También podría gustarte
- Ciencia de datos: La serie de conocimientos esenciales de MIT PressDe EverandCiencia de datos: La serie de conocimientos esenciales de MIT PressCalificación: 5 de 5 estrellas5/5 (1)
- Minería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásDe EverandMinería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásCalificación: 4.5 de 5 estrellas4.5/5 (4)
- UF2213 - Modelos de datos y visión conceptual de una base de datosDe EverandUF2213 - Modelos de datos y visión conceptual de una base de datosAún no hay calificaciones
- Introducción A La Prehistoria. La Evolución de La Cultura HumanaDocumento217 páginasIntroducción A La Prehistoria. La Evolución de La Cultura HumanaMili87% (15)
- 10 Preguntas Data Mining Unidad 1Documento4 páginas10 Preguntas Data Mining Unidad 1Anita TicanteAún no hay calificaciones
- ForoDocumento4 páginasForoDiego LópezAún no hay calificaciones
- Tendencias en Minerias de DatosDocumento9 páginasTendencias en Minerias de DatosJonaiker PérezAún no hay calificaciones
- Aplicacion Mineria de DatosDocumento4 páginasAplicacion Mineria de DatosAngelRapperittoZavalettaAún no hay calificaciones
- Minería de DatosDocumento5 páginasMinería de DatosCarlos Alberto Yarlequé YarlequéAún no hay calificaciones
- Mineria de DatosDocumento13 páginasMineria de DatosNancy PatiñoAún no hay calificaciones
- Capítulo 2 Business Problems and Data Science SolutionsDocumento12 páginasCapítulo 2 Business Problems and Data Science SolutionserikaAún no hay calificaciones
- Modelos de Data MiningDocumento6 páginasModelos de Data MiningOmar Jhonatan Huamanchumo OrtizAún no hay calificaciones
- Consulta P1 - Tareas en Minería de DatosDocumento13 páginasConsulta P1 - Tareas en Minería de DatosJANARA ASLEHY GARCIA FUENTESAún no hay calificaciones
- Minería de Datos Versus KDDDocumento7 páginasMinería de Datos Versus KDDCristhian Jose Mamani MamaniAún no hay calificaciones
- CV03 Analítica y Minería de DatosDocumento23 páginasCV03 Analítica y Minería de DatosViridiana ChagoyaAún no hay calificaciones
- Minería de Datos y Otras Disciplinas AnálogasDocumento4 páginasMinería de Datos y Otras Disciplinas AnálogasDiego CruzAún no hay calificaciones
- CONCEPTOS 2.4. DataMining o Mineria de DatosDocumento6 páginasCONCEPTOS 2.4. DataMining o Mineria de DatosFedrftg PedrftgyAún no hay calificaciones
- Rodríguez Hernán AnalizandoDocumento6 páginasRodríguez Hernán Analizandodavidrodriguez1188Aún no hay calificaciones
- Minería de DatosDocumento19 páginasMinería de DatosRolando_alone666Aún no hay calificaciones
- Investigacion Metodos y Tecnicas de Mineria de Datos 2021Documento12 páginasInvestigacion Metodos y Tecnicas de Mineria de Datos 2021Christian MontoyaAún no hay calificaciones
- Minería de DatosDocumento6 páginasMinería de DatosPamela Melgarejo GomezAún no hay calificaciones
- Mineria de Datos O.Documento5 páginasMineria de Datos O.Rafael Eduardo Velasquez VargasAún no hay calificaciones
- Mcom2 U1 A1Documento7 páginasMcom2 U1 A1Adrian ToledanoAún no hay calificaciones
- Minería de DatosDocumento4 páginasMinería de DatosGm MinatoAún no hay calificaciones
- Definicion de Data MiningDocumento7 páginasDefinicion de Data MiningStar CruzadSparzaAún no hay calificaciones
- Minería de DatosDocumento9 páginasMinería de Datoscybor2000Aún no hay calificaciones
- Mineria de Datos FinalDocumento75 páginasMineria de Datos FinalMax FuentesAún no hay calificaciones
- Qué Es La Minería de DatosDocumento4 páginasQué Es La Minería de DatosAdan RiveraAún no hay calificaciones
- Mineria de DatosDocumento16 páginasMineria de DatosLosPerrosDEMITierraCajicaAún no hay calificaciones
- Minería de DatosDocumento6 páginasMinería de DatosDeyvid LugoAún no hay calificaciones
- Ciclo de Data MiningDocumento117 páginasCiclo de Data MiningConchi MarcosAún no hay calificaciones
