También podría gustarte
- Lenguaje AWKDocumento8 páginasLenguaje AWKEva LopezAún no hay calificaciones
- Algoritmos y Lenguajes de Programacion Unidad-6Documento36 páginasAlgoritmos y Lenguajes de Programacion Unidad-6carlos gs100% (1)
- Descripción Del Proceso Merrill CroweDocumento27 páginasDescripción Del Proceso Merrill CroweBiviana100% (1)
- Función HashDocumento48 páginasFunción Hashsimbiak100% (1)
- Crea y Publica tu App Android: Aprende a programar y crea tu app con Kotlin + Jetpack ComposeDe EverandCrea y Publica tu App Android: Aprende a programar y crea tu app con Kotlin + Jetpack ComposeAún no hay calificaciones
- Unidad 6 "Funciones" Algoritmos y Lenguajes de ProgramaciónDocumento42 páginasUnidad 6 "Funciones" Algoritmos y Lenguajes de ProgramaciónFrida Leija Gomez68% (19)
- Función HashDocumento15 páginasFunción HashHeberth CórdovaAún no hay calificaciones
- Algoritmos HashDocumento13 páginasAlgoritmos HashDuvan BotelloAún no hay calificaciones
- Practica 3Documento26 páginasPractica 3Alan MauricioAún no hay calificaciones
- Lectura y Escritura Interactiva de VariablesDocumento2 páginasLectura y Escritura Interactiva de VariablesWarren Gabriel Morales MartinezAún no hay calificaciones
- Funciones HashDocumento10 páginasFunciones HashorialAún no hay calificaciones
- Transformacion de ClavesDocumento13 páginasTransformacion de ClavesPriscila RiosAún no hay calificaciones
- HashingDocumento21 páginasHashingSmart Shop EcAún no hay calificaciones
- Semantico ApuntesDocumento22 páginasSemantico ApuntesLorenzo Antonio Jasso MartinezAún no hay calificaciones
- 24 Ejercicos Propuestos Tarea 31Documento14 páginas24 Ejercicos Propuestos Tarea 31ANTHONY VINICIO PANTOJA GARCIAAún no hay calificaciones
- MOOC de Criptolog Ia Matem Atica. Funciones de Resumen Digital (HASH)Documento68 páginasMOOC de Criptolog Ia Matem Atica. Funciones de Resumen Digital (HASH)Lenin MonsalveAún no hay calificaciones
- Cadena de Caracteres & ApuntadoresDocumento21 páginasCadena de Caracteres & ApuntadoresErin LopezAún no hay calificaciones
- Investigación de Estructura de Datos II-bDocumento15 páginasInvestigación de Estructura de Datos II-bGhadafy NevilleAún no hay calificaciones
- PREDA (Teoría Exámenes)Documento19 páginasPREDA (Teoría Exámenes)Jose RodriguezAún no hay calificaciones
- Informática: Tema I1 - Funciones y CondicionalesDocumento60 páginasInformática: Tema I1 - Funciones y Condicionalessergiogr0610Aún no hay calificaciones
- FuncionesDocumento11 páginasFuncionesJoséAún no hay calificaciones
- PREDA (Teor¡a Ex Menes)Documento19 páginasPREDA (Teor¡a Ex Menes)Arturo BarbaAún no hay calificaciones
- Sesión 06 - HashingDocumento95 páginasSesión 06 - HashingRaul PerezAún no hay calificaciones
- Ensayo Sobre HaskellDocumento7 páginasEnsayo Sobre HaskellCarlos CruzAún no hay calificaciones
- Unidad 5 - Tablas de HashDocumento20 páginasUnidad 5 - Tablas de HashNoé TejaxúnAún no hay calificaciones
- Clase 3 Las Funciones Internas de MatlabDocumento105 páginasClase 3 Las Funciones Internas de MatlabLiova Vera veraAún no hay calificaciones
- Evaluación Perezosa1Documento7 páginasEvaluación Perezosa1Alejandro Hernandez ValleAún no hay calificaciones
- LAB1 cadenasDeCaracteresDocumento9 páginasLAB1 cadenasDeCaracteresJose Adrian CriscioneAún no hay calificaciones
- Resumen Teoría - PHP PDFDocumento45 páginasResumen Teoría - PHP PDFpuertasrojasAún no hay calificaciones
- Capítulo 4 - Funciones Matemáticas - Sección 4.1Documento36 páginasCapítulo 4 - Funciones Matemáticas - Sección 4.1SantiagoAún no hay calificaciones
