Tema 1Documento27 páginasTema 1Gustavo OrtegaAún no hay calificaciones
- Introduccion A Hadoop UV ESDocumento61 páginasIntroduccion A Hadoop UV EScristivenvargasAún no hay calificaciones
- Análisis de Datos Con Apache SparkDocumento66 páginasAnálisis de Datos Con Apache SparksilAún no hay calificaciones
- PDF DefinidoDocumento25 páginasPDF DefinidoAlejandro CorrealAún no hay calificaciones
- Ecosistema Spark IntroDocumento87 páginasEcosistema Spark IntrosilAún no hay calificaciones
- S02 ApacheSparkDocumento25 páginasS02 ApacheSparkSandra InfanteAún no hay calificaciones
- 3.1.1.PPT - Presentacion de SparkDocumento16 páginas3.1.1.PPT - Presentacion de Sparkjavier alberto castillo becerraAún no hay calificaciones
- Spark 1Documento44 páginasSpark 1mauricio995Aún no hay calificaciones
- 1.1 Introducción A SparkDocumento23 páginas1.1 Introducción A Sparkabel0% (1)
- Actividad 6. Investigación SparkDocumento9 páginasActividad 6. Investigación SparkBeatriz C.FloresAún no hay calificaciones
- Clase 4 - Herramientas Big Data Nov 15Documento31 páginasClase 4 - Herramientas Big Data Nov 15anamar.prilopAún no hay calificaciones
- Separata 04Documento23 páginasSeparata 04Joaquín AlvaradoAún no hay calificaciones
- 6 - SparkDocumento28 páginas6 - Sparkkinyo12Aún no hay calificaciones
- Brochure - Curso de SparkDocumento4 páginasBrochure - Curso de SparkjhuaranccacAún no hay calificaciones
- A1 - Mod2 - Unid5 - Procesamiento de Datos en Memoria. Spark CoreDocumento31 páginasA1 - Mod2 - Unid5 - Procesamiento de Datos en Memoria. Spark CoreGabriel Vargas PeñaAún no hay calificaciones
- Completar en Los Campos Diseñados El Tema PropuestoDocumento9 páginasCompletar en Los Campos Diseñados El Tema PropuestoSolo NesTor QuispeAún no hay calificaciones
- Qué Es BigData - EstudioDocumento4 páginasQué Es BigData - EstudioDianaRojasV1Aún no hay calificaciones
- 4 - Spark PDFDocumento42 páginas4 - Spark PDFAngel Pérez SouffrontAún no hay calificaciones
- SparkDocumento20 páginasSparkFredy Johel Peña AlvarezAún no hay calificaciones
- Gestion Memoria IntroduccionDocumento17 páginasGestion Memoria Introduccionsebastian aguilar marinAún no hay calificaciones
- BI&BD - Cap6 MapReduceDocumento15 páginasBI&BD - Cap6 MapReduceAdrian AriasAún no hay calificaciones
- Instalar Apache Spark en Windows 10Documento16 páginasInstalar Apache Spark en Windows 10JuanAún no hay calificaciones
- 3 - Spark DS y Topología Spark Curso BITDocumento36 páginas3 - Spark DS y Topología Spark Curso BITDeogracias PlaudAún no hay calificaciones
- 7.spark SQL EAEDocumento68 páginas7.spark SQL EAEPame PinedaAún no hay calificaciones
- Spark DefinicionDocumento44 páginasSpark DefinicionJota CartesAún no hay calificaciones
- TsojerarquiadememoriasDocumento4 páginasTsojerarquiadememoriasNelson CondoriAún no hay calificaciones
- Paper Procesadores Actuales Achoy DavidDocumento4 páginasPaper Procesadores Actuales Achoy DavidDaniel GamboaAún no hay calificaciones
- Arqui - Compu (Clase 5) Mem. CacheDocumento15 páginasArqui - Compu (Clase 5) Mem. CacheMarko Chambi ColqueAún no hay calificaciones
- 8 La Memoria RamDocumento40 páginas8 La Memoria RamVargas Limachi Kevin EdsonAún no hay calificaciones
- Sesion 3 MemoriasDocumento34 páginasSesion 3 MemoriasJose RojasAún no hay calificaciones
