También podría gustarte
- Sesion 07 - Correlacion y Regresion - 10.08Documento57 páginasSesion 07 - Correlacion y Regresion - 10.08ronald SOTO DIAZ100% (2)
- A0168399 - Efts10Documento5 páginasA0168399 - Efts10Bryam CárdenasAún no hay calificaciones
- Ecuaciones Algebraicas de Grado - A. G. KuroschDocumento44 páginasEcuaciones Algebraicas de Grado - A. G. KuroschLucius Thales da Silva100% (1)
- Rectas y Curvas PDFDocumento202 páginasRectas y Curvas PDFhans131Aún no hay calificaciones
- Test de Aptitud Visual-Psicotecnico-Ejercicios ResueltosDocumento2 páginasTest de Aptitud Visual-Psicotecnico-Ejercicios ResueltosFelicidad Alguacil del HierroAún no hay calificaciones
- Cálculo y diseño de estructuras de materiales compuestos de fibra de vidrioDe EverandCálculo y diseño de estructuras de materiales compuestos de fibra de vidrioAún no hay calificaciones
- Regresion Lineal Simple Estadistica Inferencial Ii PDFDocumento10 páginasRegresion Lineal Simple Estadistica Inferencial Ii PDFAivle MSczAún no hay calificaciones
- Acerca de La Demostración en Geometría - A. I. Fetísov - MIRDocumento68 páginasAcerca de La Demostración en Geometría - A. I. Fetísov - MIRasdfg100% (1)
- Correlacion y RegresionDocumento53 páginasCorrelacion y RegresionLuis Eduardo TorresAún no hay calificaciones
- Anat de GrayDocumento880 páginasAnat de GrayMario T. Veliz AvilaAún no hay calificaciones
- 08.regresión y Correlación SimpleDocumento77 páginas08.regresión y Correlación SimpleGary Monge SorianoAún no hay calificaciones
- Correlacion y RegresionDocumento91 páginasCorrelacion y RegresionJOSE AAún no hay calificaciones
- Sesión 7Documento58 páginasSesión 7BRENDA LIZBETH REYES CORDOVAAún no hay calificaciones
- Regresion Lineal y Correlación PDFDocumento47 páginasRegresion Lineal y Correlación PDFTeresa UrciaAún no hay calificaciones
- TRABAJO 1 - Correlación - 2018Documento8 páginasTRABAJO 1 - Correlación - 2018Marshella Velasquez FernandezAún no hay calificaciones
- Regresión Lineal y CorrelacionesDocumento53 páginasRegresión Lineal y CorrelacionesCristian Gutierrez UlloaAún no hay calificaciones
- 1regres - Simple Ei 2020Documento24 páginas1regres - Simple Ei 2020Andres TorresAún no hay calificaciones
- Clase Personal Semana 7Documento57 páginasClase Personal Semana 7Rosario Del Carmen Licona IAún no hay calificaciones
- Sesión 8. Regresión Lineal y CorrelacionesDocumento54 páginasSesión 8. Regresión Lineal y CorrelacionesGladys Zeta LopezAún no hay calificaciones
- Sesión 8. Regresión Lineal y CorrelacionesDocumento54 páginasSesión 8. Regresión Lineal y CorrelacionesJhon Josue C SevillanoAún no hay calificaciones
- Analisis de Regresion y Correlacion Lineal PDFDocumento54 páginasAnalisis de Regresion y Correlacion Lineal PDFMelissa Farfan VargasAún no hay calificaciones
- Sem9 Regresión Correlación-EGDocumento33 páginasSem9 Regresión Correlación-EGCesar pariAún no hay calificaciones
- Sesión 8 Interpretación de Los Parámteros y Variable FicticiaDocumento35 páginasSesión 8 Interpretación de Los Parámteros y Variable FicticiaGOrtizAAún no hay calificaciones
- Estadística Aplicada para La Toma de Decisiones Semana 13 ConferenciaDocumento35 páginasEstadística Aplicada para La Toma de Decisiones Semana 13 ConferenciaPedro JesúsAún no hay calificaciones
- Ecuaciones EmpiricasDocumento21 páginasEcuaciones EmpiricasGustavo GallardoAún no hay calificaciones
- Seis Sigma BB AnalisisDocumento688 páginasSeis Sigma BB AnalisisVania Lizeth Ponce LopezAún no hay calificaciones
- 1.regresión y Correlación SimpleDocumento91 páginas1.regresión y Correlación SimpleNicole R. GloriaAún no hay calificaciones
- Tema 4 PDFDocumento8 páginasTema 4 PDFjaime1180Aún no hay calificaciones
- Ecuaciones EmpiricasDocumento80 páginasEcuaciones EmpiricasFabricioAún no hay calificaciones
- Sesion 07 - Correlacion y Regresion - 10.08Documento56 páginasSesion 07 - Correlacion y Regresion - 10.08Richard Kenny Bernales78% (9)
