También podría gustarte
- Farmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1De EverandFarmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1Aún no hay calificaciones
- Cuadro SinopticoDocumento3 páginasCuadro SinopticoAlejandro Cendales Vidal100% (1)
- Unidad V Regresion Lineal Equipo 5Documento11 páginasUnidad V Regresion Lineal Equipo 5Alain A. Gómez CárdenasAún no hay calificaciones
- Subtema 1.3.1Documento2 páginasSubtema 1.3.1Mitchel Alemán PavónAún no hay calificaciones
- 4.2. Producción Con Dos Insumos VariablesDocumento3 páginas4.2. Producción Con Dos Insumos VariablesLizzyMartínezAún no hay calificaciones
- Investigacion de Operaciones y Modelos de Optimizacion de RecursosDocumento32 páginasInvestigacion de Operaciones y Modelos de Optimizacion de RecursosArmando Ruelas Aguilar100% (1)
- Traslacion y RotacionDocumento7 páginasTraslacion y RotacionING. GUSTAVO HERRERA CONTRERASAún no hay calificaciones
- 2.3. - Clasificación de Las MatricesDocumento4 páginas2.3. - Clasificación de Las MatricesHenry MartinezAún no hay calificaciones
- Unidad 3 Estadística InferencialDocumento30 páginasUnidad 3 Estadística InferencialelmerAún no hay calificaciones
- Unidad 4 Pruebas de Bondad de Ajuste y Pruebas No ParametricasDocumento7 páginasUnidad 4 Pruebas de Bondad de Ajuste y Pruebas No ParametricasJose Abraham Hernandez Mendez0% (2)
- Generacion de Numeros AleatoriosDocumento27 páginasGeneracion de Numeros Aleatoriosjuan arevaloAún no hay calificaciones
- Unidad Iv Diseño de Bloques Completos Al AzarDocumento4 páginasUnidad Iv Diseño de Bloques Completos Al AzarFernando leonAún no hay calificaciones
- Capitulo 15 Series de Tiempo - Variacion CiclicaDocumento9 páginasCapitulo 15 Series de Tiempo - Variacion CiclicaKeila OrtizAún no hay calificaciones
- Actividad 4.3Documento16 páginasActividad 4.3Ruben Lopez RicoAún no hay calificaciones
- Ejercicios EstadisticaDocumento3 páginasEjercicios EstadisticaDanielGP7739Aún no hay calificaciones
- Factor de Serie UniformeDocumento1 páginaFactor de Serie UniformeYisus Garcia OrtizAún no hay calificaciones
- 1.4 Modelos de Una Sola MetaDocumento5 páginas1.4 Modelos de Una Sola MetaOliver Yael Juarez Uribe100% (1)
- Regresión Lineal Múltiple A ManoDocumento3 páginasRegresión Lineal Múltiple A ManoBenigno BurgosAún no hay calificaciones
- Portafolio Unidad 7Documento7 páginasPortafolio Unidad 7Jesus GarciaAún no hay calificaciones
- U 3 D MuestreoDocumento2 páginasU 3 D MuestreoCristian Orozco RamírezAún no hay calificaciones
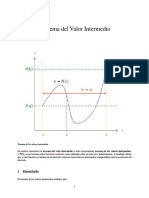
- Teorema Del Valor IntermedioDocumento6 páginasTeorema Del Valor IntermedioElmer IchAún no hay calificaciones
- Funciones VectorialesDocumento12 páginasFunciones VectorialesErik VillegasAún no hay calificaciones
- VARIACIONES ESTACIONALES e IIREGULARESDocumento11 páginasVARIACIONES ESTACIONALES e IIREGULARESDrick CrisantoAún no hay calificaciones
- Ejercicio MinitabDocumento2 páginasEjercicio MinitabYaine Meza FonsecaAún no hay calificaciones
- Método DualDocumento9 páginasMétodo DualCarlos Bibiano DiazAún no hay calificaciones
- 1.7 Organismos de Normalización Y Certificación: Actualmente Existen 10 ONN RegistradosDocumento10 páginas1.7 Organismos de Normalización Y Certificación: Actualmente Existen 10 ONN RegistradosJose Raul Morales Aguilar100% (1)
- Sesión 3.3 Medidas de Dispersión y FormaDocumento29 páginasSesión 3.3 Medidas de Dispersión y FormaLuis Manuel Huaman MartinesAún no hay calificaciones
- Funciones Vectoriales de Una Variable RealDocumento6 páginasFunciones Vectoriales de Una Variable RealPedro Flores CeledónAún no hay calificaciones
