También podría gustarte
- Regresión y CorrelaciónDocumento22 páginasRegresión y CorrelaciónFenix FrieAún no hay calificaciones
- tal como se solicitóDocumento52 páginastal como se solicitóJoset Ramos Palacios100% (1)
- Análisis Regresión LinealDocumento17 páginasAnálisis Regresión LinealSteven Cerna MejiaAún no hay calificaciones
- Regresión y correlación en control de calidadDocumento12 páginasRegresión y correlación en control de calidadJesús de la Cruz25% (4)
- Ensayo EstadisticoDocumento9 páginasEnsayo EstadisticoGino ReyesAún no hay calificaciones
- RegresionDocumento17 páginasRegresionyasuri del rosario Ramirez AcuñaAún no hay calificaciones
- Construcción bicicleta paso a pasoDocumento1 páginaConstrucción bicicleta paso a pasoAmbar Lisbeth RodriguezAún no hay calificaciones
- Analisis de Regresion y CorrelacionDocumento37 páginasAnalisis de Regresion y CorrelacionRose Lozano100% (1)
- Costo de oportunidad: la mejor alternativa perdidaDocumento49 páginasCosto de oportunidad: la mejor alternativa perdidaMassielAún no hay calificaciones
- Conceptos Basicos de Regresion LinealDocumento8 páginasConceptos Basicos de Regresion LinealGiovanna Karen Espinoza100% (1)
- Unidad 2 Estadistica Inferencial 2Documento10 páginasUnidad 2 Estadistica Inferencial 2Vallolet Juarez AcostaAún no hay calificaciones
- Regresión y Correlación Lineal Simple ResumenDocumento6 páginasRegresión y Correlación Lineal Simple ResumenRocael OrozcoAún no hay calificaciones
- RegresionDocumento23 páginasRegresionCesar Augusto Barrios FloresAún no hay calificaciones
- Tema 5 EstadísticaDocumento4 páginasTema 5 EstadísticaPilar MuÑoz100% (1)
- Análisis regresión correlaciónDocumento16 páginasAnálisis regresión correlaciónJhony Ramirez BazanAún no hay calificaciones
- ACT01P1 Castillo Mar AlejandraDocumento11 páginasACT01P1 Castillo Mar AlejandraAlejandra CastilloAún no hay calificaciones
- Regresion LinealDocumento23 páginasRegresion LinealEric ManuelAún no hay calificaciones
- Proyecto Integrador2 Analisis de Datos PDFDocumento65 páginasProyecto Integrador2 Analisis de Datos PDFJuan Manuel Garcia HernandezAún no hay calificaciones
- Análisis de Regresión-1Documento7 páginasAnálisis de Regresión-1San Marcos EstadisticaAún no hay calificaciones
- Investigacion Regresión y Correlación PDFDocumento23 páginasInvestigacion Regresión y Correlación PDFRichardVelasquez100% (1)
- Primer Parcial Econometría IDocumento18 páginasPrimer Parcial Econometría IGenesis Roxanna Mogrovejo AndradeAún no hay calificaciones
- Analisis de Regresion GenessisDocumento11 páginasAnalisis de Regresion GenessisReiner ZambranoAún no hay calificaciones
- Tema 2 ResumenDocumento9 páginasTema 2 ResumenDiego Javier Jimenez MataAún no hay calificaciones
- Cap 3 - Regresión y CorrelaciónDocumento16 páginasCap 3 - Regresión y CorrelaciónGaryEduardoNuñezLiAún no hay calificaciones
- Regresión y CorrelaciónDocumento13 páginasRegresión y CorrelaciónMax CanoAún no hay calificaciones
- 5.1 Regresión Lineal Simple y Correlación.Documento40 páginas5.1 Regresión Lineal Simple y Correlación.Ana Laura López OrocioAún no hay calificaciones
- Modelo de RegresiónDocumento4 páginasModelo de Regresiónedgar pombozaAún no hay calificaciones
- Tema 7. Regresión y CorrelaciónDocumento15 páginasTema 7. Regresión y Correlaciónyenifer alexia colmenares camargoAún no hay calificaciones
- Medidas Estadísticas BivariantesDocumento37 páginasMedidas Estadísticas BivariantesFabian Andres MoraAún no hay calificaciones
