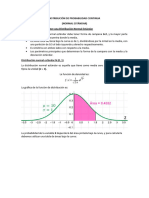
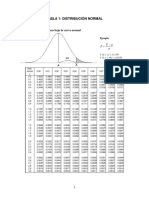
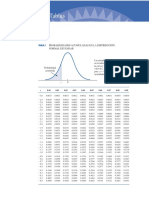
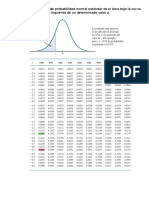
También podría gustarte
- Informe de Determicaion de NitrogenoDocumento6 páginasInforme de Determicaion de Nitrogenoandres guerreroAún no hay calificaciones
- Tema 5 Ingind2Documento21 páginasTema 5 Ingind2Laura CeciliaAún no hay calificaciones
- La distribución normalDocumento114 páginasLa distribución normalEvelina JimenezAún no hay calificaciones
- Informe de Gravimetria de CalcioDocumento5 páginasInforme de Gravimetria de Calcioandres guerrero100% (1)
- Informe Determinacion de La Constate de SolubilidadDocumento7 páginasInforme Determinacion de La Constate de Solubilidadandres guerrero100% (1)
- GUÍA Tablas de Distribución NormalDocumento19 páginasGUÍA Tablas de Distribución NormalBarriosAravenaAún no hay calificaciones
- Distribución normalDocumento19 páginasDistribución normalDIANA LISSET SANCHEZ RAMOSAún no hay calificaciones
- La Distribucion Normal - Sept. - 2016Documento23 páginasLa Distribucion Normal - Sept. - 2016Nicolás Barragán SánchezAún no hay calificaciones
- Distribución NormalDocumento14 páginasDistribución NormalNatha SureAún no hay calificaciones
- Distribuciones Normales y ProbabilidadesDocumento4 páginasDistribuciones Normales y ProbabilidadesGustavo LunaAún no hay calificaciones
- Distribución normal: características y aplicacionesDocumento33 páginasDistribución normal: características y aplicacionesNadirAún no hay calificaciones
- Distribucion NormalDocumento4 páginasDistribucion NormalCarmen GarciaAún no hay calificaciones
- DISTRIBUCION NORMAL para ClaseDocumento90 páginasDISTRIBUCION NORMAL para ClaseRobinson Saa FerAún no hay calificaciones
- Distribuciones muestralesDocumento20 páginasDistribuciones muestralesThe mastex1Aún no hay calificaciones
- Lectura Repaso Distribución NormalDocumento5 páginasLectura Repaso Distribución NormalAdriana Celia Figueroa ValdiviaAún no hay calificaciones
- Distribucion Normal Set 2006Documento14 páginasDistribucion Normal Set 2006libertadores7100% (1)
- Distribución NormalDocumento34 páginasDistribución NormalJorge CastroAún no hay calificaciones
- Distribución Normal o GaussianaDocumento17 páginasDistribución Normal o GaussianaFatima montejoAún no hay calificaciones
- Distribución de Probabilidad Continua - ExposiciónDocumento4 páginasDistribución de Probabilidad Continua - ExposiciónAlexMusicAún no hay calificaciones
- Segunda Unidad Metodos EstadisticosDocumento6 páginasSegunda Unidad Metodos EstadisticosJonatan GamalielAún no hay calificaciones
- 3 Distribucion NormalDocumento13 páginas3 Distribucion Normalgavi1912100% (1)
- Distribucion NormalDocumento115 páginasDistribucion NormalMiriam Elizabeth Coronado VilchezAún no hay calificaciones
- Tablas Areas Bajo Curva NormalDocumento2 páginasTablas Areas Bajo Curva NormalStheysi RojasAún no hay calificaciones
- TablasDocumento2 páginasTablasfixmn postyAún no hay calificaciones
- Distribucion NormalDocumento115 páginasDistribucion Normalcibeli67% (3)
- Tablas-normal-chi-t-F Alls PDFDocumento19 páginasTablas-normal-chi-t-F Alls PDFAndy MirandaAún no hay calificaciones
- Solución - Retroalimentación - Unidad 4 - GRUPO ADocumento34 páginasSolución - Retroalimentación - Unidad 4 - GRUPO ABhelen del Karmen Orellana PatazcaAún no hay calificaciones
- Distribucion NormalDocumento72 páginasDistribucion NormalHUARANCA PEREZ YESSICA YAJAIRAAún no hay calificaciones