- Wilfri Funciones BasicasDocumento3 páginasWilfri Funciones Basicasmiguel menaAún no hay calificaciones
- Funciones en HaskellDocumento28 páginasFunciones en HaskellEvan Neal B QAún no hay calificaciones
- Librerias Ansi CDocumento5 páginasLibrerias Ansi CDavid ReynaAún no hay calificaciones
- Daw Practica06 2021Documento12 páginasDaw Practica06 2021adonay rivasAún no hay calificaciones
- Resumen2 PedroJhonatanBautistaBDocumento6 páginasResumen2 PedroJhonatanBautistaBJhonatan BautistaAún no hay calificaciones
- DispersionDocumento9 páginasDispersionXannya SalgadoAún no hay calificaciones
- Algoritmos Trabajo Unidad 6Documento37 páginasAlgoritmos Trabajo Unidad 6luzAún no hay calificaciones
- Modelo de Programación FuncionalDocumento117 páginasModelo de Programación FuncionalIsai ToledoAún no hay calificaciones
- Cap 05 - Métodos de Dispersión PDFDocumento67 páginasCap 05 - Métodos de Dispersión PDFAlex Chuquisana MendozaAún no hay calificaciones
- Funciones Internas PythonDocumento12 páginasFunciones Internas PythonJuan OchoaAún no hay calificaciones
- Apuntes Sobre Funciones de Una VariableDocumento13 páginasApuntes Sobre Funciones de Una VariableRomina NogueiraAún no hay calificaciones
- Funciones Definidas Por El Usuario y El Propio Lenguaje.Documento12 páginasFunciones Definidas Por El Usuario y El Propio Lenguaje.Noel Nardo LandezAún no hay calificaciones
- Concepto de VariableDocumento5 páginasConcepto de VariableNorma MiramonAún no hay calificaciones
- Trabajo Final FuncionesDocumento16 páginasTrabajo Final FuncionesJuan jose Alcalá FajardoAún no hay calificaciones
- Diseno de Un Codec HuffmanDocumento4 páginasDiseno de Un Codec HuffmanTURATURAAún no hay calificaciones
- Sub Funcion MAtlabDocumento9 páginasSub Funcion MAtlabNomada888100% (1)
- RakuDocumento37 páginasRakuKairós RosAún no hay calificaciones
- Curso PHP Cap 20Documento2 páginasCurso PHP Cap 20foxdriverAún no hay calificaciones
- Teoria - AlgoritmosComputacionalesDocumento17 páginasTeoria - AlgoritmosComputacionalesGiuli Genre BertAún no hay calificaciones
- Creación de Ïndices - Arboles B y Tablas de HashingDocumento22 páginasCreación de Ïndices - Arboles B y Tablas de Hashingoscar hinnojosaAún no hay calificaciones
- Manual SchemeDocumento20 páginasManual SchemeAndrés RuizAún no hay calificaciones
- Tema 3 Control de Lectura Capitulo 6Documento5 páginasTema 3 Control de Lectura Capitulo 6Misael Angelito SalinasAún no hay calificaciones
- Manual de PHP de WebEstiloDocumento14 páginasManual de PHP de WebEstiloArturo PavaAún no hay calificaciones
- Introducción Al Cálculo Lambda Usando RacketDocumento15 páginasIntroducción Al Cálculo Lambda Usando RacketIrán Méndez GonzálezAún no hay calificaciones
- Analisis SemanticoDocumento43 páginasAnalisis Semanticojkl316100% (1)
- Unidad 1 - Función HashDocumento12 páginasUnidad 1 - Función HashJose RodriAún no hay calificaciones
- Valdez Aldo Evidencia2.1Documento10 páginasValdez Aldo Evidencia2.1Aldo ValdezAún no hay calificaciones
- Liberacion Instantanea o FlashDocumento3 páginasLiberacion Instantanea o FlashDayanaCamachoAún no hay calificaciones
- Monografia Sistemas Gps PDFDocumento20 páginasMonografia Sistemas Gps PDFfranz adalidAún no hay calificaciones
- Foro TematicoDocumento12 páginasForo Tematicojesus benjamin sayaverde yllatupaAún no hay calificaciones
- TesisDocumento66 páginasTesisEzraAún no hay calificaciones
- Taller 7,8,9 Estroctura de LewisDocumento5 páginasTaller 7,8,9 Estroctura de LewisDAIRO DAVID DIAZ ROJASAún no hay calificaciones
