También podría gustarte
- PresentacionDocumento1 páginaPresentacionRonald De LeonAún no hay calificaciones
- Harold de Leon Civ 419 01 Trabajo 4Documento6 páginasHarold de Leon Civ 419 01 Trabajo 4Ronald De LeonAún no hay calificaciones
- Harold de Leon-Civ-419-01-Trabajo 1Documento16 páginasHarold de Leon-Civ-419-01-Trabajo 1Ronald De LeonAún no hay calificaciones
- Harold de Leon Civ 419 01 Trabajo 3Documento17 páginasHarold de Leon Civ 419 01 Trabajo 3Ronald De LeonAún no hay calificaciones
- Harold de Leon Civ 419 01 Trabajo 4Documento6 páginasHarold de Leon Civ 419 01 Trabajo 4Ronald De LeonAún no hay calificaciones
- Coordenadas de puntos, ecuaciones de rectas y figuras geométricasDocumento2 páginasCoordenadas de puntos, ecuaciones de rectas y figuras geométricasRonald De LeonAún no hay calificaciones
- Harold de Leon Civ 419 01 Trabajo 3Documento17 páginasHarold de Leon Civ 419 01 Trabajo 3Ronald De LeonAún no hay calificaciones
- Harold de Leon Civ 419 01 Trabajo 4Documento6 páginasHarold de Leon Civ 419 01 Trabajo 4Ronald De LeonAún no hay calificaciones
- Harold de Leon-Civ-419-01-Trabajo 2Documento17 páginasHarold de Leon-Civ-419-01-Trabajo 2Ronald De LeonAún no hay calificaciones
- Trabajo 1 NormalizacionDocumento7 páginasTrabajo 1 NormalizacionRonald De LeonAún no hay calificaciones
- Harold de Leon-Civ-419-01-Trabajo 1Documento16 páginasHarold de Leon-Civ-419-01-Trabajo 1Ronald De LeonAún no hay calificaciones
- Prefacio, Indice, Titulo e Introduccion Proyecto Ronald de Leon 100470952Documento5 páginasPrefacio, Indice, Titulo e Introduccion Proyecto Ronald de Leon 100470952Ronald De LeonAún no hay calificaciones
- Formato NormalizacionDocumento1 páginaFormato NormalizacionRonald De LeonAún no hay calificaciones
- Presentar La EmpresaDocumento2 páginasPresentar La EmpresaRonald De LeonAún no hay calificaciones
- Cuestionario Ronald de Leon 100470952Documento4 páginasCuestionario Ronald de Leon 100470952Ronald De LeonAún no hay calificaciones
- Practica 9 Ronald de Leon 100470952 EST-122 SEC.04Documento14 páginasPractica 9 Ronald de Leon 100470952 EST-122 SEC.04Ronald De LeonAún no hay calificaciones
- Freddy 2Documento1 páginaFreddy 2Ronald De LeonAún no hay calificaciones
- Ejercicio ArchivosDocumento1 páginaEjercicio ArchivosRonald De LeonAún no hay calificaciones
- Ejercicio1-Ronald de Leon-Seccion03Documento3 páginasEjercicio1-Ronald de Leon-Seccion03Ronald De LeonAún no hay calificaciones
- Freddy 2Documento1 páginaFreddy 2Ronald De LeonAún no hay calificaciones
- Psicología y Sociologia General. Informe Grupal. 2do Año Sección 13Documento8 páginasPsicología y Sociologia General. Informe Grupal. 2do Año Sección 13Shamdaran JaimesAún no hay calificaciones
- TALLER 10-El-Verbo-para-Segundo-de-PrimariaDocumento4 páginasTALLER 10-El-Verbo-para-Segundo-de-PrimariaAnunciacion Carvajal100% (1)
- Saga de Hervor 1 IntroduccionDocumento12 páginasSaga de Hervor 1 IntroduccionanakotheAún no hay calificaciones
- InfluenzaDocumento25 páginasInfluenzaRomina Chavez100% (1)
- Diagnostico Situacional 4Documento6 páginasDiagnostico Situacional 4Paulina AntilefAún no hay calificaciones
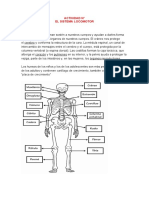
- El Sistema LocomotorDocumento3 páginasEl Sistema LocomotorExtrema RadianteAún no hay calificaciones
- Vientos: dirección, tipos e importanciaDocumento2 páginasVientos: dirección, tipos e importanciaAndres AlarconAún no hay calificaciones
- Diseño de Sistemas OperativosDocumento4 páginasDiseño de Sistemas OperativosCarlos Limachi0% (1)
- Diseño de Rocoto 5.corregidodocDocumento75 páginasDiseño de Rocoto 5.corregidodocMilenita BMAún no hay calificaciones
- Ejerciciosdiminutivo AumentativoDocumento6 páginasEjerciciosdiminutivo AumentativoAngela ChávezAún no hay calificaciones
- La Grandeza de La Sabiduría de DiosDocumento17 páginasLa Grandeza de La Sabiduría de DiosJosé Remberto HenríquezAún no hay calificaciones
- Mi Credo PersonalDocumento4 páginasMi Credo PersonalSagrario Martinez RuizAún no hay calificaciones
- La Auditoria OperacionalDocumento22 páginasLa Auditoria OperacionalLiliana CarreñoAún no hay calificaciones
- Gel Antibacterial PQP PROFESIONALDocumento1 páginaGel Antibacterial PQP PROFESIONALErika Ximena Duarte SilvaAún no hay calificaciones
- La Isla de Las TentacionesDocumento4 páginasLa Isla de Las Tentacionesshakira canteroAún no hay calificaciones
- Concepto ARIEL BELLO FERNANDEZ 12-11-2020Documento1 páginaConcepto ARIEL BELLO FERNANDEZ 12-11-2020Mao EscobarAún no hay calificaciones
