También podría gustarte
- Análisis estadístico de datos multivariadosDe EverandAnálisis estadístico de datos multivariadosCalificación: 5 de 5 estrellas5/5 (1)
- Pasos para Elaborar Un Proyecto de InvestigaciónDocumento39 páginasPasos para Elaborar Un Proyecto de Investigaciónjuan100% (1)
- Actividad 2 Introduccion Al Conocimiento Cientifico-2Documento3 páginasActividad 2 Introduccion Al Conocimiento Cientifico-2Ehukaris VegaAún no hay calificaciones
- Módulo 4 - Análisis, Rediseño y Mejoramiento de ProcesosDocumento114 páginasMódulo 4 - Análisis, Rediseño y Mejoramiento de ProcesosAngie VargasAún no hay calificaciones
- Teoria de Errores e Instrumentos de Precision de LongitudesDocumento5 páginasTeoria de Errores e Instrumentos de Precision de LongitudesOrianaAún no hay calificaciones
- VG CruzadoDocumento10 páginasVG CruzadoRichard Peña AlccaAún no hay calificaciones
- Módulo 3Documento32 páginasMódulo 3AnabelAún no hay calificaciones
- Preinforme Tratamiento Estadistico de DatosDocumento10 páginasPreinforme Tratamiento Estadistico de DatosFerney ForeroAún no hay calificaciones
- Tema 3. Estimación Por Intervalo - Parte 2Documento15 páginasTema 3. Estimación Por Intervalo - Parte 2lysiaAún no hay calificaciones
- Cartas de Control de Medias y RangoDocumento5 páginasCartas de Control de Medias y RangoLucyReyesAún no hay calificaciones
- Distribucion de ProbabilidadesDocumento36 páginasDistribucion de ProbabilidadesdeyviAún no hay calificaciones
- Análisis de Datos y VariografíaDocumento94 páginasAnálisis de Datos y VariografíaDaniel Mantilla MurgaAún no hay calificaciones
- S5 EstadisticaDocumento17 páginasS5 EstadisticaLuis VasquezAún no hay calificaciones
- Parte 1 2 3 4 HechasDocumento33 páginasParte 1 2 3 4 HechasFreddy DurandAún no hay calificaciones
- Alumnos Univariante (2) Calibracion 20-21 PDFDocumento12 páginasAlumnos Univariante (2) Calibracion 20-21 PDFAna Rodriguez PedrouzoAún no hay calificaciones
- COMPENDIO Unidad3Documento15 páginasCOMPENDIO Unidad3Thalia Guadalupe Olaya PispiraAún no hay calificaciones
- 3 Bis Estadística (Varianza y Desv STD)Documento4 páginas3 Bis Estadística (Varianza y Desv STD)ycyhrjsjnhAún no hay calificaciones
- Inferencia Estadística en El Modelo de Dos VariablesDocumento21 páginasInferencia Estadística en El Modelo de Dos VariablesKevo Pérez GarcíaAún no hay calificaciones
- NTC 107 Método para Determinar La Expansión en Autoclave Del Cemento Pórtland PDFDocumento10 páginasNTC 107 Método para Determinar La Expansión en Autoclave Del Cemento Pórtland PDFbiblia24Aún no hay calificaciones
- COMPENDIO Unidad3Documento15 páginasCOMPENDIO Unidad3Julissa Michell Domo VelezAún no hay calificaciones
- Desviación TípicaDocumento3 páginasDesviación TípicaEdgard Laura ChayñaAún no hay calificaciones
- Módulo EstadisticaDocumento19 páginasMódulo EstadisticaFrancis Lisbeth Rosero CuasmayánAún no hay calificaciones
- Análisis de Valor Extremo Utilizando GEVDocumento26 páginasAnálisis de Valor Extremo Utilizando GEVbetogs4Aún no hay calificaciones
- 3.7 Distribucion de Probabilidad NormalDocumento8 páginas3.7 Distribucion de Probabilidad NormalLuis CastilloAún no hay calificaciones
- Medidas de DispersiónDocumento3 páginasMedidas de DispersiónAna ValenciaAún no hay calificaciones
- Física I LboratorioDocumento25 páginasFísica I LboratorioElvis Ivan Silva IparraguirreAún no hay calificaciones
- 01 - Ajuste de Observaciones - ERRORES - René Zepeda - 2023 - 1Documento13 páginas01 - Ajuste de Observaciones - ERRORES - René Zepeda - 2023 - 1JonathanAún no hay calificaciones
- Tema 3 PsicometríaDocumento3 páginasTema 3 PsicometríaIvan MalangoAún no hay calificaciones
