También podría gustarte
- Actividad de Aprendizaje 1. Bases de DatosDocumento14 páginasActividad de Aprendizaje 1. Bases de DatosLuis Gerardo SanchezAún no hay calificaciones
- Actividad de Aprendizaje 2. Diseño de Una Base de Datos (Jose de La Cruz Perez Lopez)Documento7 páginasActividad de Aprendizaje 2. Diseño de Una Base de Datos (Jose de La Cruz Perez Lopez)joshua Christopher100% (1)
- Actividad de Aprendizaje 3 Interfaces y HerenciaDocumento7 páginasActividad de Aprendizaje 3 Interfaces y Herenciaelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 2 Diseño de Una Base de DatosDocumento10 páginasActividad de Aprendizaje 2 Diseño de Una Base de Datoselmer villagran0% (1)
- Actividad de Aprendizaje 2 ImplementaciónDocumento7 páginasActividad de Aprendizaje 2 Implementaciónelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 3 Implementacion de SQL AvanzadoDocumento10 páginasActividad de Aprendizaje 3 Implementacion de SQL AvanzadoALfredo PAún no hay calificaciones
- Actividad de Aprendizaje 1 Lenguaje de Definicion de DatosDocumento7 páginasActividad de Aprendizaje 1 Lenguaje de Definicion de Datosjoshua Christopher100% (1)
- Actividad de Aprendizaje 3 Aspectos Legales para La Implantacion de Un Software LibreDocumento9 páginasActividad de Aprendizaje 3 Aspectos Legales para La Implantacion de Un Software LibreAngelDeathhFishAún no hay calificaciones
- Actividad de Aprendizaje 1 Análisis y Diseño Orientado A ObjetoDocumento4 páginasActividad de Aprendizaje 1 Análisis y Diseño Orientado A Objetoelmer villagran100% (2)
- Actividad 4. Implantación de Sistemas de Software Libre.Documento27 páginasActividad 4. Implantación de Sistemas de Software Libre.juan100% (2)
- Actividad de Aprendizaje 2 Harware de Red y Medios de TransmisiónDocumento23 páginasActividad de Aprendizaje 2 Harware de Red y Medios de Transmisiónelmer villagran0% (1)
- Actividad de Aprendizaje 1. Nociones Básicas de Redes de Computadoras.Documento3 páginasActividad de Aprendizaje 1. Nociones Básicas de Redes de Computadoras.Javier LedesmaAún no hay calificaciones
- Desarrollo de Propuesta de Un Business Center para Un Hotel 5 Estrellas.Documento9 páginasDesarrollo de Propuesta de Un Business Center para Un Hotel 5 Estrellas.juan100% (1)
- Actividad de Aprendizaje 1 Sistemas de Numeración y Álgebra de BooleDocumento4 páginasActividad de Aprendizaje 1 Sistemas de Numeración y Álgebra de Booleelmer villagran50% (2)
- Actividad de Aprendizaje 1. Análisis y Diseño Orientado A ObjetoDocumento3 páginasActividad de Aprendizaje 1. Análisis y Diseño Orientado A ObjetoIgnacio Loyola CamachoAún no hay calificaciones
- Actividad Del Aprendizaje 2 Ordenamiento y BusquedaDocumento6 páginasActividad Del Aprendizaje 2 Ordenamiento y Busquedaalejandro100% (3)
- Actividad1 - Estructudas de Lenguaje Ensablador - IEUDocumento9 páginasActividad1 - Estructudas de Lenguaje Ensablador - IEUManuel Resendiz TorresAún no hay calificaciones
- Actividad de Aprendizaje 4. Bases de Datos DistribuidasDocumento11 páginasActividad de Aprendizaje 4. Bases de Datos DistribuidasLuis Gerardo SanchezAún no hay calificaciones
- Actividad de Aprendizaje 3. Aspectos Legales para La Implantación de Un Software LibreDocumento12 páginasActividad de Aprendizaje 3. Aspectos Legales para La Implantación de Un Software LibreMoises Callejas100% (3)