- Ejercicios de Modelamiento y SimulaciónDocumento6 páginasEjercicios de Modelamiento y SimulaciónJhonatan Martín Bernabé Nuntón0% (2)
- Distribucion NormalDocumento105 páginasDistribucion NormalMiguel Aguilar100% (1)
- Distribución Normal - Docx 12Documento9 páginasDistribución Normal - Docx 12Gabi MateranoAún no hay calificaciones
- Distribución Normal de ProbabilidadDocumento6 páginasDistribución Normal de ProbabilidadMaricel Anahi Carbajal SantacruzAún no hay calificaciones
- Leccion 2 Sistemas de EcuacionesDocumento7 páginasLeccion 2 Sistemas de EcuacionesJonathan PizaAún no hay calificaciones
- Qué Es Un Intervalo de ConfianzaDocumento7 páginasQué Es Un Intervalo de Confianzaisael sanchez garciaAún no hay calificaciones
- CLASE Nº3 Ditrib ZDocumento103 páginasCLASE Nº3 Ditrib ZIvana Dilia JustinianoAún no hay calificaciones
- Sesion 3 NormalDocumento10 páginasSesion 3 NormalgianellaAún no hay calificaciones
- Distribución NormalDocumento6 páginasDistribución NormalGilberto CarbajalAún no hay calificaciones
- s6 PPT Distribuciones ContinuasDocumento24 páginass6 PPT Distribuciones ContinuasSERGIO GABRIEL GOICOCHEA RABANALAún no hay calificaciones
- Fis 200 Inf#5Documento4 páginasFis 200 Inf#5Jhon D Cahuaya PintoAún no hay calificaciones
- Campo Electrico Entre Dos Placas y Lineas EquipotencialesDocumento13 páginasCampo Electrico Entre Dos Placas y Lineas EquipotencialesJurgen González LópezAún no hay calificaciones
- Analisis NumericoDocumento11 páginasAnalisis NumericoFelo OnofaAún no hay calificaciones
- Tema 4 Variables Aleatorias y Sus Distribuciones Distribución NormalDocumento5 páginasTema 4 Variables Aleatorias y Sus Distribuciones Distribución NormalAir SalvaAún no hay calificaciones
- Distribución normalDocumento3 páginasDistribución normalMario Coh MuñozAún no hay calificaciones
- Distribución normalDocumento3 páginasDistribución normalHiraikHimura50% (2)
- Tablas Z y T-StudentDocumento3 páginasTablas Z y T-StudentHiraikHimuraAún no hay calificaciones
- Tarea Estadistica Semana 9Documento8 páginasTarea Estadistica Semana 9Oliver RamirezAún no hay calificaciones
- Tabla NormalDocumento2 páginasTabla Normaljonatan david salamanca gomezAún no hay calificaciones
- Distribución Normal - Esperanza MatemáticaDocumento8 páginasDistribución Normal - Esperanza MatemáticaMaricel Anahi Carbajal SantacruzAún no hay calificaciones
- Tabla de Distribución Normal PDFDocumento2 páginasTabla de Distribución Normal PDFPopoAún no hay calificaciones
- Tablasprobabilidades ColorDocumento2 páginasTablasprobabilidades ColorLEONARDO PIERO TORRES HUAMANAún no hay calificaciones
- Distribución Normal Profesor10dematesDocumento9 páginasDistribución Normal Profesor10dematessymymelAún no hay calificaciones
- Tema 11 NormalDocumento10 páginasTema 11 NormalCamilo CastroAún no hay calificaciones
- Cálculo de Proporciones para Distribución Normal y T de StudentDocumento11 páginasCálculo de Proporciones para Distribución Normal y T de StudentAskalosAún no hay calificaciones
- 2018 - Estadistica U4 (V00)Documento21 páginas2018 - Estadistica U4 (V00)Eduardo ChivalanAún no hay calificaciones
- Tablas de Probabilidades (1) - 10Documento1 páginaTablas de Probabilidades (1) - 10Katiusca Del Cisne Jaramillo EspinozaAún no hay calificaciones
- Distribución Normal ProbabilidadesDocumento18 páginasDistribución Normal Probabilidadesiracema moralesAún no hay calificaciones
- Aaa-Jr Dist Normal Comun Sem 2-22Documento115 páginasAaa-Jr Dist Normal Comun Sem 2-22Fernando MelgarAún no hay calificaciones
