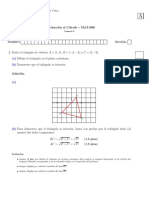
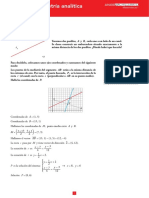
También podría gustarte
- Introducción A La Inferencia BayesianaDocumento31 páginasIntroducción A La Inferencia BayesianasaraAún no hay calificaciones
- Inferencia BayesianaDocumento31 páginasInferencia BayesianaMaria Grediaga LozanoAún no hay calificaciones
- Conjugación de Funciones de Distribución.Documento25 páginasConjugación de Funciones de Distribución.caferrobAún no hay calificaciones
- Informe DinámicaDocumento10 páginasInforme DinámicaJorge Iván RamirezAún no hay calificaciones
- PD1 RespuestasDocumento5 páginasPD1 Respuestasjosephdeabreu11Aún no hay calificaciones
- Ayudantia 1 Fis109a SolucionDocumento13 páginasAyudantia 1 Fis109a SolucionKarol Con KaAún no hay calificaciones
- SEMANA 2 Números RealesDocumento20 páginasSEMANA 2 Números RealesJeshua MacedoAún no hay calificaciones
- CALCULODocumento100 páginasCALCULOAR SkamathAún no hay calificaciones
- Reforzamiento de Matematica de 4to (Pae) PDFDocumento8 páginasReforzamiento de Matematica de 4to (Pae) PDFJorge Alexander Amaya MedinaAún no hay calificaciones
- 2009 - 12 - Letra - Examen PDFDocumento4 páginas2009 - 12 - Letra - Examen PDF7it62019 electrotecniaAún no hay calificaciones
- Reales 27 48Documento22 páginasReales 27 48Ãňthøny Făbřiciø PâchăcämåAún no hay calificaciones
- Modelos Básicos de Estadística BayesianaDocumento38 páginasModelos Básicos de Estadística BayesianaPatricia RodriguezAún no hay calificaciones
- ALGEBRA Clase 2 - 3ERO - Elementos de La GeometriaDocumento2 páginasALGEBRA Clase 2 - 3ERO - Elementos de La GeometriaIbeth keyko Jara campos de brenisAún no hay calificaciones
- Teoria RectasDocumento4 páginasTeoria RectasIsmael RuizAún no hay calificaciones
- Clase de 15 de Abril Del 2021 - 5°S - C3 - IB - 2021Documento6 páginasClase de 15 de Abril Del 2021 - 5°S - C3 - IB - 2021JOHANAún no hay calificaciones
- 2s-EXAMEN MENSUAL-ÁLGEBRA-Jose CaceresDocumento2 páginas2s-EXAMEN MENSUAL-ÁLGEBRA-Jose CaceresJose Miguel Caceres PaivaAún no hay calificaciones
- Resuelto Tema - 3Documento5 páginasResuelto Tema - 3Orochi SuarezAún no hay calificaciones
- 6 Rectas y PlanosDocumento10 páginas6 Rectas y PlanosAyrton GarciaAún no hay calificaciones
- Trabajo EconometríaDocumento3 páginasTrabajo EconometríaSergio TrigoAún no hay calificaciones
- E 5S LimaDocumento4 páginasE 5S LimaElmer SotoAún no hay calificaciones
- TP4 2006 PDFDocumento8 páginasTP4 2006 PDFhejuradoAún no hay calificaciones
- Binomial NormalDocumento24 páginasBinomial NormalIvan GarciaAún no hay calificaciones
- ConjugateDocumento25 páginasConjugatereginaxyAún no hay calificaciones
- PyE - 2020-03-09 - SoluciónDocumento6 páginasPyE - 2020-03-09 - SolucióndadasdsaAún no hay calificaciones
- 19-3-20071239guia01 Eb Sta200Documento11 páginas19-3-20071239guia01 Eb Sta200Laura Francisca Carril CancinoAún no hay calificaciones
- 1-Numeros RealesDocumento22 páginas1-Numeros Realesgaston.piresAún no hay calificaciones
- Control 2 V3Documento8 páginasControl 2 V3MrockeraAún no hay calificaciones
- Chi CuadradaDocumento16 páginasChi CuadradaGustavo TellezAún no hay calificaciones
- U5 - Clase 24 - S7Documento15 páginasU5 - Clase 24 - S7Ivis VegaAún no hay calificaciones
- Tarea Lógica y ConjuntosDocumento2 páginasTarea Lógica y ConjuntosTa CabrónAún no hay calificaciones
- Amga PD3Documento5 páginasAmga PD3Dainer Rojas MendozaAún no hay calificaciones
- Tarea 2 de EstadisticaDocumento12 páginasTarea 2 de Estadisticafabricio :vAún no hay calificaciones
- Clase 17 - Mapeo Del AmbienteDocumento22 páginasClase 17 - Mapeo Del AmbienteL.RobledoAún no hay calificaciones