- Actividad de Aprendizaje 3. Ejecución y Control de Un Proyecto.Documento4 páginasActividad de Aprendizaje 3. Ejecución y Control de Un Proyecto.jjnh0% (1)
- Actividad de Aprendizaje 4 Operaciones Con Números ComplejosDocumento5 páginasActividad de Aprendizaje 4 Operaciones Con Números Complejoselmer villagran100% (2)
- Actividad de Aprendizaje 4. Operaciones Con Números ComplejosDocumento8 páginasActividad de Aprendizaje 4. Operaciones Con Números ComplejosMoises Callejas67% (3)
- Actividad de Aprendizaje No. 3 Análisis y Diseño de CircuitosDocumento3 páginasActividad de Aprendizaje No. 3 Análisis y Diseño de CircuitosTESAESP2000100% (3)
- Actividad de Aprendizaje 1. Lenguaje de Definición de DatosDocumento7 páginasActividad de Aprendizaje 1. Lenguaje de Definición de DatosJesus Chavez100% (1)
- Aspectos Legales para La Implantación de Un Software LibreDocumento11 páginasAspectos Legales para La Implantación de Un Software Libregabriel martinAún no hay calificaciones
- Actividad de Aprendizaje 3. MySQLDocumento11 páginasActividad de Aprendizaje 3. MySQLMoises Callejas100% (2)
- Actividad de Aprendizaje 4. Proyecto IntegradorDocumento22 páginasActividad de Aprendizaje 4. Proyecto IntegradorLuis Gerardo SanchezAún no hay calificaciones
- Actividad de Aprendizaje 2. Sistema Operativo GNULinuxDocumento26 páginasActividad de Aprendizaje 2. Sistema Operativo GNULinuxMoises CallejasAún no hay calificaciones
- Actividad 4 Calculadora Binaria IIDocumento8 páginasActividad 4 Calculadora Binaria IIJuan Astorga100% (1)
- Actividad de Aprendizaje 1. Sistemas de Numeración & Álgebra de BooleDocumento4 páginasActividad de Aprendizaje 1. Sistemas de Numeración & Álgebra de BooleJavier Ledesma0% (1)
- Actividad de Aprendizaje 3. MySQLDocumento10 páginasActividad de Aprendizaje 3. MySQLAndrea MenesesAún no hay calificaciones
- Actividad de Aprendizaje 2. Funciones y SimplificacionesDocumento8 páginasActividad de Aprendizaje 2. Funciones y SimplificacionesIvan Juarez Cuautle100% (1)
- Actividad de Aprendizaje 2. Herramientas Asistidas Por ComputadoraDocumento5 páginasActividad de Aprendizaje 2. Herramientas Asistidas Por ComputadoraLuis Gerardo SanchezAún no hay calificaciones
- Actividad 2, Sistema Operativo GNU LinuxDocumento14 páginasActividad 2, Sistema Operativo GNU LinuxJuan AstorgaAún no hay calificaciones
- Actividad 1Documento6 páginasActividad 1betoAún no hay calificaciones
- Actividad de Aprendizaje 2 Lenguaje EnsambladorDocumento4 páginasActividad de Aprendizaje 2 Lenguaje EnsambladorPierre Vivanco ZavalaAún no hay calificaciones
- Actividad 4 Manual de SeleccionDocumento17 páginasActividad 4 Manual de SeleccionLevis Romario Andrade TenorioAún no hay calificaciones
- Actividad de Aprendizaje Instalación y Configuración de Mysql ServerDocumento31 páginasActividad de Aprendizaje Instalación y Configuración de Mysql Serverelmer villagran100% (1)
- Actividad de Aprendizaje 3. Matrices de Transformaciones LinealesDocumento8 páginasActividad de Aprendizaje 3. Matrices de Transformaciones LinealesAngelDeathhFish0% (3)
- Actividad de Aprendizaje 3... Procesador MipsDocumento9 páginasActividad de Aprendizaje 3... Procesador Mipselmer villagranAún no hay calificaciones