- 1984, Kostovski EscaneadoDocumento41 páginas1984, Kostovski EscaneadoRaúl Enrique Dutari DutariAún no hay calificaciones
- Geometria 4toDocumento5 páginasGeometria 4toMarcelino FreyreAún no hay calificaciones
- Manual de Análisis Estadístico de DatosDocumento46 páginasManual de Análisis Estadístico de DatosSneyder Rojas DíazAún no hay calificaciones
- Medidas de Correlacion CovarDocumento15 páginasMedidas de Correlacion CovarFigueroa CristianAún no hay calificaciones
- 0.3. Triángulo de Pascal (V. A. Uspenski - (MIR) ) 1978Documento45 páginas0.3. Triángulo de Pascal (V. A. Uspenski - (MIR) ) 1978darlan.molina1976Aún no hay calificaciones
- Diferencia de AsociacionesDocumento4 páginasDiferencia de Asociacionesjeferson vasquezAún no hay calificaciones
- Pienso Juego y Escribo 1-10Documento6 páginasPienso Juego y Escribo 1-10Alberto FAún no hay calificaciones
- AbacoDocumento14 páginasAbacoJose Avellaneda NavarreteAún no hay calificaciones
- Lynn B. Jorde - Genética Médica-ProbDocumento2 páginasLynn B. Jorde - Genética Médica-ProbRolleros unidosAún no hay calificaciones
- Hoja - de - Registro - WISC - IV 2 PaginasDocumento2 páginasHoja - de - Registro - WISC - IV 2 PaginasCande CamposAún no hay calificaciones
- RegresionDocumento25 páginasRegresionKarol RamirezAún no hay calificaciones
- Fichero 1° MatemáticasDocumento76 páginasFichero 1° MatemáticasKaty RoblesAún no hay calificaciones
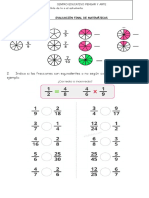
- Evaluación Final de MatesDocumento2 páginasEvaluación Final de MatesValeria FrancoAún no hay calificaciones
- Clasifica de Acuerdo Con Las CaracteristicasDocumento5 páginasClasifica de Acuerdo Con Las Caracteristicasd40532657uAún no hay calificaciones
- RM Santillana - 1° PDocumento81 páginasRM Santillana - 1° PLucio Bellido DiazAún no hay calificaciones
- PPT Unidad 01 Tema 01 2020 02 Fund Visuales I (2318)Documento66 páginasPPT Unidad 01 Tema 01 2020 02 Fund Visuales I (2318)vangheluxAún no hay calificaciones
- Apuntes Estadistica Bidimensional 2021Documento13 páginasApuntes Estadistica Bidimensional 2021Andrea Mamani GaileAún no hay calificaciones
- Tipos de Planos2Documento76 páginasTipos de Planos2leonardo corderoAún no hay calificaciones
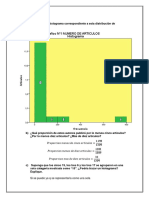
- UNIEST8Documento7 páginasUNIEST8aljo92Aún no hay calificaciones
- Tema2 BidimensionalDocumento11 páginasTema2 BidimensionalMarco MarAún no hay calificaciones
- Fichas para Trabajar La MemoriaDocumento22 páginasFichas para Trabajar La MemoriaANGELICA ROMEROAún no hay calificaciones
- Recta de RegresiónDocumento4 páginasRecta de RegresiónDennis Escudero FloresAún no hay calificaciones
- solExamenAbril B 2016Documento3 páginassolExamenAbril B 2016Juan Pena OrtizAún no hay calificaciones
- PDF Taller Evaluado Estadisticas 2 CompressDocumento2 páginasPDF Taller Evaluado Estadisticas 2 CompressMariana Moreno SantoyoAún no hay calificaciones
- Medidas para Redes y Combinación de Colores - Madero MediaDocumento12 páginasMedidas para Redes y Combinación de Colores - Madero MediaTomás CataríAún no hay calificaciones
- CIBA1937-9-La Medicina de Los AztecasDocumento36 páginasCIBA1937-9-La Medicina de Los Aztecasriss100% (1)
- Lista EjerciciosDocumento9 páginasLista EjerciciosnelsonAún no hay calificaciones
- Cuaderno de Bienvenida Mates +1.Documento16 páginasCuaderno de Bienvenida Mates +1.Raquel Benítez RodríguezAún no hay calificaciones
- Analisis de Regresion I (Analisis)Documento42 páginasAnalisis de Regresion I (Analisis)Nahuel SayagoAún no hay calificaciones
- Ajedrez en El Aula 1-81Documento1 páginaAjedrez en El Aula 1-81Carlos David ApolonioAún no hay calificaciones
- Yfa 2Documento7 páginasYfa 2isabel mancillaAún no hay calificaciones
- Practica N 2: Materia: Docente: Ing. Aleida García Alcocer Auxiliar: Fecha de EntregaDocumento3 páginasPractica N 2: Materia: Docente: Ing. Aleida García Alcocer Auxiliar: Fecha de Entregaisabel mancillaAún no hay calificaciones