- Probabilidades Acumuladas Distribución Normal EstandarDocumento3 páginasProbabilidades Acumuladas Distribución Normal Estandaruvita UuUAún no hay calificaciones
- Tablas EstadisticaDocumento5 páginasTablas EstadisticaFernando ValdezAún no hay calificaciones
- Tablas de DistribuciónDocumento5 páginasTablas de DistribuciónANTHONY ALEJANDRO LAURA PICHARDOAún no hay calificaciones
- Tablas EstadisticasDocumento11 páginasTablas EstadisticasDIANA MIRELLA QUISPE HUAMANAún no hay calificaciones
- TablasDocumento27 páginasTablasRuth LopezAún no hay calificaciones
- Iso 14001 2015 Cambios NovedadesDocumento30 páginasIso 14001 2015 Cambios NovedadesGa Ce J ManuelAún no hay calificaciones
- Clase 21 - 04 - 22Documento12 páginasClase 21 - 04 - 22andres guerreroAún no hay calificaciones
- Taller Primer Corte Volumetria y ElectroquimicaDocumento2 páginasTaller Primer Corte Volumetria y Electroquimicaandres guerreroAún no hay calificaciones
- Introducción A La ElectroquímicaDocumento46 páginasIntroducción A La Electroquímicaandres guerreroAún no hay calificaciones
- Clase 11 30 - 03 - 22Documento29 páginasClase 11 30 - 03 - 22andres guerreroAún no hay calificaciones
- Diagrama Mental de Las Definiciones y Terminos de La ISO 14001 - 2015Documento1 páginaDiagrama Mental de Las Definiciones y Terminos de La ISO 14001 - 2015andres guerreroAún no hay calificaciones
- Iso 14001Documento12 páginasIso 14001LoRelys VeGa50% (2)
- Diagrama MentalDocumento1 páginaDiagrama Mentalandres guerreroAún no hay calificaciones
- Ejercicios de ElectroquímicaDocumento4 páginasEjercicios de Electroquímicaandres guerreroAún no hay calificaciones
- Atomy ColombiaDocumento48 páginasAtomy Colombiaandres guerrero0% (1)
- Taller 3corteDocumento3 páginasTaller 3corteBrandonAún no hay calificaciones
- PDFDocumento304 páginasPDFElcacasAún no hay calificaciones
- Informe de Analitica Final PDFDocumento7 páginasInforme de Analitica Final PDFandres guerreroAún no hay calificaciones
- Tema 5 - EquilibrioDocumento30 páginasTema 5 - Equilibrioandres guerreroAún no hay calificaciones
- Taller Tercer ParcialDocumento1 páginaTaller Tercer Parcialandres guerreroAún no hay calificaciones
- Solubilidad PDFDocumento2 páginasSolubilidad PDFDonatoXDAún no hay calificaciones
- Separación de Aminas Terciarias en Modo Mixto en Primesep 200Documento2 páginasSeparación de Aminas Terciarias en Modo Mixto en Primesep 200andres guerreroAún no hay calificaciones
- Campo eléctrico y autoDocumento1 páginaCampo eléctrico y autoandres guerreroAún no hay calificaciones
- NormaCodexHarinaTrigo152Documento4 páginasNormaCodexHarinaTrigo152Justine LewisAún no hay calificaciones
- Metodo Kendal PDFDocumento77 páginasMetodo Kendal PDFDiego Iván De La CruzAún no hay calificaciones
- Halo RebirthDocumento32 páginasHalo RebirthNicolásRestrepoHenao100% (1)
- Equilibrios Heterogéneos IIDocumento3 páginasEquilibrios Heterogéneos IIDavid Gomez VegaAún no hay calificaciones
- Metodo Kendal PDFDocumento77 páginasMetodo Kendal PDFDiego Iván De La CruzAún no hay calificaciones
- Titulaciones PrecipitaciónDocumento28 páginasTitulaciones Precipitaciónandres guerreroAún no hay calificaciones
- Informe de Titulacion Acido-BaseDocumento7 páginasInforme de Titulacion Acido-Baseandres guerrero100% (2)
- CARBOHIDRATOSDocumento17 páginasCARBOHIDRATOSandres guerreroAún no hay calificaciones
- Al0137as 2Documento6 páginasAl0137as 2andres guerreroAún no hay calificaciones
- Econometría examen final Icesi 2016Documento13 páginasEconometría examen final Icesi 2016daniel pazAún no hay calificaciones