- Examen 7Documento22 páginasExamen 7Zaira TAún no hay calificaciones
- Actividad 2Documento18 páginasActividad 2Ernesto TorresAún no hay calificaciones
- Iniciando Mi Experiencia en El Proyect ManagementDocumento13 páginasIniciando Mi Experiencia en El Proyect ManagementalbertoAún no hay calificaciones
- La Herramienta de Simulación de Redes Packet TracerDocumento4 páginasLa Herramienta de Simulación de Redes Packet TracerElProfeHellsAún no hay calificaciones
- Actividad de Aprendizaje 2. Un Sistema Operativo en Máquina VirtualDocumento3 páginasActividad de Aprendizaje 2. Un Sistema Operativo en Máquina VirtualAngelDeathhFishAún no hay calificaciones
- Actividad 1 IEU Programando en JavaDocumento6 páginasActividad 1 IEU Programando en JavaalejandroAún no hay calificaciones
- Programación Con OpenGLDocumento17 páginasProgramación Con OpenGLDesarrollo WebAún no hay calificaciones
- Tarea Listas Ligadas IEUDocumento6 páginasTarea Listas Ligadas IEUDaniel LimonesAún no hay calificaciones
- Actividad de Aprendizaje 2 Equivalencias TrigonometricasDocumento10 páginasActividad de Aprendizaje 2 Equivalencias TrigonometricasJuan Astorga100% (1)
- Actividad de Aprendizaje 3 Munguia AngelDocumento15 páginasActividad de Aprendizaje 3 Munguia AngelAngelDeathhFishAún no hay calificaciones
- Actividad Uno AnteproyectoDocumento10 páginasActividad Uno Anteproyectoalejandro100% (1)
- Actividad de Aprendizaje 1. Matrices andDocumento16 páginasActividad de Aprendizaje 1. Matrices andJESUA CRUZ PACHECO100% (1)
- IEU - POO - A01 - Programacion Orientada A Objetos Actividad 1Documento3 páginasIEU - POO - A01 - Programacion Orientada A Objetos Actividad 1Raul MarunAún no hay calificaciones
- Actividad de Aprendizaje 3 Análisis de Sistemas OperativosDocumento9 páginasActividad de Aprendizaje 3 Análisis de Sistemas Operativoselmer villagran50% (2)
- Actividad de Aprendizaje 1 Bases de Datos (Jose de La Cruz Perez Lopez)Documento22 páginasActividad de Aprendizaje 1 Bases de Datos (Jose de La Cruz Perez Lopez)joshua ChristopherAún no hay calificaciones
- Actividad 1 Bases de DatosDocumento23 páginasActividad 1 Bases de DatosMarco Alejandro Hernandez SanchezAún no hay calificaciones
- Material Del Curso (Mysql)Documento68 páginasMaterial Del Curso (Mysql)Javier VegaAún no hay calificaciones
- Bases de Datos #1Documento18 páginasBases de Datos #1Jesús Daniel Alvear VillalbaAún no hay calificaciones
- Capitulogratis PHP & MYSQLDocumento60 páginasCapitulogratis PHP & MYSQLJavier GuzmánAún no hay calificaciones
- Unidad 2 - Desde Cero Con MySQLDocumento12 páginasUnidad 2 - Desde Cero Con MySQLJuan Manuel AchonAún no hay calificaciones
- Actividad de Aprendizaje 1 Componentes de La Infraestructura de TiDocumento6 páginasActividad de Aprendizaje 1 Componentes de La Infraestructura de Tielmer villagran100% (1)
- Actividad de Aprendizaje 3 JavascriptDocumento4 páginasActividad de Aprendizaje 3 Javascriptelmer villagran33% (3)
- Flota JunioDocumento7 páginasFlota Junioelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 4 Implantación de Sistemas de Software LibreDocumento26 páginasActividad de Aprendizaje 4 Implantación de Sistemas de Software Libreelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje Instalación y Configuración de Mysql ServerDocumento31 páginasActividad de Aprendizaje Instalación y Configuración de Mysql Serverelmer villagran100% (1)