- Ejercicio SimplexDocumento6 páginasEjercicio Simplexisabel mancillaAún no hay calificaciones
- Practica1 Ii 2012 PDFDocumento3 páginasPractica1 Ii 2012 PDFisabel mancillaAún no hay calificaciones
- MultidecisionDocumento127 páginasMultidecisionisabel mancillaAún no hay calificaciones
- ProblemasDocumento2 páginasProblemasisabel mancillaAún no hay calificaciones
- Unidad 4 - EsDocumento96 páginasUnidad 4 - EsVilma Duchi FárezAún no hay calificaciones
- Ejercicios de Estimación e Intervalos de ConfianzaDocumento20 páginasEjercicios de Estimación e Intervalos de ConfianzabrendaAún no hay calificaciones
- Ejercicios EstadísticaDocumento3 páginasEjercicios EstadísticaLAún no hay calificaciones
- Cuarta Clase Unac 2021Documento28 páginasCuarta Clase Unac 2021LeonelHerediaAltamirano0% (1)
- ACTIVIDAD 4 Medidas de PosicionDocumento8 páginasACTIVIDAD 4 Medidas de PosicionDavid OrtegonAún no hay calificaciones
- Tema 6. Análisis de Datos Cuantitativos II. InferencialDocumento22 páginasTema 6. Análisis de Datos Cuantitativos II. InferencialEduardoAún no hay calificaciones
- Tarea 12 Ecuacion de RegresionDocumento15 páginasTarea 12 Ecuacion de RegresionNaly RoseroAún no hay calificaciones
- Material Didáctico (Unidad 1) SPDocumento24 páginasMaterial Didáctico (Unidad 1) SPjats_zAún no hay calificaciones
- Pronostico de Ventas - Tarea 4 - Douglas Valladares - 61851145Documento5 páginasPronostico de Ventas - Tarea 4 - Douglas Valladares - 61851145Douglas ValladaresAún no hay calificaciones
- Teoria de La Estimacion y Prueba de HipotesisDocumento19 páginasTeoria de La Estimacion y Prueba de HipotesisBetsa DelgaAún no hay calificaciones
- Formato de Silabo Econometria II FinalDocumento5 páginasFormato de Silabo Econometria II FinalLIZETH MAGALY POMARI AQUISEAún no hay calificaciones
- HeterocedasticidadDocumento8 páginasHeterocedasticidadFANNY VANESSA GODOYAún no hay calificaciones
- Ejercicios de EstadísticaDocumento49 páginasEjercicios de EstadísticaMaría Jimena Quiñones Vilchez100% (1)
- Delgado Isacc AA1 2Documento9 páginasDelgado Isacc AA1 2Isacc Delgado CanteroAún no hay calificaciones
- Tema N 2 Análisis de Correlación Lineal Simple Sem 2-2021Documento10 páginasTema N 2 Análisis de Correlación Lineal Simple Sem 2-2021Mariel Aylin AdrianAún no hay calificaciones
- Esta Di SticaDocumento8 páginasEsta Di SticaOliver ZambranoAún no hay calificaciones
- Silabos Econometría II-072C-2023-I JCVDocumento8 páginasSilabos Econometría II-072C-2023-I JCVjrvv2013gmailAún no hay calificaciones
- Regresión LinealDocumento7 páginasRegresión LinealJuanita RiañoAún no hay calificaciones
- Productividad y Eficiencia 2013Documento38 páginasProductividad y Eficiencia 2013Willian Leon tafurAún no hay calificaciones
- EjercicioDocumento10 páginasEjercicioVanesa Lavilla AlvarezAún no hay calificaciones
- Inferencia Relativa MediasDocumento34 páginasInferencia Relativa MediasMauricio StanleyAún no hay calificaciones
- Estadistica 1Documento7 páginasEstadistica 1EdsonOrellanaAún no hay calificaciones
- Estadistica Aplicada Al Analisis QuimicoDocumento129 páginasEstadistica Aplicada Al Analisis QuimicoCarlos Arturo CarmonaAún no hay calificaciones
- Matematica Todos Los TpsDocumento7 páginasMatematica Todos Los TpsJordi El PoliciaAún no hay calificaciones
- Parcial RegresionDocumento7 páginasParcial RegresionTheSlothfulAún no hay calificaciones
- Ingeniera de Trabajo - Muestreo - CarinaDocumento10 páginasIngeniera de Trabajo - Muestreo - CarinaDanielLunaAún no hay calificaciones
- Problema 1 y 7Documento2 páginasProblema 1 y 7jonathanAún no hay calificaciones
- Inferencia - Dos Medias PoblacionalesDocumento19 páginasInferencia - Dos Medias PoblacionalesJulio BurgosAún no hay calificaciones
- Trabajo Final MinesightDocumento85 páginasTrabajo Final MinesightCesar Eduardo Mego SaucedoAún no hay calificaciones