- Taller Inferencia EstadisticaDocumento12 páginasTaller Inferencia EstadisticaANGELA YICEL JIMENEZ RIASCOSAún no hay calificaciones
- Ramos 2017 Etnografia Concentrca y DidacticaDocumento14 páginasRamos 2017 Etnografia Concentrca y DidacticaLeslie GAún no hay calificaciones
- Formato IEAC 3 - Español e InglesDocumento10 páginasFormato IEAC 3 - Español e InglesHernández Barragán YaritzaAún no hay calificaciones
- En General, El Método Científico Comprende Los Siguientes PasosDocumento2 páginasEn General, El Método Científico Comprende Los Siguientes PasosSnayder RuizAún no hay calificaciones
- Tarea 8Documento12 páginasTarea 8Xavier RodríguezAún no hay calificaciones
- PDF Matematica Financiera II DLDocumento48 páginasPDF Matematica Financiera II DLluis lopezAún no hay calificaciones
- SESIÓN DE APRENDIZAJ PrimeroDocumento4 páginasSESIÓN DE APRENDIZAJ PrimeroJose Antonio HospinalAún no hay calificaciones
- ParamoDocumento8 páginasParamoMaura SosaAún no hay calificaciones
- Metodologías Cualitativas y Cuantitativas Corregido - 1Documento4 páginasMetodologías Cualitativas y Cuantitativas Corregido - 1Zeus AcostaAún no hay calificaciones
- Design of Experiments DoE Applied To Pharmaceutical and - En.esDocumento16 páginasDesign of Experiments DoE Applied To Pharmaceutical and - En.esDarmSlayer 13Aún no hay calificaciones
- Actividad 2 Matematica FinancieraDocumento5 páginasActividad 2 Matematica FinancieraCarolinaAún no hay calificaciones
- Estadística en La Investigación Educativa: July 2019Documento93 páginasEstadística en La Investigación Educativa: July 2019José Alberto PinedaAún no hay calificaciones
- Libro 5Documento7 páginasLibro 5Jostin SanchezAún no hay calificaciones
- Ejercicio 66Documento5 páginasEjercicio 66daniel lancherosAún no hay calificaciones
- Laboratorio de InvestigaciónDocumento38 páginasLaboratorio de InvestigaciónMariana SophiaAún no hay calificaciones
- Tema 5Documento28 páginasTema 5marjoer77Aún no hay calificaciones
- Apéndices EstadísticosDocumento8 páginasApéndices EstadísticosLorenzoAún no hay calificaciones
- Material de Lectura v10 - A06Documento5 páginasMaterial de Lectura v10 - A06DanielRiosRoblesAún no hay calificaciones
- TV - Solucionario - Probabilidad Total PDFDocumento7 páginasTV - Solucionario - Probabilidad Total PDFBreisner GonzalesAún no hay calificaciones
- Plan de Asignatura Seminario de Investigacion IiiDocumento7 páginasPlan de Asignatura Seminario de Investigacion IiiMartha CharrisAún no hay calificaciones
- Manual Estadística en RDocumento41 páginasManual Estadística en RFernando Antonio Guevara IbáñezAún no hay calificaciones
- Preguntas Tipo IcfesDocumento3 páginasPreguntas Tipo IcfesMaria Camila ManjarresAún no hay calificaciones
- 7723 PMDocumento3 páginas7723 PMJosé MendozaAún no hay calificaciones
- Investigación CuantitativaDocumento1 páginaInvestigación CuantitativaArnaldo Preso De LigaAún no hay calificaciones
- Tarea 1 Cap 1 y 2 SampieriDocumento2 páginasTarea 1 Cap 1 y 2 SampieriIsmarc LanderosAún no hay calificaciones
- Intervalos de Confianza FormularioDocumento1 páginaIntervalos de Confianza FormularioMarco AldamaAún no hay calificaciones
- Guia DidacticaDocumento143 páginasGuia DidacticaEve Arequipa RoseroAún no hay calificaciones
- Manual para La Elaboración de Investigación Cuantitativa y Cualitativa en Psicología de La SaludDocumento62 páginasManual para La Elaboración de Investigación Cuantitativa y Cualitativa en Psicología de La SaludDann' Mendoza ÜAún no hay calificaciones