- Cadenas de Markov Unidad 4 Investigación de OperacionesDocumento13 páginasCadenas de Markov Unidad 4 Investigación de OperacionesJesus TorresAún no hay calificaciones
- Distribución MuestralDocumento6 páginasDistribución Muestralchcluz100% (5)
- Regresión Lineal Simple FormularioDocumento5 páginasRegresión Lineal Simple Formularioniti100% (1)
- Base y Dimensiones de Un Espacio VectorialDocumento18 páginasBase y Dimensiones de Un Espacio VectorialCecy CruzAún no hay calificaciones
- Comparaciones o Pruebas de Rango MultipleDocumento15 páginasComparaciones o Pruebas de Rango MultipleSergio Adrián TadeoAún no hay calificaciones
- Diseño Experimental 5 PROBLEMASDocumento37 páginasDiseño Experimental 5 PROBLEMASKeedy León GalarzaAún no hay calificaciones
- Estimación de La Proporción de La PoblaciónDocumento4 páginasEstimación de La Proporción de La PoblaciónMariaAlejandraLineroAún no hay calificaciones
- Teorema de VarignonDocumento3 páginasTeorema de VarignonminenesamaAún no hay calificaciones
- Mapa ConceptualDocumento4 páginasMapa ConceptualJorge Anfibio Garduza AlorAún no hay calificaciones
- Equivalencia, Congruencia y Semejanza de Matrices.Documento5 páginasEquivalencia, Congruencia y Semejanza de Matrices.AmIn20122Aún no hay calificaciones
- Diseños FactorialesDocumento6 páginasDiseños FactorialesSkyrest OrtizAún no hay calificaciones
- Antropomertia Estatica y DinamicaDocumento1 páginaAntropomertia Estatica y Dinamicacxrlitos pxnditx0% (1)
- Reporte Series IntegralDocumento22 páginasReporte Series IntegralAbel Jimenez HurtadoAún no hay calificaciones
- Clasificación Por Sectores y Ramas Industriales.Documento8 páginasClasificación Por Sectores y Ramas Industriales.JONATHAN BELTRAN ZAVALAAún no hay calificaciones
- Cuadro Comparativo Sobre Tipos de DistribuciónDocumento11 páginasCuadro Comparativo Sobre Tipos de DistribuciónAlejandra ChacónAún no hay calificaciones
- Prueba de Kolmogorov-SmirnovDocumento10 páginasPrueba de Kolmogorov-SmirnovIgnacioAún no hay calificaciones
- Clasificación de TablerosDocumento3 páginasClasificación de Tablerosvictor manuel vergara duarteAún no hay calificaciones
- 2.4.1 Intervalo de Confianza para La Media, 2.4.2 Intervalo de Confianza para La Diferencia de MediasDocumento5 páginas2.4.1 Intervalo de Confianza para La Media, 2.4.2 Intervalo de Confianza para La Diferencia de MediasXimena RamírezAún no hay calificaciones
- Matriz Varianza - Docx 2Documento5 páginasMatriz Varianza - Docx 2Altagracia MLAún no hay calificaciones
- 2.4 Transformaciones Elementales Por Renglón. Escalonamiento de Una Matriz. Rango de Una Matriz.Documento2 páginas2.4 Transformaciones Elementales Por Renglón. Escalonamiento de Una Matriz. Rango de Una Matriz.SACD9999Aún no hay calificaciones
- 3.8 Medidores de Torsión - MetrologiaDocumento7 páginas3.8 Medidores de Torsión - MetrologiaWil Lopez MartinezAún no hay calificaciones
- Teoría de LA PRODUCCION Y LOS Costos PDFDocumento25 páginasTeoría de LA PRODUCCION Y LOS Costos PDFANDREA CAROLINA VALDERRAMA MARTINEZAún no hay calificaciones
- 2.2 Finalidad de La OperacionDocumento12 páginas2.2 Finalidad de La OperacionAdriel MoralesAún no hay calificaciones
- Valor Esperado de Una v. A.Documento31 páginasValor Esperado de Una v. A.pavaevAún no hay calificaciones
- ¿Quién Es El CENAMDocumento2 páginas¿Quién Es El CENAMIsaac VillamaresAún no hay calificaciones
- Comparacion o Prueba de Rangos MultiplesDocumento22 páginasComparacion o Prueba de Rangos MultiplesSerch Xp0% (1)
- 2.3 Propiedades Térmicas de Los MaterialesDocumento2 páginas2.3 Propiedades Térmicas de Los MaterialesAlondra GallardoAún no hay calificaciones