- Actividad de Aprendizaje 4 Implantación de Sistemas de Software LibreDocumento26 páginasActividad de Aprendizaje 4 Implantación de Sistemas de Software Libreelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 3 Criterios de La Primera y Segunda DerivadaDocumento6 páginasActividad de Aprendizaje 3 Criterios de La Primera y Segunda Derivadaelmer villagranAún no hay calificaciones
- Tabla FederalDocumento2 páginasTabla Federalelmer villagranAún no hay calificaciones
- Flota JunioDocumento7 páginasFlota Junioelmer villagranAún no hay calificaciones
- Carga MoralDocumento7 páginasCarga Moralelmer villagranAún no hay calificaciones
- Tramite de LeonDocumento820 páginasTramite de Leonelmer villagranAún no hay calificaciones
- Tramites de Enero y NoviembreDocumento568 páginasTramites de Enero y Noviembreelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 1 Elementos y Características de Las RedesDocumento5 páginasActividad de Aprendizaje 1 Elementos y Características de Las Redeselmer villagran80% (5)
- Tramites de La SemanaDocumento304 páginasTramites de La Semanaelmer villagranAún no hay calificaciones
- Flota JunioDocumento7 páginasFlota Junioelmer villagranAún no hay calificaciones
- Empresa Sca401214et4Documento12 páginasEmpresa Sca401214et4elmer villagranAún no hay calificaciones
- Tramites de Las SemanaDocumento264 páginasTramites de Las Semanaelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 3 Ejercicios de Distribución de ProbabilidadesDocumento6 páginasActividad de Aprendizaje 3 Ejercicios de Distribución de Probabilidadeselmer villagranAún no hay calificaciones
- Flota Mayo FraDocumento68 páginasFlota Mayo Fraelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 2 Harware de Red y Medios de TransmisiónDocumento23 páginasActividad de Aprendizaje 2 Harware de Red y Medios de Transmisiónelmer villagran0% (1)
- Actividad de Aprendizaje 4 Ejercicios de Estadística InferencialDocumento12 páginasActividad de Aprendizaje 4 Ejercicios de Estadística Inferencialelmer villagran100% (2)
- Actividad de Aprendizaje 3 Ejercicios de Distribución de ProbabilidadesDocumento6 páginasActividad de Aprendizaje 3 Ejercicios de Distribución de Probabilidadeselmer villagran75% (4)
- Actividad de Aprendizaje 1 Sistemas de Numeración y Álgebra de BooleDocumento4 páginasActividad de Aprendizaje 1 Sistemas de Numeración y Álgebra de Booleelmer villagran50% (2)
- El PlanetaDocumento1 páginaEl Planetaelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 2 Ejercicios de ProbabilidadDocumento8 páginasActividad de Aprendizaje 2 Ejercicios de Probabilidadelmer villagranAún no hay calificaciones
- Actividad de Aprendizaje 3 Ejercicios de Distribución de ProbabilidadesDocumento6 páginasActividad de Aprendizaje 3 Ejercicios de Distribución de Probabilidadeselmer villagran75% (4)
- Actividad de Aprendizaje 2 Aplicación de La Técnica ContableDocumento7 páginasActividad de Aprendizaje 2 Aplicación de La Técnica Contableelmer villagran100% (2)
- Protocolos I2c, Rs-232, Rs-485, Uart, CanDocumento6 páginasProtocolos I2c, Rs-232, Rs-485, Uart, CanAnonymous IoreTDh7100% (1)