- Los Pilares de ApacheDocumento2 páginasLos Pilares de ApacheEdgar Alexander Jayo PachecoAún no hay calificaciones
- Actividad 6. Investigación SparkDocumento9 páginasActividad 6. Investigación SparkBeatriz C.FloresAún no hay calificaciones
- Learning Spark Lightningfast Big Data Analysis Cap 2 y 3Documento40 páginasLearning Spark Lightningfast Big Data Analysis Cap 2 y 3Patricia Luengo CarreteroAún no hay calificaciones
- Avance Trabajo FinalDocumento6 páginasAvance Trabajo Finalxjeregamerx159Aún no hay calificaciones
- SSD SparkDocumento8 páginasSSD SparkJuan Manuel AlvaradoAún no hay calificaciones
- Apache Spark-Alejandro PalominoDocumento54 páginasApache Spark-Alejandro PalominoLaura BazánAún no hay calificaciones
- 2023 06 11 17 35 09 201910060216 Soporte y MantenimientoDocumento11 páginas2023 06 11 17 35 09 201910060216 Soporte y MantenimientoGerson ManzanaresAún no hay calificaciones
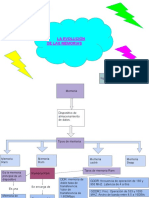
- La Evolucion de Las Memorias 1Documento6 páginasLa Evolucion de Las Memorias 1RosarioAún no hay calificaciones
- Estructura de Un ComputadorpptDocumento11 páginasEstructura de Un ComputadorpptHanna Karam CAún no hay calificaciones
- Procesamiento de Datos Con Apache SparkDocumento7 páginasProcesamiento de Datos Con Apache SparksidenandoAún no hay calificaciones
- 1 Arquitectura de Un Sistema InformaticoDocumento50 páginas1 Arquitectura de Un Sistema InformaticoCOTOBADAAún no hay calificaciones
- Parte 09 Gestion de MemoriaDocumento37 páginasParte 09 Gestion de MemoriaVicctor LlactaAún no hay calificaciones
- IS AC T3 SISTEMA DE MEMORIA 2020 2021 MEM VIRTUAL v4Documento21 páginasIS AC T3 SISTEMA DE MEMORIA 2020 2021 MEM VIRTUAL v4JijjbAún no hay calificaciones
- Tarea 6-El MicroprocesadorDocumento3 páginasTarea 6-El MicroprocesadorDavid Hernandez LopezAún no hay calificaciones
- Micro SDDocumento12 páginasMicro SDJDAVID ALARCOMAún no hay calificaciones
- Tema 6 - Memoria CachéDocumento48 páginasTema 6 - Memoria Cachéserginhomartinez2123Aún no hay calificaciones
- Clase1 Español PDFDocumento64 páginasClase1 Español PDFEMILIO JEREMY MEJIA HUERTASAún no hay calificaciones
- Spark HadoopDocumento7 páginasSpark HadoopJorge VásquezAún no hay calificaciones
- Cómo Funciona Un MicroprocesadorDocumento2 páginasCómo Funciona Un MicroprocesadorJackelin OrozcoAún no hay calificaciones
- Vidama04 Act1Documento9 páginasVidama04 Act1EJIMENEZAún no hay calificaciones
- S201. HadoopDocumento30 páginasS201. HadoopLuis CruzAún no hay calificaciones
- 2020 - Clase Virtual 11 - Hadoop Vs SparkDocumento17 páginas2020 - Clase Virtual 11 - Hadoop Vs SparkFlavio TridicoAún no hay calificaciones
- Taller BoardDocumento8 páginasTaller BoardMIRLEIDIS GRANADOS GUTIERREZAún no hay calificaciones
- Memoria RAM 21.11.20Documento10 páginasMemoria RAM 21.11.20hans blanco floresAún no hay calificaciones
- Spark 2Documento46 páginasSpark 2mauricio995Aún no hay calificaciones
- Apache SparkDocumento11 páginasApache SparklquichimAún no hay calificaciones
- Instancia Oracle: Sesión 01: Configuración de La Instancia OracleDocumento13 páginasInstancia Oracle: Sesión 01: Configuración de La Instancia OracleManuelRomuloAún no hay calificaciones
- EC Curso 2Documento5 páginasEC Curso 2ByronAún no hay calificaciones
- EC Curso 4Documento5 páginasEC Curso 4ByronAún no hay calificaciones