- Álgebra Lineal - 3.3 Interpretación Geométrica de Las Soluciones - PDFDocumento2 páginasÁlgebra Lineal - 3.3 Interpretación Geométrica de Las Soluciones - PDFOscar CalihuaAún no hay calificaciones
- Trabajo de Diferencia MinimaDocumento25 páginasTrabajo de Diferencia MinimaLuis RamosAún no hay calificaciones
- Pruebas Post Hoc PDFDocumento3 páginasPruebas Post Hoc PDFRoy Garrido CruzadoAún no hay calificaciones
- Pruebas de Comparación MultipleDocumento13 páginasPruebas de Comparación MultiplevyvizAún no hay calificaciones
- Mètodo Tukey y DuncanDocumento24 páginasMètodo Tukey y DuncanZeus LvAún no hay calificaciones
- MERCASOLDocumento3 páginasMERCASOLCETROMAún no hay calificaciones
- Idea de Un Producto o ServicioDocumento3 páginasIdea de Un Producto o ServicioCETROMAún no hay calificaciones
- Tarea 4 NECESIDADES Gonzalez RodriguezDocumento1 páginaTarea 4 NECESIDADES Gonzalez RodriguezCETROMAún no hay calificaciones
- Segmentacion Ubersexual y MetrosexualDocumento4 páginasSegmentacion Ubersexual y MetrosexualCETROMAún no hay calificaciones
- Tarea 4 NECESIDADES Gonzalez RodriguezDocumento1 páginaTarea 4 NECESIDADES Gonzalez RodriguezCETROMAún no hay calificaciones
- Al Ver El Titulo Derechos HumanosDocumento3 páginasAl Ver El Titulo Derechos HumanosCETROMAún no hay calificaciones
- Tarea 1 Conceptos de MercadotecniaDocumento2 páginasTarea 1 Conceptos de MercadotecniaCETROMAún no hay calificaciones
- EQUIPO 4 - ESTADISTICA - U3 - Parte 2Documento23 páginasEQUIPO 4 - ESTADISTICA - U3 - Parte 2CETROMAún no hay calificaciones
- Equipo 5 Estadistica U4 Parte 1Documento33 páginasEquipo 5 Estadistica U4 Parte 1CETROMAún no hay calificaciones
- EQUIPO 4 - ESTADISTICA - Parte 1Documento23 páginasEQUIPO 4 - ESTADISTICA - Parte 1CETROMAún no hay calificaciones
- EQUIPO 5 - ESTADISTICA - U5 - Parte 1Documento26 páginasEQUIPO 5 - ESTADISTICA - U5 - Parte 1CETROMAún no hay calificaciones
- Equipo 5 Estadistica U4 Parte 1Documento33 páginasEquipo 5 Estadistica U4 Parte 1CETROMAún no hay calificaciones
- EQUIPO 3 - ESTADISTICA - U4 - Parte 1Documento24 páginasEQUIPO 3 - ESTADISTICA - U4 - Parte 1CETROMAún no hay calificaciones
- Industria de Generación Eléctrica1Documento4 páginasIndustria de Generación Eléctrica1CETROMAún no hay calificaciones
- Tarea 4 NECESIDADES Gonzalez RodriguezDocumento1 páginaTarea 4 NECESIDADES Gonzalez RodriguezCETROMAún no hay calificaciones
- Tarea 7 UN3sDocumento6 páginasTarea 7 UN3sCETROMAún no hay calificaciones
- Tarea 1 Conceptos de MercadotecniaDocumento2 páginasTarea 1 Conceptos de MercadotecniaCETROMAún no hay calificaciones
- Mapa MentalDocumento2 páginasMapa MentalCETROMAún no hay calificaciones
- Unidad IIDocumento14 páginasUnidad IINelson Romero MéndezAún no hay calificaciones
- Tarea 2 Importancia de MercadotecniaDocumento3 páginasTarea 2 Importancia de MercadotecniaCETROMAún no hay calificaciones
- Investigacion MexicanaDocumento1 páginaInvestigacion MexicanaCETROMAún no hay calificaciones
- Compet I DoresDocumento1 páginaCompet I DoresCETROMAún no hay calificaciones
- TECMDocumento5 páginasTECMCETROMAún no hay calificaciones
- Unidad IIDocumento14 páginasUnidad IINelson Romero MéndezAún no hay calificaciones
- 4.2.1 Plan de Muestro de Aceptacion Por AtributosDocumento2 páginas4.2.1 Plan de Muestro de Aceptacion Por AtributosCETROM100% (1)
- 3.2 Grafico NPDocumento1 página3.2 Grafico NPCETROMAún no hay calificaciones
- AE044 MecadotecniaDocumento12 páginasAE044 MecadotecniaEliseo Zetina IslasAún no hay calificaciones
- IZTAPALAPADocumento3 páginasIZTAPALAPACETROMAún no hay calificaciones
- Unidad 2 Rev 2 PDFDocumento73 páginasUnidad 2 Rev 2 PDFCETROMAún no hay calificaciones
