También podría gustarte
- Cap03 - Sistemas OperativosDocumento7 páginasCap03 - Sistemas OperativosGattesAún no hay calificaciones
- Gestión Del Sistema de Entrada y Salida de Los Sistemas Operativos.Documento5 páginasGestión Del Sistema de Entrada y Salida de Los Sistemas Operativos.wtnAún no hay calificaciones
- Las Técnicas de Entrada y SalidadDocumento5 páginasLas Técnicas de Entrada y SalidadRodrigo HernandezAún no hay calificaciones
- Entrada / Salida Programada, Entrada / Salida Mediante InterrupcionesDocumento8 páginasEntrada / Salida Programada, Entrada / Salida Mediante InterrupcionesErikc MenesesAún no hay calificaciones
- Organizacion de Entrada y SalidaDocumento19 páginasOrganizacion de Entrada y SalidaJose CnchicaAún no hay calificaciones
- Gestion Entrada SalidaDocumento11 páginasGestion Entrada SalidaAmparo OrtizAún no hay calificaciones
- 05 Entrada SalidaDocumento4 páginas05 Entrada SalidaValenchu XDAún no hay calificaciones
- Organización E-SDocumento10 páginasOrganización E-SManuel MonteroAún no hay calificaciones
- Interconexion Entre Procesador y PerifericosDocumento23 páginasInterconexion Entre Procesador y PerifericosKaren HernandezAún no hay calificaciones
- Administracion de PerifericosDocumento29 páginasAdministracion de Perifericosp0chaca100% (2)
- Gestión de Entrada y SalidaDocumento10 páginasGestión de Entrada y Salidambezares1Aún no hay calificaciones
- Unidad de E-SDocumento7 páginasUnidad de E-Salma.quinterosquirogaAún no hay calificaciones
- Entrada y SalidaDocumento11 páginasEntrada y SalidaKelmer Ashley Comas CardonaAún no hay calificaciones
- Tarea - T3.0Documento7 páginasTarea - T3.0Imer RGAún no hay calificaciones
- Equipo Nâº3Documento30 páginasEquipo Nâº3RachelithOo ADangelAún no hay calificaciones
- Mickeal Raad - Archivos Entrada y SalidaDocumento14 páginasMickeal Raad - Archivos Entrada y SalidaMaikel RaadAún no hay calificaciones
- Modulo E-SDocumento4 páginasModulo E-SNovedades MLAún no hay calificaciones
- Conectividad Entre Procesadores, Memoria y Dispositivos de ESDocumento15 páginasConectividad Entre Procesadores, Memoria y Dispositivos de ESWendyAún no hay calificaciones
- Tema 18 - Sistemas Operativos: Gestión de Entradas/salidas: ÍndiceDocumento24 páginasTema 18 - Sistemas Operativos: Gestión de Entradas/salidas: Índiceelio ramirezAún no hay calificaciones
- E/S Mapeada en Memoria E/S AisladaDocumento35 páginasE/S Mapeada en Memoria E/S AisladaHanna C Wolf MoonAún no hay calificaciones
- Técnicas para La Administración y Asignación de PeriféricosDocumento4 páginasTécnicas para La Administración y Asignación de PeriféricosFrancisco Javier Haro EscobarAún no hay calificaciones
- Por Qué DMADocumento6 páginasPor Qué DMAAl-chan GomezAún no hay calificaciones
- Resumen Unidad6Documento18 páginasResumen Unidad6Daniel scanioAún no hay calificaciones
- 4.4operaciones de Entrada y SalidaDocumento8 páginas4.4operaciones de Entrada y SalidaMarco Antonio Ramirez EstradaAún no hay calificaciones
- Unidad 3Documento11 páginasUnidad 3Juan05Aún no hay calificaciones
- Sistemas OperativosDocumento10 páginasSistemas OperativosRoberto Carlos Terrazas GuerreroAún no hay calificaciones
- Sistemas Operativos I - Tema 6Documento15 páginasSistemas Operativos I - Tema 6itisistemasunedAún no hay calificaciones
- Jhon Arista Alarcon - Trabajo SO Semana 1Documento3 páginasJhon Arista Alarcon - Trabajo SO Semana 1Jhon Arista AlarconAún no hay calificaciones
- So DispositivosDocumento10 páginasSo DispositivosbyronAún no hay calificaciones
- Entrada Vs Salida Programada y Por InterrupcionesDocumento7 páginasEntrada Vs Salida Programada y Por InterrupcionesGovanna LunaAún no hay calificaciones