- Edo Contenido Clase No. 7 Edo Lagrange y ClairautsDocumento13 páginasEdo Contenido Clase No. 7 Edo Lagrange y ClairautsSebastian AlexanderAún no hay calificaciones
- Actividades A Realizar en La Practica Del Tema Genetica Mendeliana Monohibrida y DihibridaDocumento13 páginasActividades A Realizar en La Practica Del Tema Genetica Mendeliana Monohibrida y DihibridaAlvaro Armando Muñoz OrtizAún no hay calificaciones
- Pulso CiudadanoDocumento60 páginasPulso CiudadanoContacto Ex-Ante100% (1)
- REGVEN1Documento4 páginasREGVEN1Jorge PirelaAún no hay calificaciones
- Textual Explicita y EspecificativaDocumento4 páginasTextual Explicita y EspecificativaPerez Sanchez Miriam JaredAún no hay calificaciones
- 1.-Obra de Toma ChallhuaniDocumento4 páginas1.-Obra de Toma ChallhuaniAntonio S LeoAún no hay calificaciones
- Apuntes de Clase Del Curso Seminario Investigativo VIDocumento7 páginasApuntes de Clase Del Curso Seminario Investigativo VIwhitepaladinAún no hay calificaciones
- Cinetica QuimicaDocumento22 páginasCinetica QuimicaRamiro BritoAún no hay calificaciones
- Principios de Energía y Momentum PDFDocumento21 páginasPrincipios de Energía y Momentum PDFCésarA.LópezAún no hay calificaciones
- Circuito Conversor de Digital A Análogo (Contador + Sumador) "Documento12 páginasCircuito Conversor de Digital A Análogo (Contador + Sumador) "Luis ChasiluisaAún no hay calificaciones
- Historia de La Computadora y Sus GeneracionesDocumento3 páginasHistoria de La Computadora y Sus Generacionesjohanny Burgos VillafañaAún no hay calificaciones
- Homologacion ASSET DOC LOC 6836823Documento105 páginasHomologacion ASSET DOC LOC 6836823Ricardo Matías Fernández TapiaAún no hay calificaciones
- Examen PHOTOSHOP BÁSICODocumento3 páginasExamen PHOTOSHOP BÁSICOMiguelon CespedesAún no hay calificaciones
- Distribuciones Notables DiscretasDocumento33 páginasDistribuciones Notables DiscretasKevin Olaya TrujilloAún no hay calificaciones
- Socavacion en Los Estribos Del PuenteDocumento4 páginasSocavacion en Los Estribos Del PuenteRonald Rafael Catire SolanoAún no hay calificaciones
- Raz Lógico Tema 3 TeslaDocumento12 páginasRaz Lógico Tema 3 TeslaOperativo ConinsaAún no hay calificaciones
- Manual de Servicio REFRIGETADOR CONVENCIONAL HACEBDocumento22 páginasManual de Servicio REFRIGETADOR CONVENCIONAL HACEBLeneer Cueva Ramirez33% (3)
- Práctica de Laboratorio (Mecánica) - Velocidad Media e Instantánea (Riel de Aire)Documento12 páginasPráctica de Laboratorio (Mecánica) - Velocidad Media e Instantánea (Riel de Aire)JorgeVAún no hay calificaciones
- STPDocumento10 páginasSTPMario LunaAún no hay calificaciones
- Monday Reminder From Astraeus GymDocumento7 páginasMonday Reminder From Astraeus GymDiana Alejandra Bermudez FajardoAún no hay calificaciones
- 2018 Mat1s U4 PPT Numeros EnterosDocumento10 páginas2018 Mat1s U4 PPT Numeros EnterosCarlos Garcia MorenoAún no hay calificaciones
- Infome 1bim Prácticum 4.1 Javier SaquipullaDocumento5 páginasInfome 1bim Prácticum 4.1 Javier SaquipullamarthitacpAún no hay calificaciones
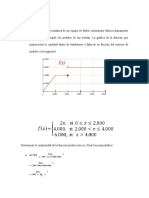
- Una Empresa Patrocinadora de Un Equipo de Fútbol Colombiano Fabrica Diariamente Banderines para Suplir Los Pedidos de Las TiendasDocumento6 páginasUna Empresa Patrocinadora de Un Equipo de Fútbol Colombiano Fabrica Diariamente Banderines para Suplir Los Pedidos de Las TiendasDianne DuarteAún no hay calificaciones
- Fichas Técnicas Alimentación Colectiva y SaludableDocumento15 páginasFichas Técnicas Alimentación Colectiva y SaludableAlan NavarroAún no hay calificaciones