- Regresión lineal simple: introducción al análisis de regresiónDocumento28 páginasRegresión lineal simple: introducción al análisis de regresiónvcamposr100% (1)
- Diagrama de CorrelaciónDocumento12 páginasDiagrama de CorrelaciónEduardo Castro Mtz100% (1)
- Expo 1Documento15 páginasExpo 1WilliamGuillermoVegaBocanegraAún no hay calificaciones
- Tecnicas de Estadistica - RegresiónDocumento20 páginasTecnicas de Estadistica - RegresiónRenzo BassAún no hay calificaciones
- Regresión lineal simple: predecir una variable a partir de otraDocumento7 páginasRegresión lineal simple: predecir una variable a partir de otraLIGIA EVELISA RAMIREZ GONZALEZAún no hay calificaciones
- Regresion LinealDocumento28 páginasRegresion LinealAlexandro Barradas DíazAún no hay calificaciones
- Análisiss de Regresión y CorrelaciónDocumento34 páginasAnálisiss de Regresión y CorrelaciónBETHIA KEREN ZEVALLOS SALAZARAún no hay calificaciones
- Segundo Trabajo de EstadisticaDocumento24 páginasSegundo Trabajo de EstadisticaMaria Meneses MezaAún no hay calificaciones
- Regresion y Correlacion Simple UTLDocumento15 páginasRegresion y Correlacion Simple UTLjesustorresAún no hay calificaciones
- Analisis de Regresion y CorrelacionDocumento7 páginasAnalisis de Regresion y CorrelacionRicardo Garcia GuzmanAún no hay calificaciones
- Análisis de regresión y correlación: métodos para medir la relación entre variablesDocumento13 páginasAnálisis de regresión y correlación: métodos para medir la relación entre variablesJesús Rolando Figueroa CampanaAún no hay calificaciones
- Sesion 04 - Analisis de Regresion y CorrelacionDocumento13 páginasSesion 04 - Analisis de Regresion y CorrelacionDINA QUISPE PAPELAún no hay calificaciones
- Análisis Regresión CorrelaciónDocumento28 páginasAnálisis Regresión CorrelaciónSantiago Ulloa CamachoAún no hay calificaciones
- Regresión y Correlación LinealDocumento9 páginasRegresión y Correlación LinealDelfina GandolfoAún no hay calificaciones
- EstaticaDocumento15 páginasEstaticaLuis Fernando BatistaAún no hay calificaciones
- PreguntasDocumento4 páginasPreguntasAriel MonzónAún no hay calificaciones
- Teoría correlación múltipleDocumento8 páginasTeoría correlación múltipleBlady AnAún no hay calificaciones
- CORRELACION Y REGRESIONDocumento5 páginasCORRELACION Y REGRESIONMauricio NievaAún no hay calificaciones
- Análisis correlación ExcelDocumento19 páginasAnálisis correlación Excelnaval1879Aún no hay calificaciones
- Universidad Latina de PanamáDocumento8 páginasUniversidad Latina de PanamáCaryAcevedo01Aún no hay calificaciones
- Probabilidad Unidad 5 y 6Documento37 páginasProbabilidad Unidad 5 y 6Zury JiménezAún no hay calificaciones
- Regresion LinealDocumento8 páginasRegresion LinealFernanfloo FooAún no hay calificaciones
- Inferencia Estadistica Anthony MelendezDocumento60 páginasInferencia Estadistica Anthony MelendezAnthony Melendez BaezAún no hay calificaciones
- Actividad 2 EstadisticaDocumento5 páginasActividad 2 EstadisticaJaneth NarvaezAún no hay calificaciones
- CorrelacionDocumento12 páginasCorrelacionCruz Sanchez ObedAún no hay calificaciones
- Regresion y Correlacion LinealDocumento16 páginasRegresion y Correlacion LinealAlfredo Avendaño SerranoAún no hay calificaciones
- Contraste Hipotesis 3rDocumento15 páginasContraste Hipotesis 3rCesar Cieza SantillanAún no hay calificaciones
- Regresion Simple 2022 11Documento27 páginasRegresion Simple 2022 11Dannis Omar Campos ZavaletaAún no hay calificaciones