- L.P.N. #004-2013-AdP MANTENIMIENTO PERIODICO DE LOS PAVIMENTOS DEL LADO AIRE DEL AEROPUERTO INTERNACIONAL DE PISCODocumento89 páginasL.P.N. #004-2013-AdP MANTENIMIENTO PERIODICO DE LOS PAVIMENTOS DEL LADO AIRE DEL AEROPUERTO INTERNACIONAL DE PISCOVlyn GallardoAún no hay calificaciones
- SEC1 ArtesDocumento5 páginasSEC1 ArtesMaria De Los Angeles VivaldoAún no hay calificaciones
- Sinopsis - Por La Senda de LuciferDocumento1 páginaSinopsis - Por La Senda de Luciferpotopoto100% (1)
- Contaminación a los seres vivos entre 2000-2022Documento3 páginasContaminación a los seres vivos entre 2000-2022The TutosgamesAún no hay calificaciones
- ProtozooDocumento5 páginasProtozooErik Solano HernándezAún no hay calificaciones
- Trigonometria Guia 1Documento24 páginasTrigonometria Guia 1Nayeli GranuelAún no hay calificaciones
- Valéry y la naturaleza técnica de la pintura: claves para un joven artistaDocumento498 páginasValéry y la naturaleza técnica de la pintura: claves para un joven artistaMª Teresa Pérez BáguenaAún no hay calificaciones
- Catequesis Padres 2°Documento150 páginasCatequesis Padres 2°Sandra RiveraAún no hay calificaciones
- Circulo Ganglionar PericervicalDocumento9 páginasCirculo Ganglionar PericervicalAnonymous 3EUrl6100% (2)
- Metodologia Jorge FrascaraDocumento2 páginasMetodologia Jorge FrascarasunshinebysgAún no hay calificaciones
- Sociologia RelacionalDocumento23 páginasSociologia RelacionalJuan felipe Sanabria ardilaAún no hay calificaciones
- Acuaval 2109 Accesorios y Aparatos SanitariosDocumento3 páginasAcuaval 2109 Accesorios y Aparatos SanitariosWalter Ariza SalasAún no hay calificaciones
- Tarea 2 Condiciones Previas de La EntrevistaDocumento7 páginasTarea 2 Condiciones Previas de La Entrevistayisus CisCAAún no hay calificaciones
- Didáctica de la matemática en la escuela primariaDe EverandDidáctica de la matemática en la escuela primariaCalificación: 2.5 de 5 estrellas2.5/5 (3)
- La Teoría de Conjuntos y los Fundamentos de las MatemáticasDe EverandLa Teoría de Conjuntos y los Fundamentos de las MatemáticasCalificación: 5 de 5 estrellas5/5 (1)
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)
- La Biblia de las Matemáticas RápidasDe EverandLa Biblia de las Matemáticas RápidasCalificación: 4.5 de 5 estrellas4.5/5 (19)
- Problemas de física general en un año olímpicoDe EverandProblemas de física general en un año olímpicoCalificación: 5 de 5 estrellas5/5 (1)
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- Enseñar Matemática hoy: Miradas, sentidos y desafíosDe EverandEnseñar Matemática hoy: Miradas, sentidos y desafíosCalificación: 5 de 5 estrellas5/5 (1)
- El Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalDe EverandEl Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalCalificación: 5 de 5 estrellas5/5 (3)
- Física cuántica para principiantes: Descubra los fundamentos de la mecánica cuántica y cómo afecta al mundo en que vivimos a través de todas sus teorías más famosasDe EverandFísica cuántica para principiantes: Descubra los fundamentos de la mecánica cuántica y cómo afecta al mundo en que vivimos a través de todas sus teorías más famosasCalificación: 5 de 5 estrellas5/5 (4)
- Proyectos de instalaciones eléctrica de baja tensiónDe EverandProyectos de instalaciones eléctrica de baja tensiónCalificación: 5 de 5 estrellas5/5 (1)
- El método de los elementos finitos: Un enfoque teórico prácticoDe EverandEl método de los elementos finitos: Un enfoque teórico prácticoCalificación: 3 de 5 estrellas3/5 (4)
- Física paso a paso: Más de 100 problemas resueltosDe EverandFísica paso a paso: Más de 100 problemas resueltosCalificación: 4 de 5 estrellas4/5 (12)
- NIKOLA TESLA: Mis Inventos - AutobiografiaDe EverandNIKOLA TESLA: Mis Inventos - AutobiografiaCalificación: 4.5 de 5 estrellas4.5/5 (2)
- Visualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónDe EverandVisualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónCalificación: 5 de 5 estrellas5/5 (18)
- Mecánica cuántica para principiantesDe EverandMecánica cuántica para principiantesCalificación: 3.5 de 5 estrellas3.5/5 (5)
- Convertidores conmutados de potencia: Test de autoevaluaciónDe EverandConvertidores conmutados de potencia: Test de autoevaluaciónCalificación: 5 de 5 estrellas5/5 (1)
- Control de calidad. Un enfoque integral y estadísticoDe EverandControl de calidad. Un enfoque integral y estadísticoCalificación: 5 de 5 estrellas5/5 (8)
- Matemáticas financierasDe EverandMatemáticas financierasCalificación: 4 de 5 estrellas4/5 (7)
- Guía práctica para la refracción ocularDe EverandGuía práctica para la refracción ocularCalificación: 5 de 5 estrellas5/5 (2)