- UnHiDER USBFile v4.3.0.0, Desinfecta Memorias USB's y Discos Duros ExtraíblesDocumento4 páginasUnHiDER USBFile v4.3.0.0, Desinfecta Memorias USB's y Discos Duros ExtraíblesCarlos andresAún no hay calificaciones
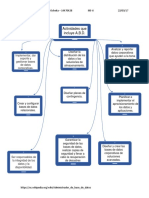
- Actividades Que Incluye La ABDDocumento1 páginaActividades Que Incluye La ABDCarlos OcheitaAún no hay calificaciones
- RHCE - Apuntes Del CursoDocumento51 páginasRHCE - Apuntes Del CursoCibeles100% (1)
- Tema 1.1 Estándar 802.11xDocumento2 páginasTema 1.1 Estándar 802.11xGustavo CruzAún no hay calificaciones
- Sistema Operativo AixDocumento22 páginasSistema Operativo AixYury Yver Ortuño CalvoAún no hay calificaciones
- Plan de Capacitacion Basica para TDM PDFDocumento5 páginasPlan de Capacitacion Basica para TDM PDFNolfa LabbéAún no hay calificaciones
- D64250CS10 sg1Documento458 páginasD64250CS10 sg1Maria PachecoAún no hay calificaciones
- Guia NormalizacionDocumento9 páginasGuia NormalizacionKrysium moonbladeAún no hay calificaciones
- Elementos de Diseño de La CachéDocumento6 páginasElementos de Diseño de La CachéEspinoza Hernández Yesser100% (1)
- Creacion de Raid 0 PDFDocumento8 páginasCreacion de Raid 0 PDFEdwinMartinezAún no hay calificaciones
- Uso Del TdaDocumento19 páginasUso Del TdaPaco Barrios33% (3)
- TD 3Documento223 páginasTD 3Claudio Francisco Viera MedinaAún no hay calificaciones
- T2 U3 Cuadro de Roles Aldahir CalderóDocumento4 páginasT2 U3 Cuadro de Roles Aldahir Calderóaldahir calderon cruzAún no hay calificaciones
- Cuadro ComparativoDocumento2 páginasCuadro ComparativoABDIIEL HERNANDEZAún no hay calificaciones
- Guia Configuracion y Funcionamiento Tia Portal v20Documento66 páginasGuia Configuracion y Funcionamiento Tia Portal v20antornioAún no hay calificaciones
- 3625 U3 Teorica Ok 1Documento49 páginas3625 U3 Teorica Ok 1kiara888kunAún no hay calificaciones
- Unidad 6Documento28 páginasUnidad 6bryan saul choqueAún no hay calificaciones
- Examen 1 A 16Documento11 páginasExamen 1 A 16IVAN33% (3)
- Semana 1 Reyna Dominguez BDDocumento9 páginasSemana 1 Reyna Dominguez BDReyna DomínguezAún no hay calificaciones
- Listas EnlazadasDocumento6 páginasListas EnlazadasKevin Olea garciaAún no hay calificaciones
- Cap10 PunterosDocumento33 páginasCap10 PunterosROYSER CARUAJULCA BARBOZAAún no hay calificaciones
- DP 5 3 Practice EspDocumento2 páginasDP 5 3 Practice EspLuis BermudezAún no hay calificaciones
- Documento Tarea2Documento10 páginasDocumento Tarea2Rafael Emilio Mateo CuevasAún no hay calificaciones
- Registros e Instrucciones PIC16F877ADocumento2 páginasRegistros e Instrucciones PIC16F877AOscarAún no hay calificaciones
- Topicos de ProgramacionDocumento6 páginasTopicos de ProgramacionAylin AnzaldoAún no hay calificaciones
- Sartoris Entris ManualDocumento46 páginasSartoris Entris ManualKarina Alvarado MenaAún no hay calificaciones
- Computation NubeDocumento4 páginasComputation Nubehfytdyj0% (1)
- Diferentes Tipos de Formatos de Videos, Audio e ImegenesDocumento9 páginasDiferentes Tipos de Formatos de Videos, Audio e ImegenesAlexRamosAún no hay calificaciones
- Final BD2 2015 1Documento4 páginasFinal BD2 2015 1Sergio Andres MazoAún no hay calificaciones