- S2 T1 Estimación de Intervalos para El Cociente de Varianzas y Diferencia de MediasDocumento18 páginasS2 T1 Estimación de Intervalos para El Cociente de Varianzas y Diferencia de MediasKatherine Bermejo VichinoAún no hay calificaciones
- Evaluacion FinalDocumento7 páginasEvaluacion FinalADITEC HOGARAún no hay calificaciones
- Problema Propuesto Semana 021Documento29 páginasProblema Propuesto Semana 021JOSSELYN DIANA YALICO CARHUALLANQUIAún no hay calificaciones
- Copia de Guia 63 - Meta 21 - Grado 6 - EstudianteDocumento16 páginasCopia de Guia 63 - Meta 21 - Grado 6 - EstudianteArlen Adan Pineda CastilloAún no hay calificaciones
- Hoja 6 PDFDocumento3 páginasHoja 6 PDFIvan EpAún no hay calificaciones
- U3-6. Analisis de Varianza ANOVA 1FDocumento17 páginasU3-6. Analisis de Varianza ANOVA 1FCarlos Steven Gaibor BohorquezAún no hay calificaciones
- Desviación TípicaDocumento3 páginasDesviación TípicaDavid SSMAún no hay calificaciones
- Resumen Prueba de Hipotesis Dos PoblacionDocumento23 páginasResumen Prueba de Hipotesis Dos PoblacionJuan Esteban Ayala0% (1)
- 1 - Cap 6-7-8-9 Estad - Infer 23 Mayo 2022Documento41 páginas1 - Cap 6-7-8-9 Estad - Infer 23 Mayo 2022Pavel CabasAún no hay calificaciones
- Informe Muestreo EstadísticoDocumento24 páginasInforme Muestreo EstadísticoPedro Q GabrielAún no hay calificaciones
- Poblacion y MuestraaDocumento10 páginasPoblacion y MuestraaYOSELINAún no hay calificaciones
- Foro Act 1 Unidad 2Documento3 páginasForo Act 1 Unidad 2ALFREDO RUIZ HERRERAAún no hay calificaciones
- Practica 1 Matematica FinancieraDocumento3 páginasPractica 1 Matematica FinancieraKeshava Montas bAún no hay calificaciones
- Parcial ProbabilidadDocumento5 páginasParcial ProbabilidadAlexis Santiago50% (2)
- EjerciciosDocumento14 páginasEjerciciosTito Carling Arbe CastilloAún no hay calificaciones
- Practica CalificadaDocumento8 páginasPractica CalificadaDenis Huallanca BlasAún no hay calificaciones
- Metodos Estadisticos - Unidad 5Documento5 páginasMetodos Estadisticos - Unidad 5Mademoiselle HugAún no hay calificaciones
- Act 4 CorreDocumento4 páginasAct 4 Correvalerie2911Aún no hay calificaciones
- Problema 1Documento5 páginasProblema 1HOMAR HERNANDEZ100% (1)
- Trabajo 1 PDFDocumento3 páginasTrabajo 1 PDFMarcus FigueroaAún no hay calificaciones
- Examen Parcial 1 - Ahumada Farfán EduardoDocumento11 páginasExamen Parcial 1 - Ahumada Farfán EduardoEduardo Ahumada FarfanAún no hay calificaciones
- 3.3 ProbabilidadDocumento41 páginas3.3 ProbabilidadPedro CouohAún no hay calificaciones
- Experimentos Factoriales (Ef)Documento22 páginasExperimentos Factoriales (Ef)YURANI VAZQUEZ AGUILERA100% (4)
- Ejercicios de Repaso Solemne 2 FMS 370Documento12 páginasEjercicios de Repaso Solemne 2 FMS 370Luis Miguel Catricheo MoralesAún no hay calificaciones
- Conceptos Bacicos de MuestreoDocumento10 páginasConceptos Bacicos de MuestreoANGELICA FRANCISCO PERALTAAún no hay calificaciones
- Intervalos de ConfianzaDocumento6 páginasIntervalos de ConfianzaIthan löweAún no hay calificaciones
- TareaDocumento8 páginasTareaSantiago Ruiz ChávezAún no hay calificaciones
- Actividad de Puntos Evaluables - Escenario 6 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO B07)Documento5 páginasActividad de Puntos Evaluables - Escenario 6 - SEGUNDO BLOQUE-CIENCIAS BASICAS - ESTADISTICA II - (GRUPO B07)andyrodtallAún no hay calificaciones
- Pruebas de Bondad de Ajuste y No Paramétricas QWExDocumento18 páginasPruebas de Bondad de Ajuste y No Paramétricas QWExEmiliano Guzman UribeAún no hay calificaciones
- Test Hipotesis 1Documento33 páginasTest Hipotesis 1MariaAún no hay calificaciones