- EC Curso 1Documento4 páginasEC Curso 1ByronAún no hay calificaciones
- EnfermeriaDocumento5 páginasEnfermeriaByronAún no hay calificaciones
- Fibra GPONDocumento1 páginaFibra GPONByronAún no hay calificaciones
- EC Curso 3Documento5 páginasEC Curso 3ByronAún no hay calificaciones
- Matriz de Capacidad Interna PDFDocumento2 páginasMatriz de Capacidad Interna PDFandres pereaAún no hay calificaciones
- Ficha Técnica - FILTER Dragón Iterativo de Filtro-2Documento7 páginasFicha Técnica - FILTER Dragón Iterativo de Filtro-2ByronAún no hay calificaciones
- S203. SqoopDocumento21 páginasS203. SqoopByronAún no hay calificaciones
- Osi Guia CiberataquesDocumento46 páginasOsi Guia CiberataquesDavid PerezAún no hay calificaciones
- Adm Estrategica Del Talento HumanoDocumento8 páginasAdm Estrategica Del Talento HumanoByronAún no hay calificaciones
- Temario Supervisores de ProduccionDocumento17 páginasTemario Supervisores de ProduccionByronAún no hay calificaciones
- Ficha Técnica - FILTER Dragón Iterativo de Filtro-2Documento7 páginasFicha Técnica - FILTER Dragón Iterativo de Filtro-2ByronAún no hay calificaciones
- Certificacià N Integral de Talento Humano AbrilDocumento14 páginasCertificacià N Integral de Talento Humano AbrilByronAún no hay calificaciones
- Manual Sistemas Electricos Motor Bateria Sistemas Arranque Carga Encendido Llave Contacto Sensores PDFDocumento13 páginasManual Sistemas Electricos Motor Bateria Sistemas Arranque Carga Encendido Llave Contacto Sensores PDFornitorrinco33Aún no hay calificaciones
- Manual Electricidad Automotriz Bateria Alternador Bobina Sistemas Electricos Encendido Componentes Sensores CircuitosDocumento91 páginasManual Electricidad Automotriz Bateria Alternador Bobina Sistemas Electricos Encendido Componentes Sensores CircuitosGonzalo Meruvia RojasAún no hay calificaciones
- Mecanica Automotriz - Electric Id Ad Automotriz InacapDocumento124 páginasMecanica Automotriz - Electric Id Ad Automotriz InacapDorian Esquer100% (5)
- S402. HBaseDocumento20 páginasS402. HBaseByronAún no hay calificaciones
- S202. HiveDocumento28 páginasS202. HiveByronAún no hay calificaciones
- S401. Arquitectura de Procesamiento Real-TimeDocumento15 páginasS401. Arquitectura de Procesamiento Real-TimeByronAún no hay calificaciones
- S203. SqoopDocumento21 páginasS203. SqoopByronAún no hay calificaciones
- CableadoDocumento1 páginaCableadoByronAún no hay calificaciones
- S202. HiveDocumento28 páginasS202. HiveByronAún no hay calificaciones
- S401. Arquitectura de Procesamiento Real-TimeDocumento15 páginasS401. Arquitectura de Procesamiento Real-TimeByronAún no hay calificaciones
- S302. SparkDocumento32 páginasS302. SparkByronAún no hay calificaciones
- S402. HBaseDocumento20 páginasS402. HBaseByronAún no hay calificaciones
- Documento de Help DeskDocumento64 páginasDocumento de Help DeskEnrique AñezAún no hay calificaciones
- Examen Tranversal de Inteligencia de NegociosDocumento16 páginasExamen Tranversal de Inteligencia de NegociosMelisaAún no hay calificaciones
- Introduccion PythonDocumento79 páginasIntroduccion PythonLADYS ANGELICA ORTIZ VELASQUEZAún no hay calificaciones
- Aplicaciones de Sistemas de Base de DatosDocumento6 páginasAplicaciones de Sistemas de Base de Datoskaty aguilarAún no hay calificaciones