- 2do CuatrimestreDocumento14 páginas2do CuatrimestreJuan Pablo MAXWELLAún no hay calificaciones
- 2do CuatrimestreDocumento14 páginas2do CuatrimestreJuan Pablo MAXWELLAún no hay calificaciones
- Entrada y Salida de Datos PDFDocumento25 páginasEntrada y Salida de Datos PDFJhonatan HernandezAún no hay calificaciones
- Cap. IV. - Entrada-Salida PDFDocumento36 páginasCap. IV. - Entrada-Salida PDFgustavo.d dddamadorAún no hay calificaciones
- Explique en Que Consisten Los Cuatro Estados BásicosDocumento30 páginasExplique en Que Consisten Los Cuatro Estados BásicosMARIA NANCYAún no hay calificaciones
- Sistemas OperativosDocumento12 páginasSistemas OperativosCristian PachecoAún no hay calificaciones
- 6 - 6.7 ArqDocumento22 páginas6 - 6.7 Arqbyron guerreroAún no hay calificaciones
- Organización de Entrada y SalidaDocumento23 páginasOrganización de Entrada y SalidaEduardo TovarAún no hay calificaciones
- Tema 6Documento44 páginasTema 6David SuruguayAún no hay calificaciones
- 4.4 Operaciones de Entrada y SalidaDocumento2 páginas4.4 Operaciones de Entrada y SalidaHilario Pimienta100% (1)
- Problemas Mas Comunes y Estrateguias de Manejo de Los Dispositivos de E-SDocumento11 páginasProblemas Mas Comunes y Estrateguias de Manejo de Los Dispositivos de E-SJulio c Resendiz75% (8)
- Monografia - Entrada y Salida FinalDocumento12 páginasMonografia - Entrada y Salida FinalMatias LupaAún no hay calificaciones
- Objetivos Del Software de Entrada y SalidaDocumento13 páginasObjetivos Del Software de Entrada y SalidaLuz Stefany Verano AlzateAún no hay calificaciones
- Unidad 5 - Sistema de Entrada - SalidaDocumento48 páginasUnidad 5 - Sistema de Entrada - SalidaDarío Fernando Huilcapi SubíaAún no hay calificaciones
- Guia Taller Capitulo IIIDocumento11 páginasGuia Taller Capitulo IIIFrancini BecerraAún no hay calificaciones
- Diana Peña CAP1 SO1Documento7 páginasDiana Peña CAP1 SO1heydiAún no hay calificaciones
- Unidad de ControlDocumento10 páginasUnidad de ControlPatriciaAún no hay calificaciones
- Guia de Administración de Sistemas Operativos IDocumento7 páginasGuia de Administración de Sistemas Operativos IDavid Alexander Monroy MirandaAún no hay calificaciones
- Dispositivos de Entradas y Salidas de Una PCDocumento40 páginasDispositivos de Entradas y Salidas de Una PCGerman ChoqueAún no hay calificaciones
- Gestión de Múltiples DispositivosDocumento8 páginasGestión de Múltiples DispositivosAlvaro Mamani ChoqueAún no hay calificaciones
- Gestion de Dispositivos de EntradaDocumento8 páginasGestion de Dispositivos de EntradaAlejandra RochaAún no hay calificaciones
- Sistemas Operativos - Introduccion A Los ComputadoresDocumento9 páginasSistemas Operativos - Introduccion A Los ComputadoresJuan Segundo ArgayoAún no hay calificaciones
- Actividad 2 de Unidad 3Documento7 páginasActividad 2 de Unidad 32330105Aún no hay calificaciones
- 6.faltantes de Resumen Proceso-Archivos (Autoguardado)Documento7 páginas6.faltantes de Resumen Proceso-Archivos (Autoguardado)Sharon Brenes CascanteAún no hay calificaciones
- Entra Da Salida SoDocumento36 páginasEntra Da Salida SoChan SeleneAún no hay calificaciones
- Entrada y Salida y Algoritmos de DiscoDocumento8 páginasEntrada y Salida y Algoritmos de DiscoMarvin David De Paz JuárezAún no hay calificaciones
- Guia Taller Capitulo IIIDocumento10 páginasGuia Taller Capitulo IIIFrancini BecerraAún no hay calificaciones
- CuestionarioDocumento4 páginasCuestionarioMajo KareninaAún no hay calificaciones
- Manejo de DispositivosDocumento8 páginasManejo de DispositivosEmmanuel Jimenez PerezAún no hay calificaciones
- UF0852 - Instalación y actualización de sistemas operativosDe EverandUF0852 - Instalación y actualización de sistemas operativosCalificación: 5 de 5 estrellas5/5 (1)
