También podría gustarte
- Econometría Práctica 1Documento13 páginasEconometría Práctica 1Like New50% (2)
- Taller 2 EconometriaDocumento6 páginasTaller 2 EconometriaAdriana Gavilan Beltran100% (1)
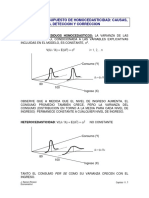
- DETECCIÓN Y CORRECCIÓN DE HETEROCEDASTICIDADDocumento10 páginasDETECCIÓN Y CORRECCIÓN DE HETEROCEDASTICIDADFlor Chura YucraAún no hay calificaciones
- Analisis-de-Covarianza Ejercicio 1Documento10 páginasAnalisis-de-Covarianza Ejercicio 1Ronal Brayam Sandoval ZuñigaAún no hay calificaciones
- Actividad 5. Regresión y Correlación Múltiple.Documento5 páginasActividad 5. Regresión y Correlación Múltiple.Asociacion mAún no hay calificaciones
- UOC-Psicología-Psicometría PEC1 AlumnoDocumento19 páginasUOC-Psicología-Psicometría PEC1 Alumnobelen060Aún no hay calificaciones
- Est Ad Is Tic A 4Documento22 páginasEst Ad Is Tic A 4Edgard Perez-Palma100% (1)
- TEMA 3. EconometríaDocumento75 páginasTEMA 3. Econometríasandra gomezAún no hay calificaciones
- Modelo de regresión simple: definición y supuestos claveDocumento59 páginasModelo de regresión simple: definición y supuestos claveSusana González RuizAún no hay calificaciones
- Sesión 8Documento30 páginasSesión 8Jany Mayta QquerarAún no hay calificaciones
- Mono 1Documento24 páginasMono 1Vamos Tu PuedesAún no hay calificaciones
- Análisis de Regresión Múltiple Con Información CualitativaDocumento26 páginasAnálisis de Regresión Múltiple Con Información CualitativaJaqueline BecharouchAún no hay calificaciones
- Sesión Ecuaciones de Primer GradoDocumento22 páginasSesión Ecuaciones de Primer GradoAlex SánchezAún no hay calificaciones
- Foro 3Documento7 páginasForo 3Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Regresion MultipleDocumento44 páginasRegresion MultipleCindy ScargglioniAún no hay calificaciones
- Foro 3Documento7 páginasForo 3Cesar Alfonso Rosales Amaya0% (1)
- Ensayo Tutoria 3Documento6 páginasEnsayo Tutoria 3BRAYAN STIVEN CARVAJAL MONTOYAAún no hay calificaciones
- Material de ApoyoDocumento63 páginasMaterial de ApoyoFabrizioAún no hay calificaciones
- ESTADISTICA Trabajo Grupal Regresion MultiplefinalDocumento28 páginasESTADISTICA Trabajo Grupal Regresion MultiplefinalDavid SincheAún no hay calificaciones
- Econometrics02 2022Documento80 páginasEconometrics02 2022Juana Montes GaddaAún no hay calificaciones
- 03 Violacion Supuestos MulticolinealidadDocumento28 páginas03 Violacion Supuestos MulticolinealidadJose Luis LabraChAún no hay calificaciones
- EcoI D 2015 I Sesión7 16 Abril 2015Documento40 páginasEcoI D 2015 I Sesión7 16 Abril 2015Kenyi MedinaAún no hay calificaciones
- Unidad 1 - Parte 3Documento19 páginasUnidad 1 - Parte 3Leslie CajanAún no hay calificaciones
- Modelo de regresión lineal en econometríaDocumento21 páginasModelo de regresión lineal en econometríaTania SanchezAún no hay calificaciones
- A Libro Completo Modelos de RegrecionDocumento67 páginasA Libro Completo Modelos de Regrecionjulian roberto bobb eslaitAún no hay calificaciones
- Modelos dependientesDocumento131 páginasModelos dependientesJarinCanazaFernandezAún no hay calificaciones
- CAPITULO 3-Analisis de Regresion Múltiple - EstimaciónDocumento40 páginasCAPITULO 3-Analisis de Regresion Múltiple - EstimaciónARony JoAún no hay calificaciones
- 2014-05-3120141917pauta Ayudantia 11 STA300Documento10 páginas2014-05-3120141917pauta Ayudantia 11 STA300Ignacio RivadeneiraAún no hay calificaciones
- MIC - Unidad 5 - Sesión 10 (Autoguardado)Documento63 páginasMIC - Unidad 5 - Sesión 10 (Autoguardado)AIDITA DAYANA AGUILA ORTEGAAún no hay calificaciones
- Trabajo en Grupo - Alex Haro - David Vega - Probabilidad y Estadistica Basica - gr3Documento12 páginasTrabajo en Grupo - Alex Haro - David Vega - Probabilidad y Estadistica Basica - gr3Alex HaroAún no hay calificaciones