- Regresion LinealDocumento6 páginasRegresion LinealKenchi OcañaAún no hay calificaciones
- Practica Final 2021 2Documento2 páginasPractica Final 2021 2Ambar Lisbeth RodriguezAún no hay calificaciones
- Estudio de Capacidad de ProcesoDocumento1 páginaEstudio de Capacidad de ProcesoAmbar Lisbeth RodriguezAún no hay calificaciones
- TERCERA PARTE Virtual2Documento13 páginasTERCERA PARTE Virtual2Ambar Lisbeth RodriguezAún no hay calificaciones
- Gráficos de ControlDocumento2 páginasGráficos de ControlAmbar Lisbeth RodriguezAún no hay calificaciones
- ProgramaDocumento1 páginaProgramaAmbar Lisbeth RodriguezAún no hay calificaciones
- Componentes y operaciones de una bicicletaDocumento6 páginasComponentes y operaciones de una bicicletaAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 4 - El MuestreoDocumento14 páginasTema 4 - El MuestreoAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 5 - Metódos de EstimaciónDocumento16 páginasTema 5 - Metódos de EstimaciónAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 5 - Metódos de EstimaciónDocumento16 páginasTema 5 - Metódos de EstimaciónAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 6 - Prueba de HipotesisDocumento18 páginasTema 6 - Prueba de HipotesisAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 5 - Metódos de EstimaciónDocumento16 páginasTema 5 - Metódos de EstimaciónAmbar Lisbeth RodriguezAún no hay calificaciones
- Comparacion de Alternativas Corregida21Documento68 páginasComparacion de Alternativas Corregida21Ambar Lisbeth RodriguezAún no hay calificaciones
- Tarea II - Ambar Rodríguez - 100439585 - Unidad 4Documento1 páginaTarea II - Ambar Rodríguez - 100439585 - Unidad 4Ambar Lisbeth RodriguezAún no hay calificaciones
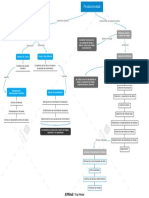
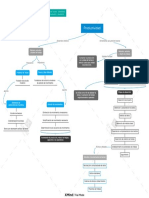
- ProductividadDocumento1 páginaProductividadAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 7 - Control Estadistico de Calidad - Informe de LecturaDocumento9 páginasTema 7 - Control Estadistico de Calidad - Informe de LecturaAmbar Lisbeth RodriguezAún no hay calificaciones
- Tarea I - Ambar Rodríguez - 100439585Documento1 páginaTarea I - Ambar Rodríguez - 100439585Ambar Lisbeth RodriguezAún no hay calificaciones
- Valeska Feliz Matos 100292911Documento6 páginasValeska Feliz Matos 100292911Valeska FelizAún no hay calificaciones
- Ámbar Rodríguez - 100439585 - DiseñoDocumento6 páginasÁmbar Rodríguez - 100439585 - DiseñoAmbar Lisbeth RodriguezAún no hay calificaciones
- Trabajo de Investigación FinalDocumento11 páginasTrabajo de Investigación FinalAmbar Lisbeth RodriguezAún no hay calificaciones
- IEM-2020 Unidad No.1Documento12 páginasIEM-2020 Unidad No.1Vianny Arlette Gomez HenriquezAún no hay calificaciones
- Jaula de Faraday - 100439585Documento4 páginasJaula de Faraday - 100439585Ambar Lisbeth RodriguezAún no hay calificaciones
- Materiales Ferromagneticos, Diamagenticos y ParamagneticosDocumento4 páginasMateriales Ferromagneticos, Diamagenticos y ParamagneticosAmbar Lisbeth RodriguezAún no hay calificaciones
- Como Funciona Un TransformadorDocumento15 páginasComo Funciona Un TransformadorAmbar Lisbeth RodriguezAún no hay calificaciones
- Tema 4 - El MuestreoDocumento14 páginasTema 4 - El MuestreoAmbar Lisbeth RodriguezAún no hay calificaciones
- 3-Trabajo Practico N1 EdDocumento5 páginas3-Trabajo Practico N1 EdAgusdeArtiagoitiaAún no hay calificaciones
- Eta CuadradoDocumento11 páginasEta Cuadradomargie mezaAún no hay calificaciones