- Tercera Lista 17octubre 2022Documento2 páginasTercera Lista 17octubre 2022LUIS ABIGAIL LLANES LEYVAAún no hay calificaciones
- Tema 2-3 Distribuciones Especiales DiscretasDocumento25 páginasTema 2-3 Distribuciones Especiales DiscretasManuelAún no hay calificaciones
- Tarea 5 - EstadisticaDocumento3 páginasTarea 5 - EstadisticaAntony Huanca zevallosAún no hay calificaciones
- Campos Electromagnéticos Taller 1Documento18 páginasCampos Electromagnéticos Taller 1Rangazel 7u7Aún no hay calificaciones
- Evaluaciones 2020 2Documento44 páginasEvaluaciones 2020 2ronaldAún no hay calificaciones
- Guia 7 - Funciones PolinomicasDocumento14 páginasGuia 7 - Funciones Polinomicasderly delgadoAún no hay calificaciones
- Inecuaciones de 1er GradoDocumento8 páginasInecuaciones de 1er GradoInés Sandra Huarcusi RamosAún no hay calificaciones
- La Recta RealDocumento5 páginasLa Recta RealFabián Colombo MoraesAún no hay calificaciones
- Compendio 2020 IDocumento17 páginasCompendio 2020 ImariamercedesmontesmunaycoAún no hay calificaciones
- Vectores - Geometría Analítica 1 Bachillerato Todas Las Soluciones PDFDocumento73 páginasVectores - Geometría Analítica 1 Bachillerato Todas Las Soluciones PDFnereaAún no hay calificaciones
- PC1 SoluciónDocumento5 páginasPC1 Soluciónsidartaa197Aún no hay calificaciones
- Tarea 4 3Documento4 páginasTarea 4 32019 Act CONTRERAS SALCEDO VIVIAN ABIGAILAún no hay calificaciones
- Sol PEC 2 2024Documento3 páginasSol PEC 2 2024OroroAún no hay calificaciones
- Complemento Ep3Documento5 páginasComplemento Ep3Leonel Mendoza TerrazasAún no hay calificaciones
- 2s-EXAMEN MENSUAL-SOLUCIONARIO-ÁLGEBRA-Jose CaceresDocumento2 páginas2s-EXAMEN MENSUAL-SOLUCIONARIO-ÁLGEBRA-Jose CaceresJose Miguel Caceres PaivaAún no hay calificaciones
- Estadistica BayesianaDocumento42 páginasEstadistica Bayesianapaomar27Aún no hay calificaciones
- Clase 2 Numeros N y ZDocumento3 páginasClase 2 Numeros N y ZDeivy AgraceAún no hay calificaciones
- Basico Sem5Documento37 páginasBasico Sem5PabloAún no hay calificaciones
- Teórica 2 EC LimitesDocumento9 páginasTeórica 2 EC LimitesjosemarazAún no hay calificaciones
- 3ra ParteDocumento1 página3ra ParteRega JuliusAún no hay calificaciones
- Und. 01 - Introducción A La Geometría - Geometría Nivel Pre PDFDocumento16 páginasUnd. 01 - Introducción A La Geometría - Geometría Nivel Pre PDFCarlitos Barreda CabreraAún no hay calificaciones
- Taller 1Documento5 páginasTaller 1SantiagoRivas100% (1)
- 14 B Algebra Divisibilidad Cocientes Notables Factorización M.C.D y M.C.MDocumento37 páginas14 B Algebra Divisibilidad Cocientes Notables Factorización M.C.D y M.C.MholaAún no hay calificaciones
- Actividad N5 SolucionDocumento6 páginasActividad N5 SolucionPablo OteroAún no hay calificaciones
- Variables Estadisticas, Distribuciones Conjuntas, Marginales y CondicionalesDocumento31 páginasVariables Estadisticas, Distribuciones Conjuntas, Marginales y CondicionalesMaria Grediaga LozanoAún no hay calificaciones
- Inferencia Clasica o FrecuentistaDocumento29 páginasInferencia Clasica o FrecuentistaMaria Grediaga LozanoAún no hay calificaciones
- Repaso Resultados ProbabilidadDocumento18 páginasRepaso Resultados ProbabilidadMaria Grediaga LozanoAún no hay calificaciones
- Tema 1Documento6 páginasTema 1Maria Grediaga LozanoAún no hay calificaciones
- EpjajaDocumento19 páginasEpjajaRubén LázaroAún no hay calificaciones
- A. Lijphart - La Política Comparada y El Método Comparativo PDFDocumento9 páginasA. Lijphart - La Política Comparada y El Método Comparativo PDFAle Viteritti0% (1)