- Regresion Lineal MultipleDocumento20 páginasRegresion Lineal MultipleAshlyana LainezAún no hay calificaciones
- Tema 4 PDFDocumento85 páginasTema 4 PDFSusana González RuizAún no hay calificaciones
- Multicolinealidad (S.8)Documento24 páginasMulticolinealidad (S.8)AnthonyAlonsoCalleVásquezAún no hay calificaciones
- 720 PDFDocumento67 páginas720 PDFPaulaAndreaMorenoAún no hay calificaciones
- Modelo de regresión simple MCODocumento70 páginasModelo de regresión simple MCOteresatsbAún no hay calificaciones
- Clase 15 Variables InstrumentalesDocumento5 páginasClase 15 Variables InstrumentalesCristian Llanos MoscaizaAún no hay calificaciones
- Sesión #06 - Ecuaciones de Primer Grado - 8 SesionesDocumento21 páginasSesión #06 - Ecuaciones de Primer Grado - 8 SesionesAlex SumiAún no hay calificaciones
- Regresión Con Variables CualitativasDocumento99 páginasRegresión Con Variables CualitativasAngela RiveroAún no hay calificaciones
- Guía Práctica-03 - Ecuaciones de Primer GradoDocumento15 páginasGuía Práctica-03 - Ecuaciones de Primer GradoJoseph Diaz QAún no hay calificaciones
- Macroeconometria Manual Sep2006Documento72 páginasMacroeconometria Manual Sep2006Manuel Alejandro Flores CruzAún no hay calificaciones
- Modelos de RegresiónDocumento9 páginasModelos de RegresiónChelsy Puente de la VegaAún no hay calificaciones
- Lectura de Virgilio RoelDocumento25 páginasLectura de Virgilio RoelANAPAULA DIAZ MONTOYAAún no hay calificaciones
- Notas de Clase de Econometría Del Dr. EscuderoDocumento90 páginasNotas de Clase de Econometría Del Dr. EscuderoJosé VélizAún no hay calificaciones
- Sesión #06Documento21 páginasSesión #06MAYCOL OSCAR BARBA SHAPIAMAAún no hay calificaciones
- Variables Binarias y FicticiasDocumento11 páginasVariables Binarias y FicticiasVanessa VallejosAún no hay calificaciones
- Tema2 Regsimple 209391Documento62 páginasTema2 Regsimple 209391Karina ArayaAún no hay calificaciones
- Regresion Lineal MultipleDocumento25 páginasRegresion Lineal MultipleYoselinAún no hay calificaciones
- Clase - 1 - ECONOMETRÍA - INTENSIVODocumento8 páginasClase - 1 - ECONOMETRÍA - INTENSIVOGina RossiAún no hay calificaciones
- Guillermo Paucar CDocumento45 páginasGuillermo Paucar CJOSE AUGUSTO QUISPE MUNARESAún no hay calificaciones
- Ilovepdf - Merged - 2019-05-27T123145.298Documento73 páginasIlovepdf - Merged - 2019-05-27T123145.298César David Aguilera RojasAún no hay calificaciones
- Clase2 1Documento16 páginasClase2 1Nicolas AndreAún no hay calificaciones
- Ayudantía 7 - Econometría IDocumento2 páginasAyudantía 7 - Econometría IJuan FelipeAún no hay calificaciones
- 03 Violacion - Supuestos MulticolinealidadDocumento156 páginas03 Violacion - Supuestos MulticolinealidadjhosepAún no hay calificaciones
- Práctica EconometríaDocumento3 páginasPráctica EconometríaMayerly Fanny Lucana ChuraAún no hay calificaciones
- Regresión MúltipleDocumento10 páginasRegresión MúltipleSheyla GarciaAún no hay calificaciones
- Violación de Los Supuestos Del Modelo ClásicoDocumento10 páginasViolación de Los Supuestos Del Modelo ClásicoDORIS arevaloAún no hay calificaciones
- Taller de Matematicas PDFDocumento6 páginasTaller de Matematicas PDFSantiago David Ortega VelascoAún no hay calificaciones
- Macroeconometria Aplicada Con EviewsDocumento76 páginasMacroeconometria Aplicada Con EviewsMiguel Alarcon100% (1)
- Resumen EconometrïaDocumento204 páginasResumen EconometrïaA Ga PiAún no hay calificaciones
- 439 - Tarea - 2 - Jose Edgar Ospina OrtizDocumento14 páginas439 - Tarea - 2 - Jose Edgar Ospina Ortizjose OspinaAún no hay calificaciones
- MULTICOLINEALIDADDocumento15 páginasMULTICOLINEALIDADPamela L. Condori QuispeAún no hay calificaciones
- Practica2 EconometriaDocumento4 páginasPractica2 EconometriaMartin Yupanqui AndradeAún no hay calificaciones