- HIPOTESISDocumento53 páginasHIPOTESISRay Garcia OrtizAún no hay calificaciones
- Ejercicios ResueltosDocumento126 páginasEjercicios ResueltosPoder Gitano Dinastia Salvador0% (1)
- Examen de La I Unidad 2021 - IDocumento6 páginasExamen de La I Unidad 2021 - IRAIY IDOSKY VEGA MACEDAAún no hay calificaciones
- Tema 1 Conceptos BasicosDocumento58 páginasTema 1 Conceptos BasicosValeria VelazquezAún no hay calificaciones
- Metodos-Estadisticos-Para-La-Investigacion Continuación PDFDocumento65 páginasMetodos-Estadisticos-Para-La-Investigacion Continuación PDFWILSON DANIEL CHICANA ZAPATAAún no hay calificaciones
- Actividad #4 - IOCDocumento16 páginasActividad #4 - IOCAlexey RojasAún no hay calificaciones
- Preguntero Estadística II - Siglo 21Documento31 páginasPreguntero Estadística II - Siglo 21Andres Villarroel67% (3)
- Trabajo Grupal #2Documento5 páginasTrabajo Grupal #2maria recalde100% (1)
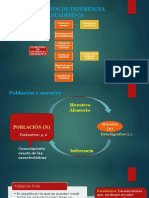
- Elementos de Inferencia EstadísticaDocumento22 páginasElementos de Inferencia EstadísticaBryan DarkAún no hay calificaciones
- Actividad Evaluativa Eje 3 Andrea GarciaDocumento16 páginasActividad Evaluativa Eje 3 Andrea GarciaPAOLA ANDREA GARCIA FAJARDOAún no hay calificaciones
- U2 Act2 Variabilidad GNPGDocumento10 páginasU2 Act2 Variabilidad GNPGGloria NohemíAún no hay calificaciones
- Validación sistemas medición laboratoriosDocumento14 páginasValidación sistemas medición laboratoriosGERARDO RAFAEL REYNOSO IBARRAAún no hay calificaciones
- 4 GGFFFDocumento2 páginas4 GGFFFFranco Barra UlloaAún no hay calificaciones
- T5 Region CríticaDocumento5 páginasT5 Region Críticaalison vannesa guevara burbanoAún no hay calificaciones
- Practica Sobe Medidad de CentralizaciónDocumento2 páginasPractica Sobe Medidad de CentralizaciónAron Vargas YucraAún no hay calificaciones
- Tamaño de Una MuestraDocumento3 páginasTamaño de Una Muestraandry shalomAún no hay calificaciones
- Explica Cinta de KendallDocumento8 páginasExplica Cinta de KendallIan NuñezAún no hay calificaciones
- Análisis Estadístico Desempleo ColombiaDocumento11 páginasAnálisis Estadístico Desempleo ColombiaWilder DazaAún no hay calificaciones
- ANOVA multifactorialDocumento14 páginasANOVA multifactorialJose Luis Lozoya GarciaAún no hay calificaciones
- Caso Milan 1Documento7 páginasCaso Milan 1Ingrid CastilloAún no hay calificaciones
- Análisis comparativo medias tratamientosDocumento10 páginasAnálisis comparativo medias tratamientosRichard FelipeAún no hay calificaciones
- Estadística Inferencial II - Unidad I.: Antología Regresión Lineal MúltipleDocumento40 páginasEstadística Inferencial II - Unidad I.: Antología Regresión Lineal MúltipleAngel Del Angel Del AngelAún no hay calificaciones
- Sustentacion Trabajo Colaborativo - Escenario 7 - PRIMER BLOQUE-CIENCIAS BASICAS - VIRTUAL - ESTADÍSTICA INFERENCIAL - (GRUPO B03)Documento5 páginasSustentacion Trabajo Colaborativo - Escenario 7 - PRIMER BLOQUE-CIENCIAS BASICAS - VIRTUAL - ESTADÍSTICA INFERENCIAL - (GRUPO B03)Andres LealAún no hay calificaciones
- Análisis no paramétricos Kruskal-Wallis FriedmanDocumento10 páginasAnálisis no paramétricos Kruskal-Wallis FriedmanRocyta Caceres PerezAún no hay calificaciones
- Ejercicios Minitab U2 v3Documento21 páginasEjercicios Minitab U2 v3Nick PrietoAún no hay calificaciones
- Medidas Tendencia CentralDocumento2 páginasMedidas Tendencia CentralCarolina Herrera GámezAún no hay calificaciones
- Que Es La ConfiabilidadDocumento4 páginasQue Es La Confiabilidadlopeznomar63Aún no hay calificaciones