- El DIF MunicipalDocumento12 páginasEl DIF Municipalcamily_30Aún no hay calificaciones
- Introducción A La MateriaDocumento3 páginasIntroducción A La MateriaprofemontiAún no hay calificaciones
- 1 - Proceso de Encendido Del ComputadorDocumento4 páginas1 - Proceso de Encendido Del ComputadorAndrés VelázquezAún no hay calificaciones
- Clase 1 Sistemas OperativosDocumento22 páginasClase 1 Sistemas OperativosYeyner LopezAún no hay calificaciones
- Gestion de FlotasDocumento40 páginasGestion de FlotasGodolfredo Beellido Turpo100% (1)
- La Musica y El Ritmo de CambioDocumento3 páginasLa Musica y El Ritmo de Cambioclara.rujinsky100% (1)
- TD 210 2 Esp2Documento60 páginasTD 210 2 Esp2Ing. Kevin D Pérez Eguis.Aún no hay calificaciones
- Entregable 1 TecnologiaDocumento6 páginasEntregable 1 TecnologiaAlvaro Jesus Moreno IbarraAún no hay calificaciones
- Unidad I El ComputadorDocumento4 páginasUnidad I El ComputadorAngel VelizAún no hay calificaciones
- Guía Del Usuario de Rimage Catalyst 6000 y 6000NDocumento15 páginasGuía Del Usuario de Rimage Catalyst 6000 y 6000NBiomédica Hospital San JoséAún no hay calificaciones
- Análisis Comparativo de Los Pros y Contras de Las TICs en El AprendizajeDocumento19 páginasAnálisis Comparativo de Los Pros y Contras de Las TICs en El AprendizajeIván LoredoAún no hay calificaciones
- Microcontroladores. El 8051 de IntelDocumento524 páginasMicrocontroladores. El 8051 de Inteldennyjoel100% (1)
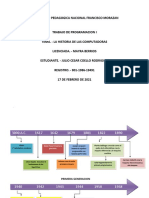
- Linea de Tiempo de La Historia de Las ComputadorasDocumento4 páginasLinea de Tiempo de La Historia de Las ComputadorasJulio CoelloAún no hay calificaciones
- Modelación y Simulación Con SIMIODocumento22 páginasModelación y Simulación Con SIMIOeraffolecca50% (2)
- En Una Empresa Al Realizar Auditoría A Un Sistema de InformaciónDocumento4 páginasEn Una Empresa Al Realizar Auditoría A Un Sistema de InformaciónVictoria FlorezAún no hay calificaciones
- Revisión Del Programador PIPO2Documento3 páginasRevisión Del Programador PIPO2Justino Bruno BaigorriaAún no hay calificaciones
- Introducción A Las Placas MadreDocumento6 páginasIntroducción A Las Placas MadreJoseph Sermeño PalaciosAún no hay calificaciones
- Conclusion Analisis de Sistema...Documento4 páginasConclusion Analisis de Sistema...bolivar20080% (1)
- Semana 11Documento41 páginasSemana 11valeria arce navarreteAún no hay calificaciones
- Breve Tutorial Sobre Manejo de MapsourceDocumento7 páginasBreve Tutorial Sobre Manejo de MapsourceCarlos ChiluisaAún no hay calificaciones
- Redes de ComunicacionDocumento7 páginasRedes de ComunicacionErick Alfredo RosasAún no hay calificaciones
- Fase 1 PresaberesDocumento12 páginasFase 1 PresaberesCésar Armando Cruz CruzAún no hay calificaciones
- Guia Programacion IDocumento43 páginasGuia Programacion ILeonardo ParraAún no hay calificaciones
- Katherine Arias Varela - Actividad 2Documento17 páginasKatherine Arias Varela - Actividad 2katherin arias varelaAún no hay calificaciones
- Final Introduccion A La Ingenieria de Manufactura y Maquinas CNCDocumento51 páginasFinal Introduccion A La Ingenieria de Manufactura y Maquinas CNCmoises3194Aún no hay calificaciones
- Algoritmos y Estructuras de Datos 2015-1Documento52 páginasAlgoritmos y Estructuras de Datos 2015-1Jordi LópezAún no hay calificaciones
- Manejo de Estación TotalDocumento15 páginasManejo de Estación TotalGuillermo ChuquilinAún no hay calificaciones
- Sistema de Conteo de Acceso.Documento33 páginasSistema de Conteo de Acceso.lizbeth de dios mendezAún no hay calificaciones
- Prueba de AdmisionDocumento8 páginasPrueba de AdmisionYeimy Rojas ArayaAún no hay calificaciones
- Manual XvisionDocumento40 páginasManual XvisionOsca Yañez SotoAún no hay calificaciones