- Clase Semana 6Documento30 páginasClase Semana 6JULIO ARMANDO LANDAZURI CASTROAún no hay calificaciones
- Mineria de DatosDocumento56 páginasMineria de DatosZerginho MuñozAún no hay calificaciones
- Tarea 1 (Ensayo Ciencia de Datos)Documento9 páginasTarea 1 (Ensayo Ciencia de Datos)Kevin Joel Zambrano LucasAún no hay calificaciones
- Mcomii U1 A1 DishDocumento4 páginasMcomii U1 A1 DishDiana Angelica SandovalAún no hay calificaciones
- Tarea JhonatanParedesDocumento3 páginasTarea JhonatanParedesDe Todo Un Poco Tutoriales OficialAún no hay calificaciones
- Qué Es Una BDMDocumento12 páginasQué Es Una BDMJovany ChavezAún no hay calificaciones
- Minería de DatosDocumento30 páginasMinería de DatosMontero Montero AriasAún no hay calificaciones
- Minería de DatosDocumento16 páginasMinería de DatosYerson Leoncio Cristobal VicenteAún no hay calificaciones
- Tratamiento de Datos KDDDocumento5 páginasTratamiento de Datos KDDYIVERAún no hay calificaciones
- Unidad 4 Ingenieria Del Conocimiento - Adquisicion Del ConocimientoDocumento16 páginasUnidad 4 Ingenieria Del Conocimiento - Adquisicion Del ConocimientoSteve D SousaAún no hay calificaciones
- Fases de Un Proyecto de Mineria de DatosDocumento10 páginasFases de Un Proyecto de Mineria de DatosrickidarkAún no hay calificaciones
- Uwe LaboDocumento4 páginasUwe LaboJean SincheAún no hay calificaciones
- Análisis de La Información: Guía de Estudio Bloque IIIDocumento16 páginasAnálisis de La Información: Guía de Estudio Bloque IIIAdrian RojasAún no hay calificaciones
- ¿Qué Es El Data Mining La Definición de La Minería de DatosDocumento2 páginas¿Qué Es El Data Mining La Definición de La Minería de DatosMelanieAún no hay calificaciones
- Ciencia de Datos Breve Tesis Instituto Jean JairoDocumento2 páginasCiencia de Datos Breve Tesis Instituto Jean JairoJairofranco25Aún no hay calificaciones
- Expo - Mineria de DatosDocumento9 páginasExpo - Mineria de Datoskevin manuel ortiz galeanoAún no hay calificaciones
- Data MiningDocumento4 páginasData MiningKrisley LagosAún no hay calificaciones
- Ensayo Mineria de DatosDocumento5 páginasEnsayo Mineria de DatosLizeth Arely Garcia100% (1)
- Análisis de DecisionesDocumento7 páginasAnálisis de DecisionesManuel MurielAún no hay calificaciones
- Actividad de Aprendizaje 1Documento5 páginasActividad de Aprendizaje 1Jhair YepesAún no hay calificaciones
- Tecnicas PredictivasDocumento11 páginasTecnicas Predictivasmccm77Aún no hay calificaciones
- Algoritmo de SegmentaciónDocumento7 páginasAlgoritmo de SegmentaciónBethAún no hay calificaciones
- KKDDocumento8 páginasKKDAdrian SantanaAún no hay calificaciones
- Introduccion A La MineriaDocumento8 páginasIntroduccion A La MineriaINDIGO TORREALBAAún no hay calificaciones
- Mineria de Datos - Base de DatosDocumento4 páginasMineria de Datos - Base de DatosVianney PichonAún no hay calificaciones
- Apuntes Big DataDocumento22 páginasApuntes Big DataJose Manuel Araujo OrregoAún no hay calificaciones
- Artículo 12.mineria de Datos.Documento8 páginasArtículo 12.mineria de Datos.Irene ValenciaAún no hay calificaciones
- Mineria de Datos - InformeDocumento16 páginasMineria de Datos - InformePaulTinocoAún no hay calificaciones
- Mineria de Datos Informe PDFDocumento16 páginasMineria de Datos Informe PDFJunior NeryraAún no hay calificaciones
- NotasDocumento7 páginasNotasGregorio Palma SarmientoAún no hay calificaciones
- Trabajo de Investigación - Fondos MutuosDocumento14 páginasTrabajo de Investigación - Fondos MutuosJuany Galindo MAún no hay calificaciones
- DaliDocumento28 páginasDaliJuany Galindo MAún no hay calificaciones
- Durante Esta Semana Deberán Elaborar Un Cuadro Resumen Con Las Principales Funciones de Los Distintos ProfesionalesDocumento2 páginasDurante Esta Semana Deberán Elaborar Un Cuadro Resumen Con Las Principales Funciones de Los Distintos ProfesionalesJuany Galindo MAún no hay calificaciones