- SCB1001-ABD Unidad 2Documento39 páginasSCB1001-ABD Unidad 2carlos lopezAún no hay calificaciones
- CB321MRDocumento6 páginasCB321MRMia CanalesAún no hay calificaciones
- Capitulo 2 - Arquitectura ADO - C#Documento10 páginasCapitulo 2 - Arquitectura ADO - C#davoateamAún no hay calificaciones
- DML, DDL y CRUDDocumento4 páginasDML, DDL y CRUDGATOAún no hay calificaciones
- Lenguaje de ConsultaDocumento3 páginasLenguaje de ConsultaSauri VegaAún no hay calificaciones
- Paso1-JOSE RAFUL FRANCODocumento12 páginasPaso1-JOSE RAFUL FRANCOcarolanAún no hay calificaciones
- Solución Guía de Aprendizaje Nro6IntroduccionSQLDocumento11 páginasSolución Guía de Aprendizaje Nro6IntroduccionSQLJulian RuizAún no hay calificaciones
- Ensayo BD NosqlDocumento2 páginasEnsayo BD NosqlabnerAún no hay calificaciones
- Resumen Cuentas Usuario MySQL - UltimoDocumento39 páginasResumen Cuentas Usuario MySQL - Ultimoluis alfredo ocoroAún no hay calificaciones
- Triptico Conceptos Basicos Estructura de Datos (Franciely)Documento2 páginasTriptico Conceptos Basicos Estructura de Datos (Franciely)Maryelis LaraAún no hay calificaciones
- Manual de Oracle XE 11G PDF 12Documento15 páginasManual de Oracle XE 11G PDF 12jose garciaAún no hay calificaciones
- CU-07 Sistema de Servicios Públicos SU y SEU CentralDocumento1 páginaCU-07 Sistema de Servicios Públicos SU y SEU CentralGerard EmmanuelAún no hay calificaciones
- Sat Manager 2.5Documento1 páginaSat Manager 2.5C3DPROLAún no hay calificaciones
- Avanze Del Modulo 3.3Documento11 páginasAvanze Del Modulo 3.3luichigo 222Aún no hay calificaciones
- El Modelos Relacional y La Normalización1 (Diapositivas)Documento76 páginasEl Modelos Relacional y La Normalización1 (Diapositivas)sdsdAún no hay calificaciones
- Guía de Actividades y Rúbrica de Evaluación - Unidad 3 - Paso 4 - Administración de Bases de Datos No RelacionalesDocumento7 páginasGuía de Actividades y Rúbrica de Evaluación - Unidad 3 - Paso 4 - Administración de Bases de Datos No RelacionalesSamuel MolinaAún no hay calificaciones
- Examen Sustitutorio GoDocumento10 páginasExamen Sustitutorio GoShanery Maritzendy Avenda�o VargasAún no hay calificaciones
- Power Builder - Procedimientos AlmacenadosDocumento6 páginasPower Builder - Procedimientos AlmacenadosAlex Omar Bardales LoyagaAún no hay calificaciones
- PZSE0005 ListadoDocumento2 páginasPZSE0005 Listadovcusco.isttAún no hay calificaciones
- Bases de Datos 2 FORODocumento1 páginaBases de Datos 2 FORONicolasVargasJimenezAún no hay calificaciones
- AP4-AA2-Ev2-Modelo Relacional de La Base de Datos Del Proyecto de FormaciónDocumento7 páginasAP4-AA2-Ev2-Modelo Relacional de La Base de Datos Del Proyecto de Formaciónkarolina cortesAún no hay calificaciones
- Unidad 5 Normalizacion Falta EjemplosDocumento3 páginasUnidad 5 Normalizacion Falta Ejemploscarli_leal1Aún no hay calificaciones
- Lmco - U5 - P8 - Abd - Migración de Bases de DatosDocumento17 páginasLmco - U5 - P8 - Abd - Migración de Bases de DatosVii SánchezAún no hay calificaciones
- Proyecto Estancia 2 AlanDocumento82 páginasProyecto Estancia 2 AlanAlán Montes De Oca ArcosAún no hay calificaciones
- Proyecto Conrol de Pagos y Rutas EscolarDocumento16 páginasProyecto Conrol de Pagos y Rutas Escolarangel urregoAún no hay calificaciones