- Tema 5Documento33 páginasTema 5Susana González RuizAún no hay calificaciones
- Tema 6Documento24 páginasTema 6Susana González RuizAún no hay calificaciones
- Tema 4 PDFDocumento85 páginasTema 4 PDFSusana González RuizAún no hay calificaciones
- Cuaderno Ejercicios Tema 1 y 2Documento16 páginasCuaderno Ejercicios Tema 1 y 2Susana González Ruiz0% (1)
- Resumen Lliço 1Documento1 páginaResumen Lliço 1Susana González RuizAún no hay calificaciones
- Cuadernillo Ejercicios 2015-16Documento16 páginasCuadernillo Ejercicios 2015-16Susana González RuizAún no hay calificaciones
- Tema 3. Análisis Multidimensional Variables DiscretasDocumento33 páginasTema 3. Análisis Multidimensional Variables DiscretasjoelAún no hay calificaciones
- Analisis de Items en SpssDocumento9 páginasAnalisis de Items en SpssThomas BruggerAún no hay calificaciones
- RiosDocumento19 páginasRiosAngela RobinsonAún no hay calificaciones
- Práctica CalificadaDocumento5 páginasPráctica CalificadaCielo BozaAún no hay calificaciones
- Curvas IsotermasDocumento13 páginasCurvas IsotermasMariaM RuizAún no hay calificaciones
- PRACT REGRESION LINEAL E INDICES ESTACIONALES Semana 11Documento16 páginasPRACT REGRESION LINEAL E INDICES ESTACIONALES Semana 11Valeria GoyenagaAún no hay calificaciones
- Planificación de producción de envasesDocumento5 páginasPlanificación de producción de envasesEvelyn Cárdenas LizárragaAún no hay calificaciones
- Examen - (AAB01) Cuestionario 1 - MulticolinealidadDocumento5 páginasExamen - (AAB01) Cuestionario 1 - MulticolinealidadMario ContrerasAún no hay calificaciones
- CURSOEXCELINTERMEDIODocumento1225 páginasCURSOEXCELINTERMEDIODiana HernándezAún no hay calificaciones
- Análisis de gradiente ecológicoDocumento20 páginasAnálisis de gradiente ecológicoBENJAMIN ATEHORTUA TRUJILLOAún no hay calificaciones
- Taller Aanalisis - LinaDocumento7 páginasTaller Aanalisis - LinaLINA MARIU CABEZAAS CLAVIJOAún no hay calificaciones
- ANALISIS DE REGRESION y CORRELACION LINEALDocumento4 páginasANALISIS DE REGRESION y CORRELACION LINEALNúmero De OroAún no hay calificaciones
- Solemne Econometria Rev 1.1Documento5 páginasSolemne Econometria Rev 1.1Marcela VegaAún no hay calificaciones
- Sem15 - Cuadernno de Trabajo - Modelos de Regresion SimpleDocumento18 páginasSem15 - Cuadernno de Trabajo - Modelos de Regresion SimpleANGIE ODALYS VILLAVICENCIO TOBARAún no hay calificaciones
- SPSS - 3 Inferencia EstadisiticaDocumento4 páginasSPSS - 3 Inferencia EstadisiticaErika Andrea P. RodríguezAún no hay calificaciones
- ANCOVADocumento28 páginasANCOVAgustavo angelAún no hay calificaciones
- ML (Pages 1 - 57)Documento57 páginasML (Pages 1 - 57)David CáceresAún no hay calificaciones
- Descubre Cómo Pronosticar La Demanda Con La Regresión LinealDocumento1 páginaDescubre Cómo Pronosticar La Demanda Con La Regresión LinealJORGE MICHAEL MENDEZ FERNANDEZAún no hay calificaciones
- Chart TitleDocumento18 páginasChart TitleVannesa HernadezAún no hay calificaciones
- Sem 02 Tcas de ProyecciónDocumento7 páginasSem 02 Tcas de ProyecciónSaul Leon AlvarezAún no hay calificaciones
- 11.-Regresion y Correlacion Lineal Multiple - 2021Documento5 páginas11.-Regresion y Correlacion Lineal Multiple - 2021Yoel Ronaldo Rosillo MüllerAún no hay calificaciones
- Pruebas de hipótesis y análisis estadísticoDocumento4 páginasPruebas de hipótesis y análisis estadísticoLizeth Nelly Lopez TorrezAún no hay calificaciones
- Ejercicios Semana 12 Sesión 1Documento2 páginasEjercicios Semana 12 Sesión 1FIORELLA LIAún no hay calificaciones
- Taller3 SergioDocumento2 páginasTaller3 SergioCarlos P.Aún no hay calificaciones
- Análisis Residual CasasDocumento2 páginasAnálisis Residual CasasRudyar GarciaAún no hay calificaciones