- ch4 Medidas Dispersion PDFDocumento21 páginasch4 Medidas Dispersion PDFMAIMAN PARKER WILSONAún no hay calificaciones
- Medidas de Tendencia Central y de Posicion 2018Documento39 páginasMedidas de Tendencia Central y de Posicion 2018Oscar RizzoAún no hay calificaciones
- RPubs - Modelización de La Volatilidad y Valor en Riesgo (VaR) Del BitcoinDocumento22 páginasRPubs - Modelización de La Volatilidad y Valor en Riesgo (VaR) Del BitcoinalvarortunsAún no hay calificaciones
- Compendio Unidad 3. EstadisticaDocumento15 páginasCompendio Unidad 3. EstadisticaJordan DelgadoAún no hay calificaciones
- UNIDAD #6 (ING. CIVIL) (1) Probabilidad y EstadísticaDocumento6 páginasUNIDAD #6 (ING. CIVIL) (1) Probabilidad y Estadísticaronaldo velasquezAún no hay calificaciones
- Tarea #2 Distribucion Estandar y Normal PDFDocumento13 páginasTarea #2 Distribucion Estandar y Normal PDFQuinio Bruno Espiritu EugenioAún no hay calificaciones
- Medidas de Variabilidad de Datos Simple y AgrupadosDocumento8 páginasMedidas de Variabilidad de Datos Simple y AgrupadosMaricel Anahi Carbajal Santacruz100% (1)
- S07.s2 - Distribución NormalDocumento31 páginasS07.s2 - Distribución Normalnathaly nicol ramirez garciaAún no hay calificaciones
- P Sem13 Distribución+normalDocumento23 páginasP Sem13 Distribución+normalJorge Luis Soria100% (1)
- Teoría - Tamaño de Corridas e Intervalos de Confianza MSP Ciclo 2020 2Documento12 páginasTeoría - Tamaño de Corridas e Intervalos de Confianza MSP Ciclo 2020 2Alvaro VargasAún no hay calificaciones
- P - Sem13 - Distribución Normal-1 PDFDocumento23 páginasP - Sem13 - Distribución Normal-1 PDFKtha RodríguezAún no hay calificaciones
- Desviación TípicaDocumento3 páginasDesviación TípicaDavid SSMAún no hay calificaciones
- Distribución NormalDocumento30 páginasDistribución NormalTatiana DíazAún no hay calificaciones
- 2.1 Introduction To Matlab 2021-2Documento35 páginas2.1 Introduction To Matlab 2021-2brayan virguezAún no hay calificaciones
- Estadística de La Medición Unt 2022Documento14 páginasEstadística de La Medición Unt 2022Richard GalvesAún no hay calificaciones
- Sesión 4 Medidas de DispersionDocumento20 páginasSesión 4 Medidas de DispersionLeandro Alva CastilloAún no hay calificaciones
- Estudio Exploratorio de Datos (O EDA en Inglés) : MIN 235 - Geoestadística y Análisis Espacial Rodrigo Estay HuidobroDocumento21 páginasEstudio Exploratorio de Datos (O EDA en Inglés) : MIN 235 - Geoestadística y Análisis Espacial Rodrigo Estay HuidobroCristopher HernándezAún no hay calificaciones
- 2020 tp4b Distribuciones Muestrales Intervalos de Confianza PDFDocumento8 páginas2020 tp4b Distribuciones Muestrales Intervalos de Confianza PDFDrift KingAún no hay calificaciones
- 2020 tp4b Distribuciones Muestrales Intervalos de Confianza PDFDocumento8 páginas2020 tp4b Distribuciones Muestrales Intervalos de Confianza PDFDrift KingAún no hay calificaciones
- Lab 1 Péndulo-Error Cuadrático-VirtualDocumento6 páginasLab 1 Péndulo-Error Cuadrático-VirtualMateo GerenaAún no hay calificaciones
- Trabajo Distribuciones de ProbabilidadDocumento22 páginasTrabajo Distribuciones de ProbabilidadAndrés ArizaAún no hay calificaciones
- Log Normal 2 ParametrosDocumento30 páginasLog Normal 2 ParametrosWilmerCamposBarbozaAún no hay calificaciones
- Distribuciones MuestralesDocumento10 páginasDistribuciones MuestralesJaime FloresAún no hay calificaciones
- Csic 21 BDocumento203 páginasCsic 21 BJuan ChapiAún no hay calificaciones
- Tema 8-Dsitribuciones VAC 2012Documento13 páginasTema 8-Dsitribuciones VAC 2012Ignacio RinaldiAún no hay calificaciones
- Laboratorio #8Documento5 páginasLaboratorio #8angel nuñezAún no hay calificaciones