- Determine 3 Causas de La Alta Rotación Del Personal JovenDocumento1 páginaDetermine 3 Causas de La Alta Rotación Del Personal JovenJuany Galindo MAún no hay calificaciones
- Preguntas Materia PrimaDocumento7 páginasPreguntas Materia PrimaJuany Galindo M0% (1)
- Ficha Observación Sesion Tutoria DITOEDocumento4 páginasFicha Observación Sesion Tutoria DITOEJesús HuapayaAún no hay calificaciones
- La Inteligencia y El ConocimientoDocumento5 páginasLa Inteligencia y El ConocimientokarlycarrascoAún no hay calificaciones
- 4 Concurso de Murales AniversarioDocumento3 páginas4 Concurso de Murales AniversarioPEREZ CORREA JOSUE ANTONIOAún no hay calificaciones
- ProgramaDocumento2 páginasProgramadarioAún no hay calificaciones
- Ivanova. Fundamentos Neurocognitivos Del Procesam. Linguistico PDFDocumento28 páginasIvanova. Fundamentos Neurocognitivos Del Procesam. Linguistico PDFJuli BailoneAún no hay calificaciones
- Lerner Construir El Objeto de EnseñanzaDocumento4 páginasLerner Construir El Objeto de EnseñanzaFlorencia BelvedereAún no hay calificaciones
- Tesis FernandoRiofrio PDFDocumento664 páginasTesis FernandoRiofrio PDFluliexperimentAún no hay calificaciones
- Verdades IneludiblesDocumento4 páginasVerdades Ineludiblescristianj777Aún no hay calificaciones
- MallaDocumento4 páginasMallaAlfonsoAún no hay calificaciones
- Carta A La EclesiasticaDocumento11 páginasCarta A La EclesiasticaOliver MunAún no hay calificaciones
- In House PDFDocumento1 páginaIn House PDFAlexis Asencio LuisAún no hay calificaciones
- Intro Ducci OnDocumento4 páginasIntro Ducci OnLisandra Castillo GonzálezAún no hay calificaciones
- Comprecion y Redaccion de Texto Semana 2Documento2 páginasComprecion y Redaccion de Texto Semana 2Dallhebert DallhebertAún no hay calificaciones
- La Vida Etica y El Desarrollo de La Persona en GuardiniDocumento13 páginasLa Vida Etica y El Desarrollo de La Persona en GuardiniJuan David QuicenoAún no hay calificaciones
- Evidencia Ficha AntropotricaDocumento2 páginasEvidencia Ficha AntropotricaLeonardo Cienfuegos100% (1)
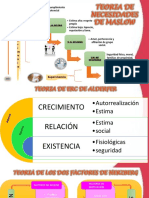
- Teoria ErcDocumento9 páginasTeoria ErcCARLOS MIÑANO SANCHEZAún no hay calificaciones
- Constancias Artemio y JosiaDocumento5 páginasConstancias Artemio y Josiajorge riosAún no hay calificaciones
- Resumen Psicologia CognitivaDocumento13 páginasResumen Psicologia CognitivaLauraAún no hay calificaciones
- FE - Evaluación Final U2v Final 2Documento7 páginasFE - Evaluación Final U2v Final 2Javiera Tobar BórquezAún no hay calificaciones
- Ficha Tecnica Wppsi Iii.Documento1 páginaFicha Tecnica Wppsi Iii.Ramon MirelesAún no hay calificaciones
- Feldman - Matematica IDocumento11 páginasFeldman - Matematica IMarcela KiernanAún no hay calificaciones
- Analisis de Los Elementos Del Conflicto WordDocumento4 páginasAnalisis de Los Elementos Del Conflicto WordJulia Ruiz HumpiriAún no hay calificaciones
- Dosificación de ContenidosDocumento5 páginasDosificación de ContenidosCynthia FloresAún no hay calificaciones
- LAS CLAVES DEL ÉXITO en FinlandiaDocumento6 páginasLAS CLAVES DEL ÉXITO en FinlandiaMaria NavarroAún no hay calificaciones
- Formato Control EscolarDocumento2 páginasFormato Control EscolarDocumentacion TeacapánAún no hay calificaciones
- Triptico de ComuDocumento2 páginasTriptico de ComuTynna Silva BendezúAún no hay calificaciones
- Contrato de Trabajo de Profesores PrivadosDocumento7 páginasContrato de Trabajo de Profesores PrivadosMaria Alejandra Charris HerreraAún no hay calificaciones
- Informe de Tesis de Maestría-Rodríguez Rocha (Zoopoética)Documento4 páginasInforme de Tesis de Maestría-Rodríguez Rocha (Zoopoética)Lisandro GómezAún no hay calificaciones
- Formato Plan de Area 2023Documento2 páginasFormato Plan de Area 2023Yolmar PintoAún no hay calificaciones