- 2019 - Metodologia de La Investigacion - ObstetriciaDocumento207 páginas2019 - Metodologia de La Investigacion - ObstetriciaMartha Milagos Calderon TintayaAún no hay calificaciones
- Resumen de Textos en MetodologiaDocumento51 páginasResumen de Textos en MetodologiaRobertoVacaAún no hay calificaciones
- Descubrimiento de La Caja NegraDocumento3 páginasDescubrimiento de La Caja NegraAndrea Yuliana BonillaAún no hay calificaciones
- MA-DP-062 Determinación de Contenido e Impurezas de Pigmentos Por HPLCDocumento20 páginasMA-DP-062 Determinación de Contenido e Impurezas de Pigmentos Por HPLCEdisson Abdiel Rodriguez TorresAún no hay calificaciones
- Dictamen en BalísticaDocumento13 páginasDictamen en BalísticaSergio MontesAún no hay calificaciones
- 3.3 Mètodos de JuiciosDocumento7 páginas3.3 Mètodos de JuiciosAmaya Rangel67% (3)
- Guia No 1 Repaso de MatematicasDocumento3 páginasGuia No 1 Repaso de MatematicasalsaapaAún no hay calificaciones
- Lazarsfeld Paul de Los Conceptos A Los Índices Empíricos PDFDocumento6 páginasLazarsfeld Paul de Los Conceptos A Los Índices Empíricos PDFJESSICA DOMINGUEZAún no hay calificaciones
- Bueno El Tío Petros y La Conjetura de Gold Bach Resumen BDocumento9 páginasBueno El Tío Petros y La Conjetura de Gold Bach Resumen BJosué DavidAún no hay calificaciones
- Memorias de Un Mexicano ReseñaDocumento3 páginasMemorias de Un Mexicano Reseñamoofer00175% (4)
- Metodos de Muestreo ProbabilisticoDocumento6 páginasMetodos de Muestreo ProbabilisticoLaura Sofia Zuñiga BolañosAún no hay calificaciones
- T Sem14 Ses28 Taller N°8Documento2 páginasT Sem14 Ses28 Taller N°8Giusseppe [MCh]Aún no hay calificaciones
- ExamenFinal METODOLOGIA GRUPODocumento9 páginasExamenFinal METODOLOGIA GRUPORay SthefanoAún no hay calificaciones
- Administración Cientifica de TaylorDocumento59 páginasAdministración Cientifica de TaylorGuidho Gutierrez PalominoAún no hay calificaciones
- Cuadro Comparativo Enfoques Cualitativo y CuantitativoDocumento2 páginasCuadro Comparativo Enfoques Cualitativo y CuantitativoAdrianAún no hay calificaciones
- 1.5 Investigación Experimental y No ExperimentalDocumento14 páginas1.5 Investigación Experimental y No ExperimentalAndres ZapataAún no hay calificaciones
- UNIDAD 1 - Tema 3Documento17 páginasUNIDAD 1 - Tema 3EFRAIN ENRIQUE VASQUEZ ALVARADOAún no hay calificaciones
- Goytia Fatima Problema2Documento28 páginasGoytia Fatima Problema2FatimaAún no hay calificaciones
- Marun SoledadDocumento3 páginasMarun SoledadJoaquinAún no hay calificaciones
- Karl Terzaghi PDFDocumento210 páginasKarl Terzaghi PDF3112705770Aún no hay calificaciones
- Actividad 1 - Eliana MorilloDocumento5 páginasActividad 1 - Eliana MorilloEliana MorilloAún no hay calificaciones
- Mapa Conceptual 118 UnaDocumento7 páginasMapa Conceptual 118 UnaMary Giovanna Vera Vielma100% (1)
- Contenido Teoria Medica IiDocumento77 páginasContenido Teoria Medica IiPaola MartinezAún no hay calificaciones
- Topo 2 Informe 4Documento9 páginasTopo 2 Informe 4Chelsea BlandonAún no hay calificaciones
- Tema 13Documento9 páginasTema 13SaraAún no hay calificaciones
- Carta Mandálica Trabajo FinalDocumento19 páginasCarta Mandálica Trabajo FinalJosé Manuel Rodríguez VillanuevaAún no hay calificaciones
- Conceptos Básicos de EstadísticaDocumento13 páginasConceptos Básicos de Estadísticamaibelin alvarezAún no hay calificaciones
- Tesis Videoconferencia 1 - Taller de Tesis 1 .2021.2 UpnDocumento89 páginasTesis Videoconferencia 1 - Taller de Tesis 1 .2021.2 UpnJorge Aguilar100% (2)
- Ciencia en Tiempos de Crisis. Una Propuesta Desde La Descolonialidad.Documento11 páginasCiencia en Tiempos de Crisis. Una Propuesta Desde La Descolonialidad.Luis PouchucqAún no hay calificaciones