- Medición y Cálculo de La IncertidumbreDocumento23 páginasMedición y Cálculo de La IncertidumbreRosa ElenaAún no hay calificaciones
- UNIDAD II - Probabilidades y Distribuciones - IC2021 - 5ta ParteDocumento19 páginasUNIDAD II - Probabilidades y Distribuciones - IC2021 - 5ta PartemasmianAún no hay calificaciones
- 1 Informe de Laboratorio de Fisica1Documento33 páginas1 Informe de Laboratorio de Fisica1Cesar Jibaja Ceron100% (1)
- Calderón, Arturo (2015) Apuntes de Estadística Cap 3Documento32 páginasCalderón, Arturo (2015) Apuntes de Estadística Cap 3Daniel MoyaAún no hay calificaciones
- Medidas de DispersionDocumento12 páginasMedidas de DispersiondouglasAún no hay calificaciones
- Leccion 6Documento4 páginasLeccion 6Amanda MonterrosoAún no hay calificaciones
- Geometric modeling in computer: Aided geometric designDe EverandGeometric modeling in computer: Aided geometric designAún no hay calificaciones
- T2-Reacciones Pericíclicas PDFDocumento63 páginasT2-Reacciones Pericíclicas PDFAna Rodriguez PedrouzoAún no hay calificaciones
- Alumnos Univariante (2) Calibracion 20-21 PDFDocumento12 páginasAlumnos Univariante (2) Calibracion 20-21 PDFAna Rodriguez PedrouzoAún no hay calificaciones
- Tema8 (A)Documento17 páginasTema8 (A)Ana Rodriguez PedrouzoAún no hay calificaciones
- Tema6 (A)Documento16 páginasTema6 (A)Ana Rodriguez PedrouzoAún no hay calificaciones
- T3. Reacciones Radicalarias PDFDocumento35 páginasT3. Reacciones Radicalarias PDFAna Rodriguez PedrouzoAún no hay calificaciones
- Tema 2. - TEV-TCC (Moodle)Documento30 páginasTema 2. - TEV-TCC (Moodle)Ana Rodriguez PedrouzoAún no hay calificaciones
- Plantilla de Evaluación (Prácticas de Laboratorio)Documento1 páginaPlantilla de Evaluación (Prácticas de Laboratorio)Ana Rodriguez PedrouzoAún no hay calificaciones
- T01. Derivados de Ácidos CarboxílicosDocumento29 páginasT01. Derivados de Ácidos CarboxílicosAna Rodriguez PedrouzoAún no hay calificaciones
- TABLAS IntegralesDocumento2 páginasTABLAS IntegralesAna Rodriguez PedrouzoAún no hay calificaciones
- TABLAS Integrales PDFDocumento16 páginasTABLAS Integrales PDFAna Rodriguez PedrouzoAún no hay calificaciones
- Practica Benzoico (2016)Documento3 páginasPractica Benzoico (2016)Ana Rodriguez PedrouzoAún no hay calificaciones
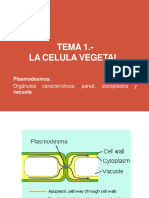
- Tema 2. - La Celula VegetalDocumento41 páginasTema 2. - La Celula VegetalAna Rodriguez PedrouzoAún no hay calificaciones
- 1ºej EnzimologíaDocumento2 páginas1ºej EnzimologíaAna Rodriguez PedrouzoAún no hay calificaciones
- 2015 BQ2 T11 Metabolismo Carbohidratos VegetalDocumento15 páginas2015 BQ2 T11 Metabolismo Carbohidratos VegetalAna Rodriguez PedrouzoAún no hay calificaciones
- C.ecuaciones Diferenciales m1Documento1 páginaC.ecuaciones Diferenciales m1Ana Rodriguez PedrouzoAún no hay calificaciones
- Tema 08-10 LípidosDocumento86 páginasTema 08-10 LípidosAna Rodriguez PedrouzoAún no hay calificaciones
- Soluciones BoletínÁcido BaseDocumento1 páginaSoluciones BoletínÁcido BaseAna Rodriguez PedrouzoAún no hay calificaciones
- Tema13 TejidoConectivoDocumento16 páginasTema13 TejidoConectivoAna Rodriguez PedrouzoAún no hay calificaciones
- Cuestionariogeneral BCDocumento18 páginasCuestionariogeneral BCAna Rodriguez PedrouzoAún no hay calificaciones
- Boletín #6 T910Documento1 páginaBoletín #6 T910Ana Rodriguez PedrouzoAún no hay calificaciones
- Dominios CelularesDocumento7 páginasDominios CelularesAna Rodriguez PedrouzoAún no hay calificaciones
- Cuestionariogeneral BCDocumento18 páginasCuestionariogeneral BCAna Rodriguez PedrouzoAún no hay calificaciones
- Guia Practica N°4 PDFDocumento23 páginasGuia Practica N°4 PDFguillermo garciaAún no hay calificaciones
- Fuentes Primarias y SecundariasDocumento3 páginasFuentes Primarias y SecundariasMiguelAún no hay calificaciones
- La Ciencia Que No Se Aprende en La Red. Modelos Didácticos para Motivar El Estudio de Las Ciencias A Través de La Arqueología (GRAO - CASTELLANO) (Spanish Edition) by Laia Coma Quintana Nayra LlonchDocumento128 páginasLa Ciencia Que No Se Aprende en La Red. Modelos Didácticos para Motivar El Estudio de Las Ciencias A Través de La Arqueología (GRAO - CASTELLANO) (Spanish Edition) by Laia Coma Quintana Nayra LlonchAgustinAún no hay calificaciones
- Guía #12 - Estadística SéptimoDocumento2 páginasGuía #12 - Estadística SéptimoMelanin Castro MontezumaAún no hay calificaciones
- Ejercicios de AdicionDocumento13 páginasEjercicios de AdicionJhuliño Ushpa UshpaAún no hay calificaciones
- Ejercicios Propuestos - Sesion 04Documento4 páginasEjercicios Propuestos - Sesion 04Albert Ccapxha50% (2)
- PARDO, R. Verdad e Historicidad El Conocimiento Cientifico y Sus FracturasDocumento14 páginasPARDO, R. Verdad e Historicidad El Conocimiento Cientifico y Sus FracturasWlos MiriAún no hay calificaciones
- Unidad 4 - Mapa ConceptualDocumento2 páginasUnidad 4 - Mapa ConceptualFede DerimaisAún no hay calificaciones
- Taller de InvestigacionDocumento2 páginasTaller de Investigaciongilgalflo galeraAún no hay calificaciones
- 2021 22 Enero21Documento4 páginas2021 22 Enero21marina hernandezAún no hay calificaciones
- Mapa Conceptual, Investigación FormativaDocumento2 páginasMapa Conceptual, Investigación FormativaDANIEL CHAVEZ MICHAAún no hay calificaciones
- Procesos Operativo Del MetodoDocumento4 páginasProcesos Operativo Del Metodonboj50% (2)
- Taller Diagramas de Venn ValenDocumento7 páginasTaller Diagramas de Venn ValenValentina LeónAún no hay calificaciones
- Diseño FactorialDocumento2 páginasDiseño FactorialBrandon Arenas HuambachanoAún no hay calificaciones
- Materialización de La Experiencia en FotografíaDocumento25 páginasMaterialización de La Experiencia en Fotografíaabelcortez77Aún no hay calificaciones
- Epistemología de Las Ciencias SocialesDocumento12 páginasEpistemología de Las Ciencias SocialesLarry J KingAún no hay calificaciones
- Ensayo Argumentativo - ParadigmaDocumento10 páginasEnsayo Argumentativo - ParadigmaConchita VazquezAún no hay calificaciones
- Orientacion EducativaDocumento362 páginasOrientacion EducativaDaniela Gutierrez100% (2)
- Estadistica Destriptiva PDFDocumento130 páginasEstadistica Destriptiva PDFNando JuniorAún no hay calificaciones
- Programa Resuelto LógicaDocumento33 páginasPrograma Resuelto LógicaEze GarcíaAún no hay calificaciones
- Robertazzi - Presentacion de Paradigmas Clasicos en Psicologia Social PDFDocumento9 páginasRobertazzi - Presentacion de Paradigmas Clasicos en Psicologia Social PDFAnonymous ehXgyygAún no hay calificaciones
- MÓDULO V TareaDocumento4 páginasMÓDULO V TareaKarina G Jimenez GomezAún no hay calificaciones
- Intrducción A La SimulaciónDocumento16 páginasIntrducción A La SimulaciónFiorela AlcarazAún no hay calificaciones
- Metodos PsicologiaDocumento14 páginasMetodos PsicologiaKevin C. Maldonado MirandaAún no hay calificaciones
- Calidad de Las MedicionesDocumento24 páginasCalidad de Las MedicionespedroantonionavaAún no hay calificaciones
- Evaluacion 1 Fundamentos de InvestigacionDocumento6 páginasEvaluacion 1 Fundamentos de InvestigacionGuataAún no hay calificaciones
- Guia DanzaDocumento22 páginasGuia DanzaFernando Perigüeza50% (2)
- Qué Se Entiende Por InvestigaciónDocumento31 páginasQué Se Entiende Por InvestigaciónHilda CerveraAún no hay calificaciones